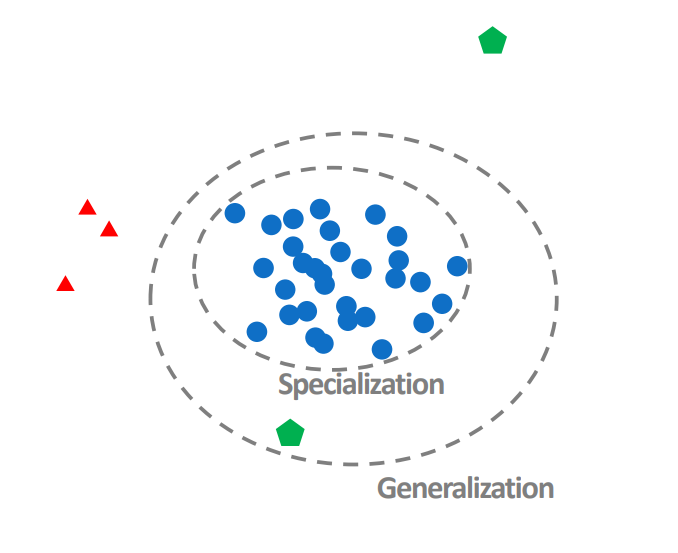
모델링의 목적은 모집단 전체를 두루 적절히 예측하는 것이다.
모델이 복잡하다 = train 데이터의 상세한 패턴까지 반영한다
-> overfitting 발생
이상탐지는 일반적인 값과 다른 특이한 값이나 드문 사건을 탐지하는 기법
얼마나 특이하고 얼마나 드물어야 이상치로 판단할 수 있을까 어느 정도 클래스가 imbalance 해야 이상치일까 딱히 기준은 없으나 경험적으로는 5%보다 적다면 심각한 불균형이라고 판단한다.
유형은 classification, 해결은 비지도 방식으로 진행한다.
1. 이상탐지 개요
1. 이상을 표현하는 용어 정의
- novelty : 긍정적인 뉘앙스(예: 주가급등)
- abnormal : 부정적인 뉘앙스(예: 불량, 사기탐지)
- outlier : 일반 범위를 극단적으로 벗어남
- anormaly
-일반적인 데이터와는 전혀 다른 메커니즘에 의해 발생된 데이터
-확률밀도가 낮은 빈도의 데이터 - Noise
-비정상(abnormal)이라기 보다는 자연발생적으로 데이터 속에 들어가는 변동성
-노이즈를 골라내서 정확히 제거하기는 어려움
Anormaly Detection의 문제 유형은 정상과 비정상을 판단해야 하는 Classification 문제로 Supervised Learning 방식으로 해결한다. 하지만 학습 방법은 Unsupervised Learning에 가까운데 이유는 보통 비정상쪽 데이터는 너무나 부족하고 그나마 있는 데이터들도 Anormaly class 전체를 대표하기는 어렵다.그러므로, 정상(Normal)데이터를 가지고 어디 까지가 정상인지 추정하는 방식을 써야 한다.
어디까지가 정상인지 그 범주를 찾고 그 범주를 벗어나는 데이터는 비정상으로 판단
2. 이상데이터의 유형
- Data Point : 정상 데이터 집단과 본질적으로 다른 희소한 데이터
예: 사기거래, 고객이탈 - Context : 특정 context를 기반으로 크게 벗어난 데이터로 context란 보통 시간의 흐름에 따른 변화이며
- Collective or Group
3. Challenge
- Label을 확보하는 문제
제대로 된 label이 있어야 한다.보통 normal data는 자동으로 수집되는데 abnormal data는 수동 관리하는 경우가 많다 물론 불량을 탐지하는 것은 자동 수집됨. 예를 들어 장애 발생시 이때가 장애 구간이라는 것은 사람이 기록하고 등록한다. 비지도로 학습할 지라도 결국 모델을 평가하려면 label이 있어야 한다. 실제 label이 없거나 신뢰도 문제가 있는 경우가 많다. - 낮은 성능 문제
이상탐지는 보통 성능이 높지 않음 - 올바른 평가를 위한 지표 선정
accuracy, recall, precision, f1-score 등은 어떠한 값을 기준으로 Score를 잘라서 (cut-off value) normal과 abnormal로 나눠야 가능한 평가임
recall과 precision을 균형 있게 볼 수 있는 f1-score가 좀 더 나은 지표일 수 있으며, cut-off value에 따라 결과가 달라지지 않는 지표인 ROC가 있으며 무엇보다 비즈니스 관점으로 평가하는 것이 중요
실제 현장에서 대부분의 데이터는 class imbalance한 상태이며 정도의 차이만 있을 뿐이다.
이상(abnormal) 데이터는 '정상(normal)이 아닌 데이터'
이상 탐지는 classification 유형으로 비지도학습 방식을 사용한다
label 확보, 낮은 성능, 올바른 평가를 위한 지표 선정에 대한 문제해결이 필요하다.
이상탐지 문제 해결 프로세스는 CRISP-DM
2. 분류를 위한 기준(cut-off)
분류 모델의 결과는 확률값으로 나오는 예측된 값을 가지고 만들어 낸 값이다. 예측된 확률 값을 어떤 기준으로 잘라서 0, 1로 분류한다. 이때 cut-off를 조정하면 결과가 달라진다
cut-off에 따른 모델의 성능 변화를 나타내는 그래프로는 ROC, Precision-Recall Curve가 있으며 curve 아래 면적으로 모델의 전반적인 성능을 비교할 수 있다. curve는
분류 모델로 예측한 결과는 0과 1사이의 확률값이며 이 확률값을 잘라야만 class로 나뉘게 됨 자르는 값(cut-off)를 어떻게 지정하느냐에 따라 accuracy, recall, precision, f1-score가 달라지며 cut-off value를 threshold로 부르기도 함 그러므로 분류 모델에 대한 평가를 할 때 비즈니스 요구사항에 맞는 평가지표를 정하고 cut-off 값의 변화에 따른 그래프를 그린 후 비교하고 대표적인 그래츠는 precision-recall curve와 AUROC임다 이상탐지 모델을 만들어 예측하고, 결과에 대해 평가할 때 score를 계산함
3. class imbalance 문제와 해결
ML 알고리즘들은 데이터가 클래스 간에 고르게 분포되어 있다고 가정
해결방법
- Resampling
-Down Sampling
-Up Sampling
소수 클래스의 데이터를 다수 클래스의 수만큼 random sampling((복원 추출, 뽑은 것을 또 뽑을 수 있음)
-SMOTE
기존 소수 샘플을 보간법(interpolation)으로 새로운 데이터를 만들어 냄 - class weight 조정
전반적인 성능을 높이기 위한 방법이 아니라 소수 클래스의 성능을 높이기 위한 작업
F1-score는 정밀도(Precision)와 재현율(Recall)의 조화평균 정밀도와 재현율을 균형있게 바라볼 수 있는 지표
모델링 절차(.fit)
- 모델(함수)의 구조를 잡는다
- 파라미터에 초기값을 할당한다
- 모델을 만들어 예측 결과를 뽑는다
- 오차를 계산한다(loss function)
- 오차를 줄이는 방향으로 파라미터를 조정한다(Optimizer)
분류 문제의 데이터는 대부분 imbalance한 상태이다 이 데이터를 그대로 모델링에 사용하면 다수 class를 더 잘 예측하고 소수 class를 잘 못 맞추는 모델이 생성되는데 이유는 모델링을 수행하는 동안 내부에서는 전체 오차를 줄이는 방향으로 최적화 작업이 수행된다 따라서 소수 class는 잘 예측하지 못하게 된다. 이를 보정하기 위해서 Resampling, Class weight를 조정하는 방법을 쓸 수 있고 두 가지 방법은 지도학습 방식에서 사용하며 둘 다 동일한 효과를 볼 수 있다. 해당 방법을 사용하여 문제를 해결할 수 있는 상황은 매우 행복한 상황이다. 보통 class_weight 옵션이 있다면 사용하는 것이 속편하지만 옵션이 없다면 resampling을 사용해야 한다.
4. Isolation Forest
Supervised Learning : Target이 있는 데이터로 학습
Semi-supervised Learning : Target이 있는 데이터와 없는 데이터로 학습
Unsupervised Learning : Target 없이 학습
1. Isolation Forest의 기본 개념
고립시킨다 = leaf node에 데이터가 한개인 상태
각각의 leaf node에 데이터가 한개인 상태 -> Isolation Tree
1. 주어진 Train set으로부터 일부 데이터를 샘플링
2. Isolation Tree를 여러개 구성해 Isolation Forest 만들기
- 랜덤하게 feature를 선정하고 랜덤하게 split 기준을 삼아 Tree 생성
- 정상 데이터일수록 Isolation 시키려면 많은 split이 필요하므로 depth가 깊어짐
- 비정상 데이터일수록 정상에서 떨어져 있으므로 depth가 얕아짐
- 이런 식으로 여러 개의 Tree를 구성해 평균 depth를 구해 Isolation Score를 구한다
3. Scoring으로 정상(normal)과 비정상(abnormal)을 구분
- Scoring 함수
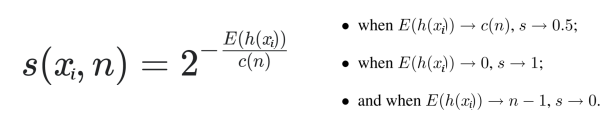
2. Hyperparameter
- contamination
cut-off를 결정해주는 요소
데이터에서 존재하는 Abnormal 데이터의 비율.
Score 계산 후, 이상치로 간주할 비율 - max_samples
Default : 256 - n_estimators
하나의 데이터를 고립시키기 위해 생성하는 tree의 개수
Default : 100 - max_depth
5. One-Class SVM
semi-supervised learning
1. One Class SVM 개념
nomal 데이터의 경계에만 초점을 맞추고 학습하여 normal 데이터만 사용하며 score 산출이 아닌 함수를 찾음
학습 시에 학습용 데이터를 커널 변환하여 새로운 Feature Space를 만들고 데이터를 원점으로부터 최대한 멀리 떨어뜨리는 초평면(Hyperplane, 결정경계)을 찾음
경계 바깥의 값에 대한 패널티 계산에 영향을 주는 Hyper parameter
- v(nu) = nu 값이 커지면 서포트 벡터가 많아지고 결정경계면이 좁아지고 과적합 가능성이 있음 작아지면 서포트 벡터가 작아지면서 결정경계면이 넓어짐
- gamma
SVM은 모델이 분할 경계면을 찾기 때문에 결과는 0,1로 딱 떨어진다 OneClassSVM은 x_train만 사용하고 특히 normal 데이터만 학습하기 때문에 준지도 학습이라고 부르지만 사실 비지도 학습과 차이가 없다. v(nu) 값에 따라 서포트 벡터의 수가 달라진다. v의 범위는 0<v<1로 클수록 서포트 벡터의 수가 많아지도 분할 경계면이 복잡해지지만 값이 작을수록 서포트 벡터의 수가 적어지고, 분할 경계면이 단순해짐
경계면 위와 바깥에 있는 데이터가 서포트 벡터
6. Auto-Encoder
진짜만을 가지고 학습, 진짜의 중요한 특징을 추출해서 기억함
auto encoder는 encoder, decoder 두 개의 부분으로 구성
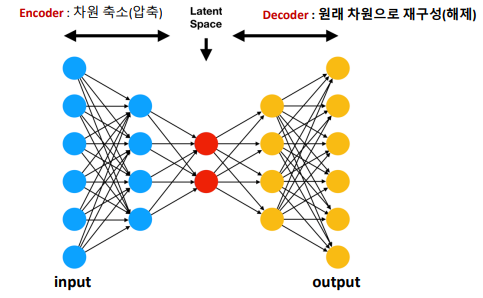
x_train에서 뽑아낸 새로운 output과 input의 차이를 오차라고 함
input를 통해 뽑아낸 output를 재구성(Reconstruction)된 input이라고 함
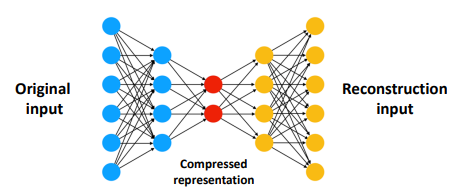
AutoEncoder를 이상탐지에 활용
1. 학습시에는
- normal data만 학습
- 정상 데이터들만의 고유한 특징을 담아내고, 불필요한 특징, 노이즈 등은 걸러지도록 함
- 인풋과 아웃풋이 같아지도록 학습
- 검증시에는
- val, test는 normal, abnormal 모두 포함
- 재구성 오차(Reconstruction Error)를 계산
- normal : 오차가 적을 것- abnormal : 오차가 클 것
- 재구성 오차가 큰 데이터를 abnormal이라고 예측
(cut-off와 동일한 역할)
그렇다면 재구성 오차는 어떻게 계산하고 얼마나 크면 abnormal이라고 할까
재구성 오차 계산
실제 data point와 예측 값에 대한 MSE 계산
분석 단위 별로 MSE 계산
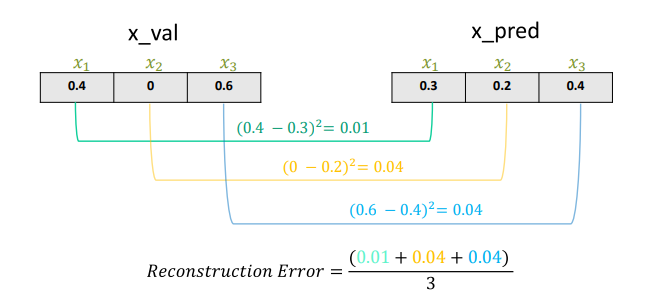
재구성 오차가 얼마나 크면 abnormal일까 f1이 최대가 되는 Threshold를 찾아야 함
AutoEncoder는 딥러닝을 이용한 비지도 학습 방식 알고리즘으로 Encoder와 Decoder로 구성되어 있음 중요한 정보는 보존되고, 불필요한 정보는 제거될 것이라는 기대가 있음
7. 비즈니스 관점에서의 모델 평가
이 모델에서 중요한 것은 무엇인가
무엇을 하려고 했는가
실제 목적에 맞게 모델의 결과를 평가하고 있는가
모델의 confusion matrix
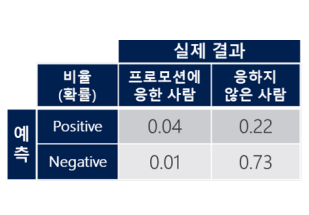
비즈니스의 가치 매트릭스
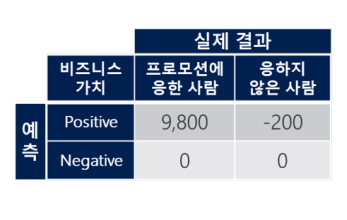
모델의 기대가치 계산
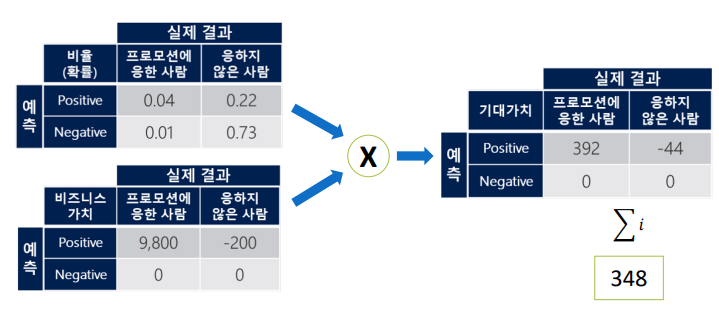
348이 고객 1명 당의 기대가치 수익이고 이 가치가 높을수록 좋은 모델이다
