.png)
✅ 핵심내용
- 확률 변수로서의 모델 파라미터
- posterior, prior, likelihood 의 관계
- MLE, MAP 비교
확률 변수로서의 모델 파라미터
아래와 같이 일차함수 모델이 존재할때,
실수 는 라는 함수로 표현되는 모델의 형태를 결정하는 파라미터로 작용한다.
이때, 가 위치하는 공강을 파라미터 공간(parameter space) 이라 한다.
간단한 시각화를 위해 [-10, 10)[−10,10) 구간에서 랜덤으로 샘플링하여 모델 공간에 매핑하면 아래와 같이 나타내어진다.
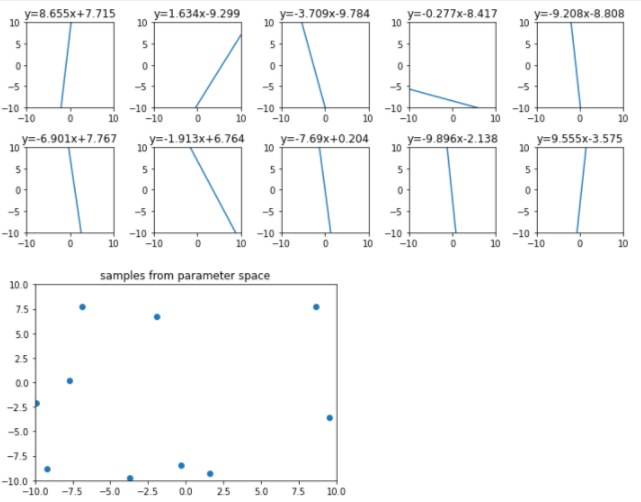
위 그림에서 파라미터 공간에 주어진 확률 분포를 평균이 (1,0) 인 정규분포로 보면 아래와 같이 나타낼 수 있다.
- 에서 와 의 값이 각각 1과 0에 가까울 확률이 크다
- 모델이 에 가까울 확률이 크다.
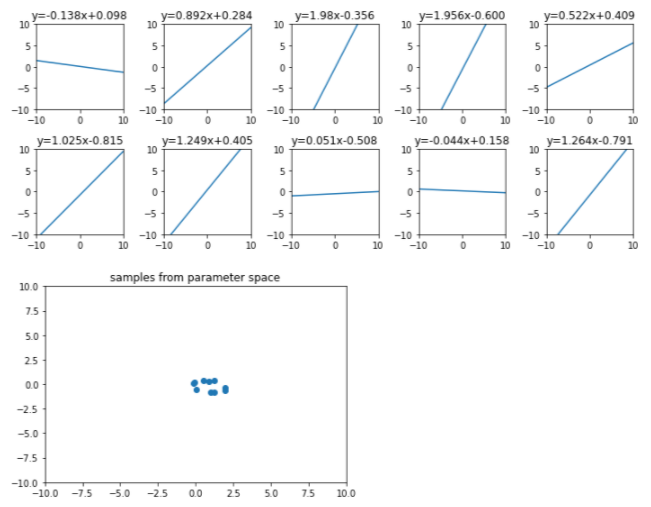
- 평균이 (1,0) 이고 표준편차가 0.5인 정규분포에서 10개의 점을 랜덤으로 뽑아 대응하는 일차함수를 나타내면 아래와 같다.
위 과정의 자세한 코드는 아래의 GitHub 에 기록하였다.
GitHub Link : Likelihood_MLE_MAP
posterior, prior, likelihood 의 관계
- 베이시안 머신러닝 핵심
- 베이시안 머신러닝 모델은 데이터를 통해 파라미터 공간의 확률 분포를 학습함
- 모델 파라미터를 고정된 값이 아닌 불확실성(uncertainty)을 가진 확률 변수로 보고, 데이터를 관찰하면서 업데이트되는 값으로 보는 것이 핵심
-
prior (prior probability, 사전 확률) :
- 데이터를 관찰하기 전 파라미터 공간에 주어진 확률 분포
- 위의 예시에서는 평균이 (1,0) 이고 표준편차가 0.5인 정규분포
- prior는 일반적인 정규분포가 될 수도 있고, 데이터의 특성이 반영된 특정 확률 분포가 될 수도 있음
- $$
-
likelihood (가능도, 우도) :
- 만약, prior 분포를 고정시킨다면, 주어진 파라미터 분포에 대해서 데이터가 얼마나 일치하는지 계산하고 이것을 나타내는 값
- 파라미터 분포 가 정해졌을 때, 라는 데이터가 관찰될 확률
- 에 의해 결정되는 함수라는 것을 강조하기 위해서 가능도 함수를 로 표기하기도 함
-
데이터들의 likelihood 값을 최대화하는 방향으로 모델을 학습시키는 방법을 최대 가능도 추정 (maximum likelihood estimation, MLE) 라고 함
- posterior (posterior probability, 사후 확률) :
- 데이터 집합 가 주어졌을 때, 파라미터 의 분포
- posterior를 최대화하는 방향으로 모델을 학습시키는 방법을 최대 사후 확률 추정(maximum a posteriori estimation, MAP) 라고 함
MLE 와 MAP
MLE : 최대 가능도 추론
머신러닝의 목표가 데이터 포인트들을 최대한 잘 표현하는 모델을 찾는 것이고 그것은 결국 데이터 포인트들의 likelihood 값을 크게 하는 모델을 찾는 것이다.
데이터의 likelihood 값을 최대화하는 모델 파라미터를 찾는 방법이 최대 가능도 추론(maximum likelihood estimation, MLE) 이다.
MAP : 최대 사후 확률 추정
MAP는 데이터셋이 주어졌을 때 파라미터의 분포, 즉 에서 확률 값을 최대화하는 파라미터 를 찾는다.
직관적으로 말하면 '이런 데이터가 있을 때 파라미터의 값이 무엇일 확률이 제일 높은가?'의 문제이다.
MLE, MAP 비교
- MAP는 MLE와 비슷하지만 정규화 항에 해당하는 negative log prior 부분이 존재한다는 차이가 있다.
- MLE 모델보다 MAP 모델이 더 안정적
이상치(outlier)가 있는 데이터셋을 이용해서 MAP와 MLE를 비교해보자.
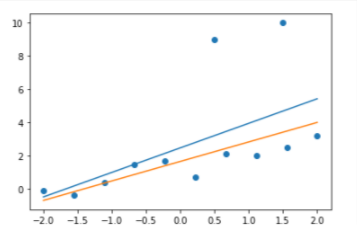
위 그래프에서 파란색 직선과 주황색 직선은 각각 MLE, MAP를 이용해 찾은 모델을 나타낸다.
- MLE(파란색)은 이상치 데이터까지 포함한 negative log likelihood를 감소시키기 위해 직선이 위로 치우쳐서 아래쪽 10개 데이터의 경향성에서는 약간 벗어남
- MAP(주황색)은 선은 이상치 데이터가 추가되어도 아래쪽 데이터에서 크게 벗어나지는 않음
- 이상치가 추가되었을때, 모델 파라미터의 변화는 MAP가 MLE 보다 작다. (MAP가 MLE보다 이상치에 영향을 덜 받음)
위 과정의 자세한 코드는 아래의 GitHub 에 기록하였다.
GitHub Link : Likelihood_MLE_MAP
