멋쟁이 사자처럼 자기주도학습
1.Pandas 정리
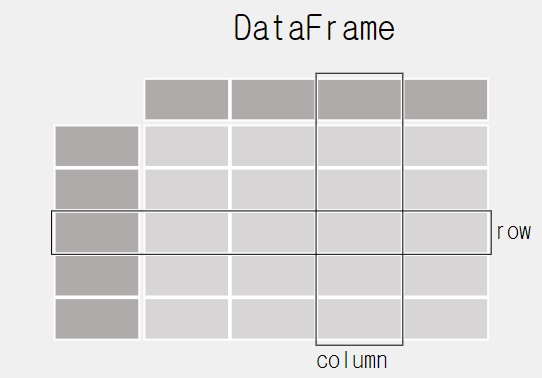
Python Data Analysis Library파이썬에서 데이터 조작 및 분석을 하기 위해 작성된 소프트웨어 라이브러리import pandas as pdimport를 통해서 pandas를 불러온다.as = alias : pandas의 별명을 설정DataFrame:
2.앤스컴콰르텟(Anscombe's quartet)
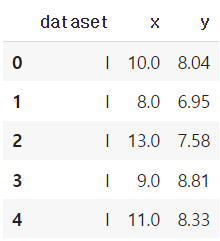
기술통계량은 유사하지만 분포나 그래프는 매우 다른 4개의 데이터셋시각화의 중요성, 특이치 및 주영향관측값의 영향을 보여주기 위해 만들어진 데이터셋앤스컴콰르텟\_위키백과df = sns.load_dataset("anscombe")df = pd.read_csv("https&
3.웹 스크래핑

\-한국 주식 가격, 미국 주식 가격, 지수, 환율, 암호화폐 가격, 종목 리스팅 등 금융 데이터 수집 라이브러리\-pandas-datareader를 보다 보완하기 위한 목적으로 만들어졌다.\-종목코드: KRX(KOSPI, KOSDAQ, KONEX), NASDAQ, N
4.머신러닝
정답이 주어지는 학습 방식선형회귀, 정규화, 로지스틱 회귀, 서포트 벡터 머신, 커널 기법을 적용한 서포트 벡터 머신, 나이브 베이즈 분류, 랜덤 포레스트, 신경망, k-최근접 이웃 알고리즘개체가 속한 범주 식별적용 : 스팸 감지, 이미지 인식 알고리즘 : SVM, n
5.머신러닝_당뇨병 예제
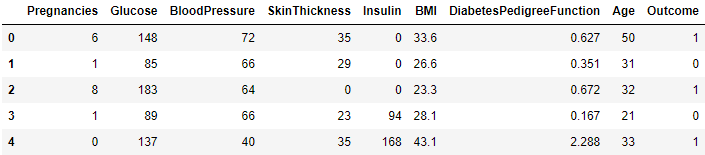
데이터셋 출처 Pima Indians Diabetes Database | KaggleScikit-learn datasets.load_diabetes데이터 구성Pregnancies : 임신 횟수Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도B
6.Matplotlib Tips
혼란한 Matplotlib에서 질서 찾기, 이제현 - Pycon Korea 2022 <- 정리하기맨 처음에 한번만 설정하면 된다.matplotlib에도 style기능이 있지만, seaborn 추천 why? 속성 별로 설정을 다르게 할 수 있기 때문 seabor
7.Feature Engineering
데이터 수집데이터 전처리탐색적 데이터 분석(EDA)특성 공학(Feature Engineering)\+머신러닝Nominal: 여러 가지로 나뉘고 자연적인 순서가 없는 범주형 변수Ordinal: 여러 가지로 나뉘고 자연적인 순서가 있는 범주형 변수Discrete: 유한하거
8.Gradient Boosting
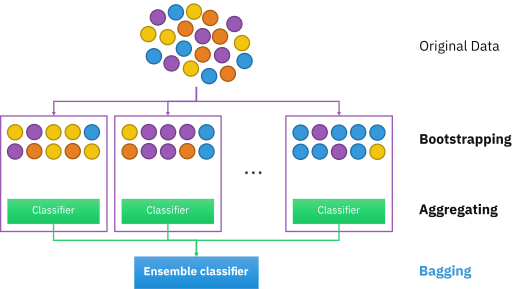
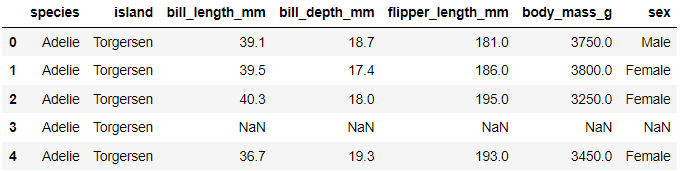
① 랜덤 포레스트조금씩 다른 여러 결정트리의 묶음각각 결정트리는 예측을 잘 할 수 있지만 데이터 일부에 과대적합된다.예측을 잘 하지만 서로 다른 부분에 과대적합된 트리를 묶어 평균을 채택하면 과대적합을 줄일 수 있다.② 그래디언트 부스팅여러 결정트리의 묶음랜덤 포레스트
9.Confusion Matrix (혼동 행렬)
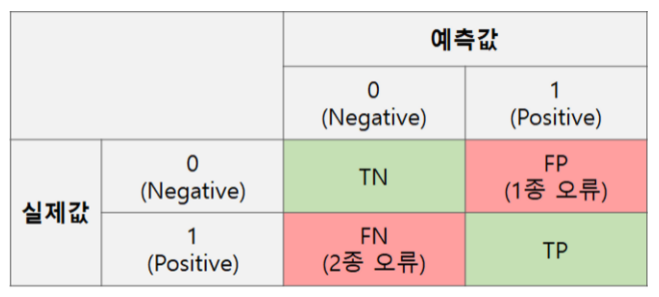
TRUE : 모델이 맞췄을 때FALSE : 모델이 틀림Positive : 모델이 예측 값이 TRUENegative : 모델이 예측 값이 FALSETN : 아닌것을 아니라고 “잘” 예측FP : 아닌데 맞는 것으로 예측 - 1종오류FN : 맞는데 아닌 것으로 예측 - 2종
10.합성곱 신경망 (CNN)
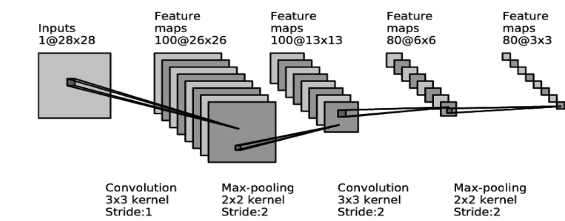
Convolution Neural Network, 합성곱 신경망다층 퍼셉트론(MLP)으로 이미지를 flat하게 펼쳐 학습하면 이미지의 지역적 정보 소실=> 합성곱 층의 뉴런은 수용 영역 안에 있는 픽셀에만 연결하여 이미지의 지역적 정보 보유다층 퍼셉트론은 해당 데이터를