1. 개발 목표
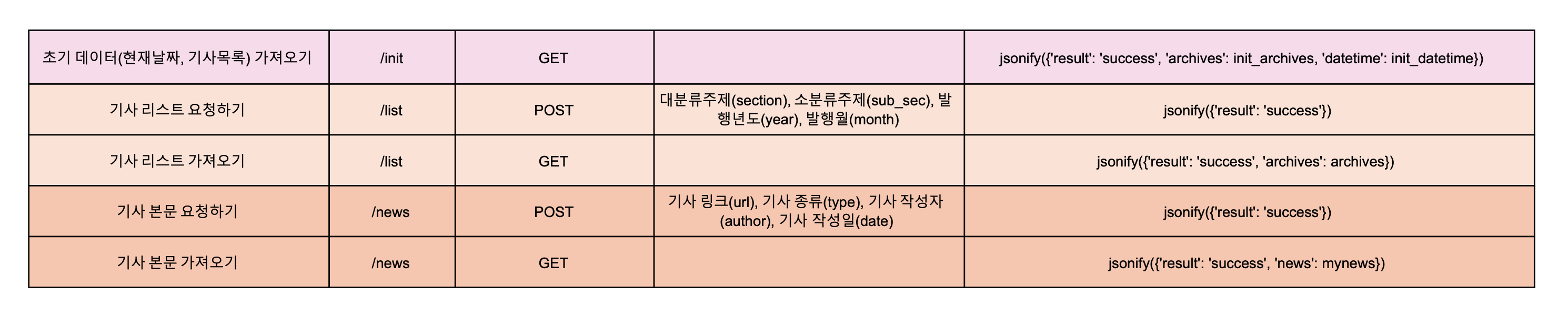
개발 첫번째 과제는 필요한 뉴스 데이터를 수집하는 기능을 구현하는 것이다. 뉴스 데이터 수집 기능은 크게 두가지 단계로 나뉜다.
- 뉴스 리스트 수집
- 뉴스 리스트 중 사용자가 선택한 뉴스의 본문 정보 수집

우선 첫 단계인 뉴스 리스트 수집을 위해 /init 과 /list API부터 설계하였다.
2. 개발 과정
1. 진행 방법
- 웹사이트 구조 파악하기
먼저 뉴스 기사를 가져올 웹사이트의 구조를 살펴보았다. 타겟 웹사이트는 이탈리아의 여러 온라인 뉴스 매체 중에서 기사 종류에 따른 구조와 분류 방식이 비교적 명확하다고 판단한 https://www.avvenire.it/ 를 선택하였다.

Avvenire 의 뉴스 기사는 위와 같이 크게 12가지의 대분류 카테고리와 각 카테고리 별 소분류 카테고리로 나누어져 있었다. 나는 이 중에서 Multimedia, Opinioni, Popotus, Rubriche 4가지를 제외한 총 8가지 카테고리에 해당하는 뉴스 기사를 수집하기로 결정했다.
기사의 경우 크게 4 종류가 존재했는데, 종류 별로 조금씩 기사 형식이 달라 본문을 수집하는 방법도 달라져야만 했다. 어떻게 기사 종류를 판별할지 고민하던 와중에 각 카테고리 별 Archive 페이지를 발견하게 되었다.
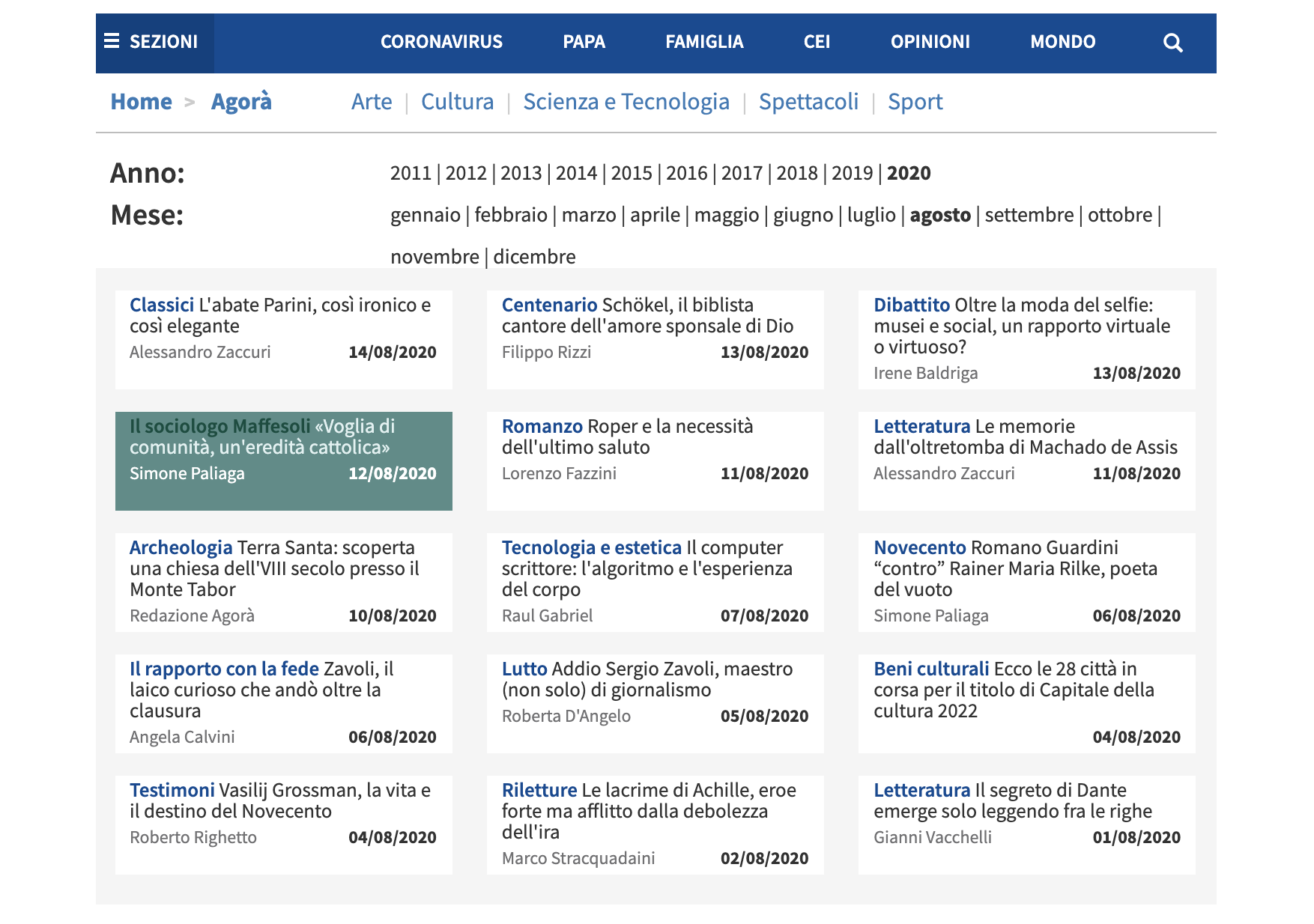
Archive 페이지는 년도와 월별로 카테고리의 기사들을 블럭 형태로 일목요연하게 보여준다. Chrome 개발자 도구로 분석해 보니 한 블럭에는 기사의 제목, 기자 이름, 작성 날짜, 기사의 URL, 그리고 기사의 종류에 관한 정보가 담겨져 있었다. 카테고리 별 뉴스 리스트를 만들기 위해 필요한 데이터가 Archive 페이지에 모두 담겨있는 셈이었다. 그것도 매우 간단명료하게.

Archive 페이지에 접근하는 URL도 간단했다. 기본적으로 "avvenire.it/Archivio/"라는 고정 url 뒤에 "대분류카테고리/소분류카테고리/년/월"로 이루어진 구조가 더해져 구성되어 있었다.
이에 사용자로부터 원하는 날짜와 카테고리 정보를 받아와서 url로 조합하면 바로바로 해당 archive의 뉴스 리스트 데이터를 가져올 수 있겠다라는 생각을 하게 되었고, 본격적인 API 설계에 들어갔다.
- /init API 설계하기
먼저 뉴스 리스트를 수집해올 URL을 구성하기 위해서 사용자에게 날짜와 카테고리 데이터를 제공하는 API가 필요했다. 이를 위해 초기 데이터를 의미하는 /init API를 설계하였다.
@app.route('/init', methods=['GET'])
def show_init_data():
year = str(datetime.today().year)
month = str(datetime.today().month)
year_list = []
anno = datetime.today().year - 4
for i in range(5):
year_list.append(str(anno))
anno += 1
month_list = []
mese = 1
for i in range(12):
month_list.append(str(mese))
mese += 1
datetimes = {
"cur_year": year,
"year_list": year_list,
"cur_month": month,
"month_list": month_list
}
return jsonify({'result': 'success', 'datetime': datetimes})/init API는 기본적으로 현재 년, 현재 월, 년 리스트(최근 5년), 달 리스트(12달)를 딕셔너리 형태로 보내준다. 현재 시간을 가져오는 python의 datetime 라이브러리를 활용해 구현하였다.
/init 데이터는 Client에서 GET 요청된다. 이후 날짜 리스트의 값을 차례대로 select 옵션으로 추가하고 현재 날짜 값과 동일한 데이터를 기본값으로 설정하면 아래와 같이 선택 가능한 날짜 데이터가 화면에 출력된다.

카테고리 데이터의 경우 이미 html 파일에서 수기로 입력하여 구현을 해버렸다. /init API에서 가져왔으면 데이터 수정도 편리하고 훨씬 수월하게 구현할 수 있었을텐데 그때는 미처 생각하지 못했다. 어떻게든 구현은 했으니 일단 넘어가기로 한다.
- FE 출력 결과
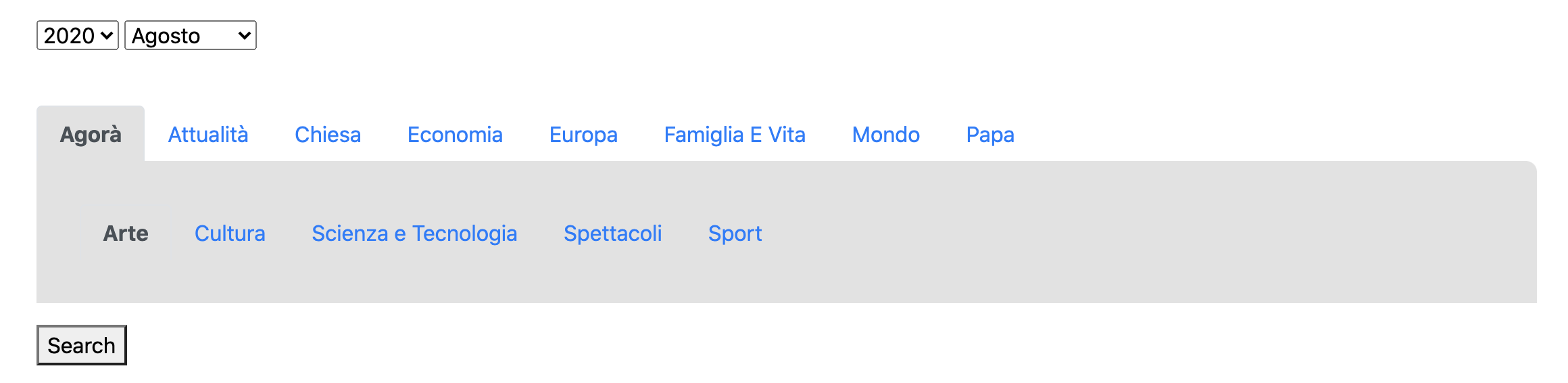
HTML 구조는 Bootstrap과 Codepen을 참고하였다.
- /list API 설계하기
url을 구성하기 위한 데이터를 가져왔으니, 이제 화면에서 값을 받아서 구성한 url로 접근해 뉴스 리스트를 가져오는 API가 필요하다. 이를 위해서 /list API를 POST와 GET 방식으로 각각 구현하였다.
- /list POST
먼저 새삼 복잡한 POST 방식의 /list API이다. Client에서 대분류, 소분류, 년, 월 값을 받아와 Archive의 URL을 만들고 BeautfulSoup4 라이브러리를 통해 뉴스 블록들을 리스트로 가져온다. 이후 반복문을 통해 각 블록의 제목, 작성자, 날짜, 종류, url 정보를 딕셔너리로 묶어 MongoDB에 하나씩 저장한다.
@app.route('/list', methods=['POST'])
def get_archives():
db.archives.drop()
section_receive = request.form['section_give']
subsec_receive = request.form['subsec_give']
year_receive = request.form['year_give']
month_receive = request.form['month_give']
url_fixed = 'https://www.avvenire.it/Archivio/'
url_var = section_receive + '/' + subsec_receive + '/' + year_receive + '/' + month_receive
archive_url = url_fixed + url_var
url_receive = archive_url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url_receive, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
archives = soup.select('#bodyBlock_bodyColumn > div.archivio > div > div > div')
for archive in archives:
news_title = str(archive.select_one('h1'))[4:-5]
news_author = archive.select_one('p.author').text
news_date = archive.select_one('p.rDate').text.strip()
news_type = archive.select_one('div')['class'][2]
news_href = archive.select_one('a')['href']
news_url = "https://www.avvenire.it/" + news_href
archive_contents = {
"title_html": news_title,
"author": news_author,
"date": news_date,
"type": news_type,
"url": news_url
}
db.archives.insert_one(archive_contents)
return jsonify({'result': 'success'})- /list GET
GET 방식의 /list API는 POST 방식에 비해 간단하다. POST에서 데이터를 저장한 DB에 접근하여 리스트 형태로 뉴스 목록을 보내준다. Client는 받아온 데이터를 정해진 HTML 형식에 맞게 뿌려준다.
@app.route('/list', methods=['GET'])
def show_archives():
archives = list(db.archives.find({}, {'_id': False}))
return jsonify({'result': 'success', 'archives': archives})- FE 출력 결과
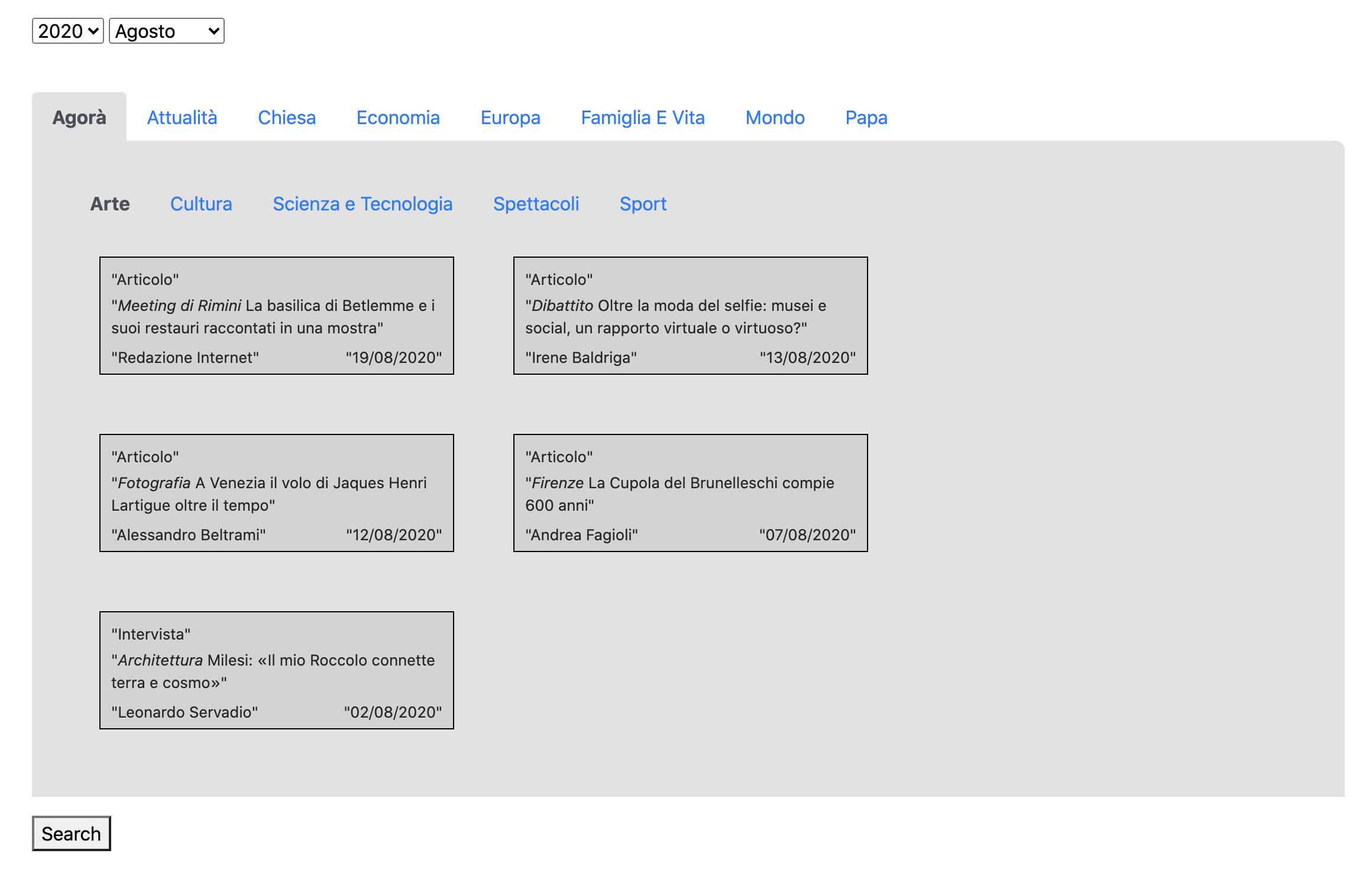
이전의 화면에 뉴스 기사 리스트가 추가되었다. 날짜와 카테고리를 변경하고 Search 버튼 을 누를 때마다 해당 뉴스 기사 리스트가 출력된다. 사실 Search 버튼이 없어도 카테고리나 날짜가 클릭될 때마다 해당 데이터가 출력되도록 만들고 싶은데 아직까지는 방법을 모르겠다. 일단 넘어가고 나중에 수정해봐야겠다.
2. 문제점 및 변경 사항
원래는 날짜와 섹션이 선택될 때마다, 해당하는 값의 db를 바로바로 웹에서 크롤링하는 방식으로 API를 설계하였다. 하지만 매번 필요한 db를 웹에서 크롤링하다 보니 클릭할 때마다 뉴스 리스트를 가져오는 로딩 시간이 너무 길어졌다.
때문에 모든 날짜와 섹션의 뉴스 리스트 데이터를 init_db.py 파일을 통해 미리 db에 저장해둔 뒤, 필요한 데이터를 db에서 바로 가져올 수 있도록 API를 재설계하였다.
- /init GET
@app.route('/init', methods=['GET'])
def show_init_data():
init_dates = db.datetimes.find_one({}, {'_id': False})
return jsonify({'result': 'success', 'datetime': init_dates})- /list POST
@app.route('/list', methods=['POST'])
def get_archives():
db.myarchives.drop()
sec_receive = request.form['sec_give']
subsec_receive = request.form['subsec_give']
year_receive = request.form['year_give']
month_receive = request.form['month_give']
arcs = list(db.archives.find({"section": sec_receive, "sub_section": subsec_receive, "year": year_receive, "month": month_receive}, {'_id': False}))
for arc in arcs:
db.myarchives.insert_one(arc)
return jsonify({'result': 'success'})- /list GET
@app.route('/list', methods=['GET'])
def show_archives():
my_archives = list(db.myarchives.find({}, {'_id': False}))
return jsonify({'result': 'success', 'archives': my_archives})변경한 부분을 요약하자면, 기존에 날짜와 뉴스 리스트를 가져오던 복잡한 함수가 모두 init_db.py 로 넘어갔고 API는 이미 저장된 DB에서 필요한 정보를 가져오는 역할만을 수행한다.
3. 해결 과제
재설계 결과, 확실히 Client 측면에서 발생하던 로딩 시간은 눈에 띄게 줄어들었다.
문제는 초기 데이터를 수집하는데도 꽤 많은 시간이 소요되는 것이다. 대략 한 카테고리에 20분 정도 잡고 8개의 카테고리 모두 수집하는데 2시간 40분이 소요되었다. 수집된 데이터는 27,081 개였다.
내가 코드를 좀 더 효율적으로 쓴다면 수행시간을 단축시킬 수도 있을 것 같기도 한데.. 아직 그 정도까지의 실력은 못되는 것 같다.
약간의 로딩시간을 감수하고 사용자가 클릭할 때마다 바로바로 데이터를 수집하는 것이 맞는 건지, 많은 시간이 걸리더라도 미리 초기 데이터를 축적해 놓는 것이 맞는 건지.. 한 번 수집한 과거 데이터는 바뀌지 않으니, 주기별 부분 업데이트가 답안이 될 수도 있을 것 같긴한데 구체적인 구현 방법은 아직까지 잘 모르겠다. 일단은 다음 과제로 넘어가고 이 부분은 나중에 튜터님께 여쭤봐야겠다.
3. To do ...
이제 뉴스 데이터 수집의 첫 단계는 끝났으니, 다음 단계인 뉴스 본문 수집 기능을 개발할 차례이다.
다음 시간에는 본문 수집 API를 설계하고 편집화면으로 넘어가는 과정을 포스팅하겠다.
