✅ 핵심내용
- 기본 SQL문
- 파이썬을 통해 DB를 연결하여 SQL 질의

Pandas DataFrame 활용하여 데이터 다루기
SQL 은 데이터 연산 작업이 가능한 쿼리(query) 를 위한 언어이다. 파이썬 기반의 프레임워크인 Pandas 를 이용하면 SQL과 유사한 기능을 수행 할 수 있다.
데이터 합치기 : merge, join, concat
Pandas 에서는 공통으로 연관이 되는 칼럼이 있는 경우에 대해 그 칼럼을 키(key)로 지정해 주어 합치기 연산을 할 수 있다.
pd.merge()
-
left: 왼쪽 데이터프레임 -
right: 오른쪽 데이터프레임 -
on: 두 데이터프레임의 기준열 이름이 같을 때 기준열 -
left_on: 기준열 이름이 다를 때, 왼쪽 기준열 -
right_on: 기준열 이름이 다를 때, 오른쪽 기준 -
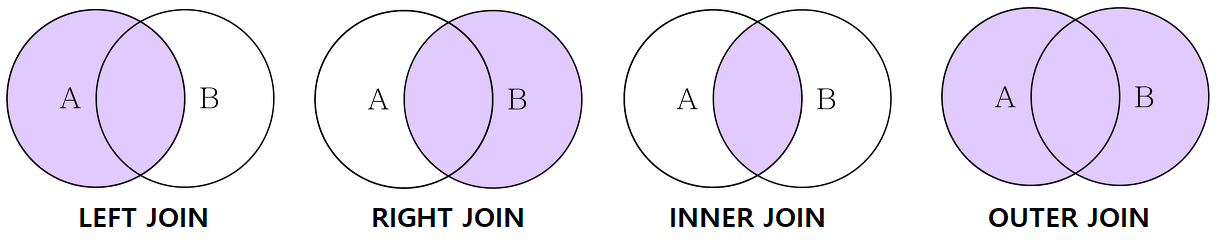
how: 조인 방식{left, right, inner, outer}기본값은inner
pd.concat()
- concatenating은 두 DataFrame을 행 방향(default로 할 시) or 열 방향으로 단순 연결하는 것을 의미
pd.merge()는 2개의 데이터를 콤마를 이용해서 넣어줬지만,pd.concat()는 리스트형식으로 연결
파이썬으로 DB 다루기
SQLite
SQLite는 서버의 필요 없이 DB의 파일에 기초하여 DB 처리를 구현한 임베디드 SQL DB 엔진이다. SQLite는 별도의 설치 없이, 쉽고 편리하게 사용할 수 있다는 점에서 많이 사용되고 있다.
-
Cursor는 SQL 질의(Query)를 수행하고 결과를 얻는데 사용하는 객체
- INSERT처럼 DB에만 적용되는 명령어를 사용한다면 Cursor를 안 사용할 수 있지만 SELECT와 같이 데이터를 불러올 때는 SQL 질의 수행 결과에 접근하기 위한 Cursor가 반드시 필요
- 이러한 이유로 습관적으로
.cursor()를 사용하는 것을 권함
-
commit
- 삽입, 갱신, 삭제 등의 SQL 질의가 끝났다면
.commit()를 호출해야 DB가 실제로 업데이트됨 select처럼 데이터를 가져오기만 하는 질의문의 경우에는commit()가 필요 없음commit()을 통해 데이터베이스에 데이터 변경이 실제적으로 반영되는 것을 데이터베이스에서는 트랜잭션(transaction) 관리라고 함
- 삽입, 갱신, 삭제 등의 SQL 질의가 끝났다면
-
close
commit()을 완료했다면close()를 이용해 DB와의 연결을 끊는 것으로 마무리
DDL문으로 테이블을 직접 생성하고 데이터의 생성/삭제/갱신 등을 처리할 때 필요한 DML문의 호출 방법에 대해 바로 위에서 다루었던 코드를 중심으로 설명하였다. 자세한 내용는 아래의 GitHub 를 참조
GitHub Link : SQL
SQL 기본
SQL 은 Structured Query Language 의 약자이다. 즉, DB라는 공간에 ‘정형화된’(일정한 형식으로 수집되는) 데이터가 차곡차곡 저장되어 있다. 이러한 DB를 특정 언어로 조회해서 가져오는데, 그때 사용하는 언어가 바로 SQL 이다.
쿼리의 기본 구조
| 형식 | 설명 |
|---|---|
SELECT ~ | 조회할 컬럼명을 선택 |
FROM ~ | 조회할 테이블명을 지정 (위치와 테이블명을 입력) |
WHERE ~ | 질의할 때 필요한 조건을 설정 |
GROUP BY ~ | 특정 컬럼을 기준으로 그룹을 지어 출력 |
ORDER BY ~ | SELECT 다음에 오는 컬럼 중 정렬이 필요한 부분을 정렬 (기본 설정 : 오름차순) |
LIMIT 숫자 | Display하고자 하는 행의 수를 설정 |
| SELECT * FROM 테이블명 | 테이블에 있는 모든 컬럼명을 추출하고 싶을 때 사용. 별표(*)는 ALL을 의미 |
| SELECT 컬럼1, 컬럼2, ... FROM 테이블명 | 추출하고 싶은 컬럼명을 쉼표로 연결하여 나열 |
| SELECT DISTINCT 컬럼1 FROM 테이블명 | 선택한 컬럼의 전체 값이 아닌, 중복을 제거한 값만 불러옴 |
| SELECT DISTINCT 컬럼1,컬럼2,컬럼3 FROM 테이블명 | 컬럼1,2,3 조합 중에서 unique한 값만 불러옴 |
| SELECT COUNT(*), COUNT(컬럼) FROM 테이블명 | COUNT(*) : 테이블 전체의 row의 수를 출력 COUNT(컬럼) : 해당 컬럼의 전체 row수를 출력 |
| SELECT COUNT(DISTINCT 컬럼) FROM 테이블명 | 래당 컬럼의 전체 row수가 아닌, 중복값을 제거한 row수를 출력 |
| SELECT 컬럼1, COUNT(*) FROM 테이블명 GROUP BY 컬럼1; | - 컬럼의 나열과 COUNT 가 같이 쓰이면 꼭 GROUP BY 구문을 사용해야함 - COUNT 앞에 나열된 컬럼의 개수만큼 그룹화 시켜줌 |
| SELECT 컬럼1, 컬럼2, COUNT(DISTINCT 컬럼3) FROM 테이블명 GROUP BY 컬럼1, 컬럼2; | 컬럼1 * 컬럼2의 조합에 대한 컬럼 3의 row수를 출력 |
데이터 타입
Oracle, SQL Server, PostgreSQL, MySQL, SQLite 등등 SQL의 종류가 다양한 만큼 데이터 타입도 다양하고 조회 및 조작어도 세밀하게 다르다.
| 데이터 형식 | 종류 | 설명 |
|---|---|---|
| 숫자형 | TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT, FLOAT, DOUBLE,.. | 각 종류마다 사용되는 바이트 수와 최소값, 최대값의 범위가 다름 |
| 문자형 | CHAR, VARCHAR,BLOB,TEXT,STRING,... | 저장되는 문자의 개수에 따라 종류가 나눠짐 |
| 날짜형 | DATE,DATETIME,TIMESTAMP,... | 저장공간과 형태에 따라 종류가 나눠짐 |
다양한 조건으로 조회
SELECT * FROM 테이블명
WHERE ~위와 같은 기본 적인 형태로 조건을 통해 원하는 형태로 테이블을 가져올 수 있다. WHERE 조건절을 몇 개씩 더 할 수도 있다.
SELECT * FROM 테이블명
WHERE
조건1
AND 조건2
AND 조건3
AND (조건 4 OR 조건5);JOIN
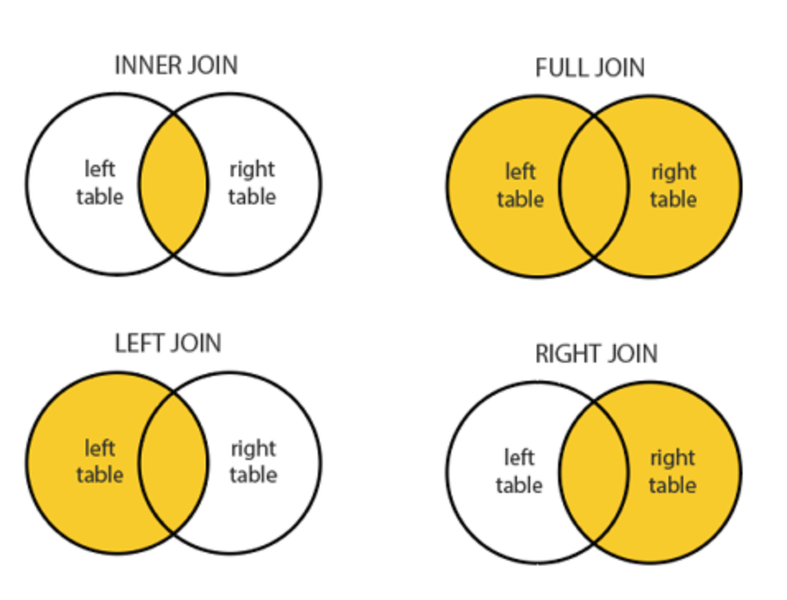
- INNER JOIN : A 테이블과 B 테이블의 교집합을 조회
- LEFT JOIN : (기준은 A 테이블) A 테이블을 기준으로 해서 B 테이블은 공통되는 부분만 조회
- RIGHT JOIN : (기준은 B 테이블) B 테이블을 기준으로 해서 A 테이블은 공통되는 부분만 조회
- FULL JOIN : A 테이블과 B 테이블 모두에서 빠트리는 부분 없이 모두 조회
SQL에 대한 실습을 아래의 GitHub 에 기록하였다.
GitHub Link : SQL
