
💡 해당 글은 이코테 2021 강의 몰아보기를 보고 개인적으로 정리한 글입니다. 문제 시 삭제하겠습니다!
🎯 코딩 테스트 개요 및 출제 경향
온라인 저지(Online Judge)
=> 프로그래밍 대회나 코딩 테스트에서 나올 법한 문제를 시험해 보는 온라인 시스템
해외 사이트
| 이름 | 주소 |
|---|---|
| 코드포스(Codeforces) | http://www.codeforces.com |
| 탑코더(TopCoder) | https://www.topcoder.com |
| 릿코드(LeetCode) | https://leetcode.com |
| 코드셰프(CODECHEF) | https:///www.codechef.com |
국내 사이트
| 이름 | 주소 |
|---|---|
| 백준 온라인 저지(BOJ) | https://www.acmicpc.net |
| 코드업(CodeUp) | https://codeup.kr |
| 프로그래머스(Programmers) | https://programmers.co.kr |
| SW Expert Academy | https://swexpertacademy.com |
코딩 테스트 응시자 설문
- "알고리즘 문제 풀이 방식의 코테에서 가장 유리한 프로그래밍 언어"와 "프로그램 개발 방식의 코테에서 가장 유리한 프로그래밍 언어" 설문조사에서
파이썬이 모두 높은 순위를 차지함
온라인 개발 환경 (Python)
오프라인 개발 환경 (Python)
- 파이참(PyCharm)
자신만의 소스코드 관리하기
- 자신이 자주 사용하는 알고리즘 코드를 라이브러리화 하면 좋다!
- 팀 노트 예시
- 요 방법은 강의자분이 강추하신다고 함👀
IT 기업 코딩 테스트 최신 출제 경향
✔️ 물론 2021 기준이라는 것...
-
응시생들에게 2~5시간 가량의 시간을 주어 여러 개의 정해진 알고리즘 문제들을 풀도록 함
-
빈출 유형
- 그리디(쉬운 난이도)
- 구현
- DFS/BFS를 활용한 탐색
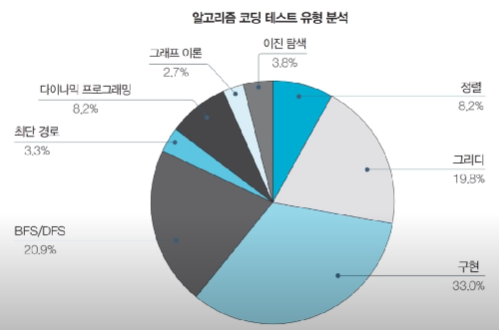
↑ 2016 ~ 2019년에 출제되었던 국내외 주요 기업들 공채에 등장한 알고리즘 유형
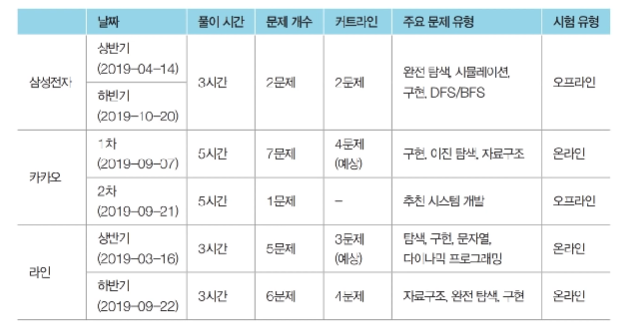
- 다양한 후기 및 복원된 문제를 참고하여 작성된 것으로, 100% 일치하지 않을 수 있다고...
- 완전 탐색, 시뮬레이션 등등이 많은듯
- 삼성전자는 기출 많음
- 카카오는 삼전에 비해서는 유형 다양한 편
- 카카오의 경우 1, 2차가 나누어져 있음
- 카카오, 라인은 문제를 절반 이상 맞히면 합격선
🎯 알고리즘 성능 평가
복잡도(Complexity)
- 시간 복잡도 : 수행 시간
- 공간 복잡도 : 메모리 사용량
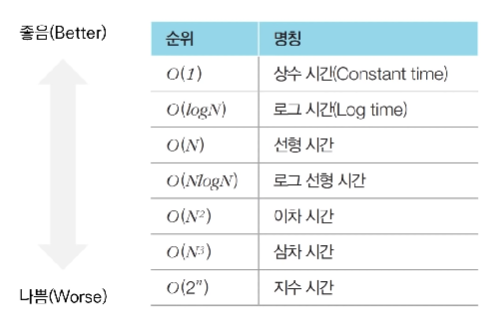
빅오 표기법(Big-O Notation)
- 가장 빠르게 증가하는 항만을 고려하는 표기법
ex) 연산 횟수가 3N^3 + 5N^2 + 1,000,000인 알고리즘이라면, O(N^3)으로 표기됨
알고리즘 설계 Tip
- 일반적으로 CPU 기반의 개인 컴퓨터나 채점용 컴퓨터에서 연산 횟수가 5억을 넘어가는 경우:
- C언어 기준 통상 1~3초 가량의 시간 소요
- Python 기준 통상 5~15초 가량의 시간 소요
(PyPy의 경우 때때로 C언어보다 빠르게 동작할 수 있기 때문에, PyPy를 지원한다면 PyPy로 제출하는 게 시간 복잡도 측면에서 유리할 수 있음)-
코딩 테스트 문제에서 시간 제한은 통상 1~5초 가량이라는 점에 유의
- 혹여 문제에 명시되어 있지 않은 경우, 대략 5초 정도라고 생각하고 푸는 것이 합리적임
요구사항에 따라 적절한 알고리즘 설계하기
- 문제에서 가장 먼저 확인해야 하는 내용은 시간제한(수행시간 요구사항)
- 시간제한이 1초인 문제를 만났을 때, 일반적인 기준은 다음과 같음
- N의 범위가 500인 경우: 시간 복잡도가 `O(N^3)`인 알고리즘을 설계하면 풀이 가능
- N의 범위가 2,000인 경우: 시간 복잡도가 `O(N^2)`인 알고리즘을 설계하면 풀이 가능
- N의 범위가 100,000인 경우: 시간 복잡도가 `O(NlogN)`인 알고리즘을 설계하면 풀이 가능
- N의 범위가 10,000,000인 경우: 시간 복잡도가 `O(N)`인 알고리즘을 설계하면 풀이 가능알고리즘 문제 해결 과정
- 지문 읽기 및 컴퓨터적 사고
- 요구사항(복잡도) 분석
- 문제 해결을 위한 아이디어 찾기
- 소스코드 설계 및 코딩
- 일반적으로 대부분의 문제 출제자들은 핵심 아이디어를 캐치한다면, 간결하게 소스코드를 작성할 수 있는 형태로 문제를 출제한다.
수행 시간 측정 소스코드 예제
import time
start_time = time.time() # 측정 시작
# 프로그램 소스코드
end_time = time.time() # 측정 종료
print("time:", end_time - start_time) # 수행 시간 출력🎯 자료형
실수형
- 파이썬에서는 변수에 소수점을 붙인 수를 대입하면 실수형 변수로 처리됨
- 소수부가 0이거나 정수부가 0인 소수는 0을 생략하고 작성 가능
# 소수부가 0일 때 0을 생략
a = 5.
print(a) # 5.0
# 정수부가 0일 때 0을 생략
a = -.7
print(a) # -0.7지수 표현 방식
- 파이썬에서는 e나 E를 이용한 지수 표현 방식 이용 가능
- e나 E 다음에 오는 수는 10의 지수부를 의미
- ex)
1e9를 입력하면, 10의 9제곱(1,000,000,000)이 됨
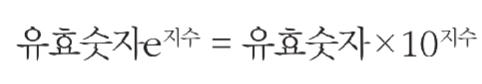
- 지수 표현 방식은 임의의 큰 수를 간결하게 표현하기 위해 자주 사용됨
- 최단 경로 알고리즘에서는 도달할 수 없는 노드에 대해 최단 거리를 무한(INF)로 설정하곤 함
- 이때 가능한 최댓값이 10억 미만이라면, 무한(INF)의 값으로 1e9를 이용할 수 있음
# 1,000,000,000의 지수 표현 방식
a = 1e9
print(a) # 1000000000.0
# 752.5
a = 75.25e1
# 3.954
a = 3954e-3실수형 더 알아보기
- 오늘날 가장 널리 쓰이는 IEEE754 표준에서는 실수형을 저장하기 위해 4바이트, 또는 8바이트의 고정된 크기의 메모리를 할당하므로, 컴퓨터 시스템은 실수 정보를 표현하는 정확도에 한계를 가짐
- 10진수 체계에서는 0.3과 0.6을 더한 값이 0.9로 정확히 떨어지지만, 2진수에서는 0.9를 정확히 표현할 수 있는 방법이 없음
- 컴퓨터는 최대한 0.9와 가깝게 표현하지만, 미세한 오차가 발생하게 됨
a = 0.3 + 0.6
print(a)
if a == 0.9:
print(True)
else:
print(False)출력
0.8999999999999999
False- 개발 과정에서 실수값을 제대로 비교하지 못해서 원하는 결과를 얻지 못할 수도 있음
- 이럴 때는
round()함수를 이용하는 방법이 권장됨 - 예를 들어 123.456을 소수 셋째 자리에서 반올림하려면
round(123.456, 2)라고 작성함
(결과는 123.46)
수 자료형의 연산
- 사칙연산과 나머지 연산자 많이 사용됨
- 파이썬은 나누기 연산자(/)는 나눠진 결과를 실수형으로 반환함
- 파이썬에서 몫을 얻기 위해서는 몫 연산자(//) 사용
- 이외에도 거듭 제곱 연산자(**) 등등 존재
a = 5
b = 3
# 거듭 제곱
print(a ** b) # 125
# 제곱근
print(a ** 0.5) # 2.23606797749979리스트 자료형
- 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형
- C나 Java의
배열기능 및연결 리스트와 유사한 기능도 제공 배열또는테이블로 부르기도 함
- 대괄호(
[]) 안에 원소를 넣어 초기화하며, 쉼표(,)로 원소 구분 - 비어 있는 리스트를 선언하고자 할 때는
list()또는[]를 이용할 수 있음
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0] * n
print(a)리스트 인덱싱
- 리스트의 특정한 원소에 접근하는 것을 인덱싱(Indexing)이라고 함
- 인덱스 값은 "양의 정수", "음의 정수" 모두 가능하고,
음의 정수를 넣으면 원소를 거꾸로 탐색하게 됨
리스트 슬라이싱
- 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(Slicing)을 이용
- 대괄호 안에 콜론(
:)을 넣어서 시작 인덱스와 끝 인덱스 설정 가능 - 끝 인덱스는 실제 인덱스보다 1 더 크게 설정!!
리스트 컴프리헨션 🌟
- 대괄호 안에
조건문과반복문을 적용하여 리스트 초기화 가능
a = [i for i in range(10)]
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]array = [i for i in range(20) if i % 2 == 1]
print(array) # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
array = [i * i for i in range(1, 10)]
print(array) # [1, 4, 9, 16, 25, 36, 49, 64, 81]- 조건문도 포함 가능하다는 것!
- 리스트 컴프리헨션을 이용하면 코드 라인 수를 효율적으로 줄일 수 있음
- 리스트 컴프리헨션은 2차원 리스트를 초기화할 때 효과적으로 사용 가능
- 특히 N x M 크기의 2차원 리스트를 한 번에 초기화 해야 할 때 매우 유용함
array = [[0] * m for _ in range(n)]- 만약 2차원 리스트를 초기화 할 때, 아래와 같이 작성하면 예기치 않은 결과가 나올 수 있음
array = [[0] * m] * n- 위 코드는 전체 리스트 안에 포함된 각 리스트가 "모두 같은 객체"로 인식됨
- 참조값을 복사하는 것과 같기 때문에!
언더바는 언제 사용하나요?
- 반복을 수행하되, 반복을 위한 변수의 값을 무시하고자 할 때(사용하지 않을 때) 언더바(_)를 자주 사용
# 그냥 Hello World 5번 출력하는 로직
for _ in range(5):
print("Hello World")리스트 관련 메소드
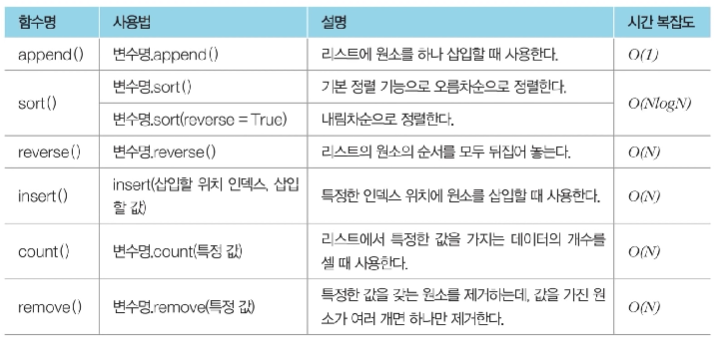
리스트에서 특정 값을 가지는 원소를 모두 제거하기
a = [1, 2, 3, 4, 5, 5, 5]
remove_set = {3, 5} # 집합 자료형
# remove_list에 포함되지 않은 값만을 저장
result = [o for i in a if i not in remove_set]
print(result)문자열 자료형
- 문자열 변수를 초기화할 때는 큰따옴표(
")나 작은따옴표(') 이용 - 문자열 안에 큰따옴표나 작은따옴표를 포함되어야 하는 경우는?
- 전체 문자열을 큰따옴표로 구성하는 경우, 내부적으로 작은따옴표 포함
- 전체 문자열을 작은따옴표로 구성하는 경우, 내부적으로 큰따옴표 포함
- 혹은
백슬래시(\)를 사용하면, 큰따옴표나 작은따옴표를 원하는 만큼 포함시킬 수 있음
문자열 연산
- 문자열 변수에 덧셈(+)을 이용하면, 문자열이 더해져서 연결(Concatenate)됨
- 문자열 변수를 특정 양의 정수와 곱할 경우, 문자열이 그 값만큼 여러 번 더해짐
- 문자열에 대해서도 마찬가지로 인덱싱과 슬라이싱을 이용할 수 있으나, 특정 인덱스 값을 변경할 수는 없음(Immutable)
튜플 자료형
- 리스트와 유사하지만, 다음과 같은 차이가 있음
- 튜플은 한 번 선언된 값을 변경할 수 없음
- 리스트는 대괄호를 이용하지만, 튜플은 소괄호(()) 이용
- 리스트에 비해 상대적으로 공간 효율적
튜플을 사용하면 좋은 경우
- 서로 다른 성질의 데이터를 묶어서 관리해야 할 때
- 최단 경로 알고리즘에서는 (비용, 노드 번호)의 형태로 튜플 자료형을 자주 사용
- 데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때
- 튜플은 변경이 불가능하므로, 리스트와 다르게 키 값으로 사용될 수 있음
- 리스트보다 메모리를 효율적으로 사용해야 할 때
사전 자료형
- 사전 자료형은 키(Key)와 값(Value)의 쌍을 데이터로 가지는 자료형
- 리스트나 튜플이 값을 순차적으로 저장하는 것과 대비됨
- 변경 불가능한(Immutable) 자료형을 키로 사용 가능
- 파이썬의 사전 자료형은 내부적으로 해시 테이블(Hash Table)을 이용하므로, 데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리 가능
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
print(data) # {'사과': 'Apple', '바나나': 'Banana', '코코넛': 'Coconut'}
if '사과' in data:
print("'사과'를 키로 가지는 데이터가 존재합니다.")사전 자료형 관련 메소드
- 키 데이터만 뽑아서 리스트로 이용할 때 :
keys() - 값 데이터만 뽑아서 리스트로 이용할 때 :
values()
집합 자료형
- 중복 허용 X
- 순서 X
- 리스트 또는 문자열을 이용해서 초기화 가능
- 이때
set()함수 사용
- 이때
- 또는 중괄호({}) 안에 각 원소를 콤마(,)를 기준으로 구분하여 삽입함으로써 초기화 가능
- 데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리 가능
집합 자료형의 연산
- 합집합, 교집합, 차집합
a = set([1, 2, 3, 4, 5])
b = set([3, 4, 5, 6, 7])
# 합집합
print(a | b)
# 교집합
print(a & b)
# 차집합
print(a - b)집합 자료형 관련 함수
add(): 새로운 원소 추가update(): 새로운 원소 여러 개 추가remove(): 특정한 값을 가지는 원소 삭제
사전 자료형과 집합 자료형의 특징
- 리스트나 튜플은 순서가 존재하기 때문에, 인덱싱을 통해 값을 얻을 수 있음
- 사전과 집합은 순서가 없기 때문에, 인덱싱을 통해 값을 얻을 수 없음
- 사전의 키(Key) 또는 집합의 원소(Element)를 이용해 O(1)의 시간 복잡도로 조회
🎯 기본 입출력
기본 입출력
- 모든 프로그램은 적절한(약속된) 입출력 양식 가지고 있음
자주 사용되는 표준 입력 방법
input(): 한 줄의 문자열을 입력 받는 함수map(): 리스트의 모든 원소에 각각 특정한 함수를 적용할 때 사용- ex) 공백을 기준으로 구분된 데이터를 입력 받을 때
list(map(int, input().split()))- ex) 공백을 기준으로 구분된 데이터의 개수가 많지 않을 때
a, b, c = map(int, input().split())빠르게 입력 받기
- 사용자로부터입력을 최대한 빠르게 받아야 하는 경우
sys라이브러리에 정의되어 있는sys.stdin.readline()메서드 사용- 단, 입력 후 엔터(Enter)가 줄 바꿈 기호로 입력되므로,
rstrip()메서드와 함께 사용
- 단, 입력 후 엔터(Enter)가 줄 바꿈 기호로 입력되므로,
import sys
# 문자열 입력 받기
data = sys.stdin.readline().rstrip()
print(data)자주 사용되는 표준 출력 방법
- 기본 출력은
print()함수 사용 - 각 변수를 콤마(,)를 이용하여 띄어쓰기로 구분하여 출력 가능
print()는 기본적으로 출력 이후에 줄 바꿈 수행- 줄 바꿈을 원치 않는 경우, 'end' 속성 이용 가능
a = 1
b = 2
print(a, b)
print(7, end=" ")
print(8, end=" ")
answer - 7
print("정답은 " + str(answer) + "입니다.")1 2
7 8 정답은 7입니다.f-string 예제
- 파이썬 3.6부터 사용 가능하며, 문자열 앞에 접두사
f를 붙여 사용 - 중괄호 안에 변수명을 기입하여, 간단히 문자열과 정수를 함께 넣을 수 있음
answer = 7
print(f"정답은 {answer}입니다.")- JS의 ${} 문법으로 생각하면 될듯?
🎯 조건문과 반복문
- 잘 아는 내용들은 생략...
들여쓰기
- 파이썬은 코드의 블록(Block)을 들여쓰기(Indent)로 지정
- 탭을 사용하는 쪽과 2. 공백 문자(space)를 여러 번 사용하는 쪽이 있음
- 파이썬 스타일 가이드라인에서는, 4개의 공백 문자를 사용하는 것을 표준으로 설정하고 있음
비교 연산자
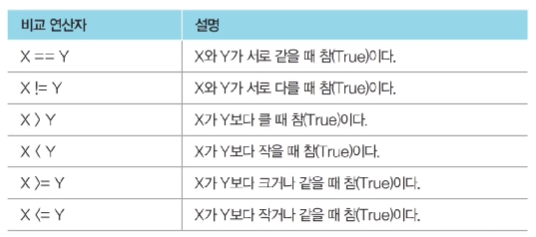
논리 연산자

- 파이썬은
&&,||,!안 쓰고and,or,not쓴다는 것 주의
파이썬 기타 연산자

- 리스트, 튜플, 문자열, 딕셔너리 모두에서 사용 가능
파이썬의 pass 키워드
- 아무것도 처리하고 싶지 않을 때
pass키워드 사용 - ex) 디버깅 과정에서 일단 조건문의 형태만 만들어 놓고 조건문을 처리하는 부분은 비워놓고 싶은 경우
score = 85
if score >= 80:
pass # 나중에 작성할 부분
else:
print('성적인 80점 이하입니다.')조건문 간소화
- 조건문에서 실행될 소스코드가 한 줄인 경우, 굳이 줄 바꿈 하지 않고도 간략하게 표현 가능
score = 85
if score >= 80: result = "Success"
else: result = "Fail"- 조건부 표현식(Conditional Expression)은 if ~ else문을 한 줄에 작성할 수 있도록 해 줌
score = 85
result = "Success" if score >= 80 else "Fail"- 조건이 가운데 들어간다는 것 주의(참값이 왼쪽, 거짓값이 오른쪽)
파이썬 조건문 내에서의 부등식
- 다른 프로그래밍 언어와 다르게 파이썬은 조건문 안에서 수학의 부등식 그대로 사용 가능
- 예를 들어, 다른 프로그래밍 언어면
x > 0 and x < 20이렇게 작성해야 하는데 파이썬에서는 그냥0 < x < 20으로 작성해도 됨
반복문: for문
- 연속적인 값을 차례대로 순회할 때는
range()를 주로 사용 range(시작 값, 끝 값 + 1)- 인자를 하나만 넣으면 자동으로 시작 값은 0이 됨
🎯 함수의 람다 표현식
함수 정의하기
def 함수명(매개변수):
실행할 소스코드
return 반환 값global 키워드
global키워드로 변수를 지정하면 해당 함수에서는 지역 변수를 만들지 않고, 함수 바깥에 선언된 변수를 바로 참조하게 됨
a = 0
def func():
global a
a += 1
for i in range(10):
func()
print(a) # 10여러 개의 반환 값
- 파이썬에서 함수는 여러 개의 반환 값을 가질 수 있음
def operator(a, b):
add_var = a + b
subtract_var = a - b
multiply_var = a * b
divide_var = a / b
return add_var, subtract_var, multiply_var, divide_var
a, b, c, d = opeartor(7, 3)- 여러 개의 값이 한 번에 묶이는 것을 엄밀히 말하면 "패킹"이라고 함
- 이 값을 차례대로 특정 변수에 담는 것을 "언패킹"이라고 함
람다 표현식
- 특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다는 점이 특징
- 한 번 사용하고 말 로직을 굳이 함수로 정의하지 않고 싶을 때 사용 가능
def add(a, b):
return a + b
# 일반적인 add() 메서드 사용
print(add(3, 7))
# 람다 표현식으로 구현한 add() 메서드
print((lambda a, b: a + b)(3, 7))람다 표현식 예시: 내장 함수에서 자주 사용되는 람다 함수
array = [('홍길동', 50), ('이순신', 32), ('아무개', 74)]
def my_key(x):
return x[1]
print(sorted(array, key=my_key))
print(sorted(array, key=lambda x: x[1]))- 점수순으로 학생 정보 정렬
람다 표현식 예시: 여러 개의 리스트에 적용
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = map(lambda a, b: a + b, list1, list2)
print(list(result))🎯 실전에서 유용한 표준 라이브러리
- 내장 함수 : 기본 입출력 함수부터 정렬 함수까지 기본적인 함수들 제공
- itertools : 파이썬에서 반복되는 형태의 데이터를 처리하기 위한 유용한 기능들 제공
- 특히 "순열"과 "조합" 라이브러리는 코테 완전탐색 문제에서 자주 사용됨
- heapq : 힙(Heap) 자료구조 제공
- 일반적으로 "우선순위 큐" 기능을 구현하기 위해 사용됨
- bisect : 이진 탐색(Binary Search) 기능 제공
- collections: 덱(deque), 카운터(Counter) 등의 유용한 자료구조 포함
- math : 필수적인 수학적 기능 제공
- 팩토리얼, 제곱근, 최대공약수(GCD), 삼각함수 관련 함수부터 파이(pi)와 같은 상수 포함
자주 사용되는 내장 함수
# sum()
result = sum([1, 2, 3, 4, 5])
# min(), max()
min_result = min(7, 3, 5, 2)
max_result = max(7, 3, 5, 2)
# eval()
result = eval("(3+5)*7")eval()은 사람이 이해할 수 있는 수식 형태의 값을 실제 수 형태로 반환해주는 함수
# sorted()
result = sorted([9, 1, 8, 5, 4])
reverse_result = sorted([9, 1, 8, 5, 4], reverse=True)
# sorted() with key
array = [('홍길동', 35), ('이순신', 75), ('아무개', 50)]
result = sorted(array, key=lambda x: x[1], reverse=True)순열과 조합
- 모든 경우의 수를 고려해야 할 때
- 완전탐색으로 될지 안 될지를 가늠할 때 유용하게 사용한다고 함
- 순열 : 서로 다른 n개에서 서로 다른 r개를 선택하여 일렬로 나열하는 것
{'A', 'B', 'C'}에서 3개를 선택하여 나열하는 경우:ABC,ACB,BAC,BCA,CAB,CBA
- 조합 : 서로 다른 n개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
{'A', 'B', 'C'}에서 순서를 고려하지 않고 2개를 뽑는 경우:AB,AC,BC
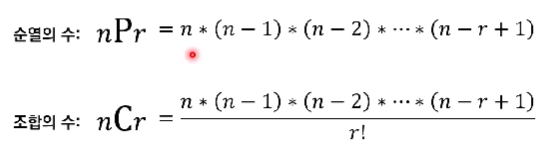
순열
from itertools import permutations
data = ['A', 'B', 'C']
result = list(permutations(data, 3))
print(result)[('A', 'B', 'C'), ('A', 'C', 'B'), ('B', 'A', 'C'), ('B', 'C', 'A'), ('C', 'A', 'B'), ('C', 'B', 'A')]조합
from itertools import combinations
data = ['A', 'B', 'C']
result = list(combinations(data, 2))
print(result)[('A', 'B'), ('A', 'C'), ('B', 'C')]Counter
collections라이브러리의Counter는 등장 횟수를 세는 기능을 제공함- 리스트와 같은 반복 가능한(iterable) 객체가 주어졌을 때, 내부의 원소가 몇 번씩 등장했는지를 알려줌
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(counter['blue']) # 'blue'가 등장한 횟수 출력
print(counter['green']) # 'green'이 등장한 횟수 출력
print(dict(counter)) # 사전 자료형으로 반환3
1
{'red': 2, 'blue': 3, 'green': 1}최대 공약수와 최소 공배수
import math
# 최소 공배수(LCM)을 구하는 함수
def lcm(a, b):
return a * b // math.gcd(a, b)
a = 21
b = 14
print(math.gcd(21, 14)) # 최대 공약수(GCD) 계산
print(lcm(21, 14)) # 최소 공배수(LCM) 계산7
42- 최대 공약수는
math라이브러리의gcd()함수 사용하면 되고, 최소 공배수는 그gcd()함수를 이용하여 최소 공배수 공식에 따라 함수 작성하면 됨

쉽게만살아가면재미없어빙고