요약
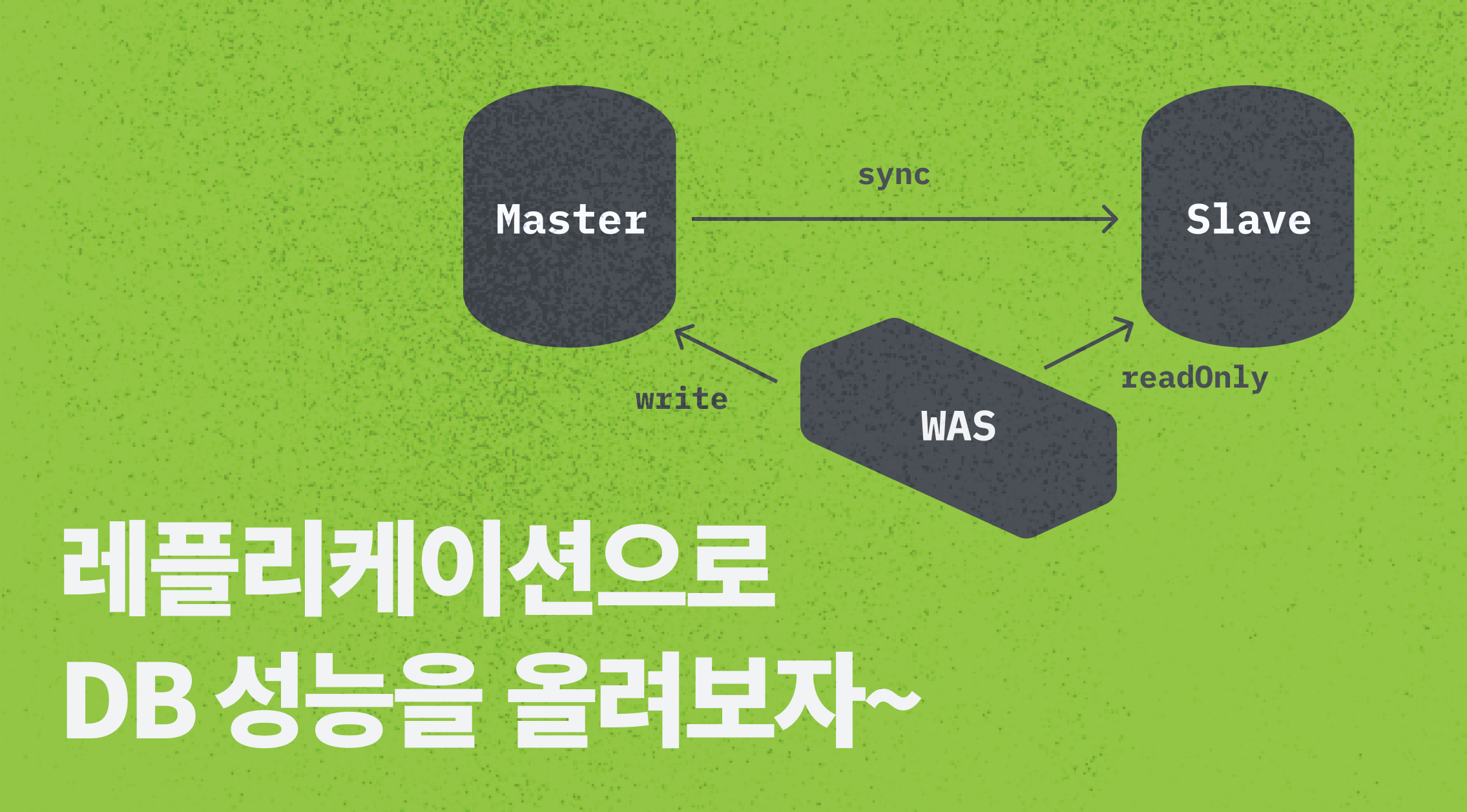
DB 병목을 완화하기 위해 레플리케이션을 적용했습니다. 각 DB별로 DataSource 빈을 등록하고, AbstractRoutingDatasource를 이용해 트랜잭션의 readOnly 여부에 따라 DataSource를 동적으로 선택하도록 했습니다. 그리고 LazyConnectionDataSourceProxy를 사용함으로써 DB 커넥션을 얻기 전에 미리 트랜잭션 정보를 동기화해서 적절한 DataSource를 선택하도록 했습니다. 이 과정에서 DataSource 타입의 빈들이 여러 개 생성되었는데, 여러 설정들이 추가된 최종 DataSource 빈을 @Primary로 지정해서, DataSourceAutoConfiguration에서 1개의 메인 빈으로 인식할 수 있도록 해서 자동설정이 정상적으로 이뤄지게끔 했습니다.
레플리케이션?
담배200이라는 프로젝트를 진행중인데, 트래픽을 늘리며 성능테스트를 진행하다보니 DB에서 병목이 발생했습니다. 병목을 해소할 방법을 조사해보니 레플리케이션이란 걸 알게 되었습니다. 많은 서비스에서 조회 쿼리가 대부분이기 때문에 조회와 갱신/추가 쿼리 전용 서버를 나눠 처리하는 스케일아웃 방식이라고 볼 수 있습니다. 물론 Primary/Replica 서버 간 동기화 시간과 I/O처리와 락에 대한 오버헤드가 있긴 하지만, 이 프로젝트는 많은 사람이 이용하는 대용량 트래픽을 가정하고 진행하기 때문에 그런 상황에선 이렇게 해서라도 DB 병목을 줄이는 것이 성능상 이점이 있을 것 같아 적용했습니다.
레플리케이션이란?
읽기 전용 DB를 추가함으로써 성능을 향상시키는 방식입니다. 읽기쿼리는 replica DB로 보내고, 쓰기 쿼리는 primary DB으로 보내며, 새 내용이 replica로 보내져 두 DB 사이의 일관성을 유지합니다. 대부분의 쿼리가 조회쿼리이기 때문에 replica를 여러개 두거나 스케일업을 하기도 합니다.
MySQL 레플리케이션 설정
스프링에서 레플리케이션 코드를 짜기전에, MySQL에서 실제로 DB간 레플리케이션을 설정해야하는데 이 내용은 구글링해서 쉽게 찾아볼 수 있습니다. 이 글에선 스프링부트에서 레플리케이션을 어떻게 활용하는지에 중점적으로 대해 다룹니다.
readOnly에 따라 DataSource를 동적으로 결정
각 DB별로 다른 설정 값을 가진 DataSource 빈을 등록했습니다. 어떤 DataSource를 사용할지를 서비스 코드에서 개발자가 일일이 정하게 되면 코드가 너무 복잡해지고 DB 클러스터를 구성함에 있어 관리가 어려워질 것 같았습니다. 그래서 AbstractRoutingDatasource 추상클래스를 상속해 트랜잭션이 ReadOnly라면 slave DataSource를, 아니라면 master DataSource를 쓰도록 동적으로 결정하도록 구현했습니다.
// 내가 구현한 AbstractRoutingDatasource의 구현체
protected Object determineCurrentLookupKey() {
DataSourceType dataSourceType = TransactionSynchronizationManager.isCurrentTransactionReadOnly() ? DataSourceType.SLAVE : DataSourceType.MASTER;
return dataSourceType;
}DataSource와의 Connection을 Lazy하게 생성
원래 Spring에서 DataSource와의 커넥션을 형성하는 과정은 다음과 같습니다.
트랜잭션에 진입하는 순간 → TransactionManager 선택 → DataSource와의 Connection 획득 → 트랜잭션 동기화
즉 커넥션 획득 시점에는 트랜잭션이 동기화되어있지 않아있는 것입니다. 그러면 현재 스레드에 매핑된 트랜잭션의 정보를 불러올 수 없어서, 위의 AbstractRoutingDataSource 구현체에서 현재 트랜잭션이 readOnly인지 아닌지 알 수가 없어 데이터소스를 찾기위한 분기처리가 불가능합니다.
그래서 LazyConnectionDataSourceProxy를 사용함으로써, 트랜잭션 동기화를 먼저하고 난 뒤 커넥션을 얻도록 했습니다. 그러면 커넥션을 얻는 과정은 아래와 같아집니다.
TransactionManager 선택 → Proxy Connetion 획득 → 트랜잭션 동기화 → 실제 쿼리를 활용할 때 Proxy Connection의 getConnection() 호출
DataSourceAutoConfiguration을 비활성화 해야할까?
DataSourceAutoConfiguration을 포함해서 많은 AutoConfiguration 클래스들은 DataSource가 1개임을 가정하고 구성되어있습니다. 근데 이 프로젝트에선 DataSource 클래스가 총 3개(Master, Slave, Routing)가 있기 때문에, DataSourceAutoConfiguration이 작동하지 않아 오류를 내었습니다. 그래서 처음엔 DataSource 설정클래스에서 DataSourceAutoConfiguration을 제외하고, 트랜잭션매니저와 EntityManager 또한 직접 빈으로 등록 해주었습니다.
하지만 꼭 이런식으로 해줘야할까 의문이 들어, AutoConfiguration 클래스에 적용되는 @Conditional과 같은 어노테이션을 익히고나니, 사용자에 의해 등록된 DataSource 빈이 없을 때 DataSourceAutoConfiguration에 의해 새 DataSource빈을 생성함을 알 수 있었습니다.
그런데 제 프로젝트에선 이미 DataSource 타입의 빈을 3개 만들었으니, 어떤 DataSource를 AutoConfiguration이 사용해야할지 모르는 문제였던 겁니다.
public class DataSourceAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@Conditional(EmbeddedDatabaseCondition.class)
// 기본적으로 사용자 빈이 자동설정 빈보다 먼저 등록되게 되는데,
// (아래) DataSource 빈이 등록되어있지 않은 경우에만
@ConditionalOnMissingBean({DataSource.class, XADataSource.class})
// 아래 설정클래스를 활성화하겠다는 뜻이다.
@Import(EmbeddedDataSourceConfiguration.class)
protected static class EmbeddedDatabaseConfiguration {
}
...
}// 그 설정 클래스의 내부에 들어가보면
@EnableConfigurationProperties(DataSourceProperties.class)
public class EmbeddedDataSourceConfiguration implements BeanClassLoaderAware {
private ClassLoader classLoader;
@Override
public void setBeanClassLoader(ClassLoader classLoader) {
this.classLoader = classLoader;
}
// DataSourceProperties를 기반으로 Bean을 자동생성하는 코드가 들어있다.
// 즉, DataSource 빈을 사용자가 등록하지 않는다면 스프링의 자동설정 기능이 알아서 등록한다는 것이다.
@Bean(destroyMethod = "shutdown")
public EmbeddedDatabase dataSource(DataSourceProperties properties) {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseConnection.get(this.classLoader).getType())
.setName(properties.determineDatabaseName()).build();
}
}그럼 위에서 제가 만든 최종 DataSource를 @Primary로 지정하면, DataSourceAutoConfiguration에서 해당 DataSource 빈 1개를 기준으로 자동설정을 진행함을 이해할 수 있었습니다.
그래서 DataSourceAutoConfiguration을 다시 활성화시킨 뒤 DataSource를 @Primary로 지정해주었고, 정상적으로 작동하는 것을 확인했습니다.
Slave 서버 스케일업
처음엔 master와 slave 서버 모두 1vCPU / 2GB RAM으로 구성했는데, slave 서버의 CPU 이용률이 포화되어 8vCPU 8GM RAM으로 올려주었더니 CPU 이용률이 188%에 머물렀습니다.
성능 향상
성능 저하의 원인이 DB 병목인줄 모르고 이것저것 시도하며 성능 테스트하다가 레플리케이션을 시도하다보니 레플리케이션 적용 전의 TPS는 잘 모르겠지만, 마지막으로 TPS를 쟀을 때 793이었는데, 레플리케이션 후에 측정했을 때 4061로 크게 상승했습니다.
커넥션풀 조정
지금까지는 커넥션풀을 임의로 300으로 지정하고 진행했는데, 이미 최적인지 모르겠고, master DB 서버와 slave DB 서버에 필요한 커넥션풀 크기도 다를 것 같아서 여러가지로 진행해보았습니다.
| master CP | slave CP | TPS |
|---|---|---|
| 100 | 300 | 2894 |
| 200 | 200 | 1806 |
| 300 | 300 | 4096 ✨ |
| 350 | 350 | 3951 |
| 300 | 400 | 3939 |
master와 slave 모두 커넥션풀 크기를 300으로 했을 때 제일 높은 TPS를 얻을 수 있었습니다.
