서론
오늘은 캠퍼스팀에서 프로덕션 배포가 있는 날이다. 뭐 대충 develop → main 머지하고 젠킨스 한번 돌리면 잘 되겠지 싶었다. 그래도 조심하면 좋으니 설정파일에 빠진거 없는지 확인하는 정도만 해주면 충분할 것 같았다.
그런데..
마구마구 터지는 에러와 그의 도움 요청..
본론
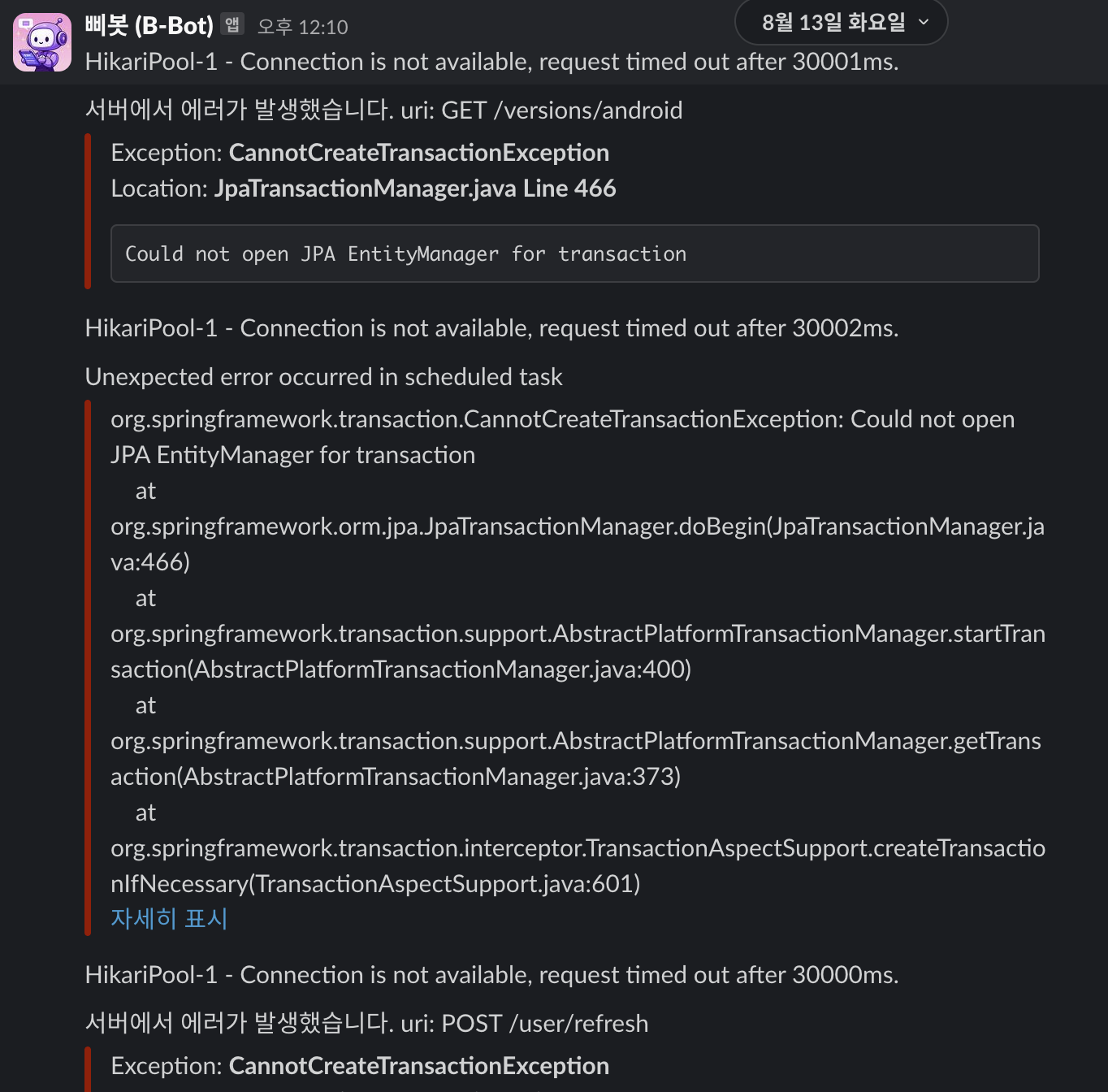
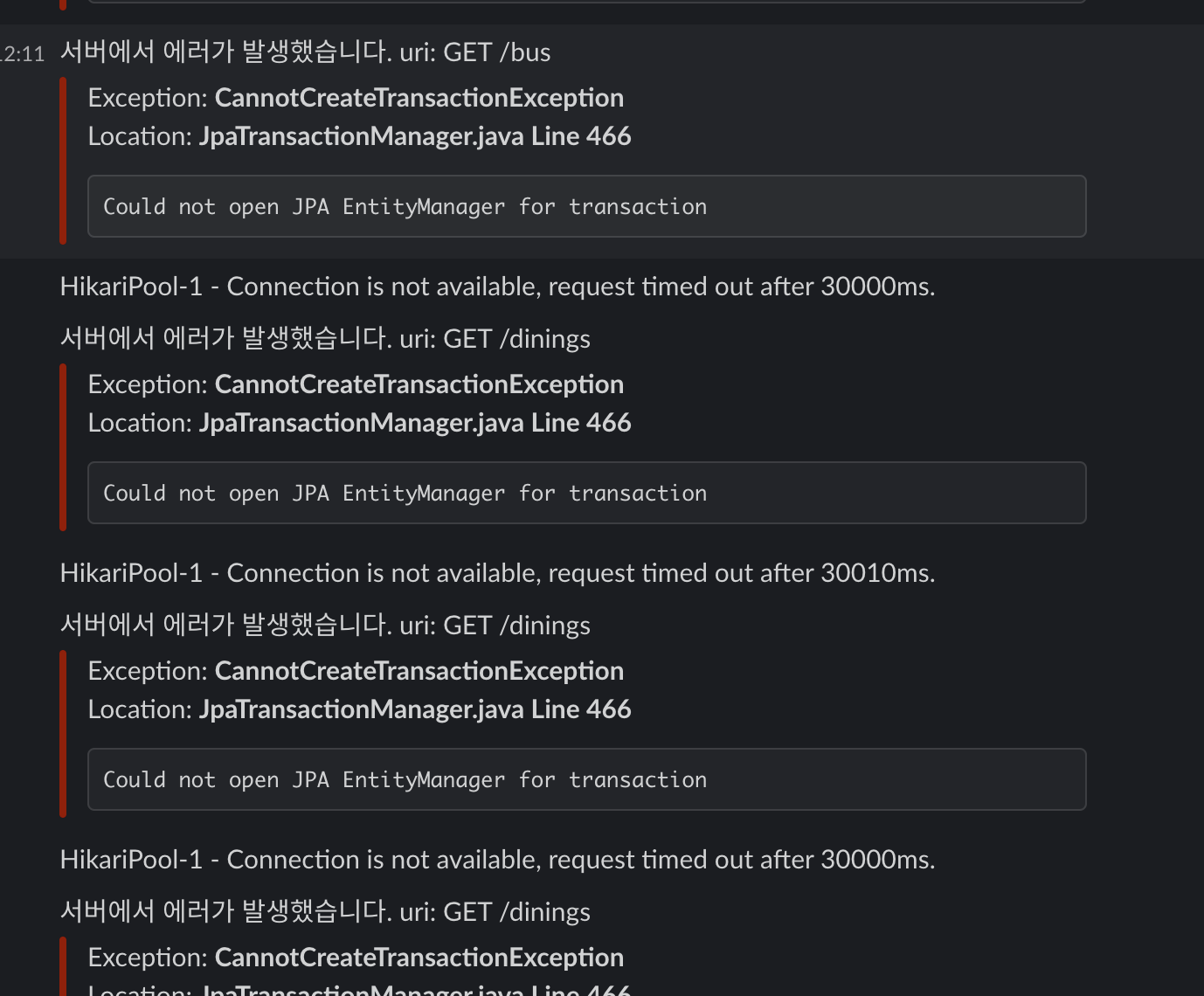
에러 로그를 확인해 보니 대충 DB쪽에서 문제가 생겨서 Connection이 안되는 것 같다. Connection이 안되니 JPA Entity도 다 터지는 것 같다.
해결방안 1 - Docker Swarm Rollback
우리 서비스는 Docker Swarm으로 구성되어 있다. Docker Swarm은 무려 명령어 한줄로 Rollback이 된다는거!
그런데 Rollback을 해도 레플리카가 생성되지 않는다. 혹시 몰라서 Update로 Rollback을 시도해 봤지만 이 역시 되지 않았다.
해결방안 2 - Git Revert후 재배포
Git Revert후 재배포를 하니 서비스가 다시 돌아왔다. 내가 생각한 Revert후 배포했을때 성공한 이유는 다음과 같다.
배포 파이프라인에서
Service를Update하기 전에 선행해서 실행되어야 하는 명령어들이 있었는데 해당 명령어들을 실행하지 않고Update명령어를 단독으로 실행시켜서Update문이 동작하지 않았다. 하지만Git Revert후 재배포를 하게 되면 모든 명령어들이 순차적으로 실행된다.
가설 세우기
- 코드의 문제인가? → 동일한 코드로 테스트 환경에서는 잘 동작 했다. → 코드의 문제일 확률 낮음
- DB의 문제인가? →
DB를 연결하지 못해서JPA Entity들이 모두 터졌다. →DB의 문제일 확률 높음
이렇게 2가지의 가설을 세울 수 있었고 두 번째 가설이 유력하다고 생각해서 검증해보기로 했다.
가설 구체화
가설을 구체화 해볼 수 있는 항목들은 다음과 같다.
flyway실행에서 오류가 터졌는가?Mysql Container에 문제가 있는가?
위와 같이 가설을 구체화해볼 수 있었고 이를 검증하려고 시도해봤다.
가설 검증
flyway 실행에서 오류가 터졌는가?
제일 먼저 프로덕션 DB를 접속해서 flyway_schema_history를 확인해 보니 새로운 flyway버전이 등록되진 않은 것 같다. 혹시 모르니 새로운 버전과 관련되어 있는 table들을 모두 확인해 봤다.
그런데 dining_menus테이블에 price컬럼이 추가되어 있었다.
flyway_schema_history를 보면flyway는 실행되지 않았다.table들을 직접 확인해 보니flyway는 실행되었다.
flyway는 실행되지 않았는데 flyway내용은 반영됐다.. 이해할 수 없는 상황을 구체적으로 확인해 보기 위해서 프로덕션 DB의 SQL실행 로그를 확인해 보기로 했다.
SQL로그 확인하기
동아리원이 로그파일을 확인하기 위해서 Volume경로로 들어가서 로그 파일(binlog.000001)을 vim으로 열었다. 그 파일은 약 900MB정도 의 binary파일이였고 그 파일을 vim으로 여는 순간 서버가 먹통이 됐다..(매니저 노드인데..)
DB서버 다운
Mysql의 로그를 보려다가 매니저노드인 DB Server가 죽었다. DB Server에 있던 Production DB, Stage DB 모두 같이 죽었고, 동시에 Stage서버에 있던 WAS도 같이 터졌다.
DB Server 재부팅
DB Server를 일단 살려야 하기 때문에 재부팅을 했다. 문제는 재부팅을 하면 Docker Container가 모두 없어진다. Docker Compose를 설정해놨다면 DB Container를 간단하게 다시 띄울 수 있겠지만, 지금은 직접 다 띄워줘야 한다. 어차피 이렇게 된거 이전의 방식으로(Blue/Green) 돌아가자는 의사결정을 했다.
Docker Swram은 롤백도 간편하고, 로드밸런싱을 해준다. 하지만Docker Swram배포 파이프라인에 문제가 생긴다면 문제의 원인을 파악하는것이 쉽지 않다.Docker Swram의 인프라는 동아리원 한명이 구축하고 떠난 인프라기 때문에 유지보수 할 사람이 없다.Docker Swram을 학습해서 유지보수 하기에는 인프라의 학습곡선이 높아진다.- 백엔드 트랙원 모두가 유지보수 할 수 있는 인프라구조 이여야 한다.
Blue/Green방식은 이전에 사용했던 방식이고 배포 파이프라인이 간단하다. → 모든 트랙원이 유지보수 할 수 있다.
일단 급한대로 Blue/Green배포를 여러번 해본 갓준호가 2시간 동안 Blue/Green방식으로 원복하여 서비스가 정상적으로 실행될 수 있도록 하였다.
Blue/Green으로 원복
Prod, Stage DB 분리
Production DB의 로그를 보기 위해서 로그 파일을 열어봤는데 DB Server가 터지면서 Stage DB도 같이 내려갔었다. 두 DB가 서로에게 영향을 주고 있는 것이였다. 때문에 Production, Stage DB의 서버를 분리해줬다.
Blue/Green으로 재배포
Git Revert된 Production코드로 재배포를 했고, 성공적으로 배포됐다.
결론
이번에 배포를 하면서 다음과 같은 것들을 배울 수 있었다.
Production,StageDB분리의 필요성- 기술의 고가용성도 중요하지만 그 기술에 대해 유지보수 할 수 있는 사람이 있는지가 더 중요하다.
- 서비스의 규모에 맞는 기술 선정은 중요하다.
- 기능이 많을수록 인프라는 복잡해진다. → 인프라가 복잡해지면 인프라에 대한 전문성이 중요해진다. → 인프라에 대한 전문성이 중요해지면 유지보수할 수 있는 사람이 줄어든다.
이번 배포에서 Blue/Green으로 원복은 했지만 여전히 여러가지 문제가 있다.
Blue/Green으로 급한 불은 껐지만Docker Swram에서 지원하던 강력한 기능인 롤백을 잃었다.- 이번 배포가 실패한 정확한 원인 규명을 하지 못했다.
- DB문제였을 확률이 높았고,
Blue/Green으로 바꾸면서 DB도 다시 구축했다. 하지만 코드 문제였을 가능성을 배제할 수 없다. Git Revert로 코드를 롤백해놓은 상태이고, 만약 코드 문제라면 다시 배포했을 때 또 터질것이다.
- DB문제였을 확률이 높았고,
트랙장이 되고 처음으로 Production이 터졌는데 대처가 많이 미흡했던것 같다. 글을 적다 보니 더 나은 대응 방법이 있었을 것 같다는 생각도 많이 든다. 그래서 그런지 직접 터지면서 배우는게 정말 많은 것 같다.
앞으로 위에서 나왔던 두 가지 문제점들에 대해서 해결해보고자 한다.
