
01. 데이터 분석과 통계
1.1 데이터 분석에 있어 통계가 중요한 이유
- 데이터를 이해하고 해석하는 데 중요한 역할
- 데이터를 요약하고 패턴 발견
- 추론을 통해 결론 도출에 도움
🍀 정리: 통계를 이용하여 데이터 기반의 의사결정을 내릴 수 있음!
-> 통계를 활용한 데이터 분석은 필수임
1.2 기술통계와 추론통계
데이터 종류
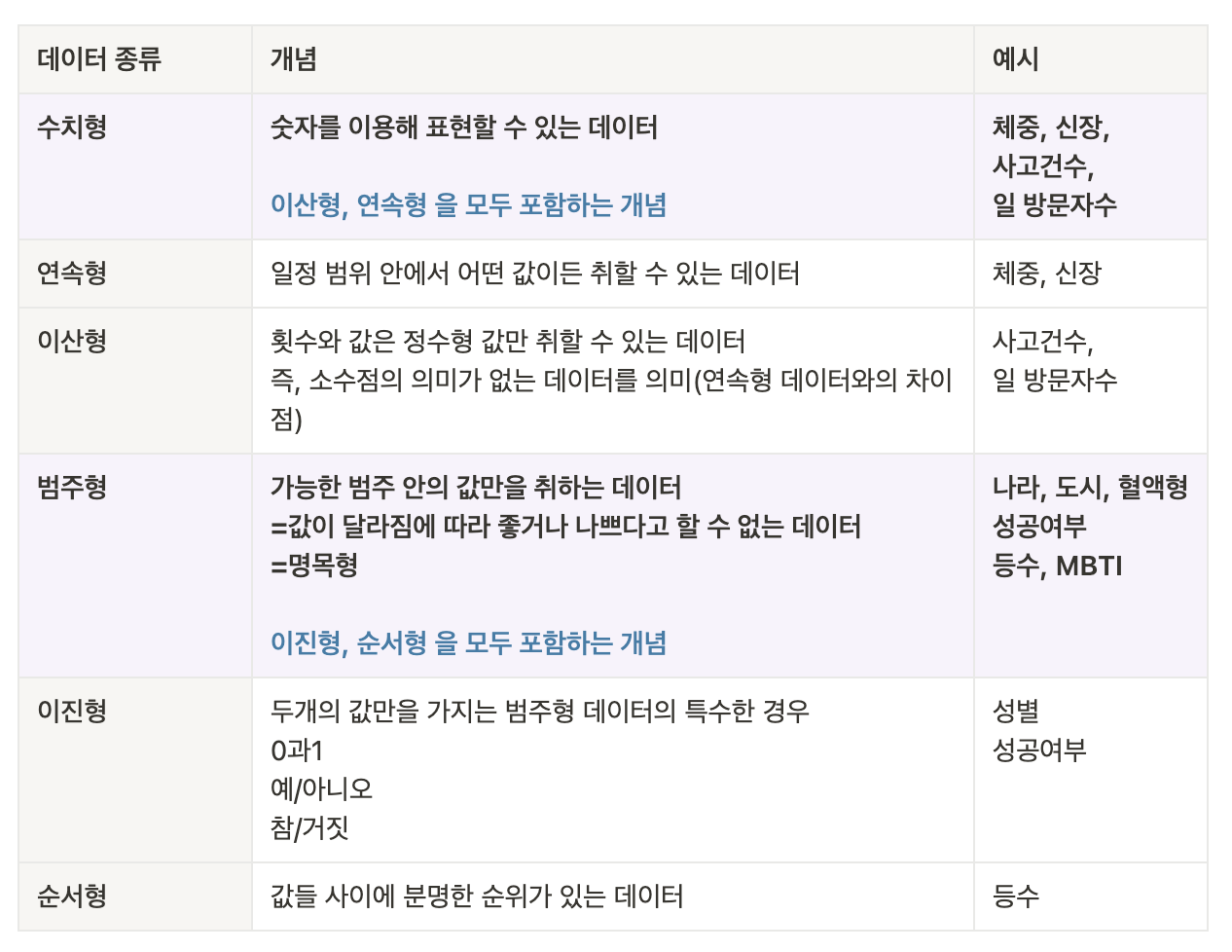
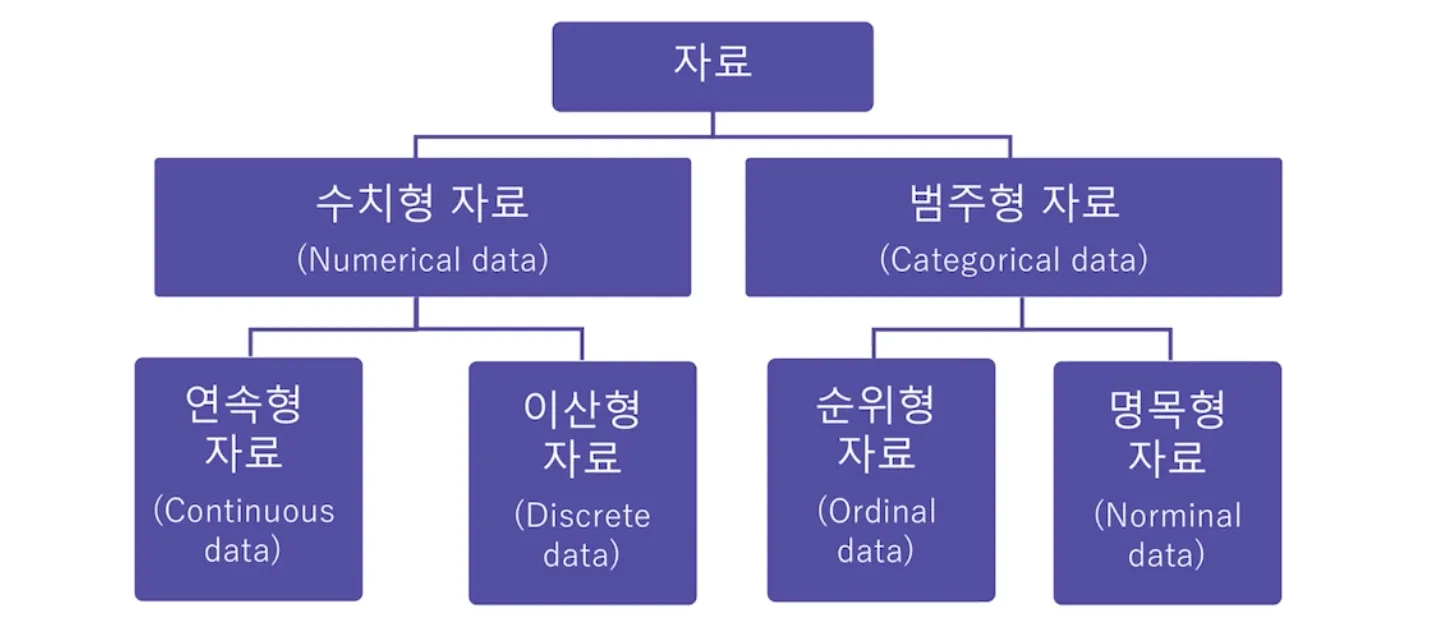
기술통계
데이터를 요약하고 설명하는 통계 방법
- 주로 평균, 중앙값, 분산, 표준편차를 사용
-> 즉, 데이터를 특정 대표값으로 요약 - 데이터의 대략적인 특징을 간단하고 쉽게 알 수 있음
- 주의🚨 : 데이터 중 이상치가 존재할 수 있기 때문에, 데이터의 모든 부분을 확인 할 수 있는 것은 아님!!
기술통계 관련 용어 정리
-
평균 (Mean)
데이터의 대표값으로, 모든 데이터를 더한 후 데이터의 개수로 나누어 계산
-> 데이터의 일반적인 경향 파악에 유용 -
중앙값(Median)
데이터셋을 크기 순서대로 정렬했을 때 중앙에 위치한 값
-> 이상치에 영향을 덜 받기 때문에 데이터의 중심 경향을 나타내는 또 다른 방법 -
분산(Variance)
데이터 값들의 평균으로부터 얼마나 떨어져 있는지 나타내는 척도
(각 데이터 값에서 평균을 뺀 값을 제곱한 후, 모두 더해서 데이터 개수로 나눔)

-> 분산이 클수록 데이터가 넓게 분포, 분산이 작으면 데이터가 평균에 몰려 있음
-
표준편차(Standard Deviation)
데이터 값들이 평균에서 얼마나 떨어져 있는지 나타내는 척도, 분산의 제곱근을 취해서 계산
-> 분산과 데이터 분포도 사이의 관계 그대로 가짐 -
표준편차와 분산의 관계
분산은 데이터의 값과 평균의 차이를 제곱하여 평균을 낸 값
-> 제곱 단위
표준 편차는 분산에다가 다시 제곱근을 취함
-> 원래 데이터 단위🍀 분산보다는 표준 편차가 데이터 단위와 동일하기 때문에 훨씬 직관적임
추론통계
표본 데이터를 통해 모집단의 특성을 추정하고 가설을 검정하는 통계 방법
- 주로 신뢰구간, 가설검정 등을 사용
-> 즉, 데이터의 일부를 가지고 데이터 전체를 추정하는 것이 핵심
추론통계 관련 용어 정리
-
신뢰구간 (COnfidence Interval)
모집단의 평균이 특정 범위 내에 있을 것이라는 확률
일반적으로 95% 신뢰구간 사용 -> "모집단 평균이 95% 확률로 이 구간 내에 있음" -
가설검정 (Hypothesis Testing)
모집단에 대한 가설을 검증하기 위해 사용
귀무가설(H0) : 검증하고자 하는 가설이 틀렸음을 나타내는 기본 가설 (변화가 없다, 효과가 없다 등)
대립가설(H1) : 귀무가설의 반대의 가설, 주장하는 바를 나타내는 가설(변화가 있다, 효과가 있다 등)
-> p.vaule를 통해 귀무가설을 기각할 지 여부를 결정함
기술통계 vs 추론통계 예시
- 기술통계 : 회사의 매출 데이터를 요약하기 위해 평균 매출, 매출의 표준편차 등을 계산
- 추론통계: 일부 고객의 설문조사를 통해 전체 고객의 만족도를 추정
1.3 다양한 분석 방법
위치추정
- 데이터의 중심을 확인하는 방법
- 평균, 중앙값이 대표적
- df['~~'].mean()
- df['~~'].median()
ex) 학생들의 시험 점수에서 평균 점수, 중간 점수 계산
# 데이터 분석에서 자주 사용되는 라이브러리
import pandas as pd
# 다양한 계산을 빠르게 수행하게 돕는 라이브러리
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
# 시각화 라이브러리2
import seaborn as sns
data = [85, 90, 78, 92, 88, 76, 95, 89, 84, 91]
mean = np.mean(data)
median = np.median(data)
print(f"평균: {mean}, 중앙값: {median}")변이추정
- 데이터들이 서로 얼마나 다른지 확인하는 방법
- 분산, 표준편차, 범위(최대-최소) 사용
ex) 매출 데이터의 변이를 분석하여 비즈니스의 안정성 평가
(위에 데이터 사용한다고 가정)
variance = np.var(data)
std_dev = np.std(data)
data_range = np.max(data) - np.min(data)
print(f"분산: {variance}, 표준편차: {std_dev}, 범위: {data_range}")데이터 분포 탐색
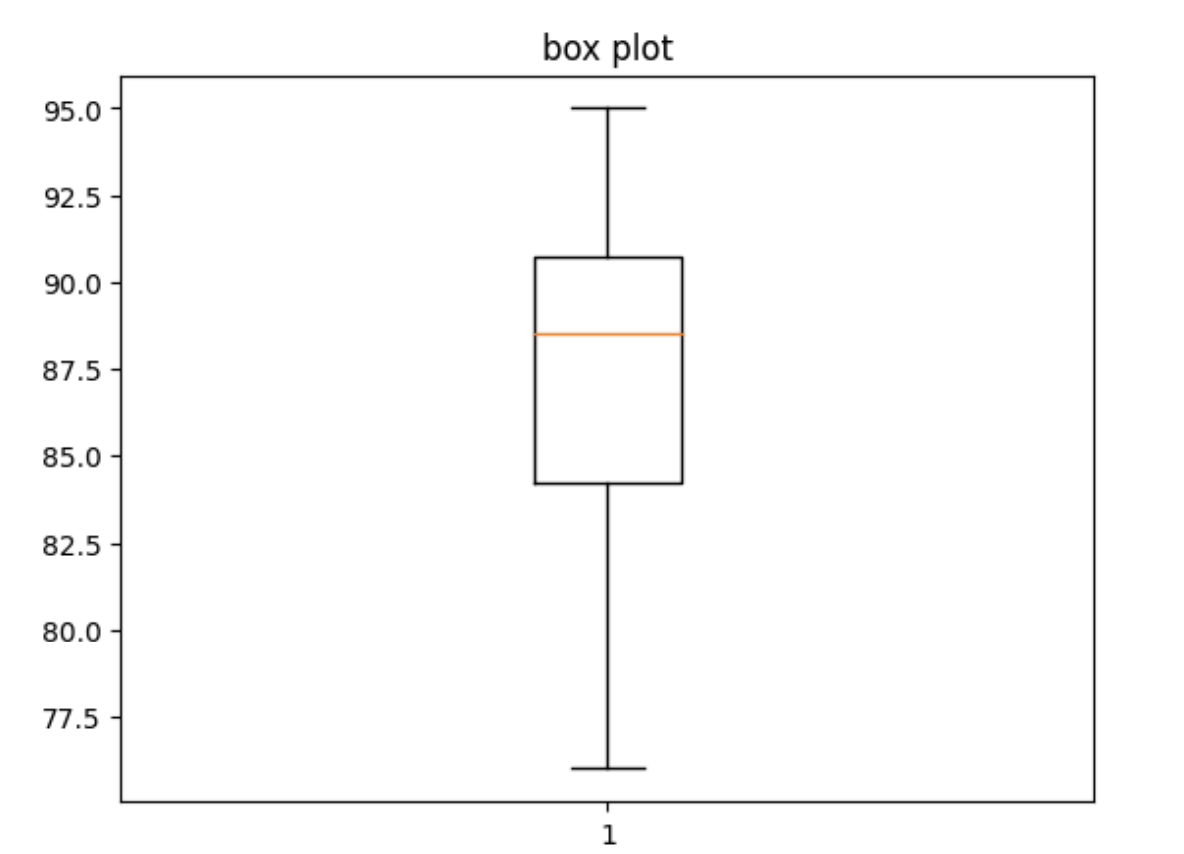
- 데이터의 값들이 어떻게 이루어져 있는지 확인하기
- 히스토그램, 상자 그림(Box Plot)이 대표적
ex) 시험 점수의 분포를 히스토그램과 상자 그림으로 표현
plt.hist(data, bins=5)
plt.title('histogram')
plt.show()
plt.boxplot(data)
plt.title('boxplot')
plt.show()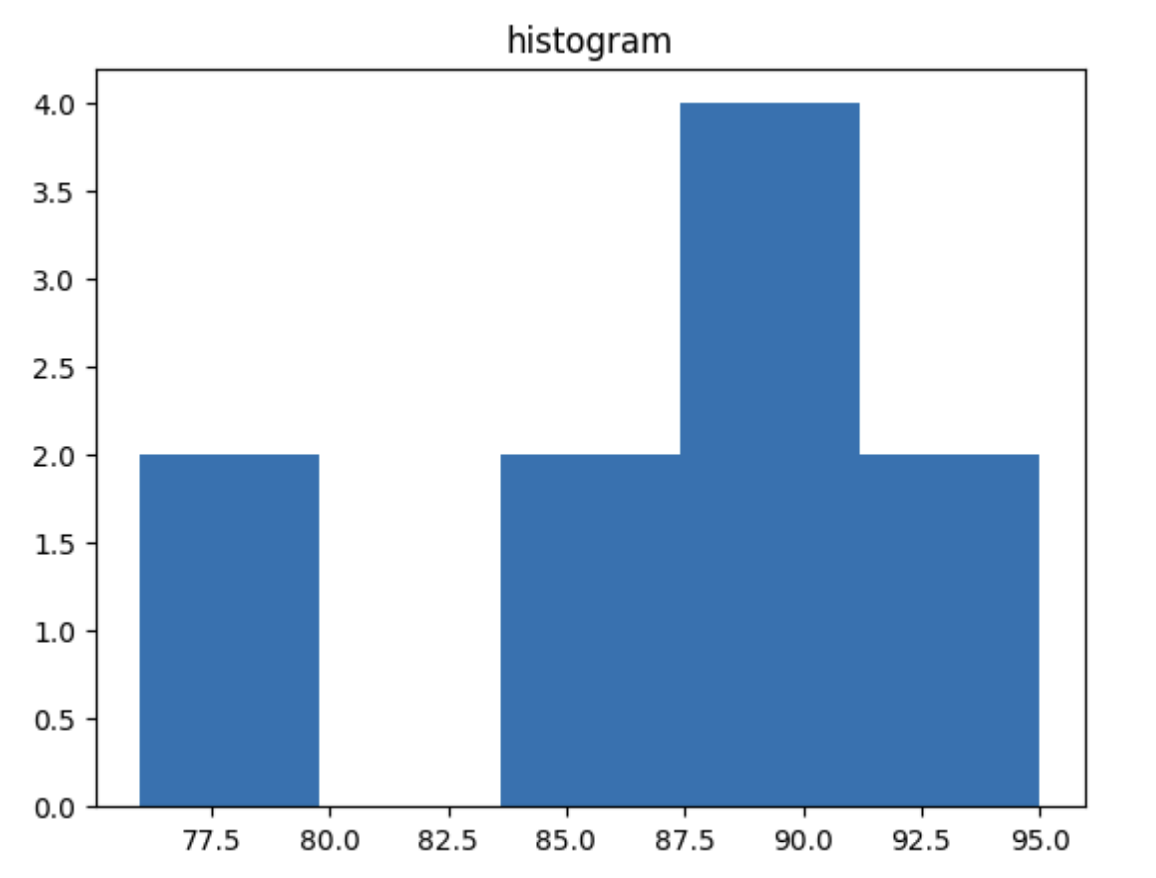
이진 데이터와 범주 데이터 탐색
- 데이터들이 서로 얼마나 다른지 확인하는 방법
- df['~~'].mode()
- 최빈값(개수가 제일 많은 값) 주로 차용
- 파이그림, 막대그래프 (vs 수치형: 히스토그램)이 대표적
ex) 고겍 만족도 설문에서 만족/불만족의 빈도 분석
satisfaction = ['satisfaction', 'satisfaction', 'dissatisfaction',
'satisfaction', 'dissatisfaction', 'satisfaction', 'satisfaction',
'dissatisfaction', 'satisfaction', 'dissatisfaction']
satisfaction_counts = pd.Series(satisfaction).value_counts()
satisfaction_counts.plot(kind='bar')
plt.title('satisfaction distribution')
plt.show()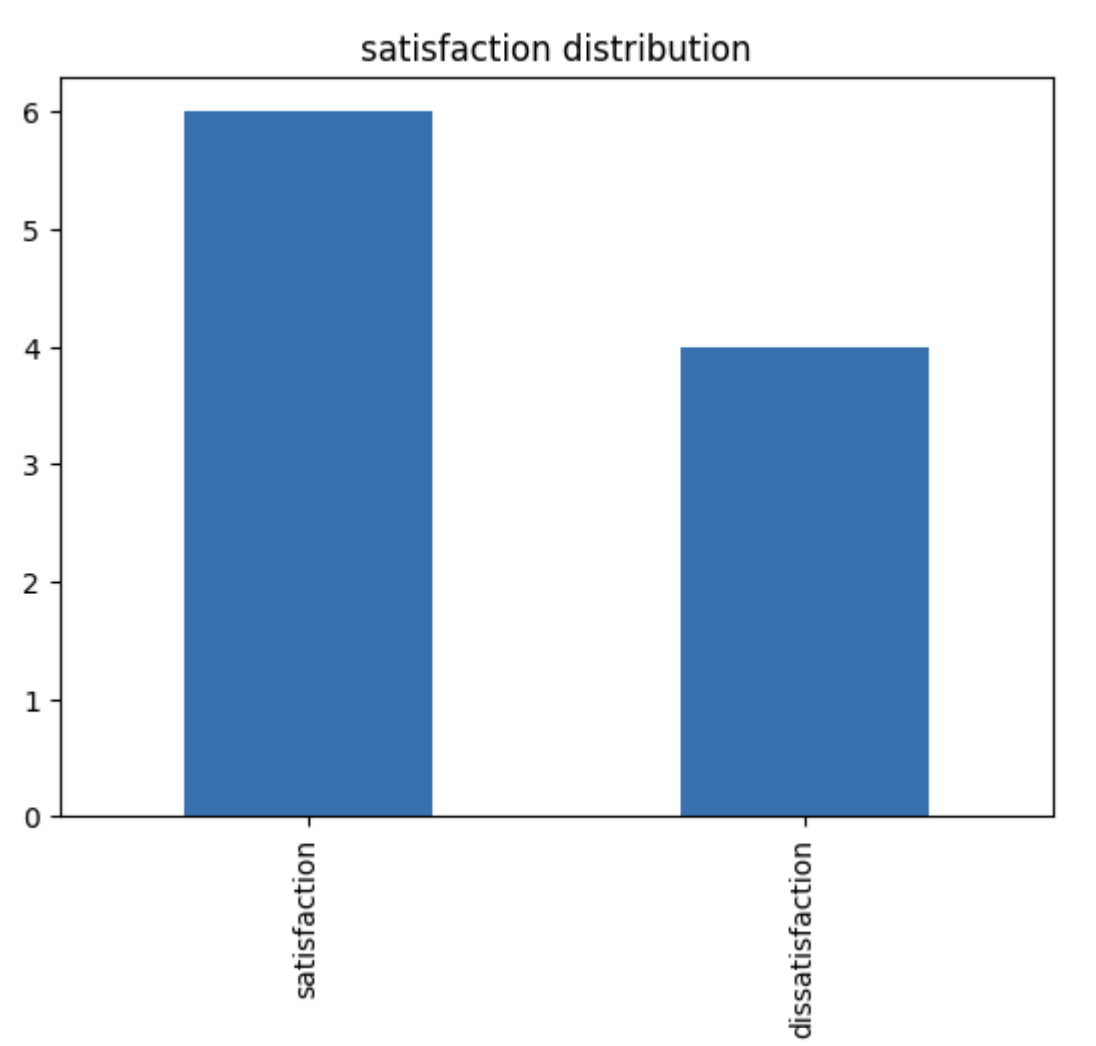
상관관계
- 데이터들끼리 서로 관련이 있는지 확인하는 방법
- 상관계수를 계산해서 -1, 1과 가까워지면 강력한 상관관계
-> -0.5, 0.5면 중간정도의 상관관계
-> 0에 가까울수록 상관관계 X
ex) 공부 시간과 시험 점수 간의 상관관계 분석
study_hours = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
exam_scores = [95, 90, 85, 80, 75, 70, 65, 60, 55, 50]
correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
print(f"공부 시간과 시험 점수 간의 상관계수: {correlation}")
plt.scatter(study_hours, exam_scores)
plt.show()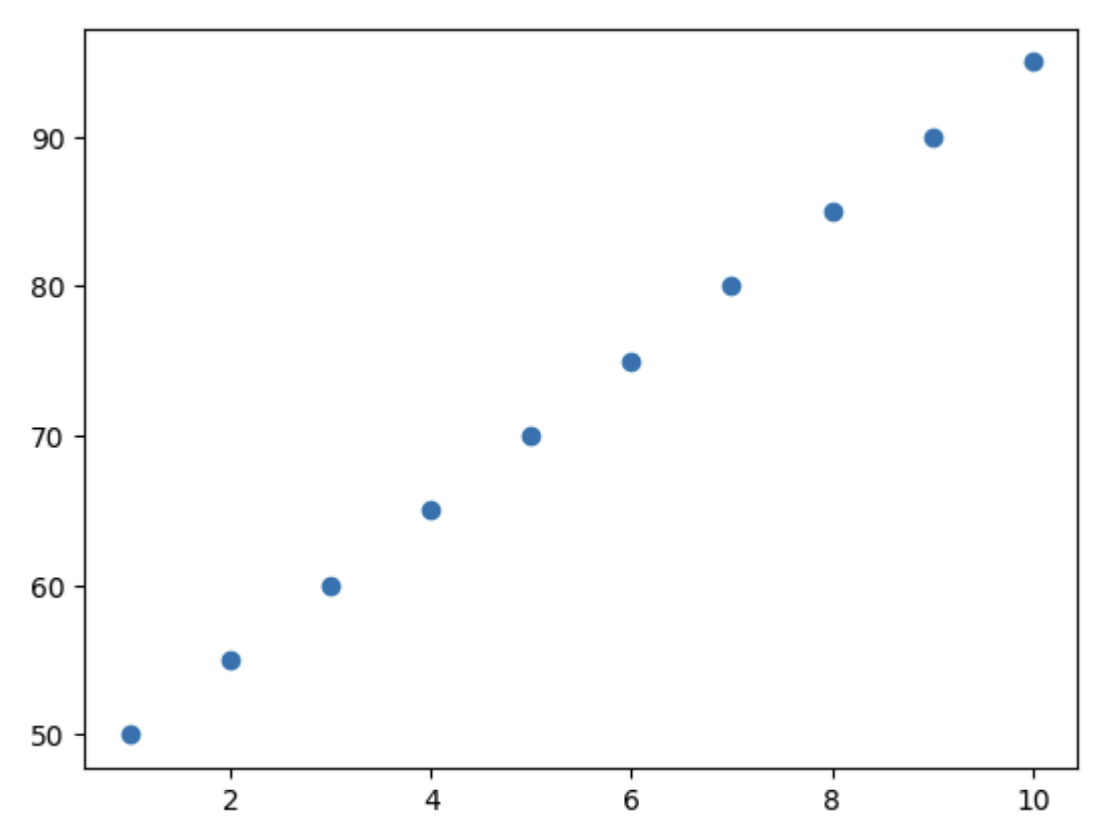
-> 강력한 양의 상관관계를 가짐
인과관계와 상관관계의 차이
- 인과관계는 상관관계와 다르게, 원인과 결과가 명확해야함
- 상관관계는 두 변수 간의 관계를 나타내고, 인과관계는 한 변수가 다른 변수에 미치는 영향을 나타냄
ex) 아이스크림 판매량과 익사 사고 수 간의 상관관계는 높지만, 인과관계는 아님
다변량 분석
- 여러 변수 간의 관계를 분석하는 방법
ex) 여러 마케팅 채널의 광고비와 매출 간의 관계 분석
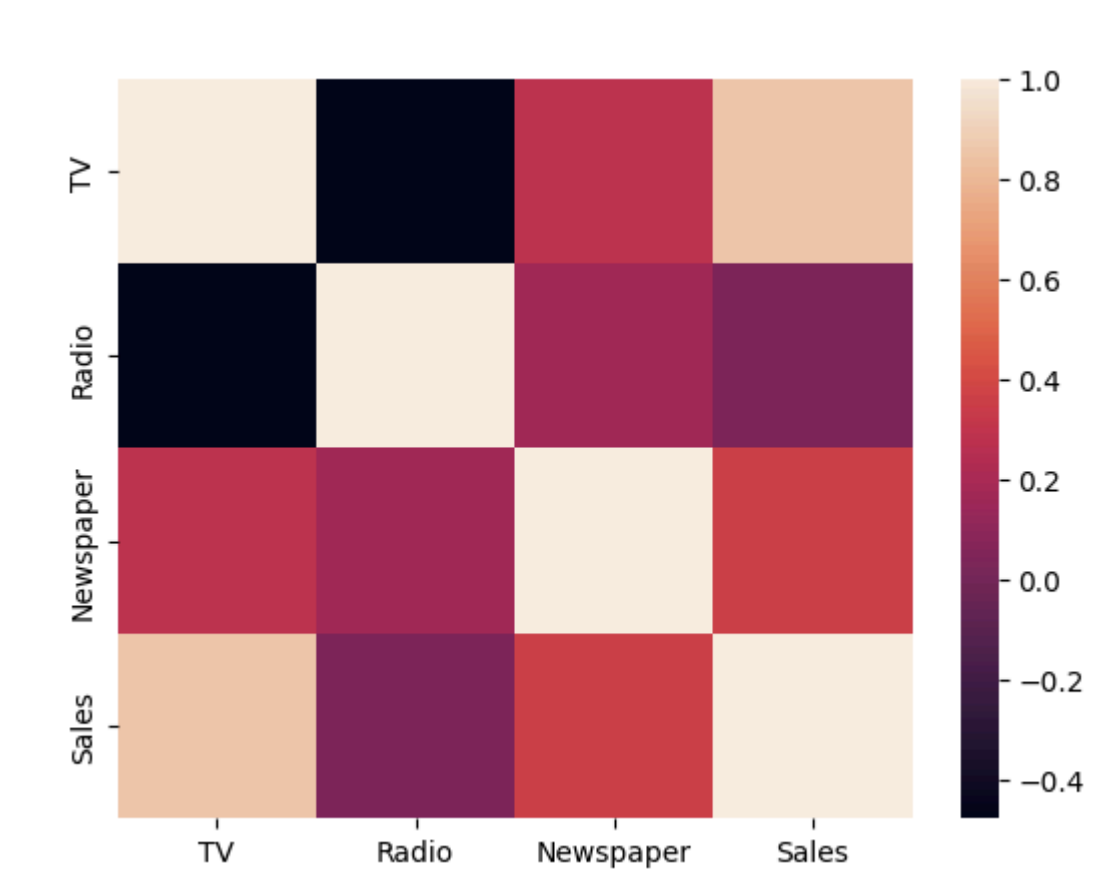
data = {'TV': [230.1, 44.5, 17.2, 151.5, 180.8],
'Radio': [37.8, 39.3, 45.9, 41.3, 10.8],
'Newspaper': [69.2, 45.1, 69.3, 58.5, 58.4],
'Sales': [22.1, 10.4, 9.3, 18.5, 12.9]}
df = pd.DataFrame(data)
sns.pairplot(df)
plt.show()
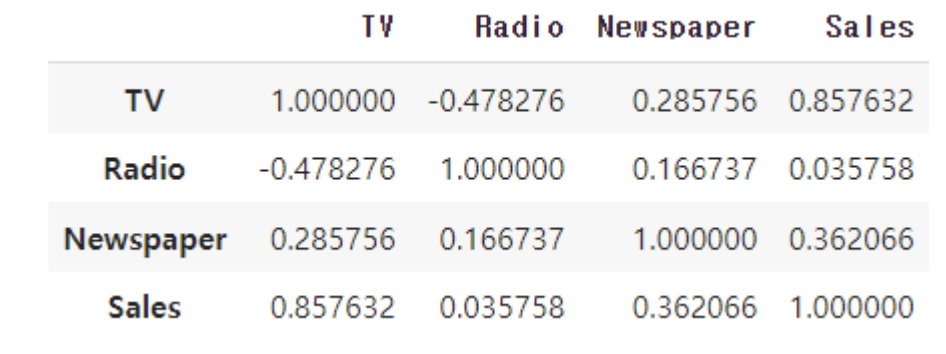
df.corr()
# heatmap까지 그린다면
sns.heatmap(df.corr())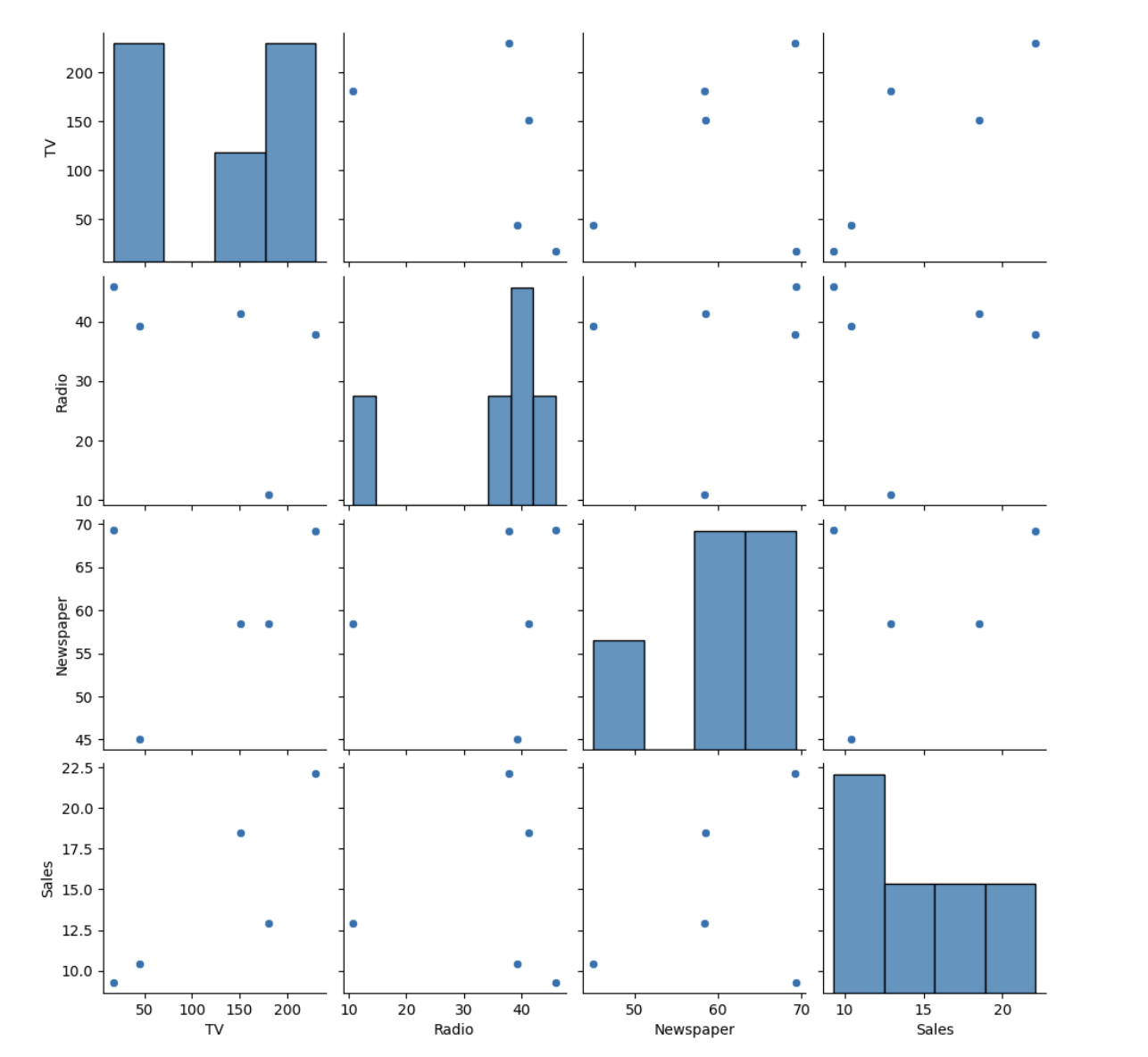
02. 데이터 분포
2.1 모집단과 표본
모집단과 표본이란?
- 모집단(Population) : 관심의 대상이 되는 전체 집단 ex) 한 국가의 모든 성인
- 표본(Sample) : 모집단에서 추출한 일부 ex) 그 국가의 성인 중 일부를 조사
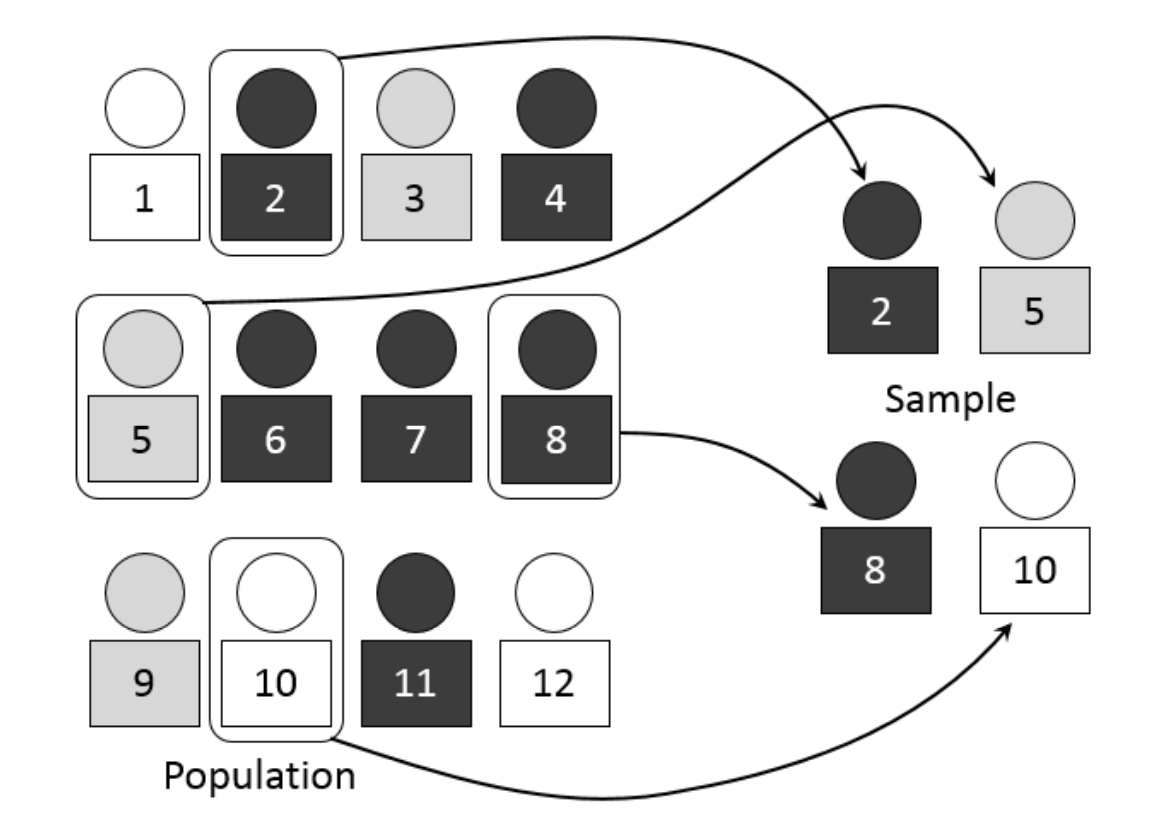
왜 표본을 사용해야 하는가?
- 현실적인 제약 - 비용, 시간, 접근성
- 대표성 - 무작위로 표본을 추출하면 편향을 최소화하고 모집단의 다양한 특성을 포함할 수 있음
- 데이터 관리 - 데이터 처리의 용이성, 데이터 품질 관리
- 모델 검증 용이
☑️ 전수조사
모집단 전체를 조사하는 방법. 대규모일 경우 비용과 시간이 많이 듦.
☑️ 표본조사
표본만을 조사하는 방법. 비용과 시간이 적게 들지만, 표본이 대표성을 가져야 함
실제 사례
- 실제로 모든 데이터를 다 수집할 수 없을 때 표본을 사용
- 도시 연구
한 도시의 모든 가구(모집단) 중 100가구(표본)를 조사하여 평균 전력 사용량
을 추정.- 의료 연구
특정 치료법의 효과를 알아보기 위해 전체 환자를 조사하는 대신, 표본을 통해
추정하고 이를 바탕으로 결론을 도출합니다.- 시장 조사
소비자 선호도를 파악하기 위해 모든 소비자를 조사하는 대신, 무작위로 선택된
표본을 통해 전체 시장의 트렌드를 추정합니다.- 정치 여론 조사
선거 전 여론 조사를 통해 전체 유권자의 투표 경향을 추정하여 선거 결과를 예
측합니다
ex) 국가의 모든 성인 키 데이터
import numpy as np
import matplotlib.pyplot as plt
# 모집단 생성 (예: 국가의 모든 성인의 키 데이터)
population = np.random.normal(170, 10, 1000)
# 표본 추출
sample = np.random.choice(population, 100)
plt.hist(population, bins=50, alpha=0.5, label='population', color='blue')
plt.hist(sample, bins=50, alpha=0.5, label='sample', color='red')
plt.legend()
plt.title('population and sample distribution')
plt.show()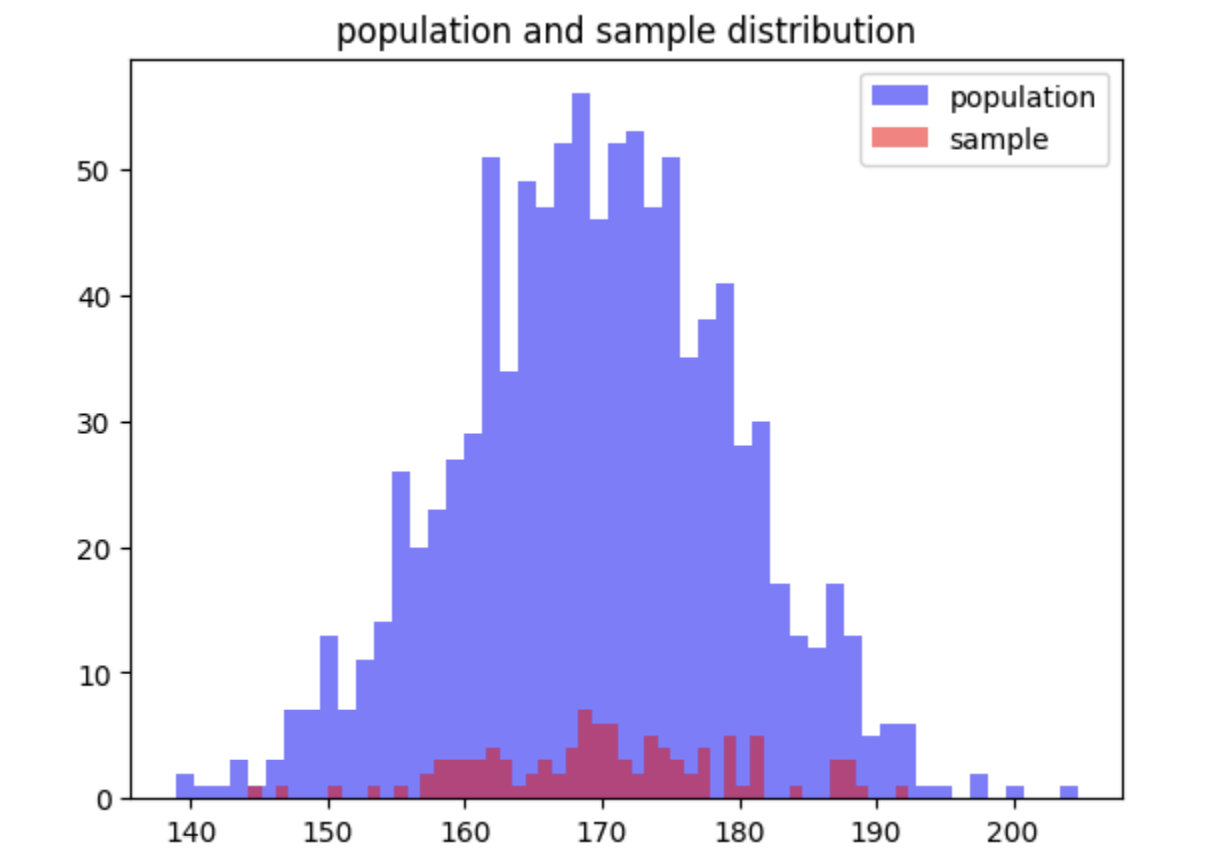
-> 모집단과 표본이 비슷한 경향성을 보이는 것을 알 수 있음
- numpy.random
numpy.random 모듈은 NumPy 라이브러리의 일부로, 다양한 확률 분포에 따라 난수를 생성하는 기능을 제공 - np.random.normal
함수는 정규분포(가우시안 분포)를 따르는 난수를 생성
코드 설명
numpy.random.normal(loc=0.0, scale=1.0, size=None)loc (float): 정규분포의 평균 (기본값: 0.0)
scale (float): 정규분포의 표준편차 (기본값: 1.0)
size (int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 스칼라 값 반환)
- np.random.choice
주어진 배열에서 임의로 샘플링하여 요소를 선택
-> 지정된 배열에서 무작위로 선택된 요소를 반환하는 기능
코드 설명
numpy.random.choice(a, size=None, replace=True, p=None)a (1-D array-like or int): 샘플링할 원본 배열. 정수인 경우 np.arange(a) 와 동일하게 간주됩니다.
size (int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 단일값 반환)
replace (boolean): 복원 추출 여부를 나타냅니다. True면 동일한 요소가 여러 번 선택될 수 있습니다 (기본값: True)
p (1-D array-like, optional): 각 요소가 선택될 확률. 배열의 합은 1
- plt.hist
Matplotlib 라이브러리에서 히스토그램을 그리는 함수
히스토그램은 데이터의 분포를 시각화하는 데 유용 - bins
히스토그램의 빈(bins)의 개수 또는 경계
빈(bins)은 데이터 몇개의 구간으로 나눌 것인지에 대한 것
정수나 리스트로 입력 가능정수: 빈의 개수를 지정
리스트: 각 빈의 경계를 직접 지정 (140~150, 150~160 … 이
렇게 경계를 지정하고 싶으면 리스트로 작성) - alpha
히스토그램 막대의 투명도를 지정
0(투명)에서 1(불투명) 사이의 값 - label
히스토그램의 레이블을 지정합니다. 여러 히스토그램을 그릴 때 범례를 추가하는 데 사용 - color
히스토그램 막대의 색상을 지정
2.2 표본오차와 신뢰구간
표본오차와 신뢰구간이란?
☑️ 표본오차 (Sampling Error)
표본에서 계산된 통계량과 모집단의 진짜 값 간의 차이
표본 크기가 클수록 표본오차는 작아짐
표본이 모집단을 완벽하게 대표하지 못하기 때문에 발생하며, 표본의 크기와 표본 추출 방법에 따라 달라질 수 있음
- 표본의 크기: 표본의 크기가 클수록 표본오차는 줄게 됨
-> 더 많은 데이터를 수집할수록 모집단을 더 잘 대표- 표본 추출 방법: 무작위 추출 방법을 사용하면 표본오차를 줄일 수 있음
-> 모든 모집단 요소가 선택될 동등한 기회를 가지게 해야 함
☑️ 신뢰구간 (Confidence Interval)
신뢰구간은 모집단의 특정 파라미터(예: 평균, 비율)에 대해 추정된 값이 포함될 것으로 기대되는 범위
신뢰구간 계산 방법
신뢰구간=표본평균±z×표준오차
여기서 z는 선택된 신뢰수준에 해당하는 z-값
ex) 95% 신뢰수준의 z-값은 1.96
일반적으로 95% 신뢰수준을 많이 사용
표본오차, 신뢰구간 그림으로 확인하기
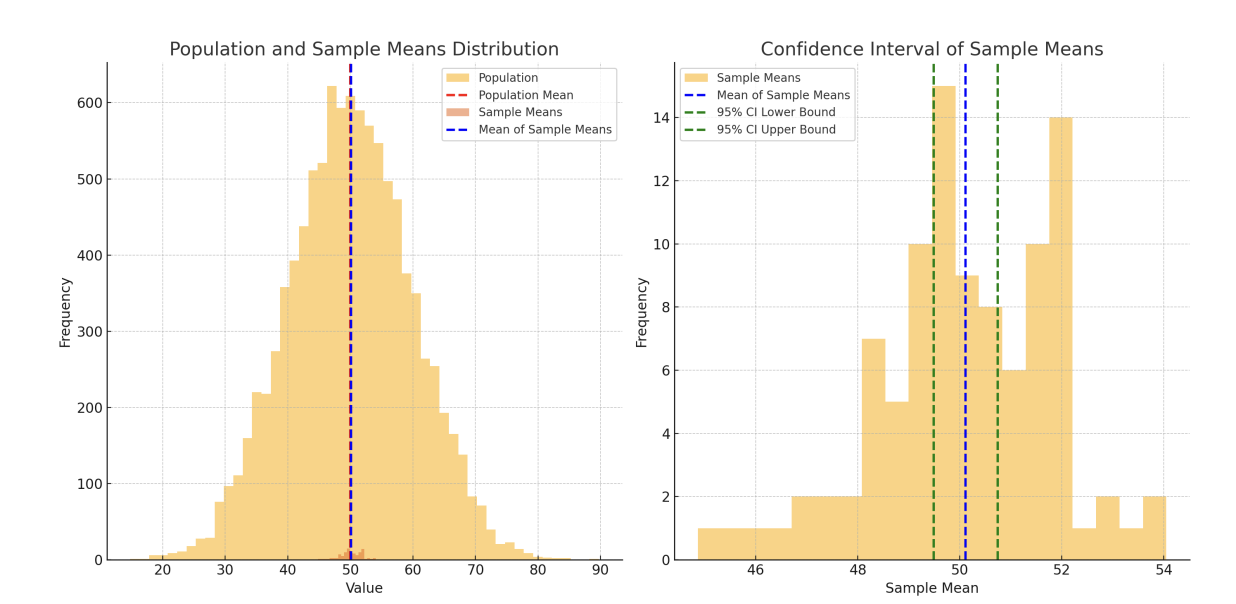
- 모집단과 표본 분포 (왼쪽 그림)
붉은색 점선 :모집단의 평균
파란색 점선 : 표본의 평균
모집단의 분포는 넓고, 표본 평균들의 분포는 좁아짐
표본 크기가 커질수록 표본 평균이 모집단 평균에 더 가까워지는 경향을 보여줌 - 신뢰구간 시각화 (오른쪽 그림)
오른쪽 그림은 표본의 분포와 95% 신뢰구간(모집단의 평균을 포함할 것으로 예상되는 범위)을 보여줌
파란색 점선은 표본의 평균을 나타내고, 녹색 점선은 95% 신뢰구간의 상한과
하한을 나타냄
실제 사례
ex) 100명의 학생을 표본으로 추출하여 그들의 평균 수학 점수를 구하고, 이 점수의 신뢰구간을 계산
import scipy.stats as stats
sample_mean = np.mean(sample)
sample_std = np.std(sample)
conf_interval = stats.t.interval(0.95, len(sample)-1 , loc = sample_mean, scale = sample_std/np.sqrt(len(sample)))
print(f"표본 평균: {sample_mean}")
print(f"95% 신뢰구간: {conf_interval}")
- stats.t.interval
scipy.stats 는 SciPy 라이브러리의 일부로, 통계 분석을 위한 다양한 함수와 클래스들을 제공하는 모듈
scipy.stats.t.interval 함수는 주어진 신뢰 수준에서 t-분포를 사용하여 신뢰 구간을 계산하는 데 사용
<코드 설명>
scipy.stats.t.interval(alpha, df, loc=0, scale=1)- alpha
신뢰 수준(confidence level)을 의미
-> 예를 들어, 95% 신뢰 구간을 원하면 alpha 를 0.95로 설정 - df
자유도(degrees of freedom)를 나타냄
일반적으로 표본 크기에서 1을 뺀 값으로 설정 (df = n - 1) - loc
위치(parameter of location)로, 일반적으로 표본 평균을 설정 - scale
스케일(parameter of scale)로,일반적으로 표본 표준 오차(standard error)를 설정함
표본 표준 오차는 표본 표준편차를 표본 크기의 제곱근으로 나눈 값( scale = sample_std / sqrt(n) )
도수분포표와 히스토그램 (추가)
- 도수: 특정 구간에 발생한 값의 수
- 상대도수: 특정 도수를 전체 도수로 나눈 비율
- 도수분포표: 각 값에 대한 도수와 상대도수를 나타내는 표
- 도수분포표 만들기
<도수분포표>
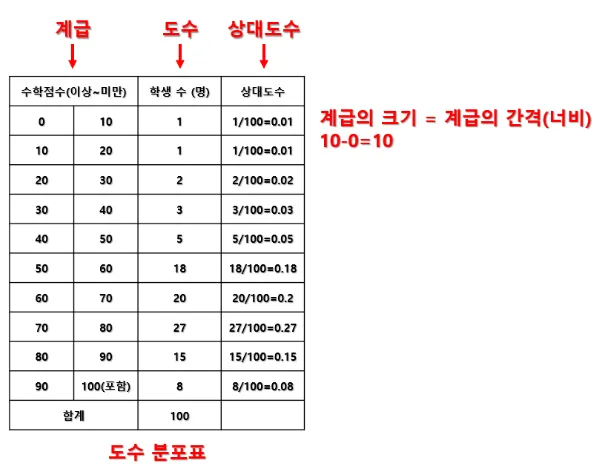
- 히스토그램: 도수분포표를 활용하여 만든 막대그래프
2.3 정규분포
가장 대표적인 분포!
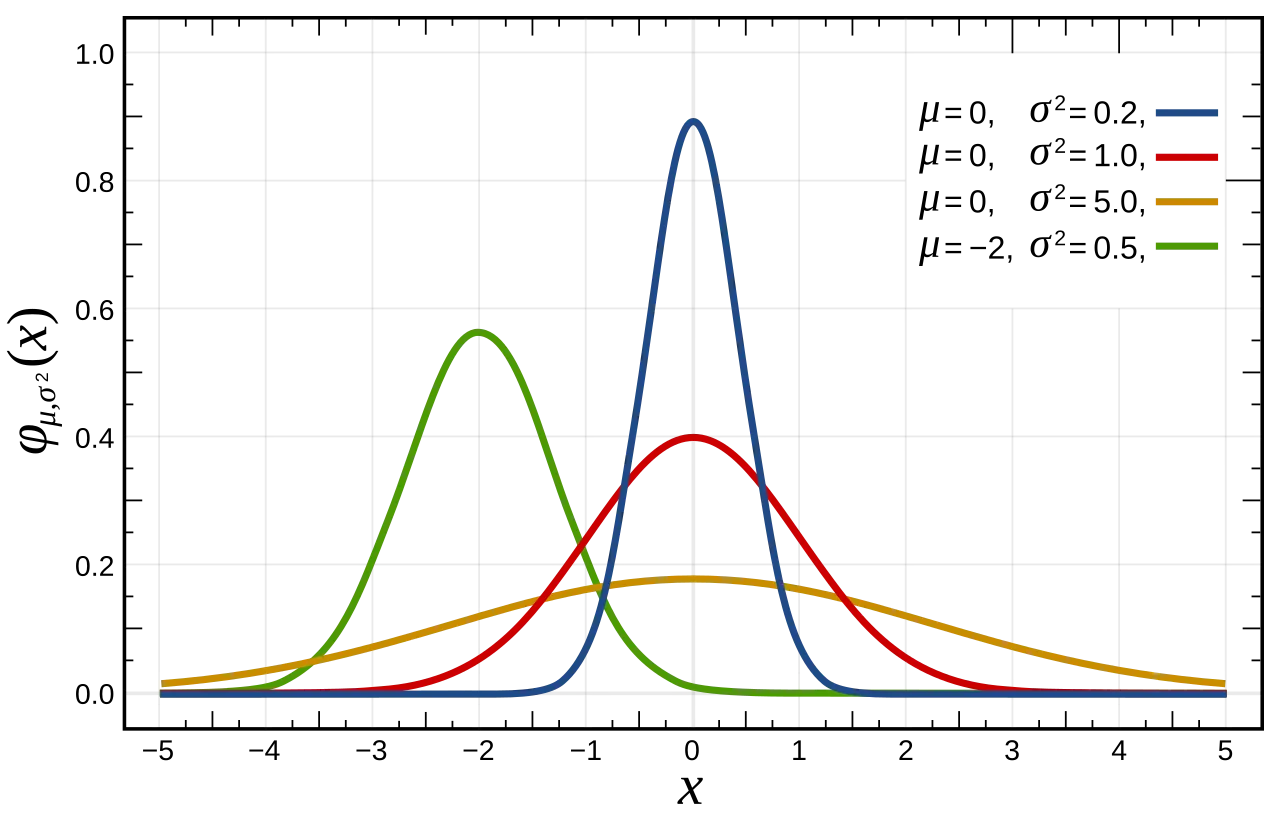
정의 및 특징
- 정규분포는 종 모양의 대칭 분포로, 대부분의 데이터가 평균 주위에 몰려 있는 분포
- 평균을 중심으로 좌우 대칭이며, 평균에서 멀어질수록 데이터의 빈도가 감소
- 표준편차는 분포의 퍼짐 정도
- 대부분의 데이터가 평균 주변에 몰려 있으며, 평균에서 멀어질수록 빈도가 줄어듦
실제 사례
- 키와 몸무게
- 대부분의 사람들의 키와 몸무게는 정규분포를 따름.
예를 들어, 평균 키가 170cm이고 표준편차가 10cm인 경우, 대부분의 사람들의 키는 160cm에서 180cm 사이에 위치
- 대부분의 사람들의 키와 몸무게는 정규분포를 따름.
- 시험 점수
- 큰 집단의 시험 점수는 정규분포를 따르는 경향이 존재
평균 점수 주위에 많은 학생들이 위치하고, 극단적인 고득점자와 저득점자는 적음
- 큰 집단의 시험 점수는 정규분포를 따르는 경향이 존재
ex) 코드 예시
# 정규분포 생성
normal_dist = np.random.normal(170, 10, 1000)
# 히스토그램으로 시각화
plt.hist(normal_dist, bins=30, density=True, alpha=0.6, color='g')
# 정규분포 곡선 추가
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = stats.norm.pdf(x, 170, 10)
plt.plot(x, p, 'k', linewidth=2)
plt.title('normal distribution histogram')
plt.show()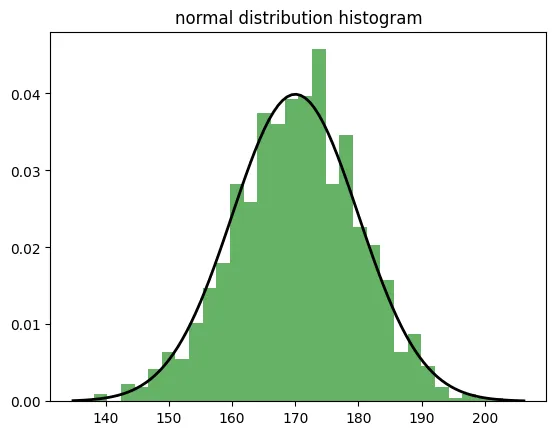
2.4 긴 꼬리분포
데이터가 비대칭적으로 꼬리 형태로 분포할 때 사용!
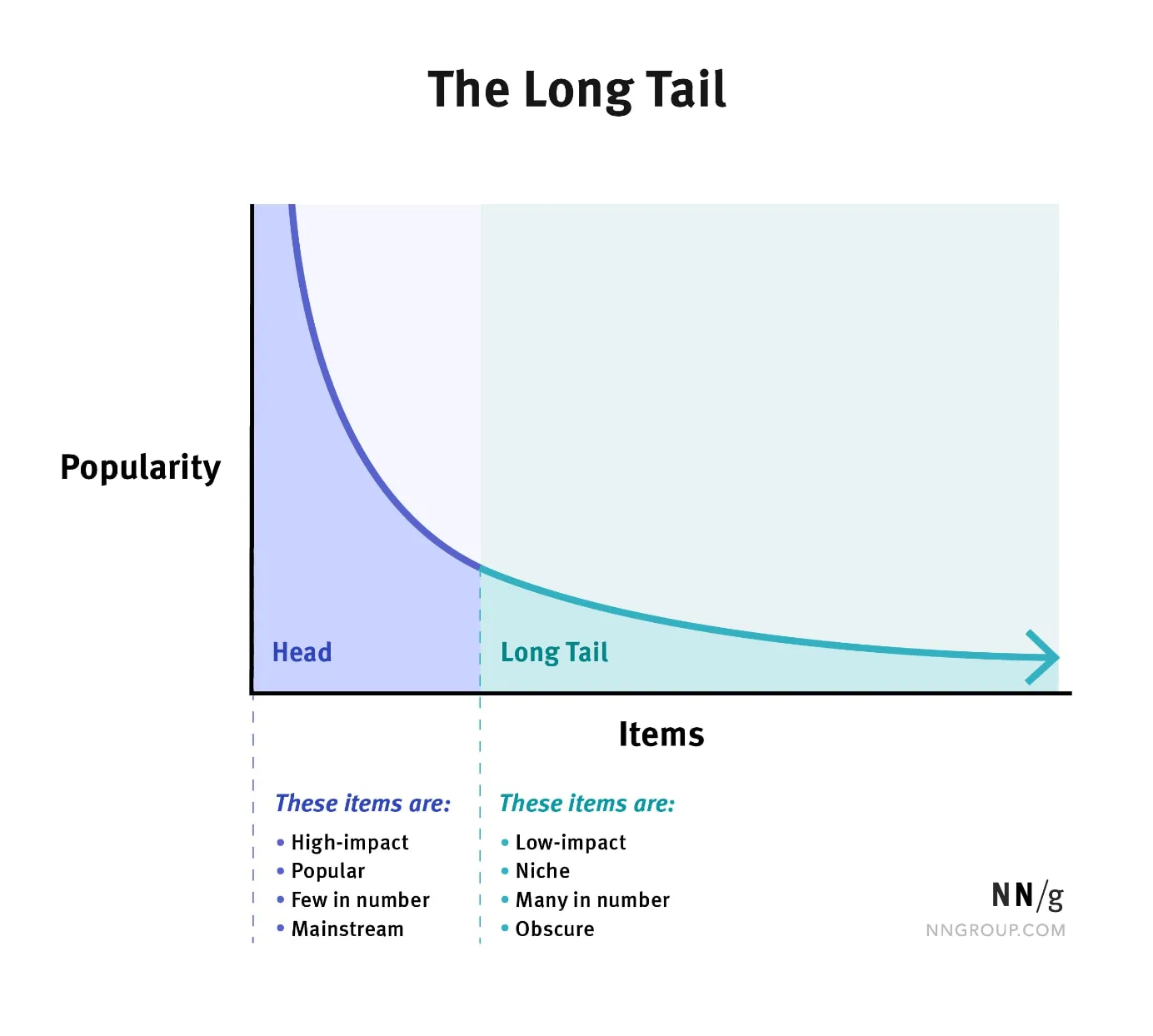
정의 및 특징
- 긴 꼬리 분포는 대부분의 데이터가 분포의 한쪽 끝에 몰려 있고, 반대쪽으로 긴 꼬리가 이어지는 형태의 분포
- 정규분포와 달리 대칭적이지 않고 비대칭적
- 특정한 하나의 분포를 의미하지 않으며 여러 종류의 분포(예: 파레토 분포, 지프의 법칙, 멱함수)를 포함할 수 있음
- 소득 분포, 웹사이트 방문자 수 등에서 관찰됨
실제 사례
😀 일부가 전체적으로 큰 영향을 미치는 경우
- 소득 분포
- 일부 부유층이 전체 소득에서 큰 비중을 차지하는 소득 분포
- 온라인 쇼핑
- 아마존과 같은 대형 온라인 쇼핑몰에서는 소수의 인기 제품이 많은 판매를 기록하고, 많은 수의 비인기 제품이 적은 판매를 기록하는 긴 꼬리 분포를 보임
-> 이 현상을 "롱테일 현상"이라고 함 - 잘 팔리는 상위 20%가 전체 매출의 80%를 차지
- 아마존과 같은 대형 온라인 쇼핑몰에서는 소수의 인기 제품이 많은 판매를 기록하고, 많은 수의 비인기 제품이 적은 판매를 기록하는 긴 꼬리 분포를 보임
- 도서 판매
- 소수의 베스트셀러 도서가 전체 판매량의 대부분을 차지하고, 많은 수의 비인기 도서가 적은 판매를 기록하는 긴 꼬리 분포를 보임
ex) 코드 예시
# 긴 꼬리 분포 생성 (예: 소득 데이터)
long_tail = np.random.exponential(1, 1000)
# 히스토그램으로 시각화
plt.hist(long_tail, bins=30, density=True, alpha=0.6, color='b')
plt.title('long tail distribution histogram')
plt.show()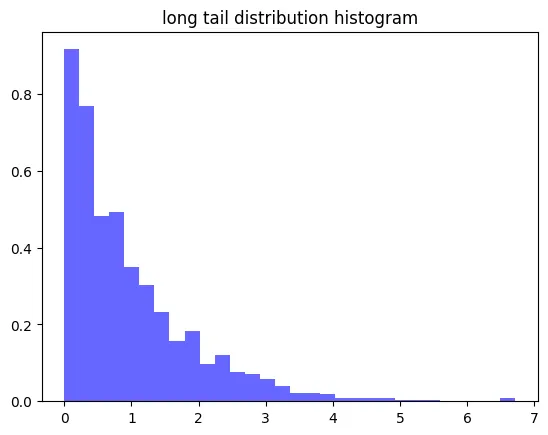
2.5 스튜던트 t 분포
표본이 작을 때 정규분포 대신 사용!
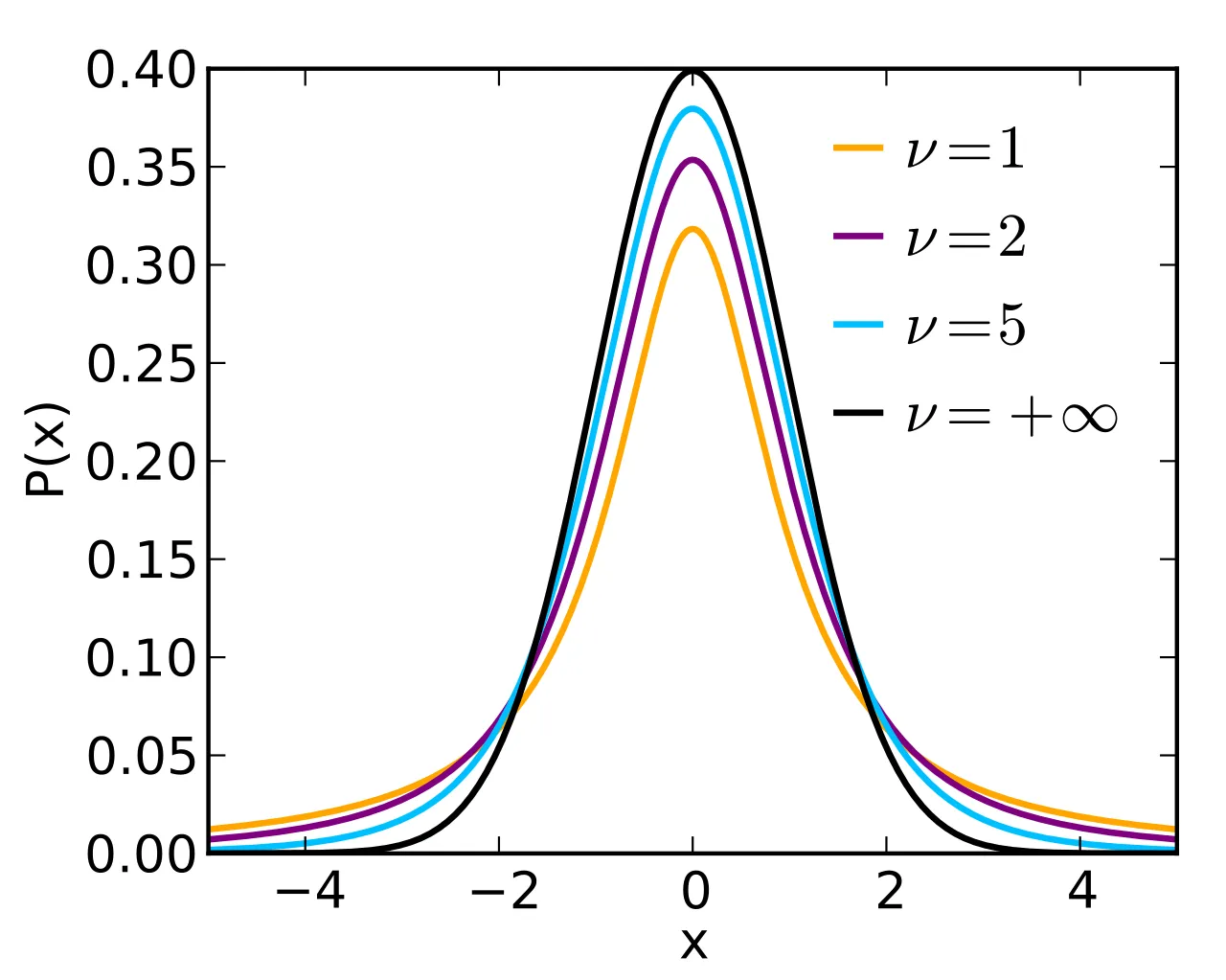
자유도가 커질 수록 정규분포에 가까워짐 (여기서 자유도란 표본의 크기와 관련이 있는 값이라고 이해!)
정의 및 특징
- t분포는 모집단의 표준편차를 알 수 없고 표본의 크기가 작은 경우(일반적으로 30미만)에 사용되는 분포
- 정규분포와 유사하지만, 표본의 크기가 작을수록 꼬리가 두꺼워지는 특징이 있음
- 표본 크기가 커지면 정규분포에 가까워짐
실제 사례
😜 데이터가 적은 경우 사용
- 작은 표본의 평균 비교
- 예를 들어, 두 그룹의 평균 시험 점수를 비교할 때 표본 크기가 작다면 t검정을 사용하여 두 그룹의 평균이 유의미하게 다른지 검토할 수 있음
- 약물 시험
- 새로운 약물의 효과를 테스트할 때, 소규모 임상 시험에서 두 그룹 간의 차이를 분석하는 데 사용
ex) 코드 예시
# 스튜던트 t 분포 생성
t_dist = np.random.standard_t(df=10, size=1000)
# 히스토그램으로 시각화
plt.hist(t_dist, bins=30, density=True, alpha=0.6, color='r')
# 스튜던트 t 분포 곡선 추가
x = np.linspace(-4, 4, 100)
p = stats.t.pdf(x, df=10)
plt.plot(x, p, 'k', linewidth=2)
plt.title('student t distribution histogram')
plt.show()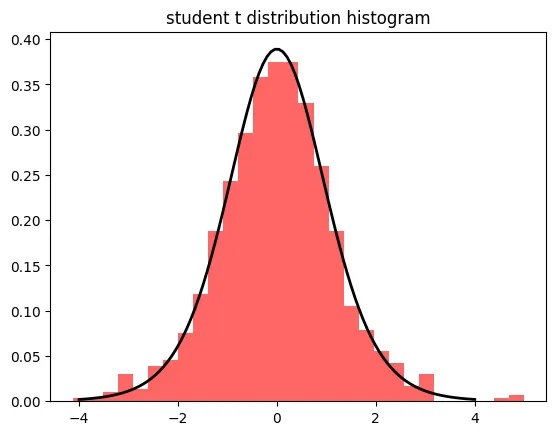
2.6 카이제곱분포
독립성 검정이나 적합도 검정에 사용되는 분포!
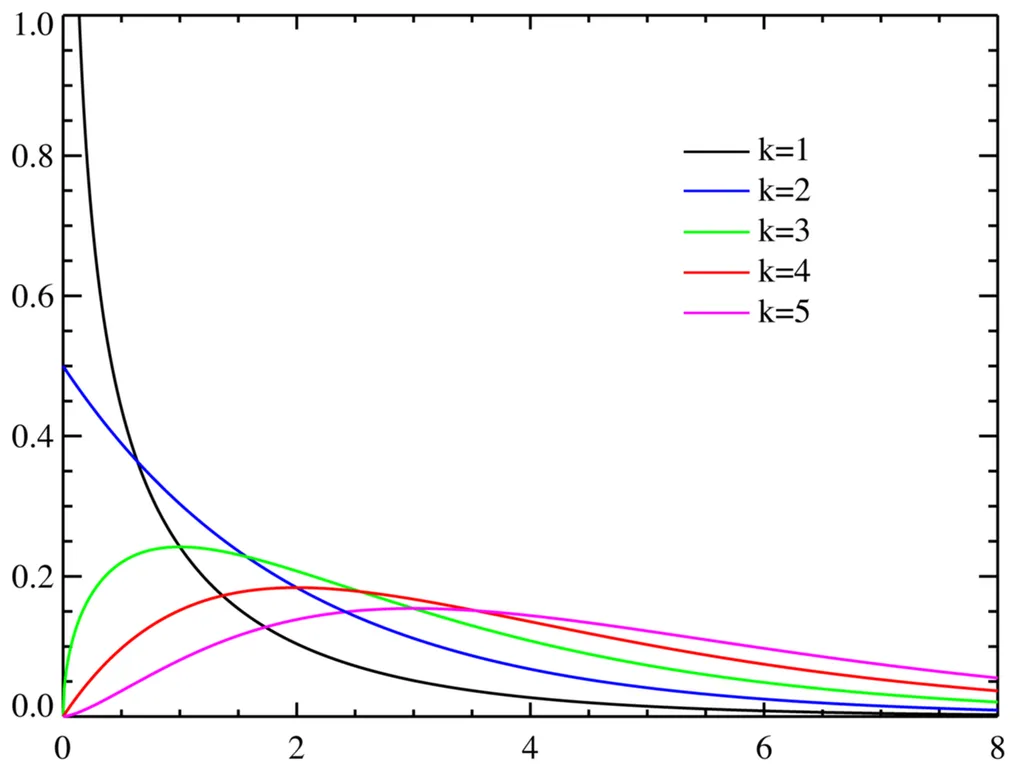
여기서 K값은 자유도 (여기서 자유도란 표본의 크기와 관련이 있는 값이다 정도로 이해!)
정의 및 특징
- 카이제곱분포는 범주형 데이터의 독립성 검정이나 적합도 검정에 사용되는 분포
- 자유도에 따라 모양이 달라짐
- 상관관계나 인과관계를 판별하고자 하는 원인의 독립변수가 ‘완벽하게 서로 다른 질적 자료’일 때 활용
- ex) 성별이나 나이에 따른 선거 후보 지지율
- 범주형 데이터 분석에 사용
실제 사례
👊🏻 독립성 검정이나 적합도 검정이 필요할 때
- 독립성 검정
- 두 범주형 변수 간의 관계가 있는지 확인할 때 사용
- 예를 들어, 성별과 직업 선택 간의 독립성을 검토할 수 있음
- 혹은, 성별이 후보 지지율에 영향을 끼치는지? 검토할 수도 있음
- 적합도 검정
- 관측한 값들이 특정 분포에 해당하는지? 검정할 때 사용
- 예를 들어, 주사위의 각 면이 동일한 확률로 나오는지 검토할 수 있음
- 노란색 완두와 녹색완두가 3:1의 비율로 나와야 하는데 실험적으로 측정한 데이터가 그렇게 나오는지?
ex) 코드 예시
# 카이제곱분포 생성
chi2_dist = np.random.chisquare(df=2, size=1000)
# 히스토그램으로 시각화
plt.hist(chi2_dist, bins=30, density=True, alpha=0.6, color='m')
# 카이제곱분포 곡선 추가
x = np.linspace(0, 10, 100)
p = stats.chi2.pdf(x, df=2)
plt.plot(x, p, 'k', linewidth=2)
plt.title('카이제곱 분포 히스토그램')
plt.show()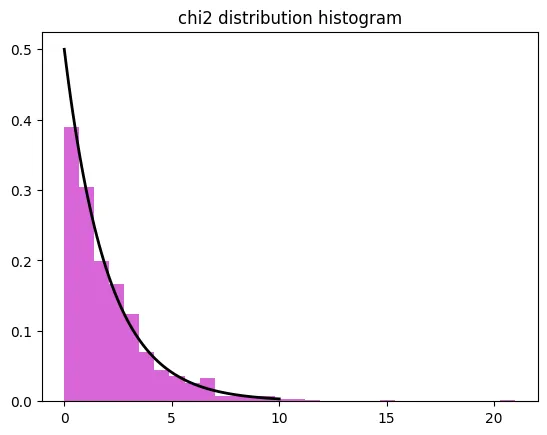
2.7 이항분포
결과가 2개가 나오는 상황일 때 사용하는 분포!
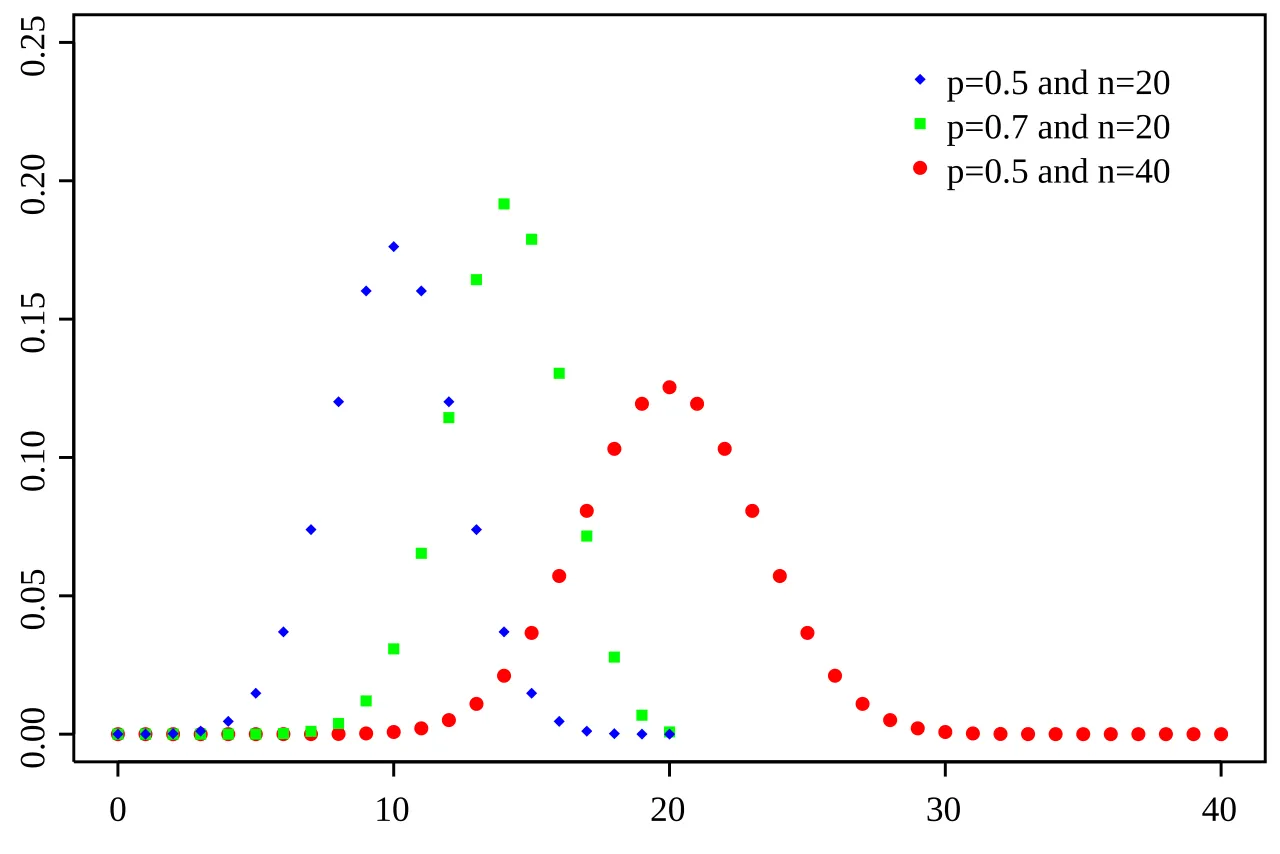
- 이항분포는 연속된 값을 가지지 않고, 특정한 정수 값만을 가질 수 있음
- 이항분포처럼 연속된 값을 가지지 않는 분포를 이산형 분포라고 지칭 하기도 함
정의 및 특징
- 성공/실패와 같은 두가지 결과를 가지는 실험을 여러 번 반복했을 때 성공 횟수의 분포
- 독립적인 시행이 n번 반복되고, 각 시행에서 성공과 실패 중 하나의 결과만 가능한 경우를 모델링하는 분포
- 성공 확률을 p라 할 때, 성공의 횟수를 확률적으로 나타냄
- 실험 횟수(n)와 성공 확률(p)로 정의
실제 사례
✋🏻 결과가 2개만 나오는 상황을 여러번 하는 경우
- 동전 던지기
- 동전을 10번 던졌을 때, 앞면이 나오는 횟수는 이항분포를 따름
- 품질 관리
- 제조업체가 제품의 불량률을 모니터링할 때, 무작위로 선택된 100개의 제품 중 불량품의 수는 이항분포를 따름
ex) 코드 예시
# 이항분포 생성 (예: 동전 던지기 10번 중 앞면이 나오는 횟수)
binom_dist = np.random.binomial(n=10, p=0.5, size=1000)
# 히스토그램으로 시각화
plt.hist(binom_dist, bins=10, density=True, alpha=0.6, color='y')
plt.title('이항 분포 히스토그램')
plt.show()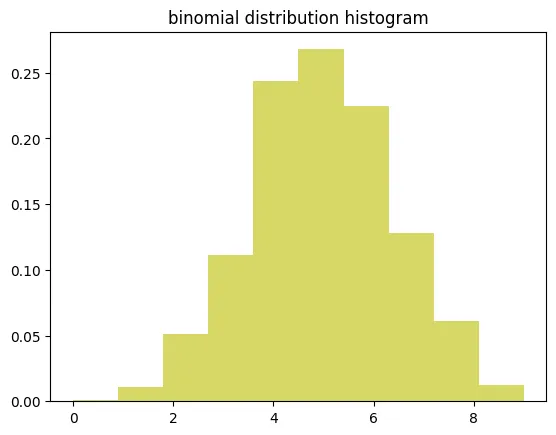
2.8 푸아송 분포
희귀한 사건이 발생할 때 사용하는 분포!
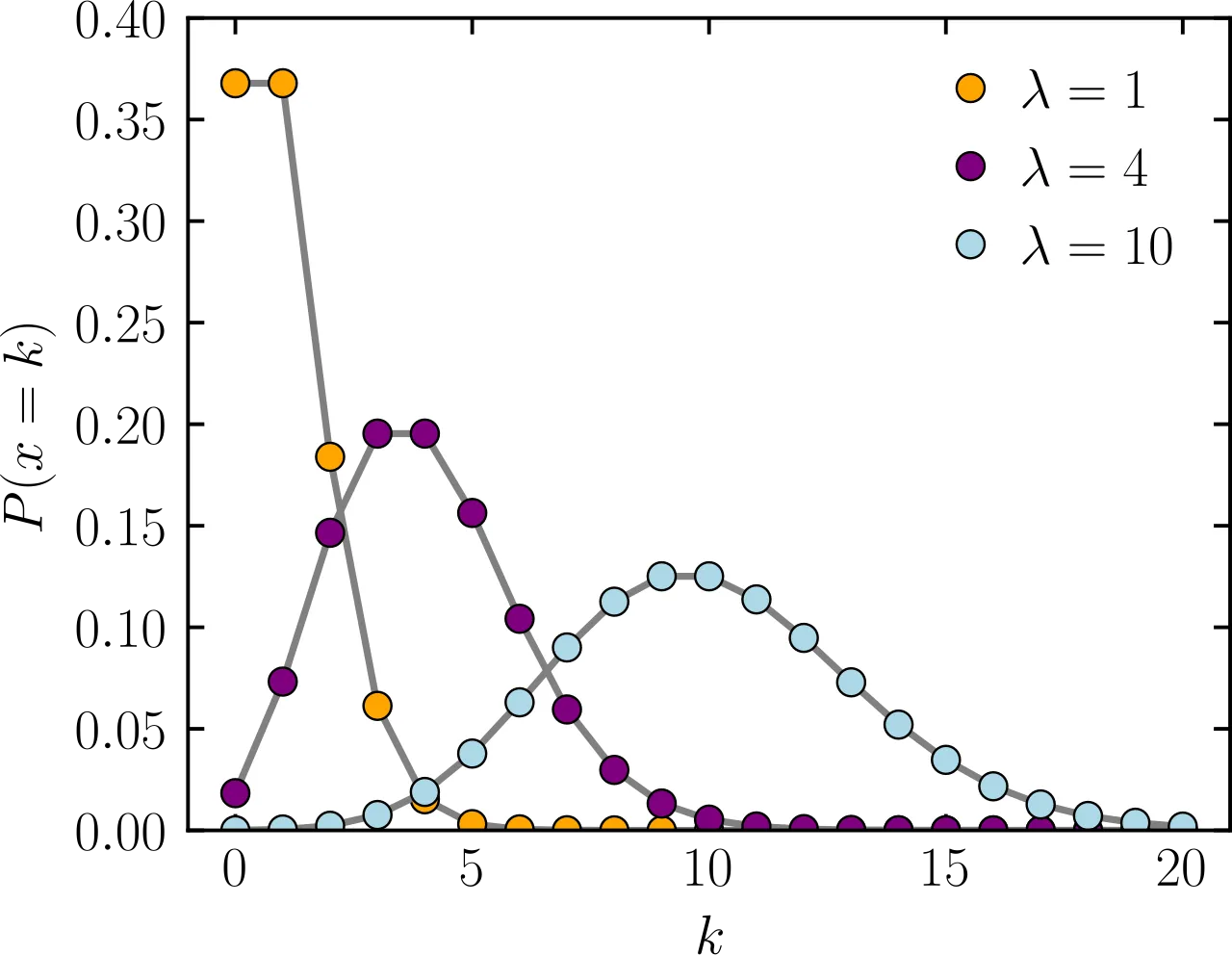
- 이항 분포처럼 연속된 값을 가지지 않기 때문에 이 분포도 이산형 분포
- 평균 발생률 λ가 충분히 크다면 정규분포에 근사
- 평균 발생률이란 주어신 시간이나 공간에서 사건이 몇번 발생했는지?
- ex) 한 시간동안 콜센터에 전화오는 건수가 10건이면 λ는 10
정의 및 특징
- 단위 시간 또는 단위 면적 당 발생하는 사건의 수를 모델링할 때 사용하는 분포
- 푸아송 분포는 평균 발생률 λ를 가진 사건이 주어진 시간 또는 공간 내에서 몇 번 발생하는지를 나타냄
- 푸아송 분포는 단위 시간 또는 단위 면적당 희귀하게 발생하는 사건의 수를 모델링하는 데 적합
실제 사례
🌝 특정 공간이나 특정 시간에 사건이 발생하는 경우
- 콜센터
- 특정 시간 동안 콜센터에 도착하는 전화 통화의 수
- 교통사고
- 특정 도로 구간에서 일정 기간 동안 발생하는 교통사고의 수
- 문자 메시지
- 특정 시간 동안 수신되는 문자 메시지의 수
- 웹사이트 트래픽
- 특정 시간 동안 웹사이트에 도착하는 방문자의 수
ex) 코드 예시
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import poisson
# 푸아송 분포 파라미터 설정
lambda_value = 4 # 평균 발생률
x = np.arange(0, 15) # 사건 발생 횟수 범위
# 푸아송 분포 확률 질량 함수 계산
poisson_pmf = poisson.pmf(x, lambda_value)
# 그래프 그리기
plt.figure(figsize=(10, 6))
plt.bar(x, poisson_pmf, alpha=0.6, color='b', label=f'Poisson PMF (lambda={lambda_value})')
plt.xlabel('Number of Events')
plt.ylabel('Probability')
plt.title('Poisson Distribution')
plt.legend()
plt.grid(True)
plt.show()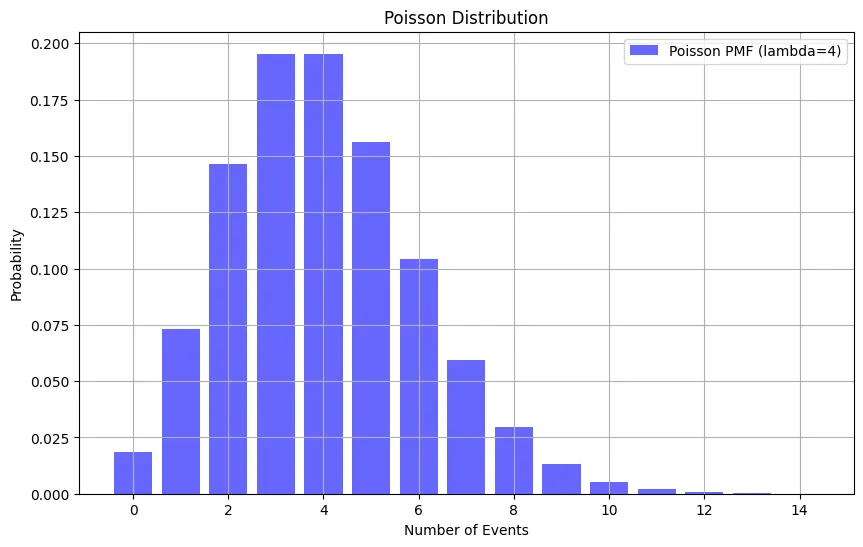
2.9 분포 정리하기
분포 정리본
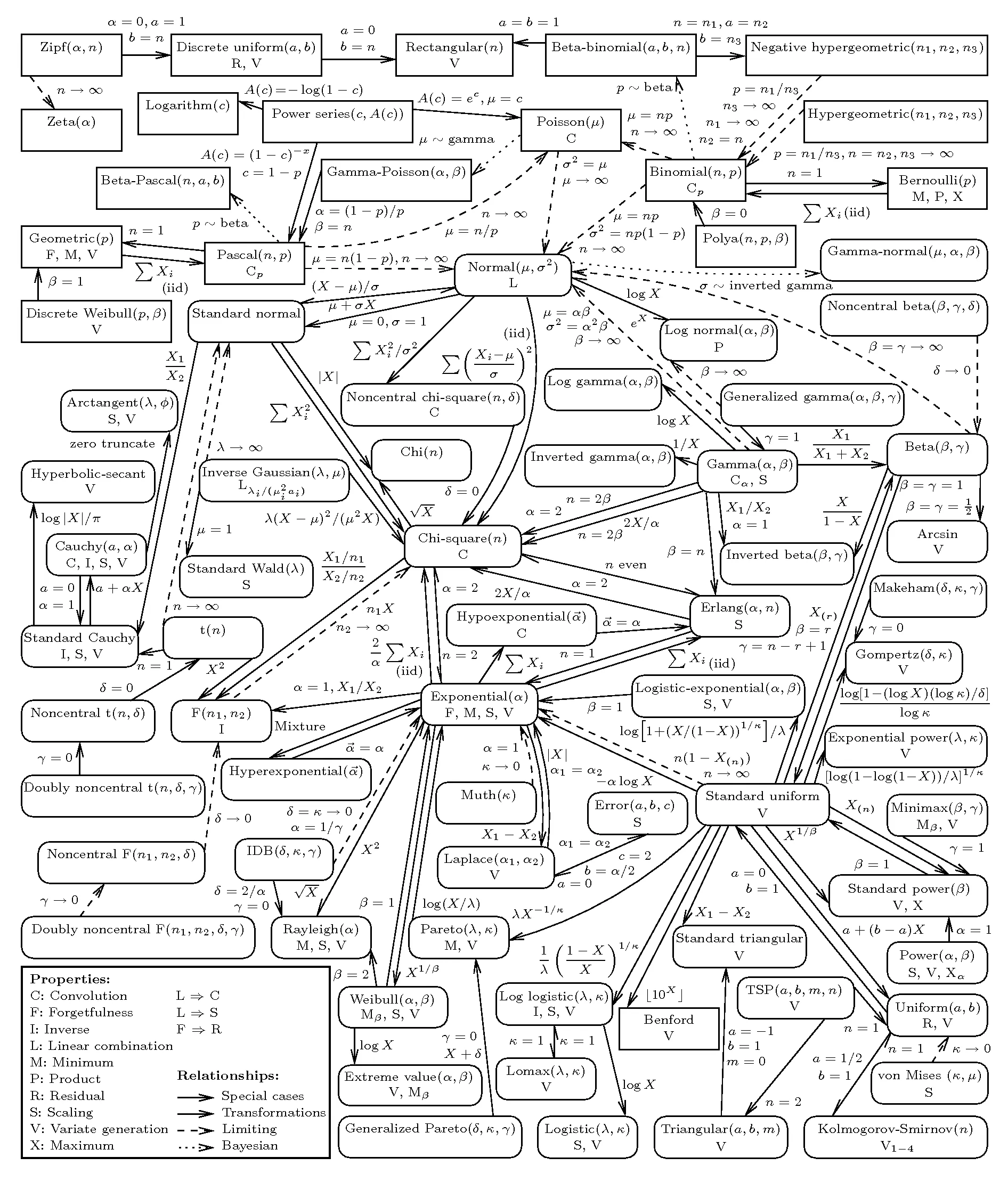
세상 많은 분포들이 존재하지만,,, 위에 설명한 분포들이 대표적인 데이터 분석에 필요한 분포들!
데이터 분석에 필요한 분포 정리본
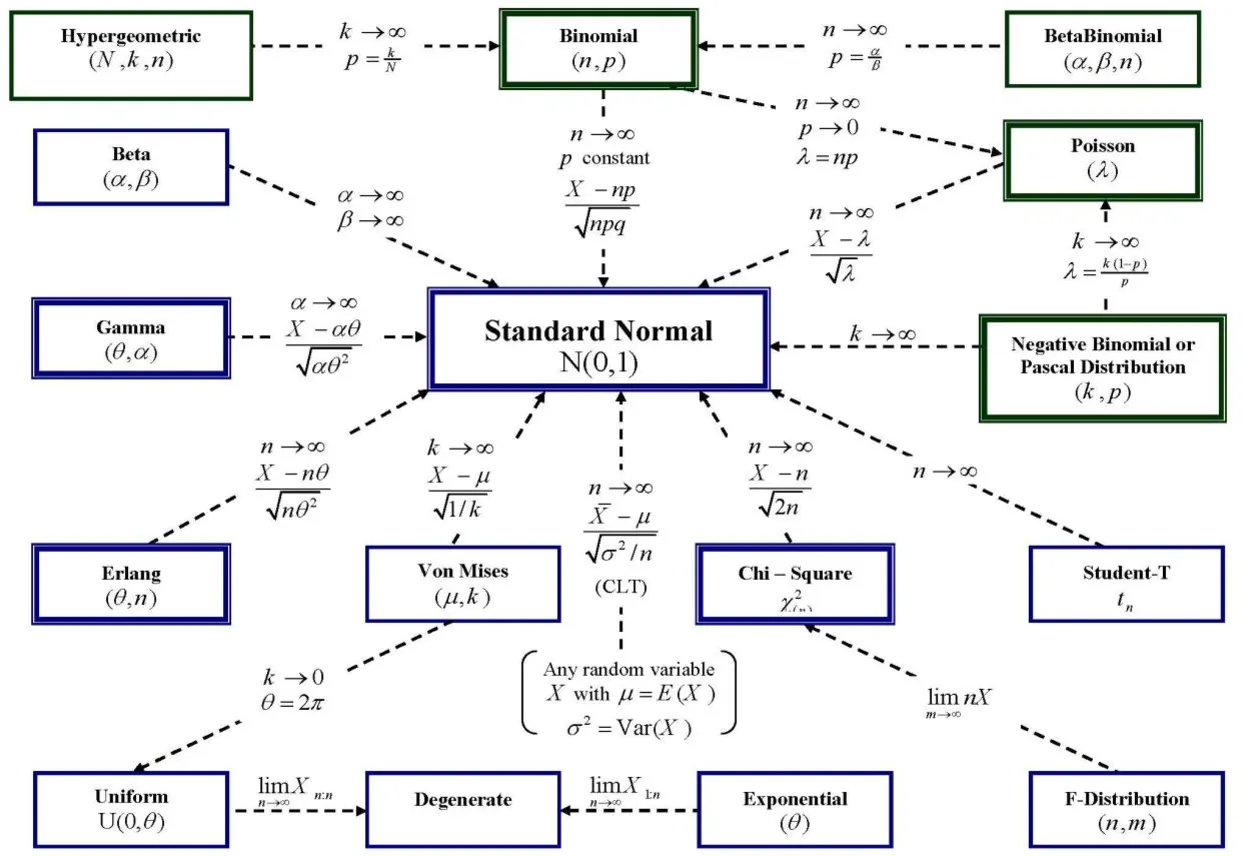
- 결국 데이터 수가 엄청 많아지면 정규분포에 수렴 (중심극한정리)
- 데이터 수가 많으면 묻지도 따지지도 말고 바로 정규분포로 가정!
- 하지만, 데이터가 적을 경우 각 상황에 맞는 분포를 선택
- 특히, long tail distribution은 데이터가 많아도 정규분포가 되지 않는 분포!
분포 고르는 법
☑️ 데이터 수가 충분하다 → (무조건) 정규분포
☑️ 데이터 수가 작다 → 스튜던트 t 분포
☑️ 일부 데이터가 전체적으로 큰 영향을 미친다 → 롱 테일 분포 (파레토 분포)
☑️ 범주형 데이터의 독립성 검정이나 적합도 검정 → 카이 제곱 분포
☑️ 결과가 두 개(성공 or 실패)만 나오는 상황 → 이항 분포
☑️ 특정 시간, 공간에서 발생하는 사건 → 푸아송 분포
