✅ 핵심내용
- 정칙화(Regularization),정규화(Normalization) 개념 이해
- L1 regularization과 L2 regularization의 차이
- Lp norm, Dropout, Batch Normalization 구현
Regularization과 Normalization
Regularization과 Normalization 이 두 개념은 둘 다 한국어로 번역할 때 정규화 로 변역될 때가 많아서 헷갈리는 경우가 많다.
Regularization : 정칙화
- 과적합(overfitting) 을 해결하기 위한 방법 중의 하나
- train loss는 약간 증가하지만 결과적으로, validation loss나 최종적인 test loss를 감소시키려는 목적
- L1, L2 Regularization, Dropout, Batch normalization 등이 있음
Normalization : 정규화
- 데이터의 형태를 좀 더 의미 있게, 혹은 training 에 적합하게 전처리하는 과정
- 데이터를 z-score로 바꾸거나 minmax scaler를 사용하여 0과 1사이의 값으로 분포를 조정하는 등의 방법 존재
- 모든 피처의 범위 분포를 동일하게 하여 모델이 풀어야 하는 문제를 좀 더 간단하게 바꾸어줌
- ex. 금액과 같은 큰 범위의 값(10,000 ~ 10,000,000)과 시간(0 ~ 24) 의 값이 들어가는 경우, 학습에 방해를 받을 수 있음 --> 모두 0~1 사이 값으로 변환
Iris dataset의 회귀 문제를 풀면서 Regularization와 Normalization의 간단한 예제를 살펴보았다.
자세한 코드는 아래의 Github 를 참조
GitHub Link : Regularization_Normalization
Normalization
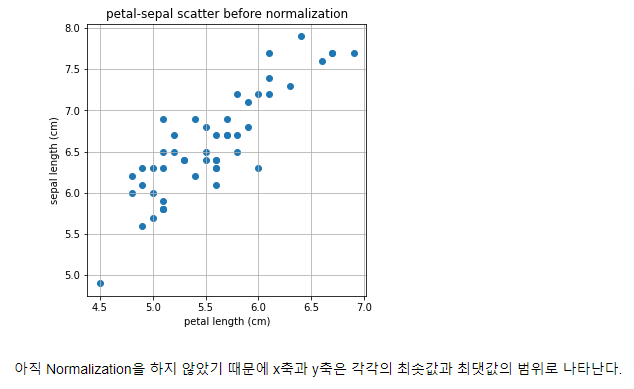
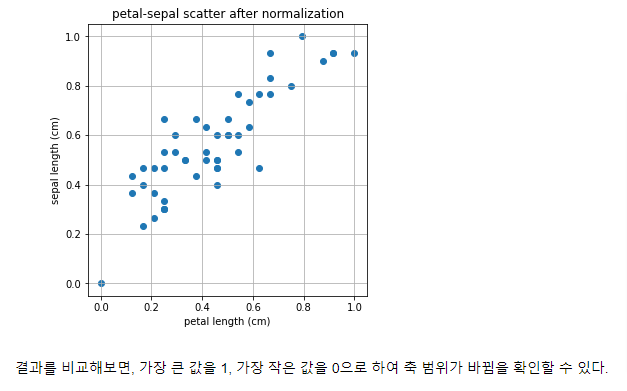
Regularization
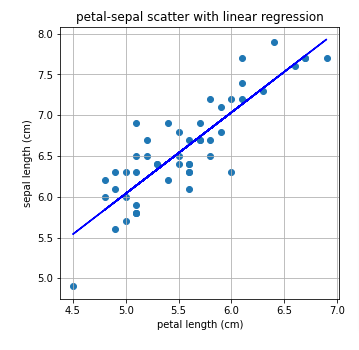
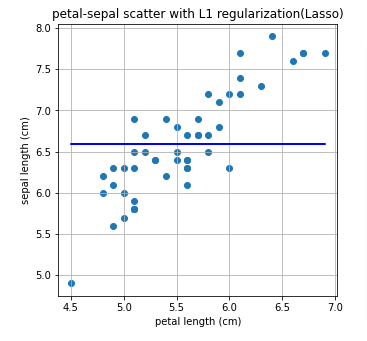
기울기가 0으로 나오는 것을 확인 할 수 있다. Lasso 방법은 제대로 문제를 풀어내지 못하는 것 같다. 그 이유는 아래에 정리하였다.
L1 Regularization
Regularization 은 손실 함수에 정규화 항을 더해 가설 함수를 평가하는 기준을 바꿈으로서 overfitting 을 방지한다.
L1 regularization은 아래와 같은 식으로 정의된다.
L1 regularization 의 핵심 부분은 부분이다.
위에서 L1 Regularization 의 기울기가 0으로 나온 이유는 X가 1차원 값인 선형회귀분석 같은 경우 에 대해서 미분하는 과정에서 가 사라지므로, L1 Regularization이 의미가 없기 때문이다.
따라서 L1 Regularization을 사용할 때는 X가 2차원 이상인 여러 컬럼 값이 있는 데이터일 때 실제 효과를 볼 수 있다.
컬럼 수가 많은 데이터에서의 L1 regularization 비교
총 13개의 값을 갖는 wine dataset 을 사용해서 각각 Linear regression 과 L1 regularization 로 문제를 풀고, 계수(coefficient)와 절대 오차(mean absolute error), 제곱 오차(mean squared error), 평균 제곱값 오차(root mean squared error)를 비교해보자.
자세한 코드는 아래의 Github 를 참조
GitHub Link : Regularization_Normalization


결과 비교
- coefficient 부분을 보시면 Linear Regression과 L1 Regularization의 차이가 두드러짐
- Linear Regression에서는 모든 컬럼의 가중치를 탐색하여 구함
- L1 Regularization에서는 총 13개 중 7개를 제외한 나머지의 값들이 모두 0임
- Error 부분에서는 큰 차이가 없었지만, 우리가 어떤 컬럼이 결과에 영향을 더 크게 미치는지 확실히 확인할 수 있음
- 차원 축소와 비슷한 개념으로 변수의 값을 7개만 남겨도 충분히 결과를 예측함을 알 수 있음
L2 Regularization
L2 Regularization 은 아래의 식으로 정의한다.
L2 Regularization 에서는 부분이 핵심 내용이 된다.
L1 / L2 Regularization의 차이점
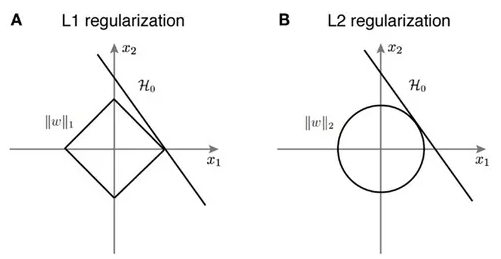
- L1 Regularizaion(Lasso)는 를 이용하여 마름모 형태의 제약조건이 생김
- L1 Regularization은 가중치가 적은 벡터에 해당하는 계수를 0으로 보내면서 차원 축소와 비슷한 역할을 하는 것이 특징
- L2 Regularization은 이므로 원의 형태
- L2 Regularization은 0이 아닌 0에 가깝게 보내지만 제곱 텀이 있기 때문에 L1 Regularization보다는 수렴 속도가 빠름
데이터에 따라 적절한 Regularization 방법을 활용하는 것이 좋다.
Lp norm
norm은 벡터나 행렬, 함수 등의 거리를 나타내는 것으로 딥러닝을 배우는 과정에서는 주로 벡터, 좀 더 어렵게는 행렬의 Norm 정도가 사용된다.
vector norm
벡터의 Norm은 L1 / L2 Regularization에서 사용한 Norm으로 아래와 같이 정의된다.
p=∞ 인 Infinity norm의 경우는 가장 큰 숫자를 출력한다.
matrix norm
행렬의 norm의 경우는 벡터와 조금 다르며, 주로 인 경우만 알면 된다.
p=1인 경우에는 컬럼의 합이 가장 큰 값이 출력되고, p=\inftyp=∞인 경우에는 로우의 합이 가장 큰 값이 출력된다.
Dropout
드롭아웃 기법이 나오기 전의 신경망은 fully connected architecture로 모든 뉴런들이 연결되어 있었다.
드롭아웃이 나오면서 확률적으로 랜덤하게 몇 가지의 뉴럴만 선택하여 정보를 전달하는 과정을 가진다.
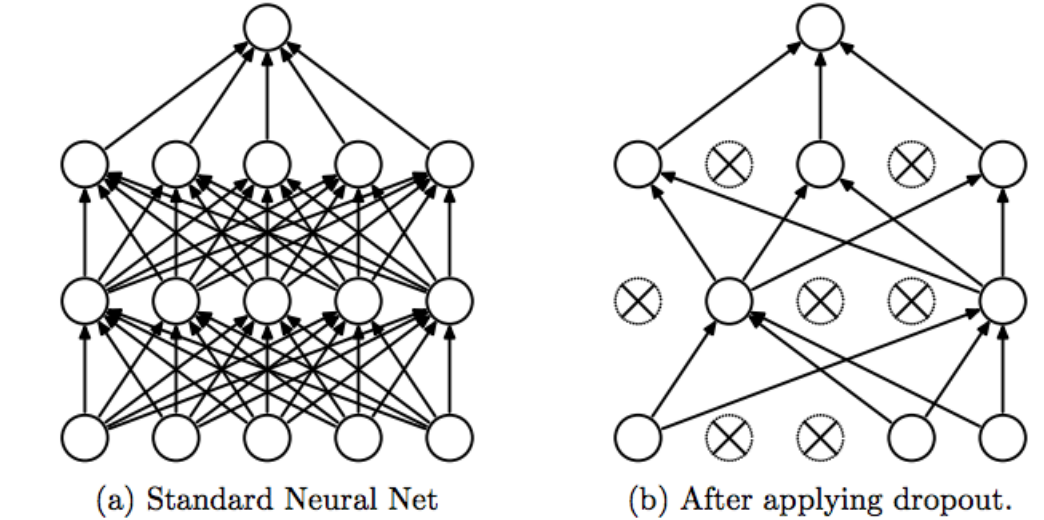
- 드롭아웃은 오버피팅을 막는 Regularization layer 중 하나
- 몇 가지의 값들을 모든 뉴런에 전달하는 것이 아닌 확률적으로 버리면서 전달하는 기법
- 확률을 너무 높이면, 제대로 전달되지 않으므로 학습이 잘되지 않음
- 확률을 너무 낮추는 경우는 fully connected layer와 같음
fashion mnist 데이터셋을 이용해 dropout 을 구현하였다.
자세한 코드는 아래의 Github 를 참조
GitHub Link : Regularization_Normalization
Batch Normalization
Batch Normalization은 gradient vanishing, explode 문제를 해결하는 방법이다.
fully connected layer와 Batch Normalization layer를 추가한 두 실험을 비교했다.
중점적으로 봐야할 내용은 정확도 비교와 속도의 차이 이다.
자세한 코드는 아래의 Github 를 참조
GitHub Link : Regularization_Normalization
