
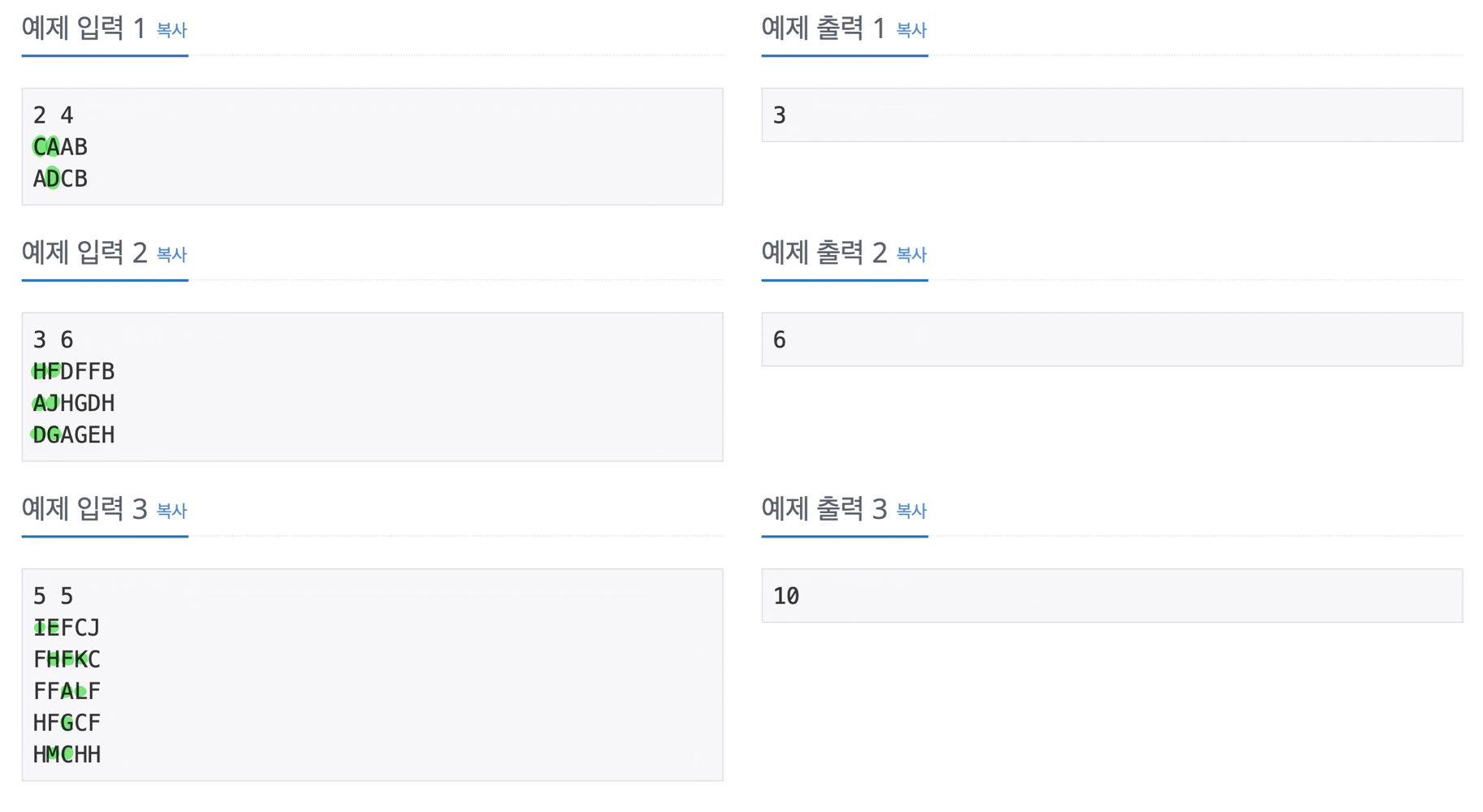
1️⃣ 문제 설명

- 같은 알파벳이 적힌 칸을 두 번 지날 수 없다.
- 좌측 상단 칸(시작하는 칸)도 포함하여 센다.
2️⃣ 예시
3️⃣ 문제 풀이 아이디어
- 최대한 많은 칸을 지나야 하기 때문에 깊이 우선 탐색인
DFS가 적합하겠군! - 같은 알파벳이 적힌 칸을 두 번 지날 수 없고, 이미 지나온 칸도 다시 지날 수 없으니 visited 배열과 비슷하게 visited_alpha 배열을 만들어 이미 지나온 알파벳인지 검사해야지!
4️⃣ 코드
import sys
import string
input = sys.stdin.readline
r, c = map(int, input().split())
graph = []
visited = [[False for _ in range(c)] for _ in range(r)] # 해당 칸을 방문했는지 체크
visited_alpha = [False] * 26 # 이미 방문했던 알파벳인지 체크
count = 1
for _ in range(r):
alpha = list(input().rstrip())
graph.append(alpha)
def dfs(graph, x, y, visited, visited_alpha):
# 현재 노드 방문 처리
char = graph[x][y]
index = string.ascii_uppercase.index(char) # 현재 칸에 적힌 알파벳이 몇 번째 알파벳인지 체크
visited[x][y] = True
visited_alpha[index] = True
dx = [0, 1, 0, -1]
dy = [1, 0, -1, 0]
for i in range(4):
nx, ny = x+dx[i], y+dy[i]
# 보드를 벗어난 경우
if nx<0 or nx>=r or ny<0 or ny>=c:
continue
char = graph[nx][ny]
index = string.ascii_uppercase.index(char)
# 방문하지 않은 칸이며, 이제까지 지나오지 않은 알파벳인 경우
if not visited[nx][ny] and not visited_alpha[index]:
global count
count += 1
dfs(graph, nx, ny, visited, visited_alpha)
dfs(graph, 0, 0, visited, visited_alpha)
print(count)

5️⃣ 틀린 이유 및 정답 코드
 왼쪽이 정답인 경로이고, 오른쪽이 잘못된 경로이다.
왼쪽이 정답인 경로이고, 오른쪽이 잘못된 경로이다.
하지만 나의 코드로 동작할 경우, 잘못된 경로로 진입했다가 빠져나올 때 visited_alpha 배열과 count 변수가 진입 이전으로 초기화되지 않았다.
결국 ... 오늘도 다른 사람의 코드를 참고하였다 ... 🥹
핵심은 visited 배열과 visited_alpha 대신
set을 활용하였다.
리스트에서 in 키워드를 사용하여 포함 여부를 확인하는 것의 시간 복잡도는 평균O(n)이지만,
Set이나 Dictionary와 in 키워드를 사용하면 시간 복잡도가O(1)이다.
(내부적으로 Hash를 사용하기 때문)
파이썬의 집합 자료형인 set에 대해 자세히 알고 싶다면? 옆에 링크로 들어가서 읽어보자.
- 배운 점 1 ‼️ 내가 밟은 칸이 이미 방문했던 알파벳인지만 체크하면 된다. 알파벳이 같으면 이미 지나온 칸이란걸 알 수 있다. visited 배열은 필요 없다.
- 배운 점 2 ‼️ 잘못된 경로로 진입했다가 빠져나올 때 변수를 초기화하는 것은 재귀로 dfs()를 호출한 다음에 해주면 되는 것이다.
import sys
input = sys.stdin.readline
r, c = map(int, input().split())
graph = []
alphabet = set()
ans = 0
# 입력
for _ in range(r):
graph.append(list(input().rstrip()))
def dfs(x, y, count):
global ans
ans = max(ans, count) # 최대 칸의 개수를 출력하기 위해 비교
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
for i in range(4):
nx, ny = x+dx[i], y+dy[i]
if 0<=nx<r and 0<=ny<c and graph[nx][ny] not in alphabet:
alphabet.add(graph[nx][ny])
# count += 1
# dfs(nx, ny, count)
dfs(nx, ny, count+1)
alphabet.remove(graph[nx][ny])
alphabet.add(graph[0][0])
dfs(0, 0, 1)
print(ans)
🤔 왜 count+= 1을 따로 빼면 틀릴까?
우리가 지금 필요한 것은 dfs에서 depth가 증가할 때마다 count를 1 증가시키는 것이다.
💢그러나 count+=1을 하고 → dfs에 인자를 넘기면 for문에서 range를 돌며 상하좌우마다 1씩 더해진다💢
이는 for문을 돌 때 조건문의 조건을 충족하는 방향이 둘 이상일 때 count가 여러 번 증가되어 문제가 되는 것이다.
그러므로 해당 문제 뿐만 아니라 재귀 함수를 사용하며 횟수를 셀 때 되도록이면 인자 안에서 세는 것을 추천한다.
(+) 파이썬은 변수 선언이 없어서 사용된 변수인지 새 변수인지 다르게 인식할 수 있다 조심조심🤯
6️⃣ BFS & DFS를 파이썬으로 풀 때 시간초과를 조심하자
✅ 조건문의 순서
if adj[v][i] and i not in hist:if i not in hist and adj[v][i]:위 코드는 시간 초과가 발생하지 않지만, 아래 코드는 시간 초과가 발생한다.
조건문의 조건으로 A and B라고 쓸 때 A가 false이면 B는 보지 않고 넘어간다.
최대한 A에 false가 많이 발생하는 것을 위치시키자.
✅ 런타임 에러
파이썬에서 정한 재귀 깊이를 넘어가면 런타임 에러가 발생한다. 이 때는
import sys
sys.setrecursionlimit(10000) 을 추가해주어 재귀 깊이를 변경해주자.
단, 너무 깊게 설정해도 시간 초과가 발생할 수 있으니 무조건적으로 쓰는 것은 좋지 않다. 간혹 해당 코드를 쓰면 틀리고, 쓰지 않아야 맞는 문제도 있다.
