
Previous Methods
기존에는 대용량의 corpus에서 word embedding을 pretraining하고 이것을 embedding layer weight의 seed 또는 freeze하여 fine tuning을 진행하였다. 그 과정에서 주변 출현 단어 군이 비슷한 단어일수록 비슷한 임베딩을 갖도록 하는 방향으로 pretraining 하였는데 이 경우 target task의 training objective에서 필요한 정보가 반영되기 힘들고, 항상 같은 임베딩을 가지기 때문에 context에 따라 달라지는 단어의 의미를 임베딩할 수 없었다. 때문에 실제 fine tuning으로 성능을 올리기 어려워 실제로는 거의 활용되지 않았다.
ELMo(Embedding from Language Models)
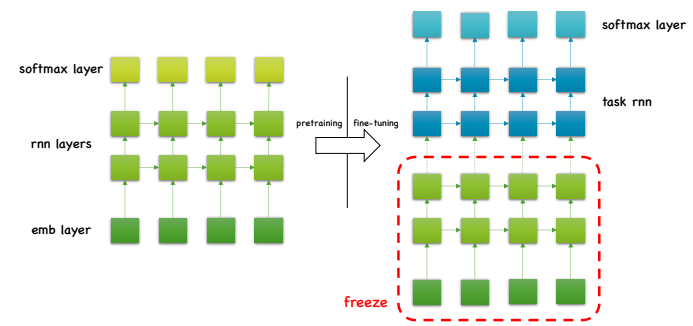
2018년 초에 ELMo가 등장했다. bidirectional context를 반영한 word embedding을 pretraining 하겠다는 컨셉이었다. 이전의 word embedding은 주변의 단어들을 통해서 현제 타임스텝의 word embedding을 학습하기는 하지만 전체 corpus를 대상으로 했기 때문에 global하게 적용되는 것이었다. 실제 task에서는 주변 문맥, 단어를 통해 의미가 달라지고 이는 문장마다 word embedding이 달라질 수 밖에 없는 이유이다. 기존의 word embedding은 주변의 단어가 바뀐다고 word embedding이 바뀌지 않는다. 왜냐면 해당 corpus 에서는 global하게 fix되었기 때문이다.
하지만 ELMo의 경우 양방향적인 컨텍스트 즉, 문맥에 따라 의미를 결정한다. 문맥을 통해 word embedding을 결정하면 downstream task에서도 성능이 좋아질 것이다.
구조는 emb, rnn, softmax layer로 ELMo를 이루고 fine tuning하여 사용하는 경우에는 해당 아키텍처로 self-supervised learning을 하고 pretraining된 rnn과 emb을 떼서 freeze 시킨다. 그 다음 downstream task에 기존 emb layer 대신에 freeze한 ELMo를 집어 넣어 사용하는 것이다. 그리고 그 위에 있는 random initialized된 weight parameter를 fine tuning 하면 된다.
ELMo Equations

ELMo에서 self-suprevised learning을 하는 것은 Bi-LM(Bidirectional Language Model)로 LM이란 문장의 출현 확률을 모델링하는 것으로 자연스럽게 trainer를 통해서 이전 단어가 주어졌을때 다음 단어의 확률을 추정하도록 모델링된 것이다. n개로 이루어진 x라는 입력이 주어지고 P(x)를 펼치면 각 문장, 단어 들의 sequence에 대한 확률을 볼 수 있고 이것은 이전 타임스텝의 단어가 주어졌을때, 현재 타임스텝의 단어의 확률 1부터 n까지를 곱한 것과 같은 것이다. 양방향적이기 때문에 뒤의 단어가 주어졌을 때 현재 단어를 예측하는 것과도 같다. 우리가 학습하고자 하는 pretraining의 object는 다음과 같다. loss function을 최소화하는 방식으로 을 최적화할 수 있다. 의 경우 , (정방향 LM), (역방향 LM), 파라미터로 rnn layer에서는 LSTM cell을 사용한다.
정방향의 파라미터 즉, 앞의 타임스텝 단어가 주어졌을때 현재 타임스텝 단어의 로그확률값의 합과 역방향의 파라미터 즉, 이후 타임스텝 단어가 주어졌을 때 현재 타임스텝 단어의 로그확률 값의 합의 합을 최소화하는 형태로 학습을 진행하게 된다.

좀 더 자세히 살펴보면 정방향 단어를 예측하는 것 은 정방향 하이퍼파라미터의 hidden state인 에 softmax를 씌워주는 것이다.
은 t번째 레이어에 i번째 레이어의 hidden state로 이전 레이어의 현재 타임스텝의 hidden state를 받고, 이전 타임스텝의 현재 레이어의 hidden state를 받아서 RNN이 계산된다. 0번째 레이어는 임베딩 레이어와 같다. RNN layer만 정방향, 역방향의 파라미터가 다르고 임베딩 레이어나 softmax 레이어의 경우에는 이를 공유하게 된다.
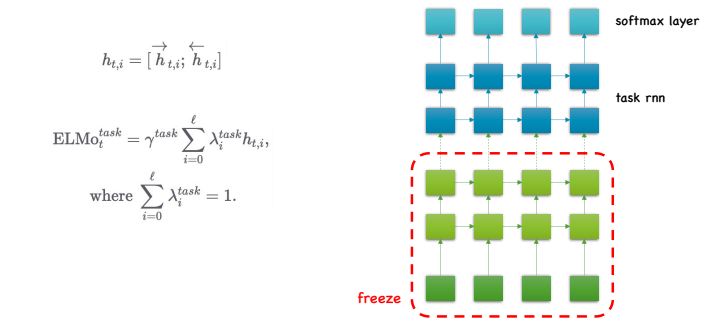
fine tuning 단계에서는 임베딩 레이어가 있어야 하는 자리에 ELMo에서 가져온 임베딩 레이어와 rnn 레이어를 가져와서 얼리면 특정 타임스텝의 워드임베딩 벡터는 로 정의할 수 있다. 는 로 정방향의 t번째 타임스텝에 i번째 레이어의 hidden layer와 역방향의 t번째 타임스텝에 i번째 레이어의 hidden layer의 concat이고 여기에 normalize parameter인 를 곱한 것을 더한 것이 ELMo word embedding 벡터가 된다. 는 스케일링 요소로 hyperparameter이다. 은 학습 parameter이다. ELMo의 경우에는 feature based approach에 가장 대표적인 방법이다.
Conclusion
기존의 단순한 skip-gram 등의 word embedding은 전체 corpus에 대해서 단 하나의 word embedding 벡터를 가지기 때문에 성능이 좋지 않았지만 ELMo의 경우에는 문장 별로 word embedding representation이 나와 성능을 향상시킬 수 있었다. 다만 ELMo의 경우 classifiaction 문제라면 classification에 맞는 task specific한 구조의 모델이 필요하다. 해당 모델은 random seed를 가지고 weight parameter가 initailized되기 때문에 대용량 corpus의 도움을 직접적으로 받지 못한다. Bi-LM을 만들기는 하지만, 각 방향마다 LSTM cell이 구성되기 때문에 각기 한 방향의 정보만 담고 있다는 점은 ELMo의 한계점이라 할 수 있다. Word2Vec을 비롯한 ELMo와 같은 방식은 feature를 사전학습하는 방법이다. 대용량의 corpus를 통해 학습한 더 좋은 feature를 입력으로 넣어주는 것을 목표로 한다. 임베딩 레이어의 weight만 사전학습하는 방식으로 이로 인해 downstream task를 위한 모델 파라미터 자체는 사전학습할 수 없다. 따라서 타겟 object와의 괴리로 인해 성능향상에 효과가 적었다. 추후 등장하는 PLM 방식들은 모델 파라미터 자체를 사전학습하는 것이다. 대용량 corpus를 통해 학습한 더 좋은 seed weight parameter를 통해 더 나은 성능을 확보하게 된다.
