1. FinanceDataReader
-한국 주식 가격, 미국 주식 가격, 지수, 환율, 암호화폐 가격, 종목 리스팅 등 금융 데이터 수집 라이브러리
-pandas-datareader를 보다 보완하기 위한 목적으로 만들어졌다.
-종목코드: KRX(KOSPI, KOSDAQ, KONEX), NASDAQ, NYSE, AMEX, S&P 500
-가격 데이터: 해외주식 가격 데이터, 국내주식 가격 데이터, 각종 지수, 환율데이터, 암호화폐 가격
설치
!pip install -U finance-datareader
라이브러리 불러오기
데이터 분석을 위해 Pandas 불러오기
import pandas as pd
import numpy as np
FinanceDateReader 불러오기
import FinanceDataReader as fdr
데이터 수집
-한국거래소 상장종목 전체 가져오기
df_krx = fdr.StockListing("KRX")
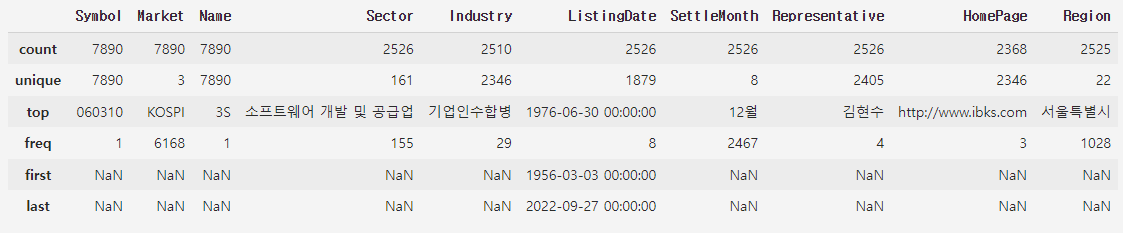
-최근 상장한 종목 보기
ListingDate 컬럼을 기준으로 내림차순 정렬하기
df_krx.sort_values(by="ListingDate", ascending=False)

웹 상의 특정 url에 있는 데이터 직접 불러오기
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13'
pd.read_html(url)
2. 네이버 금융 뉴스기사 수집
pandas 이용
import pandas as pd
검색값 설정
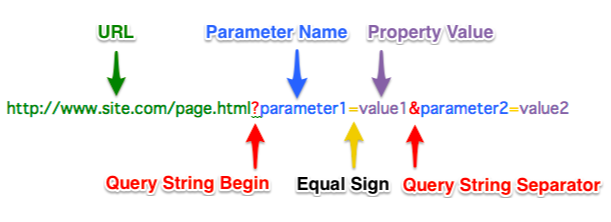
Query String : URL 뒤에 물음표를 붙이고 입력 데이터를 작성하여 데이터를 전달하는 방식
item_code = "035720"
item_name = "카카오"
page_no = 1
url = f"https://finance.naver.com/item/news_news.nhn?code={item_code}&page=1&sm=title_entity_id.basic&clusterId="
데이터 수집
네이버 금융의 주가 기사를 read_html()을 통해 가져와서 table 변수에 담기
table = pd.read_html(url)
데이터프레임으로 만들기
df = table[0]
반복문으로 데이터 모두 가져오기
----------------------------------
# 컬럼 이름을 통일시키기 위해 데이터프레임의 컬럼명 가져오기
cols = df.columns
temp_list = []
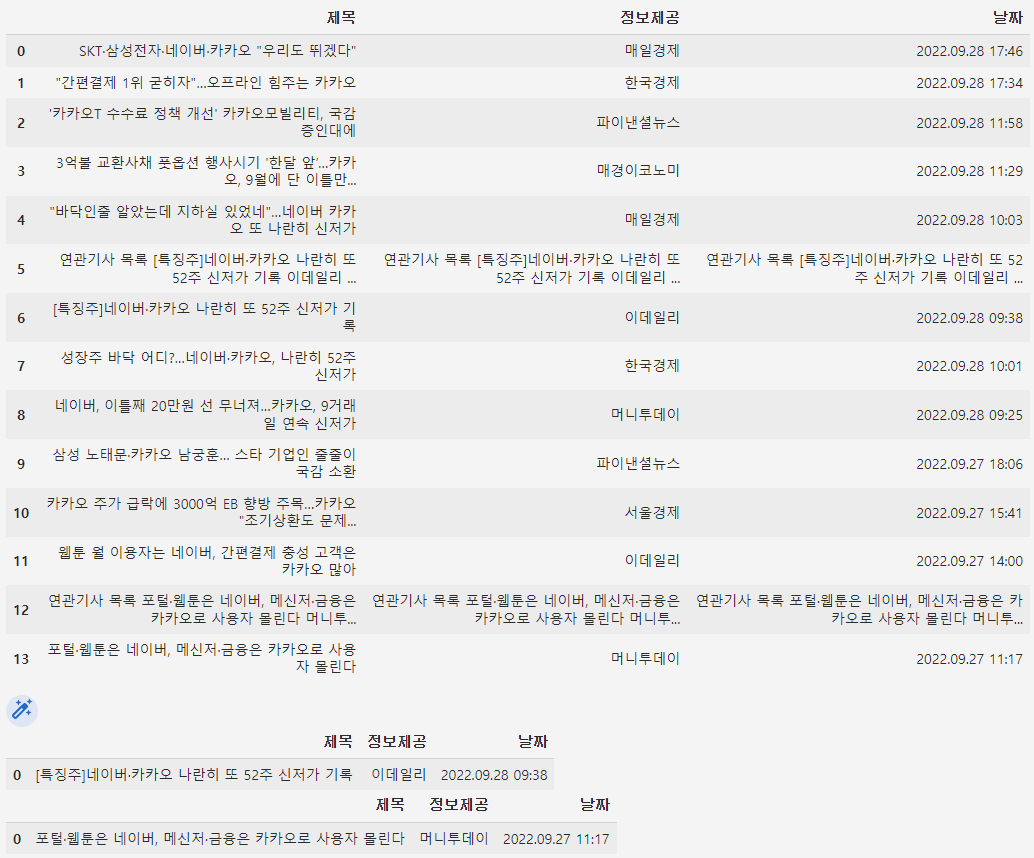
for news in table[:-1]:
# df의 컬럼명으로 통일
news.columns = cols
# temp_list에 하나씩 추가하기
temp_list.append(news)
# news 출력해보기
display(news)
----------------------------------
하나의 데이터프레임으로 합치기
df_news = pd.concat(temp_list)
-axis=0 : 행을 기준으로 위아래로 같은 컬럼끼리 이어붙이기 (기본값)
-axis=1 : 열을 기준으로 인덱스가 같은 값끼리 옆으로 이어붙이기
인덱스 번호 재설정
drop=True => 별도의 인덱스를 생성하지 않음
df_news = df_news.reset_index(drop=True)
결측치 제거
df_news = df_news.dropna()
제목에 "연관기사"가 들어가는 데이터 제거
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
"연관기사" 가 들어가는 행이 삭제되었으므로 인덱스 재설정
df_news = df_news.reset_index(drop=True)

중복값 제거
df_news = df_news.drop_duplicates()
하나의 함수로 만들기
-----------------------------------------------------------------------------------------------------------------------------
def get_url(item_code, page_no):
url = f"https://finance.naver.com/item/news_news.nhn?code={item_code}&page={page_no}&sm=title_entity_id.basic&clusterId="
return url
def get_onde_page_news(item_code, page_no):
url = get_url(item_code, page_no)
table = pd.read_html(url, encoding="cp949")
cols = table[0].columns
temp_list = []
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
df_news = pd.concat(temp_list).reset_index(drop=True)
df_news = df_news.dropna()
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
df_news = df_news.reset_index()
df_news = df_news.drop_duplicates()
return df_news
-----------------------------------------------------------------------------------------------------------------------------반복문을 사용하여 10페이지까지 수집
------------------------------------------------------------------------
import time
from tqdm import trange
page = 0
# item_name을 통해 FinanceDataReader에서 item_code를 찾아오기
item_name = "기아"
item_code = df_krx.loc[df_krx["Name"] == item_name, "Symbol"].values[0]
new_list = []
for page in trange(1, 11):
temp = get_one_page_news(item_code, page)
new_list.append(temp)
# 상대 서버의 부하를 줄이기 위해 딜레이
time.sleep(0.1)
------------------------------------------------------------------------Pandas를 통해 new_list를 하나의 데이터프레임으로
df_news = pd.concat(news_list)
3. 네이버 금융 개별종목 수집
라이브러리 로드
import pandas as pd
import numpy as np
import requests
수집할 URL 정하기
-URL 가져오기
① 네이버 금융에서 "삼성전자" 검색
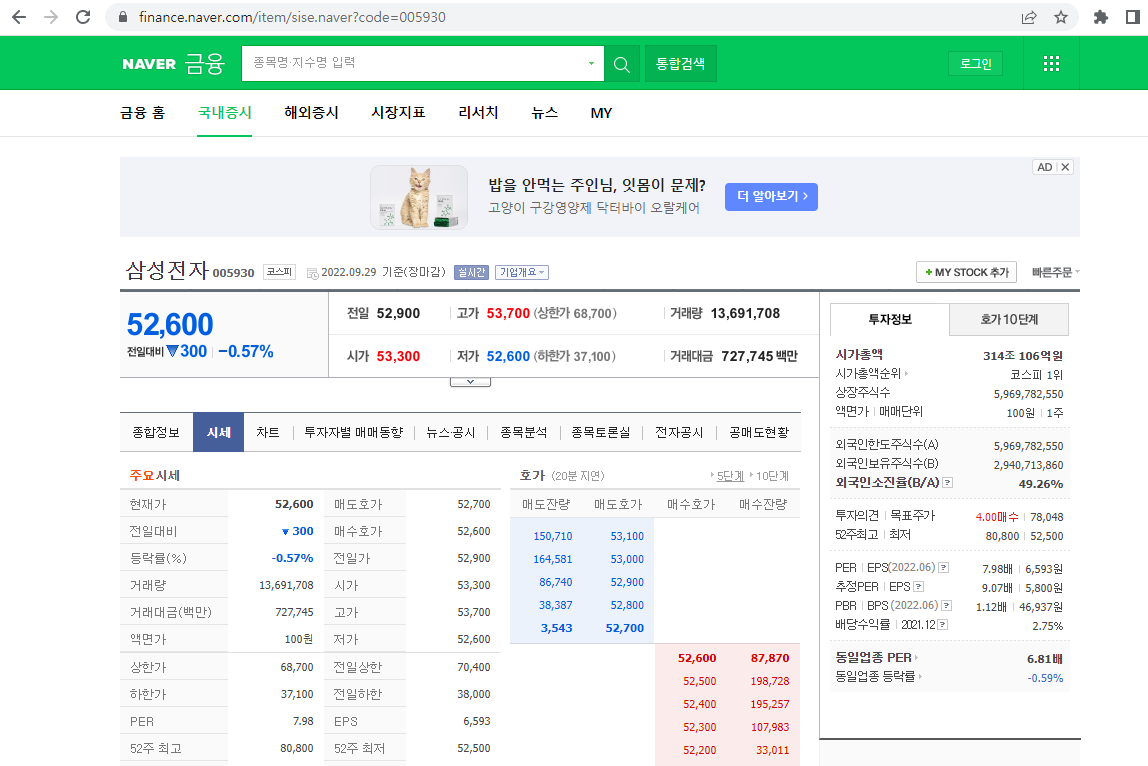
② 시세 탭 클릭하고 마우스 오른쪽 클릭한 후 검사 선택
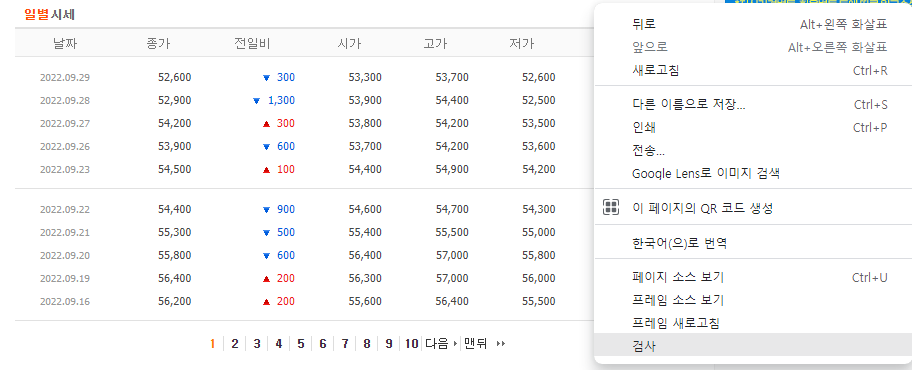
③ 네트워크 탭 - Doc 탭 - URL 가져오기
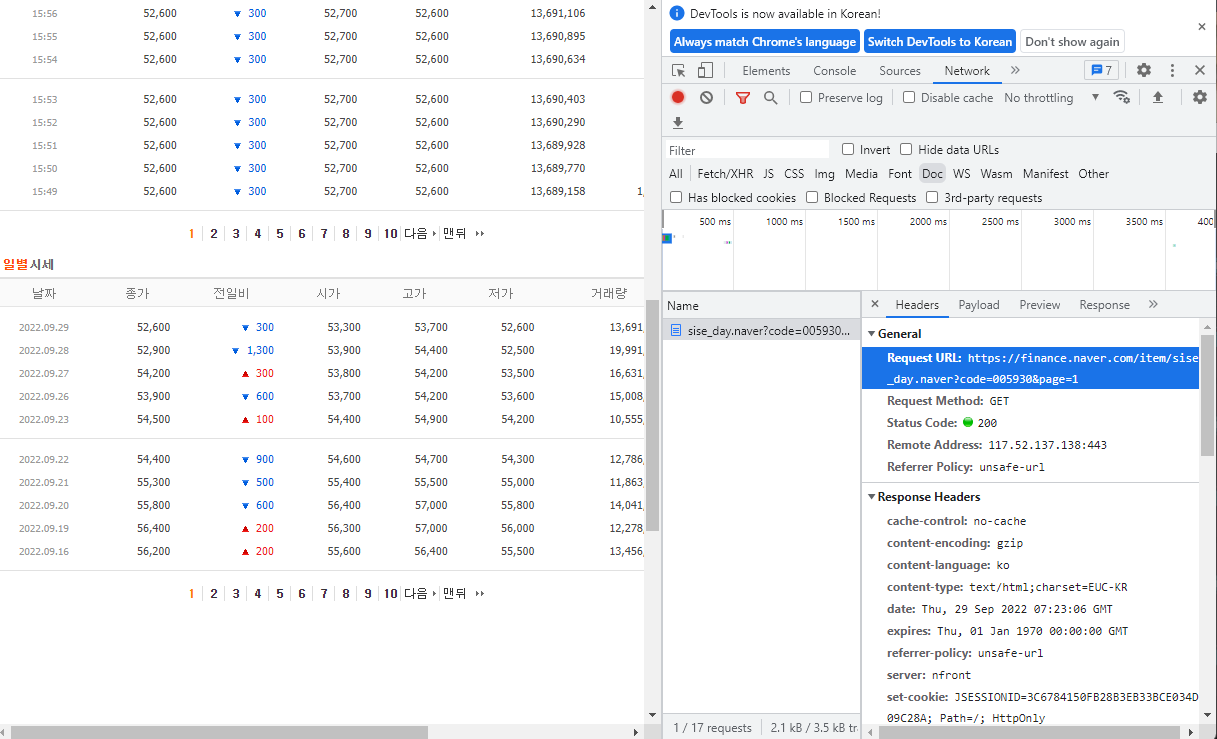
=> URL = https://finance.naver.com/item/sise_day.naver?code=005930&page=1
-URL을 fstring을 통해 포맷팅하여 다른 종목도 검색할 수 있도록
----------------------------------------------------------------------------------------
item_code = "005930"
item_name = "삼성전자"
page_no = 1
url = f"https://finance.naver.com/item/sise_day.naver?code={item_code}&page={page_no}"
----------------------------------------------------------------------------------------requests를 통한 HTTP 요청
서버에서 봇으로 오해하여 접속을 막지 않도록 headers를 통해 서버에 봇이 아니라 브라우저라고 알려준다.
response = requests.get(url, headers={"user-agent : Mozilla/5.0"})
table 태그 찾기
- BeautifulSoup 이용
html문서를 BeautifulSoup으로 감싸면 보기 좋게 구조화해준다. (Parsing)
=> 원하는 정보를 쉽게 추출할 수 있다.
불러오기
from bs4 import BeautifulSoup as bs
구조화
html = bs(response.text)
table 태그 찾기
① html.table : table 태그 하나만 가져옴
② html.find_all("table") : table 태그 모두 가져옴
-인덱스 슬라이싱 가능
-attribute를 지정 가능
html.find_all("a", class="sister")
=> 링크를 콕 집어서 가져올 수 있다.
③ html.select("table") : table 태그 모두 가져옴
-브라우저에서 copy selector를 통해 태그 위치를 hiararchical하게 복사해올 수 있다.
html.select("body > table.type2")
※ 태그 위치가 순서대로 작성되지 않으면 내용이 출력되지 않으므로 직접 입력하는 것보다는 브라우저에서 복사해오는 것을 추천
- Pandas 코드 한 줄로 데이터 수집
read_html() 내부에 table 태그를 가져오는 기능이 내장되어있다.
=> BeautifulSoup 사용 X, table이 아닌 다른 태그가 필요하다면 사용 O
table 변수에 데이터 담기
table = pd.read_html(response.text)

필요한 데이터만 가져오기
필요한 데이터가 table[0]에 있으므로 table[0]만 변수에 담기
temp = table[0]
결측치(NaN) 제거
temp.dropna()
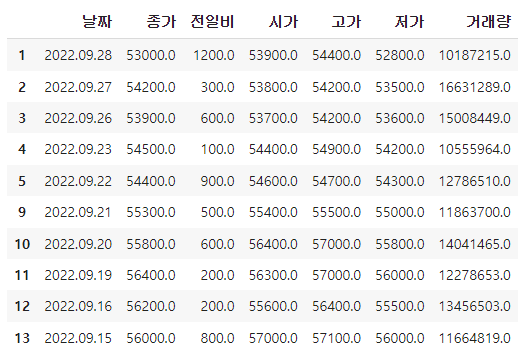
페이지별 데이터 수집 함수 만들기
종목 번호를 이용하여 page에 따라 데이터를 읽어오는 함수
------------------------------------------------------------------------------------------
def get_day_list(item_code, page_no):
# url을 만든다.
url = f"https://finance.naver.com/item/sise_day.naver?code={item_code}&page={page_no}"
# requests를 통해 html 문서 받아오기
response = requests.get(url, headers={"user-agent" : "Mozilla/5.0"})
# read_html을 통해 table 태그 읽어오기
table = pd.read_html(response.text)
# 결측행 제거
item_list = table[0]
item_list = item_list.dropna()
# 데이터프레임 반환
return item_list
------------------------------------------------------------------------------------------함수가 잘 만들어졌는지 확인
page_no = 1
item_code = "035720"
get_day_list(item_code, page_no)
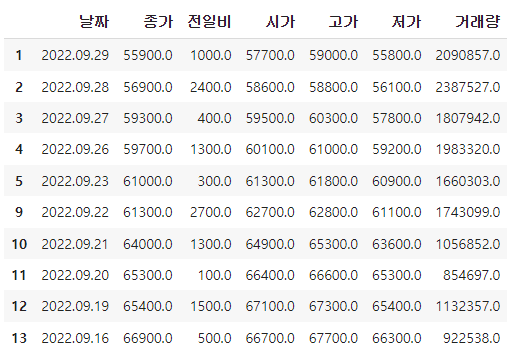
반복문을 이용하여 전체 일자 데이터 수집하는 함수 만들기
※ 서버에 부담주지 않도록 time.sleep() 입력해주기
import time 필요
--------------------------------------------------------------------------------------
def get_item_list(item_code, item_name):
page_no = 1
# 데이터를 저장할 빈 변수 선언, 이전 데이터 날짜 초기값 설정
item_list = []
prev_day = ""
while True:
# 반복문을 통해 한 페이지씩 일별 시세 수집
df_item = get_day_list(item_code, page_no)
# 해당 페이지의 마지막 날짜 가져오기
last_day = df_item.iloc[-1]["날짜"]
# 해당 데이터의 마지막 날짜와 이전 데이터의 날짜 비교-같으면 반복문 탈출
if last_day == prev_day:
break
# 현재 데이터의 날짜를 다음 턴에서 비교할 수 있게 변수에 값을 넣어줌
prev_day = last_day
# 수집한 일별 시세를 리스트에 추가
item_list.append(df_item)
# 다음 페이지를 수집하기 위해 페이지번호 1 증가
page_no += 1
# 서버에 부담을 주지 않도록 쉬었다가 가져옴
time.sleep(0.1)
# 수집한 데이터를 하나의 데이터프레임으로 합치고 인덱스 재설정
df_day = pd.concat(item_list).reset_index(drop=True)
# 종목코드와 종목명 컬럼 추가
df_day["종목코드"] = item_code
df_day["종목명"] = item_name
# 컬럼 순서 변경하기
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df_day = df_day[cols]
# 중복 데이터 제거
df_day = df_day.drop_duplicates()
# 데이터 프레임 반환
return df_day
--------------------------------------------------------------------------------------함수가 잘 만들어졌는지 확인
item_code = "323410"
item_name = "카카오뱅크"
get_item_list(item_code, item_name)
파일로 저장하기
fstring으로 파일명 만들기
-종목명, 종목코드, 날짜를 이름으로 하는 csv 파일명
file_name = f"{item_name}_{item_code}_{date}.csv"
csv 파일로 저장
-index=False : 별도의 인덱스를 생성하지 않음
df_day.to_csv(file_name, index=False)
저장한 csv 파일을 데이터프레임으로 불러오기
pd.read_csv(file_name)
*한글 윈도우 엑셀에서 보기 : encoding="cp949" 를 통해 인코딩
