state를 잘 반영하면서 좋은 결과를 낼 수 있도록 쿼리를 다양하게 넣어 검색을 다양하게 할 수 있다면
Transformer overview
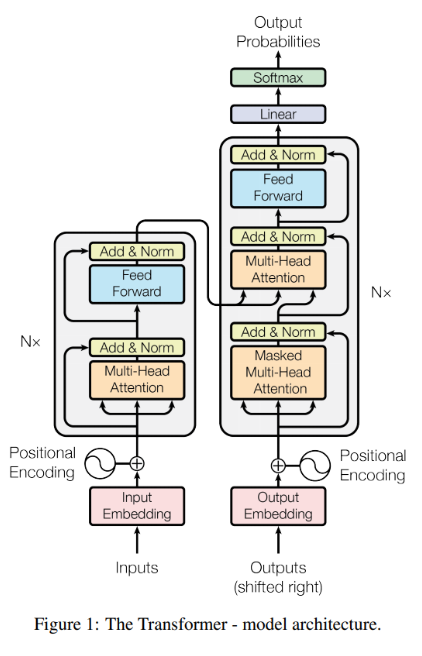
Attention 연산을 통해 정보의 encoding/decoding을 해결 RNN과 달리 위치(순서) 정보를 따로 넣어주어야 하는 position encoding 필요
3가지 attention으로 구성되었는데
- self-attention @ encoder : 밑에서부터 올라오는
- self-attention with mask @ decoder : mask 적용
- attention from encoder @ decoder : cross attention
Residual connection으로 깊게 쌓을 수 있음 추후 BERT와 같은 Big LM이 가능하게 됨
Multi-head Attention
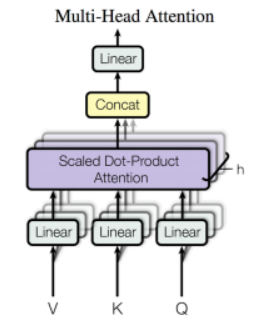
쿼리를 여러번 날릴 수 있으면 좋지 않을까
- Attention @ Sequence to Sequence
Dot-product 연산은 cosine similarity와 매우 유사하다. 즉, attention은 query를 잘 만들어내서, query와 유사한 key를 얻는 과정이며 해당 key-value로부터 필요한 정보를 얻어내는 과정이다. Decoder의 각 time-step마다 encoder로부터 attention을 통해 정보를 얻어와 생성 토큰의 품질을 높인다. - Multi-head Attention @ Transformer
각 head별로 attention을 수행하여 다양한 정보를 얻어올 수 있으며 Self-attention을 통해 이전 layer의 정보를 encoding/decoding 한다. Attention을 통해서 encoder의 정보를 얻어온다. head 마다 attention을 수행하는데 이걸 multi 여러번 수행함
Multi-head Attention Equations

Q,K,V가 self-attention에서 올 경우 same origin이 되며 사이즈가 모두 같다. cross-attention에서 오는 경우 different origin이며 사이즈가 달라지는데 Q의 경우 decoder에서 오므로 n개의 time-step, K, V의 경우 encoder에서 오므로 m개의 time-step을 가진다. Multi-head attention인 각 head에 들어가는 의 수식에서 의 사이즈는 이므로 이 되고 는 이므로 나눠준 것에 를 씌우면 Query와 Key의 유사도를 구하게 된다. 이는 한마디로 w(attention weight)인데 미니배치 별, 디코더에 대한 각 time-step별, 인코더에 대한 각 time-step별 weight가 들어있다. 이렇게 구한 attention weight에 V를 곱하면 weighted sum(가중합)으로 이때의 사이즈는 가 되어 가 된다. 이는 미니배치 내의 각 샘플별, 디코더의 각 타임스텝에 대해서 context vector가 나오게 된다. 이것이 Attention 함수의 정의이고 head의 결과가 된다. 이때 는 attention 함수를 호출해서 Query에 대해서 i번째 Query에 대한 linear transformation, Key에 대해서 i번째 key에 대한 Linear transformation, Value에 대해서 i번째 value에 대한 linear transformation을 먹인 것에 Attention 함수를 적용한다.
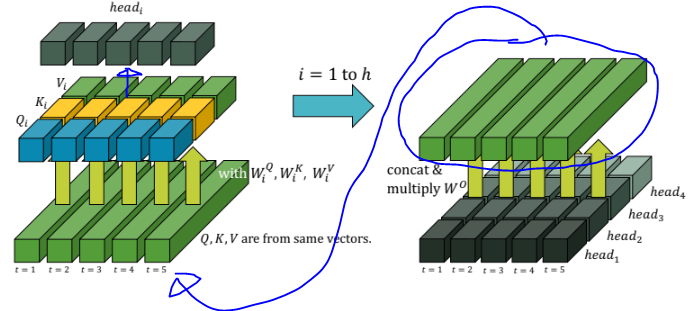
multi-haed attention을 도식화하면 다음과 같은데 Q,K,V라는 벡터가 self-attention을 통해 들어오고 하나의 head에 각각 linear transformation을 먹인다. 그러면 각 타임스텝에 대해서 각각의 가 만들어진다. 그리고 그것에 attention 연산을 수행해 각 타임스텝 별 로 만든다. 이 과정을 h번 반복해서 각 타임스텝 별로 head를 생성하고 concat을 하고 를 곱한다. 최종적으로 다음 레이어에 들어가기 위한 Q,K,V가 만들어지고 위와 동일한 과정을 반복한다. 그런 식으로 마지막 레이어까지 올라가게 된다.
Conclusion
기존의 Seq2Seq에서의 attention은 Query를 잘 만들어서 Key-Value를 잘 maching 시키는 것을 목표로 했다. Transformer의 Multi-head attention은 여러 개의 Query를 만들어 다양한 정보를 잘 얻어오는 것을 목표로 하여 attention 자체로도 정보의 encoding과 decoding이 가능함을 보여줬다. 이를 통해 연산량이 많아지기는 했지만 성능에서 좋은 결과를 얻을 수 있었다. 결과적으로 Transformer는 NLP뿐만 아니라 딥러닝 전반에 큰 영향을 주었는데 NLP의 거의 모든 분야에서 Transformer를 활용하기 시작했고, Sequential 데이터를 다루는 Speech 분야에서도 요긴하게 활용되었다. Vision 분야에서도 이미지 인식 쪽에 큰 인기를 얻고 있고, GNN(Graph Neural Networks)에서도 널리 활용되고 있다.
Seq2Seq에서 한층 더 발전한 Transformer는 더 좋은 성능을 가졌고 더 넓고 깊은 네트워크를 구성하기에 좋다. 다만 seq2seq에 비해 연산량과 메모리 사용량에서 단점을 지니는데 입력으로 이전 모든 타임스텝으로부터 hidden state를 받아와서 attention 연산을 통해서 현재 타임스텝의 hidden state가 결정되기 때문에 메모리 소모가 크기 때문에 길이가 긴 타임스텝을 가져가기 어렵다. 때문에 PLM의 scale에서 단점이 극대화되고 이 때문에 Parallel operation에 대한 engineering이 중요해졌다.
