✅ 핵심내용
- 시퀀스 데이터에 대한 이해
- 순환신경망 RNN 개념
- 언어모델 Language Model
시퀀스 (Sequence)
시퀀스는 데이터에 순서를 붙여서 나열한 것이다.
- 데이터를 순서대로 하나씩 나열하여 나타낸 구조
- 특정 위치의 데이터 선택 가능
시퀀스 데이터가 각 요소들의 연관성을 의미하지는 않지만, 모델이 예측을 하기 위해서는 어느정도 연관성이 필요 하다.
문장을 구성하는 각 단어들의 경우에는 통계에 기반한 방법 을 통해 다음에 올 단어를 예측을 할 수 있다.
쉽게 말하면, 수많은 글을 읽게함으로써, 나는 , 밥을 뒤에 먹는다 라는 단어가 올 수 있음을 예측 할 수 있다. 이런 이유에서 많은 데이터로 모델을 학습하는 것이 중요하다.
순환신경망 (RNN)
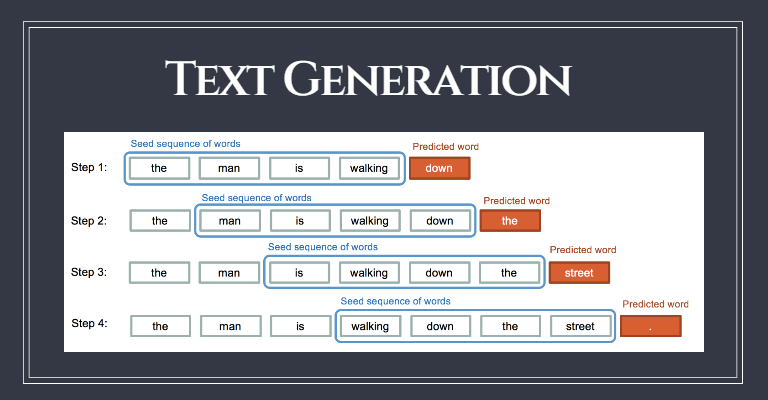
위와 같은 방식을 가장 잘 처리하는 모델 중 하나가 순환신경망 (Recurrent Neural Network, RNN) 이다.
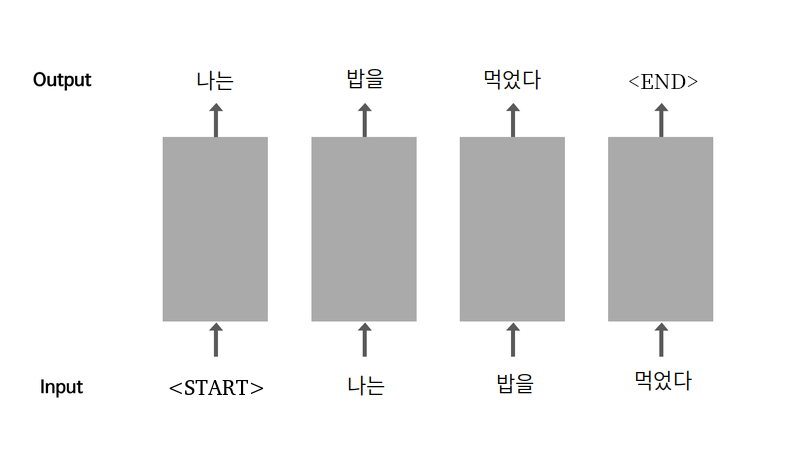
위 그림에서 확인 할 수 있듯이 RNN은 이러한 순환적인 특성을 가진다.
<start>라는 토큰을 맨 앞에 추가함으로써 시작을 뜻함<start>를 입력으로 받은 모델은 다음 단어로나는을 생성- 생성한 단어를 다시 입력으로 사용
- 문장을 다 만들면
<end>토큰을 맨 뒤에 추가함으로써 종료를 뜻함 <start>가 문장의 시작에 더해진 데이터를 입력 데이터로,
<end>가 문장의 끝에 더해진 데이터를 출력 데이터로 사용하여 모델을 학습
RNN에 대한 더욱 자세한 내용은 AIFFEL FD #18 딥러닝 레이어 - Embedding, Recurrent
언어 모델 (Language Model)
언어 모델(Language Model) 이란, 개의 단어 시퀀스 가 주어졌을 때, 번째 단어 으로 무엇이 올지를 예측하는 확률 모델이다.
파라미터 로 모델링하는 언어 모델은 아래와 같이 표현할 수 있다.
- 번째까지의 단어 시퀀스가
x_train - 번째 단어가
y_train - 위와 같이 학습된 언어 모델을 테스트모드로 가동하면, 일정한 단어 시퀀스 뒤에 다음 단어를 계속해서 예측해 낼 수 있음 -> 문장 생성기
Text Generation 작사가
순환신경망(RNN) 을 이용한 언어 모델로 여러 노래의 가사들을 학습해서 스스로 가사를 생성해내는 인공지능을 구현하였다.
자세한 코드는 아래의 GitHub 링크를 참조
GitHub : Text_Generation_Lyricist
데이터 불러오기
아래와 같은 노래 가사 데이터를 이용한다.

데이터 정제
불러온 데이터 중에서 필요한 부분만 사용하기 위해 다음의 데이터 정제 과정을 수행한다.
- 공백인 문장
- 가수 파트 구분을 위해 대괄호가 포함된 부분
- 'Young money Verse 1: Jason Derulo thousand different favors' 와 같이 파트 구분이 되고 앞뒤 내용이 이어지지 않는 문장이 많음
- 중복되는 문장

전처리
정규표현식을 사용하여 데이터 문장을 사용하기편하도록 전처리한다.
- 소문자로 바꾸고, 양쪽 공백을 지움
- 특수문자 양쪽에 공백을 넣음
- 여러개의 공백은 하나의 공백으로 바꿈
- a-zA-Z?.!,¿가 아닌 모든 문자를 하나의 공백으로 바꿈
- 다시 양쪽 공백을 지움
- 문장 시작에는
<start>, 끝에는<end>를 추가

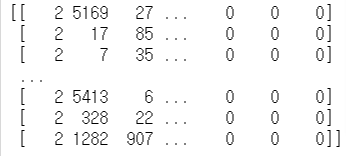
토큰화 (Tokenize)
Tensorflow 의 Tokenizer와 pad_sequences 을 사용하여 문장을 일정한 기준으로 쪼개는 토큰화 (Tokenize) 를 진행한다.

평가 데이터셋 분리
sklearn.model_selection.trian_test_split 을 이용해 training set 과 test set 을 분리한다.

모델 학습 및 평가
LSTM 레이어를 사용하여 모델을 생성하였다.

위 모델을 학습하고 실제로 문장을 생성시켜보았다.

위와 같이 여러 단어를 통해 모델을 실행시킨 결과 실제 가사에 나올 법한 가사들이 생성되었다.
프로젝트 정리
많은 가사들을 불러와 데이터를 전처리하였다.
- 가수 파트를 구별하는 대괄호가 포함된 문장 삭제
- 중복되는 문장 삭제
- 15000개의 단어를 기억할 수 있는 tokenizer 생성
- 토큰화 후 토큰 개수 15개 이상인 문장 삭제
그것을 이용해 모델을 학습시켜 가사를 생성해내는 모델을 만들었다.
파라미터 값을 데이터에 알맞게 설정하여 모델을 학습시켰다.
학습시킨 모델이 i was born to make you happy, you are the greatest thing to me 와 같이 굉장히 감성적인 가사를 쓸 수 있는 것을 확인하였다.
하지만 여전히 문장 문법이 어색하거나, 내용이 어색한 문장도 종종 생성되었다.
학습시키는 데이터 수를 늘리면 이러한 문제가 줄어들고 점점 사람이 만들어내는 가사와 비슷한 가사들이 생성될 것이다.
이번 프로젝트를 통해 인공지능이 문장을 이해하는 방식에 대해 알아볼 수 있었고 어떻게 모델을 학습시켜서 작문을 하게 하는지에 대한 전체적인 구조에 대해 이해할 수 있었다.
