Motivation
목표는 주변(Context window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터 값을 가지게 하는 것이다. 문장의 문맥에 따라 단어의 임베딩이 정해지는 것이 아니라 corpus 전체에 대한 통계에 따라 임베딩이 정해진다. context window의 사이즈에 따라 embedding의 성격이 바뀔 수 있다.
기본 전략
주변 단어를 예측하도록 하는 과정에서 적절한 단어의 임베딩(정보의 압축)을 할 수 있으며 non-linear activation func이 없다
기본적인 개념은 오토인코더와 굉장히 비슷하다. 원핫 벡터가 들어가면 특정 단어를 예측하기 위한 정보가 임베딩 z로 압축이 되고 y를 성공적으로 예측하기 위해 필요한 정보를 선택 및 압축
Transfer Learning via Pretrained Word Embedding
일반적으로 원핫 벡터를 task에 맞는 임베딩 벡터로 바꿔주는 과정이 필요한데 이 때 word embedding 대신에 pretrained된 word embedding 벡터를 넣어주면 잘 되지 않을까 했는데 성능은 비슷하거나 오히려 나빠지는 경우가 발생하였다. 오히려 NLP 이외의 영역에서 응용의 발판이 되었고(추천시스템에서 활용할 수 있는 product2vec 등), 일반적인 NLP 지도학습에서는 random initialized embedding layer를 사용한다. 딥러닝은 중간 산출물을 통해서 할 수 있는 것이 없다. 워드 임베딩이 결과물로 나온다면 유사도 비교 이외에는 딱히 쓸 일이 없다. 실전에서는 사용할 이유가 없다. 일반적으로 사용하는 Embedding layer가 역할을 잘 수행하고 있기 때문이다.
Embedding Layer
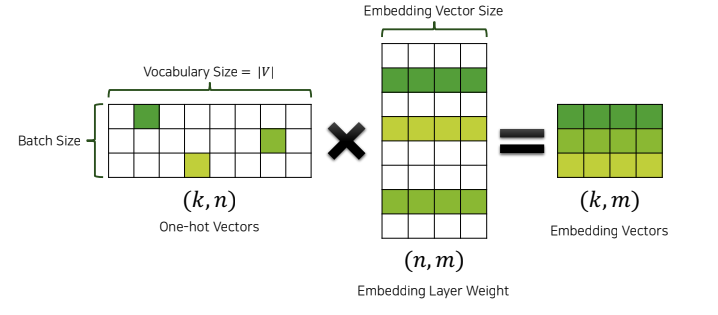
맨 왼쪽에 있는 것은 어떤 한 단어에 대한 원핫벡터로 이루어진 미니 배치이다. k는 배치 사이즈고 n이 vocab의 사이즈다. 이것을 임베딩 레이어에 통과시키는데 사실상 임베딩 레이어는 구현은 다르지만 수식 상으로는 Linear layer와 똑같다. W의 사이즈는 vocab의 사이즈 n과 워드임베딩 벡터의 사이즈 m으로 이루어져 있다. k 행과 m 열이 곱해질때 원핫벡터가 곱해지므로 임베딩 레이어의 row값이 임베딩 벡터에 그대로 간다. 임베딩 벡터가 모델에 들어가면서 임베딩 레이어의 weight 값은 모델에서 좋은 결과를 낼 수 있는 좋은 임베딩 벡터를 뱉어내는 형태로 학습될 것이다. 특정 task에서 서로 유사한 단어는 각각의 임베딩 레이어 weight값이 유사해진다. 단어가 어떻게 동작할지는 task에 따라 다르다. 그렇기 때문에 임베딩 레이어 벡터는 task에 맞게 알아서 잘 학습될 것이다. 그렇기 때문에 pretrained된 word embedding vec을 쓰려고 한다면 해당 task를 고려하지 않고 일괄적인 적용을 하기 때문에 임베딩 레이어는 task에 따라서 weight가 구성이 되기 때문에 word embedding layer가 pretrained 된 word embedding 벡터를 가져와서 Transfer learning을 하는 것보다 일반적으로 같거나 더 좋다. pretrained된 워드 임베딩 벡터에는 하이퍼 파라미터가 따라오고 그걸 또 튜닝하는 것은 굉장히 비효율적이기 때문에 실제로는 굉장히 드물게 사용된다.
conclusion
Word Embedding vector는 주변 단어가 비슷한 단어일수록 비슷한 임베딩 값을 갖도록 학습을 하는데 특수한 상황을 제외하면 실제로 NLP에서 사용되는 경우는 드물다. Embedding Layer는 원핫 인코딩된 이산(discrete)샘플의 영향을 받아, 연속(continuos)벡터로 변환된다. 이는 높은 차원의 벡터를 효율적으로 계산하기 위해서이다. loss를 최소화하는 과정에서 자연스럽게 해당 task에서 비슷한 쓰임새를 갖는 단어는 비슷한 벡터를 갖게 된다.
