1. 개발 목표
두번째 과제는 가져온 뉴스 데이터의 번역 데이터를 가져오는 것이다. 이를 위해서는 먼저 우리가 많이 사용하는 번역기와의 연동이 필요하다. 번역 데이터가 다양할수록 번역의 질이 올라갈 수 있기에, 나는 크게 3개의 번역기를 활용하기로 결정했다.
- 구글의 Google Translate
- 네이버의 Papago
- 카카오의 Kakao i 번역
번역기와 연동하는 방법에는 크게 두 가지(API or 크롤링)가 있는데, 우선 각 회사에서 제공하는 Open 번역 API를 활용하여 연동해보았다.
2. 개발 과정
- Papago API 연동하기
먼저 Papago의 API를 연동해보았다. 이유는 참고할 수 있는 한글 자료가 많았고 비교적 간단해 보였기 때문이다.
-
Naver Developer 로그인하기
먼저 네이버에서 제공하는 각종 API를 이용하기 위해서는 네이버 개발자센터 홈페이지에 로그인을 해야한다. 네이버 계정이 이미 있는 사람이라면 기존 네이버 계정으로 로그인이 가능한다.
(네이버 개발자센터: https://developers.naver.com/)

-
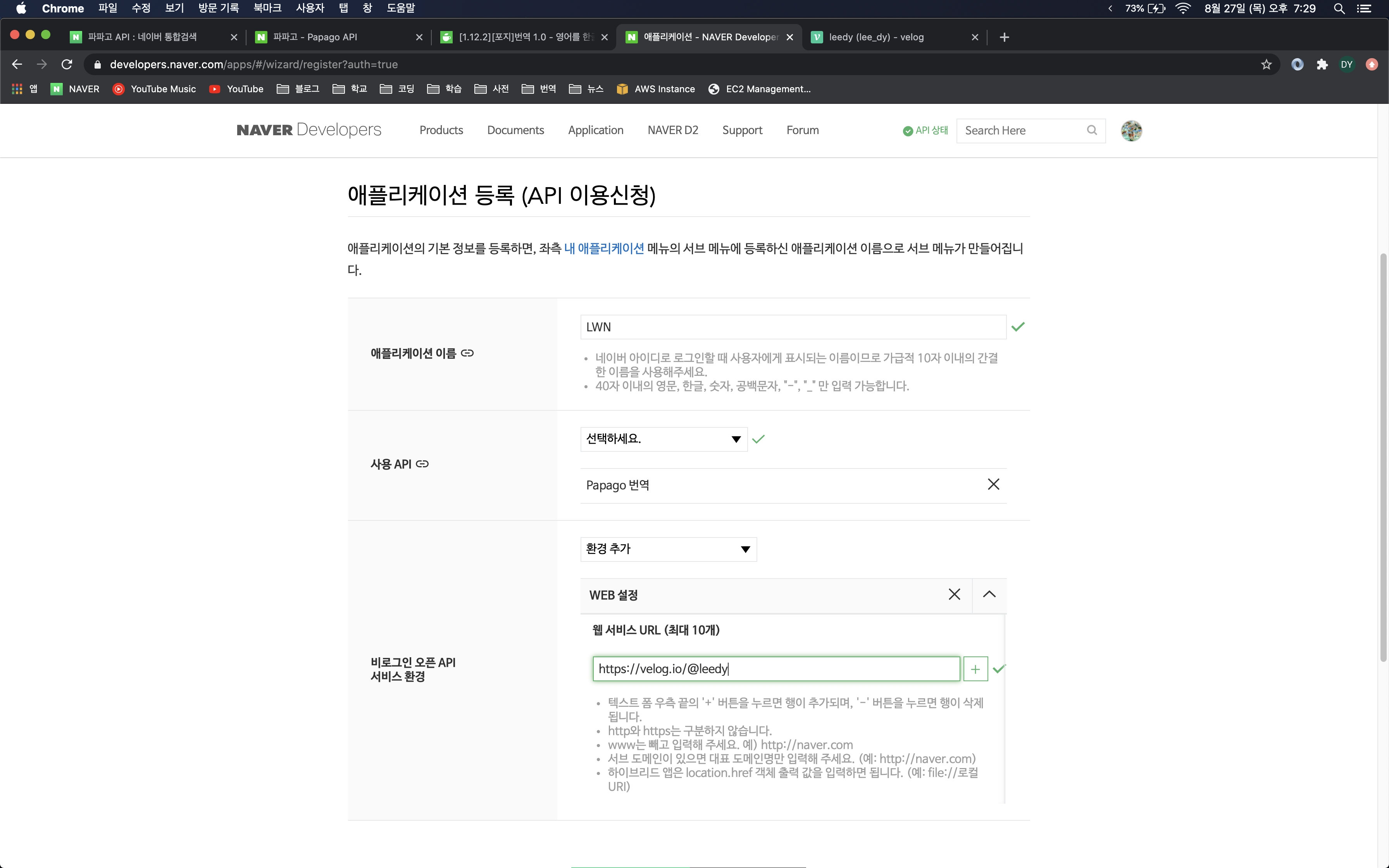
애플리케이션 등록하기
로그인을 했으면 나만의 애플리케이션을 새로 등록해야한다. 홈페이지 상단의 목록 중 Application을 클릭하면 등록이 가능하다. API를 활용할 내 프로젝트의 이름을 입력하고 사용하고자하는 API를 선택한다. 그 다음 사용할 환경을 선택해야하는데, 나 같은 경우 API를 웹 환경에서 활용할 것이기 때문에 WEB으로 설정을 하였다. 웹서비스 URL은 아직 정식으로 배포되지 않았기 때문에 그냥 나의 블로그 주소를 입력하였다.
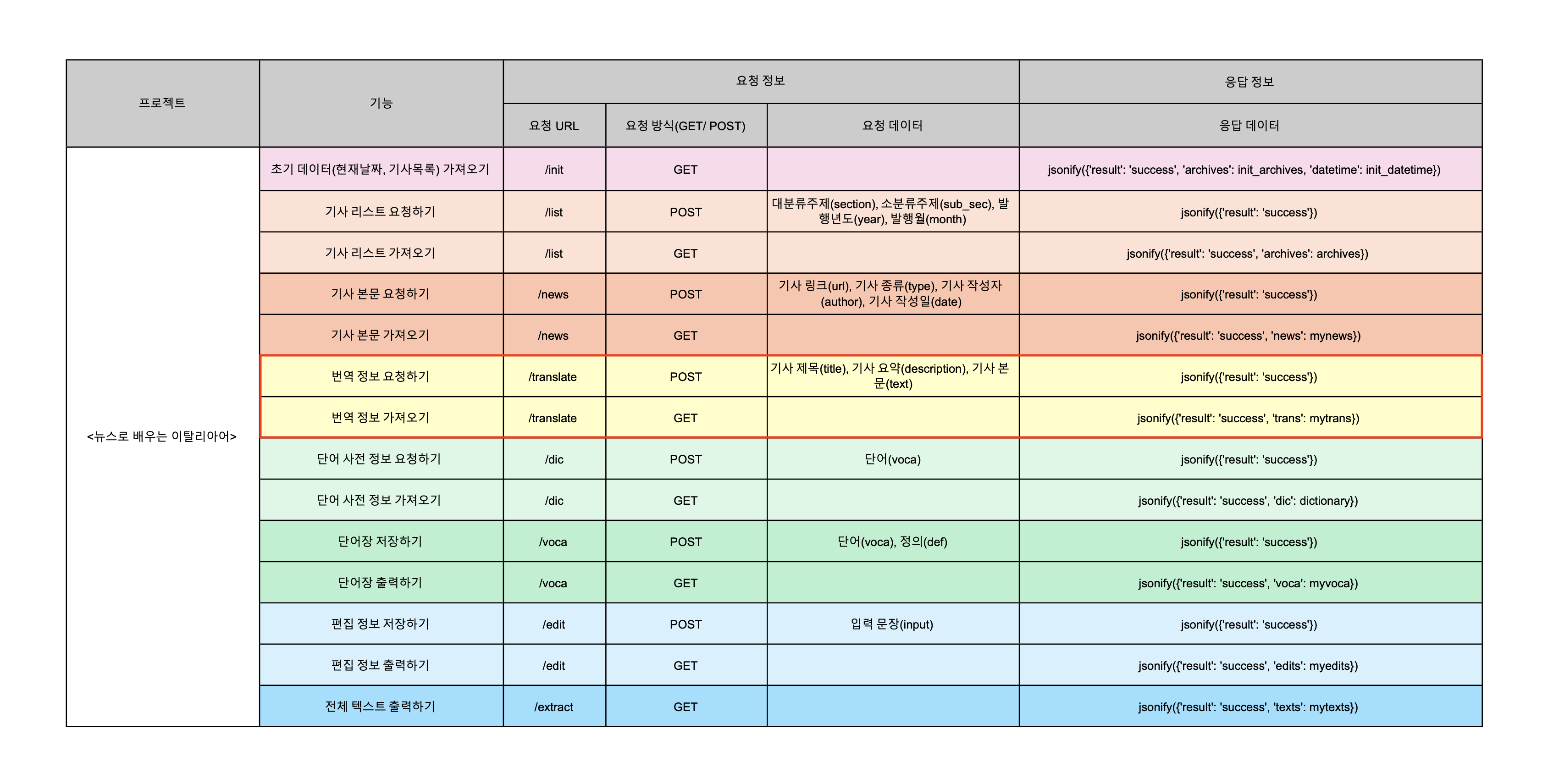
-
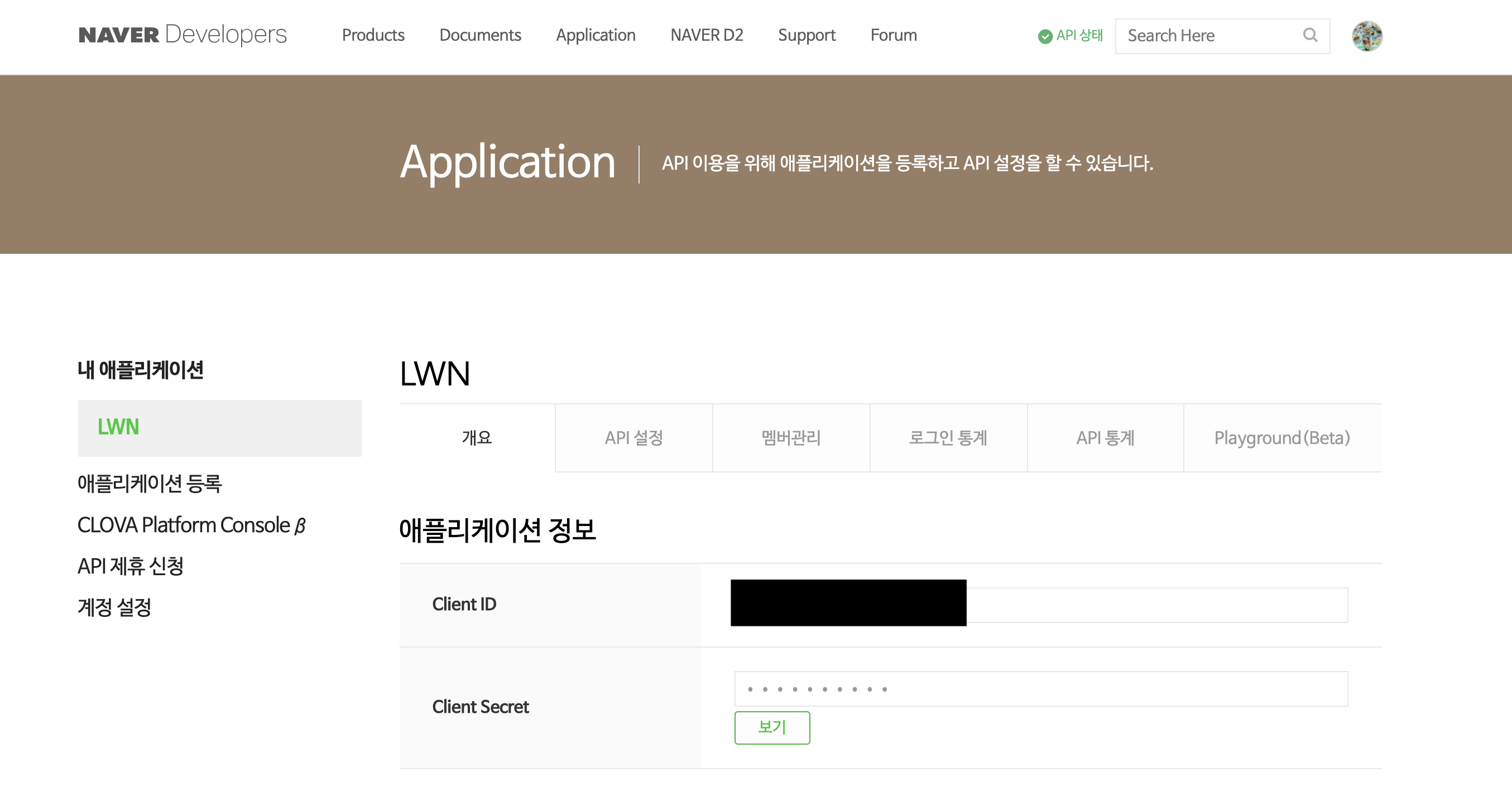
Client ID와 Secret 확인하기
정상적으로 애플리케이션 등록을 완료하였다면, 내 애플리케이션 페이지에서 발급된 Cleint ID와 Secret을 확인한다. 애플리케이션 사용자에게 발급되는 고유한 아이디와 비밀번호인데, 이것이 있어야지만 나중에 내 코드에서 Naver의 API를 활용할 수 있다.
-
코드 활용하기
이제 개발자 페이지에 있는 파파고 개발 가이드를 참고하여 API를 활용하면 된다. 예제 코드 링크에 접속하면 Java, PHP, C#, Python 등 다양한 언어로 작성된 API 활용 코드들이 나와있다. 나는 이중 Python 코드를 가져와 실행해보았다.
(파파고 개발 가이드: https://developers.naver.com/docs/nmt/reference/)
(파파고 NMT API 예제 코드: https://developers.naver.com/docs/nmt/examples/)import os import sys import urllib.request client_id = "YOUR_CLIENT_ID" client_secret = "YOUR_CLIENT_SECRET" encText = urllib.parse.quote("번역할 문장을 입력하세요") data = "source=ko&target=en&text=" + encText url = "https://openapi.naver.com/v1/papago/n2mt" request = urllib.request.Request(url) request.add_header("X-Naver-Client-Id",client_id) request.add_header("X-Naver-Client-Secret",client_secret) response = urllib.request.urlopen(request, data=data.encode("utf-8")) rescode = response.getcode() if(rescode==200): response_body = response.read() print(response_body.decode('utf-8')) else: print("Error Code:" + rescode)
-
코드 수정
위 코드를 그대로 복사 붙여넣기 하여 실행 했을 때, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed'라는 메세지와 함께 에러가 발생하였다. 구글링 결과 다음과 같은 이유로 작동이 되지 않는 것이었다. 해결방법을 따라 아래 코드를 추가하니 정상적으로 작동하였다.
(출처: https://devlog.jwgo.kr/2018/04/13/how-to-unverified-ssl-in-django/)
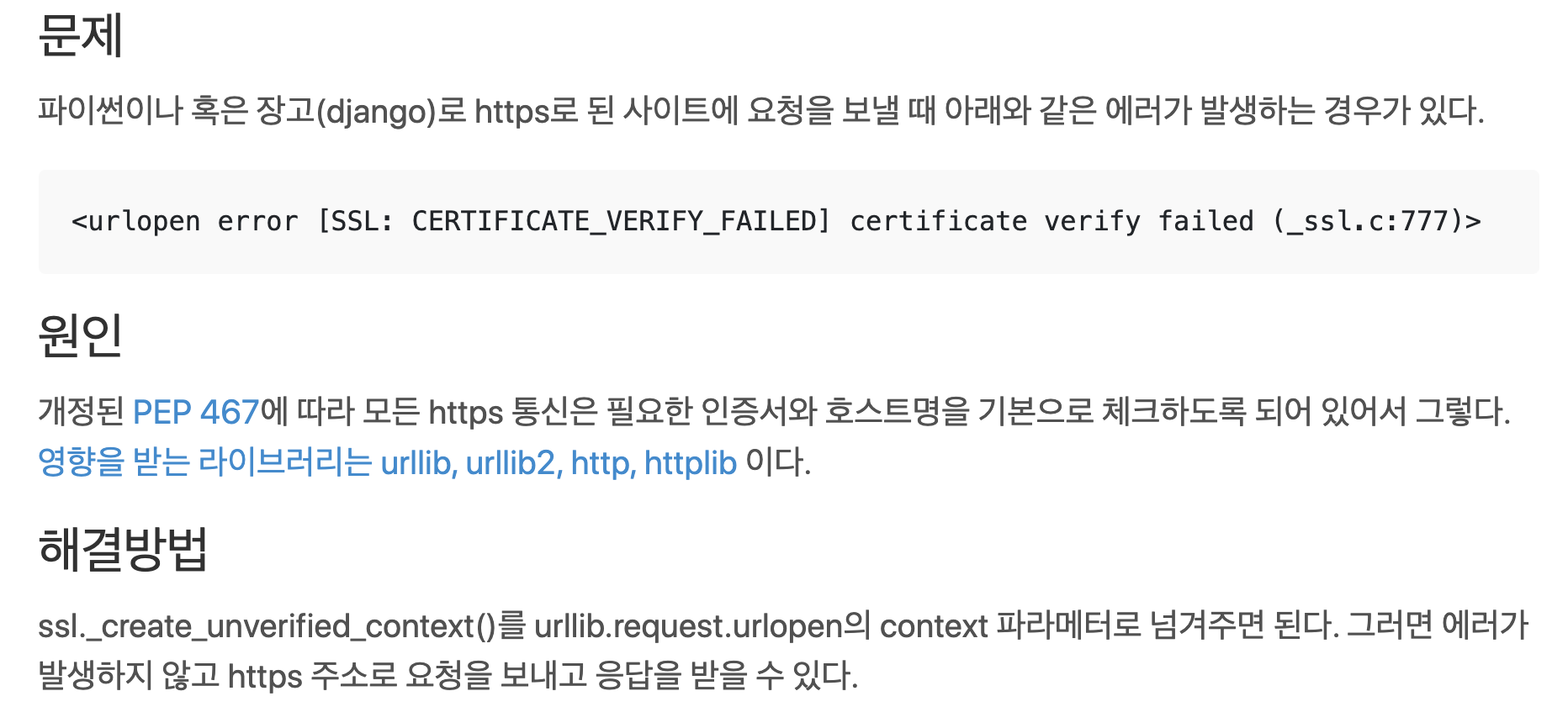
import ssl context = ssl._create_unverified_context() -
테스트
이번에는 기본코드의 변수값을 변형하여 이탈리아어 문장을 한국어로 번역해보는 테스트를 해보았다. 실행 결과 정상적으로 결과값이 출력되는 것을 확인할 수 있었다.encText = urllib.parse.quote("Che cosa hai fatto di bello?") data = "source=it&target=ko&text=" + encText -
{"message":{"@type":"response","@service":"naverservice.nmt.proxy","@version":"1.0.0","result":{"srcLangType":"it","tarLangType":"ko","translatedText":"당신은 무엇을 하고 있었습니까?","engineType":"N2MT","pivot":null}}}
- 결과값에서 번역내용만 출력하기
딕셔너리 형태로 구성된 결과값에서 번역 데이터인 'translatedText' 값만 출력하는 코드는 다음과 같다.
(참고: https://developers.naver.com/forum/posts/27964)if(rescode==200): response_body = response.read() res = response_body.decode('utf-8') import json res = json.loads(res) result = res['message']['result']['translatedText'] print(result)
- 문제점 발견
papago urllib.error.HTTPError: HTTP Error 429: Too Many Requests
성공적으로 Papago API에 연동하여 번역 API를 구축하고 있을 때 또 하나의 오류를 마주하였다. 구글링을 해보니, 검색 API 호출 제한으로 발생한 오류라고 한다.

근본적으로 파파고 API에서 무료로 제공하는 일일허용량이 1만자로 제한되어있었다. 이 이상을 사용하기 위해서는 유료로 사용해야만 하는 것. 구글 번역기도 마찬가지로 무료로 사용할 경우 일일허용량이 1만자 정도로 제한되어있었다. (카카오의 경우 1일 5만자의 쿼터를 제공한다고 한다.)
기사글의 특성상 몇 개만 번역해도 일일허용량을 훌쩍 넘어버리기에 어느 순간부터 해당 오류가 발생하는 것이었다.
- 개발 방향 수정
첫 프로젝트인 만큼 배포보다는 구현에 더 의미를 두고 있기 때문에, 유료로 전환해서 API를 사용하기에는 조금 부담스러웠다. 때문에 번역기 연동 방식을 Open API 활용에서 웹크롤링 방식으로 수정하기로 결정했다.
3. To do ...
따라서 다음 시간에는 request, Selenium과 같은 웹크롤링 라이브러리를 활용하여 번역 정보를 수집할 예정이다.
스파르타코딩클럽 종강일까지 일주일밖에 남지 않은 상황에서 아직까지 갈 길이 멀다 .. 부지런히 개발하지 않으면 프로젝트를 완성하지 못할 수 도 있을 것 같다. 힘!내!자!
