성능테스트를 통한 서버 튜닝으로 핵심 요청 TPS 239 -> 4292 (스케일업 아웃, 커넥션풀, 스레드풀, 레플리케이션) 🔥
담배200 : 공동 편집과 권한 관리를 지원하는 담배 검수 도구
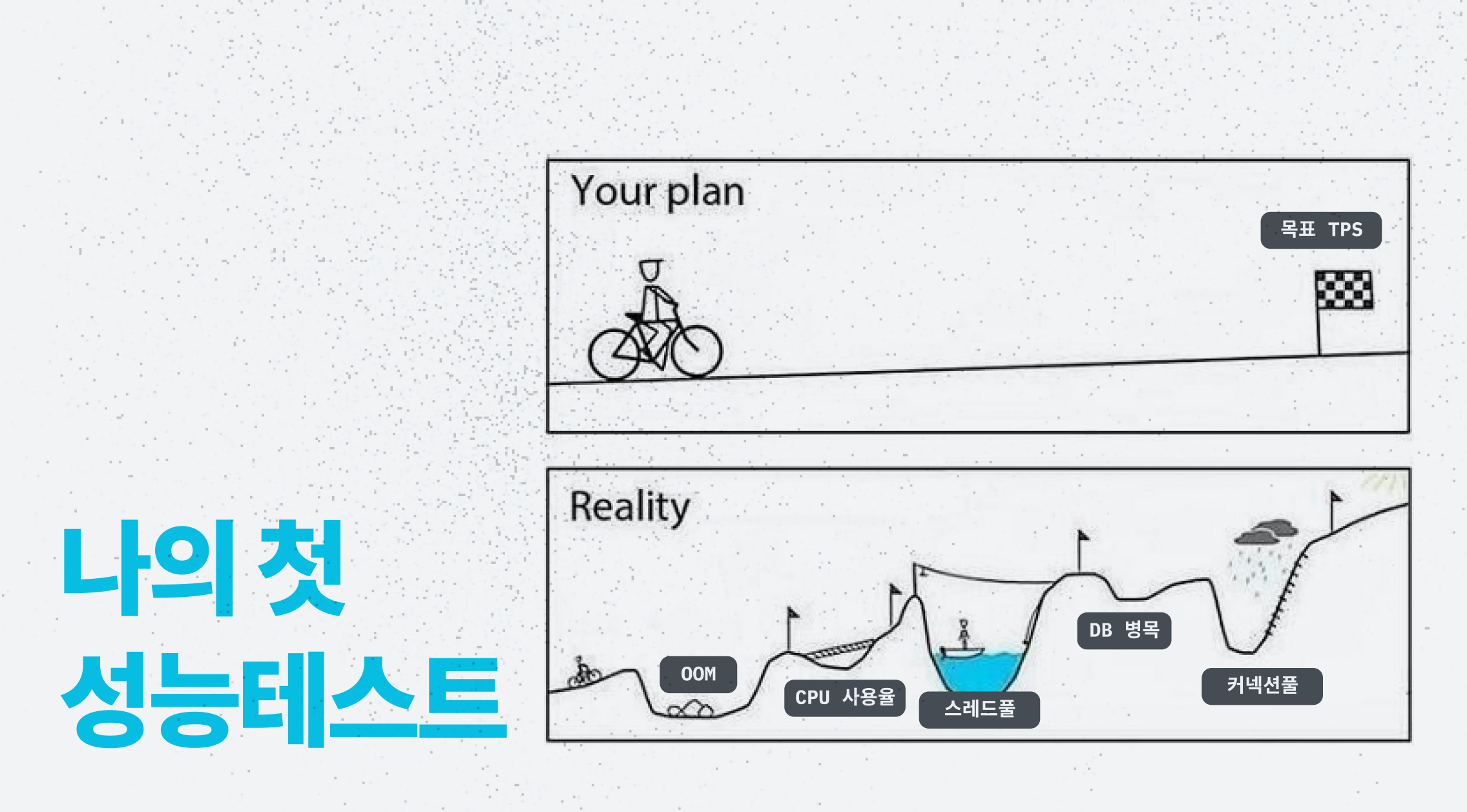
요약
목표하는 트래픽을 감당하기 위해 목표 TPS를 설정하고, jmeter로 소켓 메시지 부하를 생성해 pinpoint로 서버를 모니터링하거나 힙덤프를 둘러보면서 TPS나 CPU 이용률이 적은 이유, 메모리가 부족한 이유를 고민해보았습니다. TPS를 올리기 위해 각 서버들을 스케일 업/아웃하고, 커넥션풀과 스레드풀을 조정하고, 레플리케이션함으로써 핵심 요청의 tps를 목표치인 2080보다 훨씬 높은 4292까지 끌어올렸습니다. 응답시간도 평균적으로 250ms로 만족할만한 속도였습니다. 이 경험을 통해 스레드풀이 무작정 커도 좋지 않음을 느끼게되었고, 성능테스트할 때 WAS 뿐 아니라 다른 서버들의 리소스 이용률을 매번 모니터링하는 게 병목의 원인을 빨리 찾는 방법임을 알게되었습니다.
순서 현 상태 생각 조치 0 최소 서버 스펙
vUser2001 239tps "처리율이 너무 낮네" WAS 1개 → 3개 2 697tps
CPU 이용률 25%"CPU 이용률이 낮은 게 부하가 너무 적어서 그런건가?" vUser 200 → 400 3 793tps (큰 차이 없음) "스레드풀이 너무 적어서 요청을 받아내지 못하는건가?" 스레드풀 200 → 1000 4 차도 없음 "부하를 더 올려야하나?" vUser 400 → 800 5 차도 없음 "DB 커넥션이 적어서 병목이 발생했나?" 커넥션풀 300 6 CPU 이용률 20% → 50%
첫 GC 시간 10분 → 40분"메모리가 한계까지 차는데 왜 안 해제되지?" 스레드덤프 검사 7 스레드풀 자체가 메모리를 많이 차지하는 걸 발견 "아 스레드풀을 너무 크게 설정해서 그렇구나" 스레드풀 1000 → 500 8 WAS CPU 이용률 50% → 70%
메모리는 계속 참"아 메모리 자체가 작은 걸수도 있겠다!" 메모리 4GB → 16GB 9 메모리 일정 수준에서 유지됨 "CPU가 아직 좀 여유로운데, 부하를 높여볼까? vUser 800 → 1200 10 차도 없음 "mySQL 서버 CPU 이용률이 94%네?" mySQL 레플리케이션 11 master DB CPU 30%
slave DB CPU 94%"slaveDB가 바쁘네. 스케일업해주자" slave DB 1vCPU 2GB RAM
→ 8vCPU 8GB RAM12 4061tps "DB 서버의 커넥션풀 크기가 과연 이게 최적일까?" 다양한 커넥션풀 크기로 성능테스트 13 커넥션풀 300으로 고정 "nginx CPU 이용률이 95%네?" nginx 1vCPU → 2vCPU
최대커넥션 1024 → 204814 4292tps
평균응답시간 250ms
문제
앱의 기능을 모두 구현하긴 했지만, 이 서버가 예상 트래픽을 감당할 수 있을지가 의문이었습니다. 그래서 예상 트래픽을 정하고 성능테스트를 통해 목표 TPS를 달성할 수 있도록 튜닝했습니다.
성능테스트를 통한 튜닝을 안해보셨다면 이 글을 한 번 훑어보시면서, 문제를 찾고 해결하는 과정을 간접체험 해보시면 좋겠습니다.
목표 지표 구하기
| 이용 시간 | DAU | 한 사람당 요청 수 | 피크 이용률 | 평균 RPS | 피크 RPS | 평균 vUser | 피크 vUser |
|---|---|---|---|---|---|---|---|
| 오전 12 ~ 6시 | 5만 | 300 | 3 | 694 | 2082 | 347 | 1200 |
전국에 편의점이 5만여개가 있고, 1명씩 담배검수를 위해 이 서비스를 사용한다고 가정하였을 때 예상 DAU는 5만명입니다.
담배 목록 안엔 약 200개의 담배 항목이 있는데 그걸 모두 수정하니 기본적으로 200개의 요청을 보내게 되고, 여유분까지 해서 하루에 한 사람당 300개의 요청을 보낸다고 가정했습니다.
그렇게 가정했을 때 5만명이 보내는 평균 rps는 (5만명 * 300요청) / 6시간 = 694rps입니다. 피크 이용률 3이라고 가정했을 때 피크시간대에 필요한 처리율은 2082rps입니다.
vUser는 rps * (응답시간) 공식을 사용해 평균 vUser 수와 피크 시간대에서의 vUser 수를 결정했습니다.
핵심 요청 정의
이 앱은 담배 검수를 위해 우리 가게 200여개의 담배들의 재고 갯수를 입력하는 것이 주된 요청이기에, 그 소켓 요청을 핵심 테스트 대상으로 정했습니다.
부하, 모니터링 시스템 구축
부하 생성기는 소켓 테스팅이 용이한 Jmeter를, 모니터링 툴은 스택 트레이싱이 가능한 Pinpoint를 사용했습니다.
최소 스펙으로 시작
위와 같은 스펙으로 처음엔 구성했습니다. pinpoint와 jmeter는 성능이 높아야하기 문제없이 작동하기 때문에 8vCPU 8GM MEM의 높은 스펙으로 지정해주었고, WAS(ncp-main)는 최소보다는 좋은 스펙인 2vCPU 4GB RAM, 나머지는 최소 스펙인 1vCPU 2GB MEM으로 시작했습니다.
처리가 느려 스케일 아웃하다
200vUser로 테스트를 해보니 239rps가 나왔습니다. 목표 RPS인 2082rps보다 너무 낮아 WAS를 1개에서 3개로 늘려주었더니 tps가 239rps에서 697rps로 늘었습니다.
스레드풀과 커넥션풀을 늘리다
이전 테스트에서 WAS의 CPU 이용률이 25%정도로 여유로운 모습을 보여서, vUser를 200에서 400으로 늘려보았지만 tps는 697에서 793으로 늘 뿐 큰 변화가 없었습니다.
[vUser 200]
[vUser 400]
Tomcat 스레드풀이 적어 요청을 받아내지 못하는 건가 싶어 Tomcat 스레드풀도 올려보고, 부하가 적어서 CPU 이용률이 낮은건가 싶어 vUser를 더 올려보았지만 결과는 마찬가지였습니다.
마지막으로 들었던 생각이 커넥션풀이 적어서 DB에서 병목이 발생해 스레드들이 대기상태로 있기 때문에 CPU 이용률이 낮은게 아닐까 싶어 커넥션풀을 300으로 늘려주었더니 CPU 이용률이 50% 정도로 올랐습니다. 메모리 효율도 올라 기존엔 10분만에 GC가 일어났는데 커넥션풀을 WAS별로 300개로 늘리니 40분만에 GC가 일어나는 걸 볼 수 있었습니다.
힙덤프를 보고 스레드풀을 줄이고 메모리를 스케일업하다
그러나 여전히 메모리에 문제가 있었습니다. 메모리가 빠르게 차다가 GC가 일어나며 처리율이 급격히 떨어지는 문제입니다. ‘왜 할당된 메모리가 해제되지 않을까?’하는 생각으로, 어떤 메모리가 할당되고 해제되지 않는지 보기 위해 힙덤프를 분석해보기로 했습니다.
이클립스의 MAT을 통해 힙덤프를 분석해보았을 때, threadPoolExecutor의 크기가 가장 크게 나타났습니다. 아무래도 이전의 테스트에서 스레드풀의 크기를 1000으로 설정한 게 너무 커서, 각 스레드에 대한 메모리들을 계속 쥐고있다보니 메모리 공간이 부족한게 아닌가 싶었습니다.
[threadPoolExecutor에서 너무 많은 메모리를 잡고 있다]
그래서 스레드풀을 1000에서 500으로 줄였는데, WAS의 CPU 사용량은 70%정도로 여유로운데 여전히 메모리가 빨리 차는 문제가 있었습니다.
아무래도 CPU를 최대로 이용하기 위해서는 스레드풀을 많이 써야하기는 한데, 그러려면 메모리도 더 많아야한다는 결론에 도달했습니다. 그래서 WAS의 메모리를 4GB에서 16GB로 대폭 올려주었습니다. 결국 메모리 이용량은 일정 수준에서 멈추면서 훨씬 여유로워졌습니다.
mysql 레플리케이션
WAS의 메모리를 4GB에서 16GB로 올려주었음에도 CPU 이용률에는 큰 차도가 없었습니다. 부하가 적은건가 싶어 800vUser에서 1200vUser로 올려주었는데도 차도가 없었습니다.
nginx에 문제가 있는게 아닐까 싶어서 nginx 서버를 보았더니 CPU를 거의 90% 사용중이었습니다. mysql 서버를 보아도 94%를 사용중이었습니다. 혹시 몰라 redis 서버도 보았지만 5%의 이용률로 굉장히 여유로웠습니다.
nginx는 아직 좀 여유롭다 싶어도 mysql의 경우 병목이 일어나고 있음을 바로 느낄 수 있었습니다.
[nginx 서버]
[mysql 서버]
[redis 서버]
MySQL 서버를 master와 slave의 2개 서버로 레플리케이션 하고 서버에 맞게 스펙을 조정하면 DB 병목을 해결할 수 있겠다고 생각했습니다. 처음엔 master와 slave 서버의 스펙을 동일하게 했지만, slave 서버가 좀 더 CPU를 많이 사용하기 때문에 스펙을 더 올려주었습니다. (8vCPU 8GB RAM)
레플리케이션의 결과로 평균 4061rps가 나왔습니다.
커넥션풀 조정
지금까지는 커넥션풀을 임의로 300으로 지정하고 진행했는데, 이미 최적인지 모르겠고, master DB 서버와 slave DB 서버에 필요한 커넥션풀 크기도 다를 것 같아서 여러가지로 진행해보았습니다.
| master CP | slave CP | TPS |
|---|---|---|
| 100 | 300 | 2894 |
| 200 | 200 | 1806 |
| 300 | 300 | 4096 ✨ |
| 350 | 350 | 3951 |
| 300 | 400 | 3939 |
master와 slave 모두 커넥션풀 크기를 300으로 했을 때 제일 높은 TPS를 얻을 수 있었습니다.
nginx 스케일업
nginx의 CPU 이용량이 100%에 가까워 nginx 서버를 1vCPU 2GB에서 2vCPU 2GB로 바꾸니 CPU 이용률이 174%가 되어 딱 좋은 수준이 되었습니다.
vUser 수가 1200인데 기본 최대 커넥션 수는 1024개이므로 모든 vUser가 nginx에 커넥션을 맺고있지 못하는 상황이라 생각하고 2048로 넉넉하게 늘려주니 tps가 4096에서 4292로 늘었습니다.
[스케일업 전]
[스케일업 후]
튜닝으로 목표한 수치를 달성하다
[WAS Heap / Non-Heap / CPU]
각 서버들을 스케일 업/아웃하고, 커넥션풀과 스레드풀을 조정하고, 레플리케이션함으로써 핵심 요청의 tps를 목표치인 2080보다 훨씬 높은 4292까지 끌어올렸습니다. 응답시간도 평균적으로 250ms로 만족할만한 속도였습니다. 이 경험을 통해 스레드풀이 무작정 커도 좋지 않음을 느끼게되었고, 성능테스트할 때 WAS 뿐 아니라 다른 서버들의 리소스 이용률을 매번 모니터링하는 게 병목의 원인을 빨리 찾는 방법임을 알게되었습니다.
| 서버 | 스펙 | CPU 이용률 | MEM 이용률 |
|---|---|---|---|
| WAS 3개 | 2vCPU, 16GB RAM | 150% | 50% |
| nginx | 2vCPU, 2GB RAM | 174% | 7% |
| mysql master | 1vCPU 2GB RAM | 51% | 21.3% |
| mysql slave | 8vCPU 8GB RAM | 188% | 5.7% |
| redis | 1vCPU, 2GB RAM | 5.3% | 0.5% |
| jenkins | 1vCPU, 2GB RAM | - | - |
| pinpoint | 8vCPU, 8GB RAM | - | - |
| jmeter | 8vCPU, 8GB RAM | - | - |
개선 과정 정리
| 순서 | 현 상태 | 생각 | 조치 |
|---|---|---|---|
| 0 | 최소 서버 스펙 vUser200 | ||
| 1 | 239tps | "처리율이 너무 낮네" | WAS 1개 → 3개 |
| 2 | 697tps CPU 이용률 25% | "CPU 이용률이 낮은 게 부하가 너무 적어서 그런건가?" | vUser 200 → 400 |
| 3 | 793tps (큰 차이 없음) | "스레드풀이 너무 적어서 요청을 받아내지 못하는건가?" | 스레드풀 200 → 1000 |
| 4 | 차도 없음 | "부하를 더 올려야하나?" | vUser 400 → 800 |
| 5 | 차도 없음 | "DB 커넥션이 적어서 병목이 발생했나?" | 커넥션풀 300 |
| 6 | CPU 이용률 20% → 50% 첫 GC 시간 10분 → 40분 | "메모리가 한계까지 차는데 왜 안 해제되지?" | 스레드덤프 검사 |
| 7 | 스레드풀 자체가 메모리를 많이 차지하는 걸 발견 | "아 스레드풀을 너무 크게 설정해서 그렇구나" | 스레드풀 1000 → 500 |
| 8 | WAS CPU 이용률 50% → 70% 메모리는 계속 참 | "아 메모리 자체가 작은 걸수도 있겠다!" | 메모리 4GB → 16GB |
| 9 | 메모리 일정 수준에서 유지됨 | "CPU가 아직 좀 여유로운데, 부하를 높여볼까? | vUser 800 → 1200 |
| 10 | 차도 없음 | "mySQL 서버 CPU 이용률이 94%네?" | mySQL 레플리케이션 |
| 11 | master DB CPU 30% slave DB CPU 94% | "slaveDB가 바쁘네. 스케일업해주자" | slave DB 1vCPU 2GB RAM → 8vCPU 8GB RAM |
| 12 | 4061tps | "DB 서버의 커넥션풀 크기가 과연 이게 최적일까?" | 다양한 커넥션풀 크기로 성능테스트 |
| 13 | 커넥션풀 300으로 고정 | "nginx CPU 이용률이 95%네?" | nginx 1vCPU → 2vCPU 최대커넥션 1024 → 2048 |
| 14 | 4292tps 평균응답시간 250ms |
마무리
차분하고 차곡차곡 향상시키면서 성능을 개선시킬 줄 알았지만, 실제로 해보니까 성능이 개선되지 않는 원인도 빨리 찾을 수 없었고, 특히 소켓 요청의 성능테스트에 대한 명확한 가이드라인이 없어서 많이 헤맸습니다. 성능테스트를 하면서 많이 헤맸고 어떻게 해야할지 몰라 슬럼프가 심해졌었고 책상에 앉는게 힘들어졌었습니다.
그래도 계속 이렇게 저렇게 알아보고 시도해보고 나니 분명 개선이 있었고, 성능테스트와 튜닝, 모니터링을 직접 해보니 서비스 개발을 바라보는 눈이 한 차원 달라진 것을 느낄 수 있었습니다.

좋은글 감사합니다!