✅ 핵심내용
- 딥러닝과 머신러닝의 차이
- 딥러닝의 '표현 학습' 이해
- 함수 차원에서 신경망 모델 이해
- 선형성에 대한 이해
머신러닝과 딥러닝
딥러닝과 머신러닝, 이 둘이 뭐가 다른가?
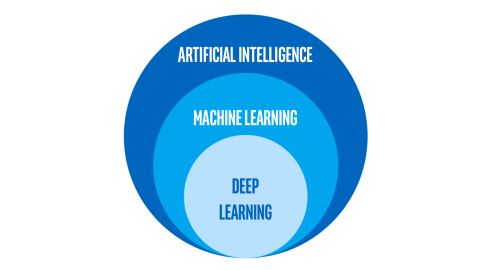
관점에 따라 답이 다양하게 달라질수 있지만 일반적으로 인공지능이 가장 큰 범주이고, 그 안에는 머신러닝이, 또 그 안에 딥러닝이 있다고 설명한다.
- 인공지능 : 사람이 직접 프로그래밍 한 내용이 아니라 기계가 자체 규칙 시스템을 구축하는 과학
- 머신러닝 : 데이터를 통해 스스로 학습하는 방법론. 학습한 내용을 토대로 판단이나 예측
- 딥러닝 : 학습하는 모델의 형태가 신경망인 방법론
딥러닝에서의 표현(Representation)
딥러닝의 대가 중 한 명인 조슈아 벤지오는 다음과 같이 딥러닝을 정의하였다.
Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.
뇌의 신경 구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는, "합성된 함수를 학습시켜서 풍부하면서도 유용한 '내재적 표현'을 찾아내는 machine을 구축하는 것"이다.
여기서 내재적 표현, 즉 internal represntation 은 딥러닝에서 아주 중요한 개념이다.
추상적이고 내재적인 표현들을 사람의 개입 없이 딥러닝만으로 나타낼 수 있는 모델을 학습시키는 것이 딥러닝의 궁극적인 목표이다.
즉, 어떠한 데이터를 입력 받으면 신경망 내부의 복잡한 함수 연산을 통해 최종적으로 피처(Feature), 혹은 표현(Representation)이라고 할 수 있는 '숫자로 이루어진 벡터'를 추출해냅니다. 이것이 머신러닝과 딥러닝의 차이점 중 하나라고 할 수 있다.
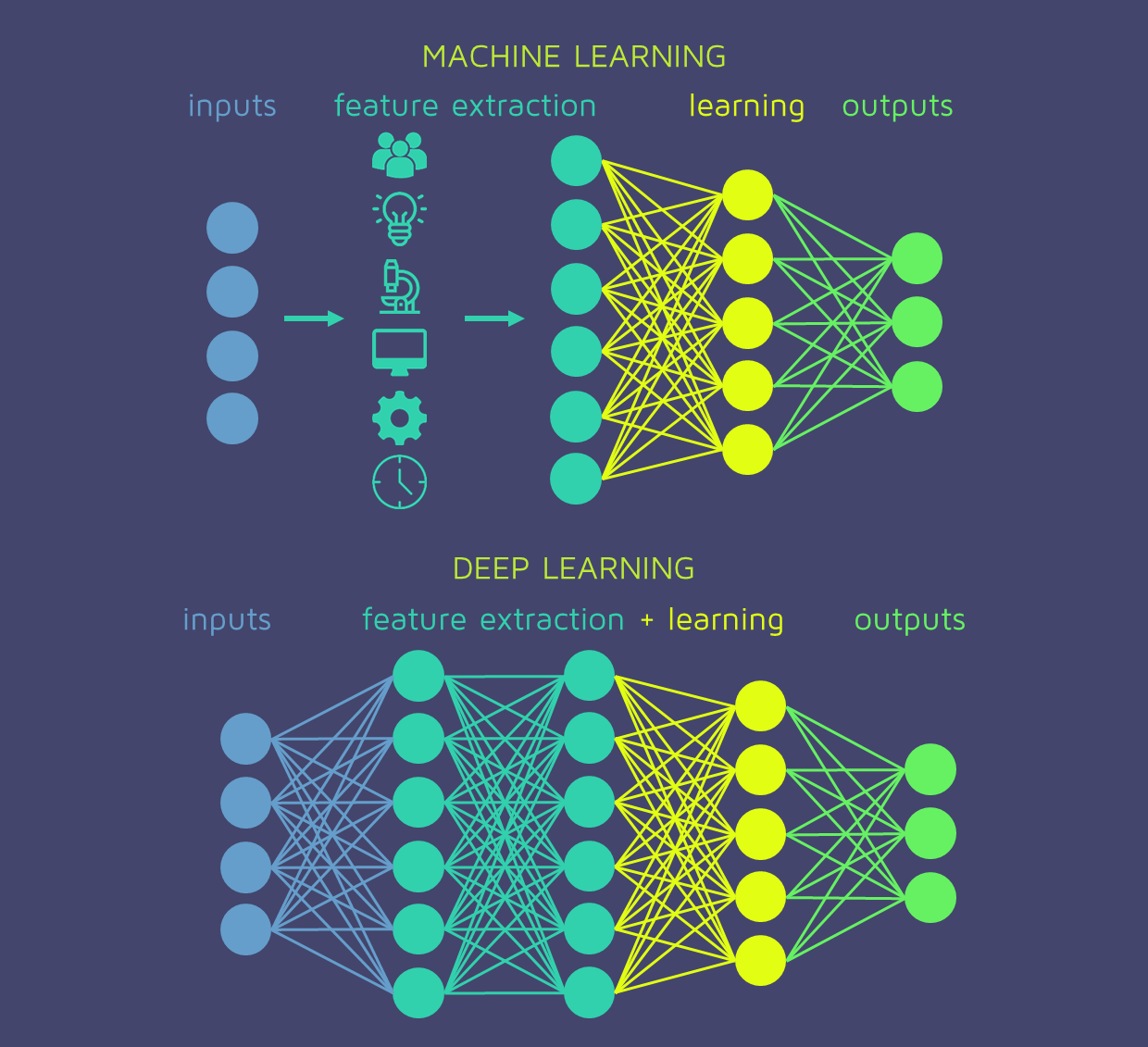
출처 : https://quantdare.com/what-is-the-difference-between-deep-learning-and-machine-learning/
딥러닝의 본질은 이렇게 데이터로부터 내재된 표현을 추출해내는 것이며, 이는 모델을 Gradient Descent 기반의 학습으로 수행할 수 있다.
딥러닝을 관통하는 철학
- 행동주의
- 심리학을 과학적으로 접근하고자 하는 시도를 가진 분야로, 철저하게 경험적이고 실증적으로 인간의 내면을 접근
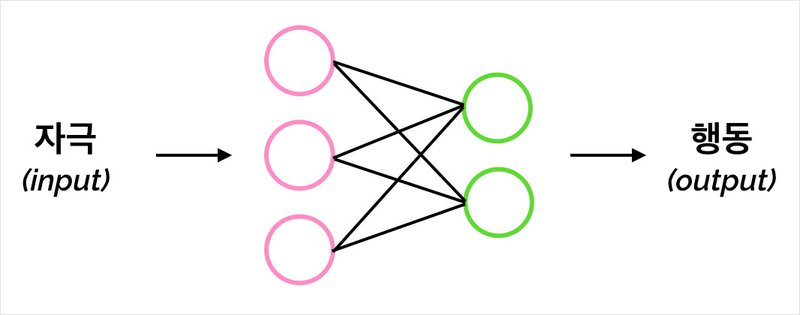
- '자극 → 행동'의 관점
- 자신에게 유리한 결과를 가져다주는 행동을 알게 된다면 그 행동의 빈도를 높인다는 '강화이론'은, 머신러닝의 방법론 중 '강화학습(Reinforcement Learning)'의 근간이 되는 이론
- 인지주의
- 인간이 자극을 받은 후 내면에서 정보를 처리하고 가공하는 의식이 존재함 주장
- '자극 → (정보처리) → 행동' 의 관점
- 인간의 마음을 일종의 정보 처리 체계로 보고 접근하고, 이에 따라 인간의 뇌가 정보를 처리하는 과정에 집중
- 연결주의
- 자극으로부터 반응을 하기까지의 과정에서 뉴런과 같이 연결되어 있는 모형이 정보를 처리
- 처음에는 '백지' 상태이며, 다수의 사례를 주고 '경험'함으로써 스스로 천천히 '학습' 주장
- 딥러닝은 바로 이 연결주의를 따름
- 딥러닝
- 뇌의 뉴런이 얽히고 섥혀서 연결되어 있는 모양을 본딴 '인공 신경망' 모델
- 자극(input)을 받아 내부에서 일련의 정보처리 과정을 거친 후 반응(output)
- 신경망 내부에서는 하나의 데이터를 여러 형태로 바꾸어가며 표현(representation)을 해 나가다가, 최종적으로 의도한 형태의 데이터를 출력
신경망
어떤 입력을 받으면 신경망 내부에서 처리 과정을 거쳐 출력은 만들어낸다.
이러한 구조는 흔히 입력을 받아 출력을 하는 함수의 형태 와 같다.

신경망은 입력을 받은 후 내부에서 일련의 연산 과정을 거쳐 출력을 내는 거대한 함수라고 볼 수 있다.
함수의 역할
그럼 일반적인 함수의 역할은 다음과 같다.
-
Relation : x 와 y의 관계를 나타낼 수 있는 도구
- 간단한 예로 라는 함수가 있을때, x 가 변하는 정도에 따라 y가 얼마나 변하는지 알 수 있다. 즉, 함수는 x 와 y 사이에 종속적인 관계를 가지게 한다.
-
Transformation : x 를 변환해주는 도구
- 함수를 변환(Transformation)의 관점에서 볼 때, 필수적으로 이해해야 하는 개념은 바로 선형 변환(Linear Transformation)이다.
- Linear Transformation은 행렬곱 연산과 연관되어 있다.
- 변환하기 전의 vector를 입력받아 변환된 후의 vector를 출력
- 2차원 평면에서의 Transformation은 축(grid)을 '옮기는(move)' 역할
- Linear Transformation이 되려면 두 가지 조건 : 변환된 축은 직선, 변환 후에도 원점은 그대로.
- Mapping : x 의 공간에서 y 의 공간으로 매핑해주는 도구
- 하나의 벡터를 다른 벡터로 매핑 -> Transformation
- 함수의 입력과 출력이 스칼라(Scalar)인지, 벡터(Vector)인지에 따라 구분
머신러닝,딥러닝에서의 함수
머신러닝, 딥러닝에서의 함수, 즉 모델은 정확히 단 하나로 정해져있는 함수도 아닐뿐더러, 그 함수가 어떤 형태인지를 모른다. 주어진 것은 데이터 뿐이다.
따라서 데이터에 가장 잘 근사할 수 있는 함수를 찾는 것이 머신러닝, 딥러닝에서 해야할 일이다.
데이터를 잘 표현/예측할 수 있는 모델(함수)를 찾아내기 위한 두 가지 단계가 있다.
-
- 모델을 어떤 함수 형태로 나타낼 것인지 함수 공간을 정하는 단계
- 어떠한 모델을 쓸지 (선형함수, Decision Tree, 신경망 모델 등등) 결정
-
- 함수 공간을 정했다면 그 안에서 최적의 함수를 찾아 학습
- 신경망의 경우, 경사하강법으로 최적의 함수를 찾음
