
들어가며
이 글은 Dataquest.io의 Machine Learning Fundamentals: Predicting Airbnb Prices를 읽고 번역한 글입니다.
머신러닝은 현재 IT 산업에서 가장 핫한 분야 중 하나입니다. 그 증거로 지난 3년 간 머신러닝에 대한 검색은 350% 증가했습니다.. 그 인기에도 불구하고, 머신러닝은 여전히 이해하기 어려운 분야입니다. 라이브러리를 사용하면 손쉽게 데이터 분석을 할 수 있지만, 정교한 작업을 위해서는 높은 수준의 수학과 선형대수를 이해해야 합니다.
이 튜토리얼은 머신러닝의 가장 기본적인 개념을 소개하기 위해 작성되었습니다. 먼저 모델의 작동 방식을 이해하고, 그 후에는 기초적인 예측 모델을 만들어보도록 하겠습니다.
튜토리얼은 데이터 사이언스 강좌 중 하나인 Dataquest Machine Learning Fundamentals course에 기초하고 있습니다. 해당 강좌는 머신러닝을 좀 더 디테일하게 다루고, 따라 작성할 수 있는 코드 샘플도 제공됩니다.
본격적으로 시작하기 전에 정확히 머신러닝이 무엇인지 먼저 살펴봅시다.
What is machine learning?
머신러닝은 모델로 알려진 시스템을 만드는 일련의 과정을 가리킵니다. 데이터를 통해 모델을 학습시키고, 패턴을 발견하여 이를 새로운 데이터에 적용하면 어떤 값을 예측할 수 있습니다.
if-else 조건문으로 구성된 기존의 시스템과 머신러닝의 가장 중요한 차이점은 머신러닝은 규칙 기반 시스템이 아니라는 점입니다. 즉, 만약 학생이 수업을 절반 이상 출석하지 않으면 자동적으로 F 처리된다와 같은 규칙은 모델에는 존재하지 않습니다. 머신러닝은 과거의 데이터를 기반으로 예측 대상에 대해서 학습하고, 그 결과를 새로운 데이터에 적용시키는 방식에 가깝습니다.
이제 현재 거주 중인 집의 적절한 판매 가격을 설정해야 된다고 생각해봅시다. 가장 먼저 떠오르는 방법은 주변 지역의 최근 주택 판매 가격표에서 내 집과 가장 비슷한 집의 판매 가격을 참고하는 것입니다. 여기서 가격 참고의 대상이 되는 집을 observation이라고 부릅니다. 또 비교 대상을 결정할 때는 집평수나 침실, 욕실의 수 등을 기준으로 삼는데 이들 각각을 feature라고 부릅니다.

비슷한 집을 몇 개 찾은 후에 그 가격을 살펴보고 해당 그룹의 평균 가격을 판매하려는 집의 가격으로 결정할 수 있는 것이죠.
위 예시에서 우리는 주변 지역 주택의 데이터로 학습시킨 모델을 통해 아직 관측한 적 없는 새로운 데이터인 판매하려는 주택의 가격을 결정할 수 있었습니다.
여기서 예측의 대상이 되는 가격은 target 이라 부릅니다.
우리가 작성할 모델도 위와 비슷한 전략을 사용합니다. 이번 모델은 파이썬을 통해 Airbnb에 등록할 숙소의 적절한 숙박료를 예측하는데 사용될 것입니다.
이 포스트는 파이썬의 pandas 라이브러리에 어느 정도 익숙하다고 가정합니다.
Predicting Airbnb rental prices
Airbnb는 다른 사람에게 거주 공간을 단기 임대할 수 있도록 중개하는 플랫폼입니다. 2008년에 세워진 Airbnb의 회사 가치는 2016년 300억 달러 상당에서 현재는 전 세계 어떤 호텔 체인보다도 높습니다.
Airbnb에 처음 호스팅하는 사람이 겪는 어려움 중 하나는 적절한 숙박료를 정하는 일입니다.
Airbnb에 등록된 숙소라면 어떤 지역이든 숙박객은 가격, 침실의 개수, 숙소의 종류 등과 같은 기준에 따라 자유롭게 숙소를 고를 수 있습니다. 또 Airbnb에서는 누구나 호스트가 될 수 있기 때문에 호스트가 매기는 숙박료는 시장의 성격에 큰 영향을 받습니다:
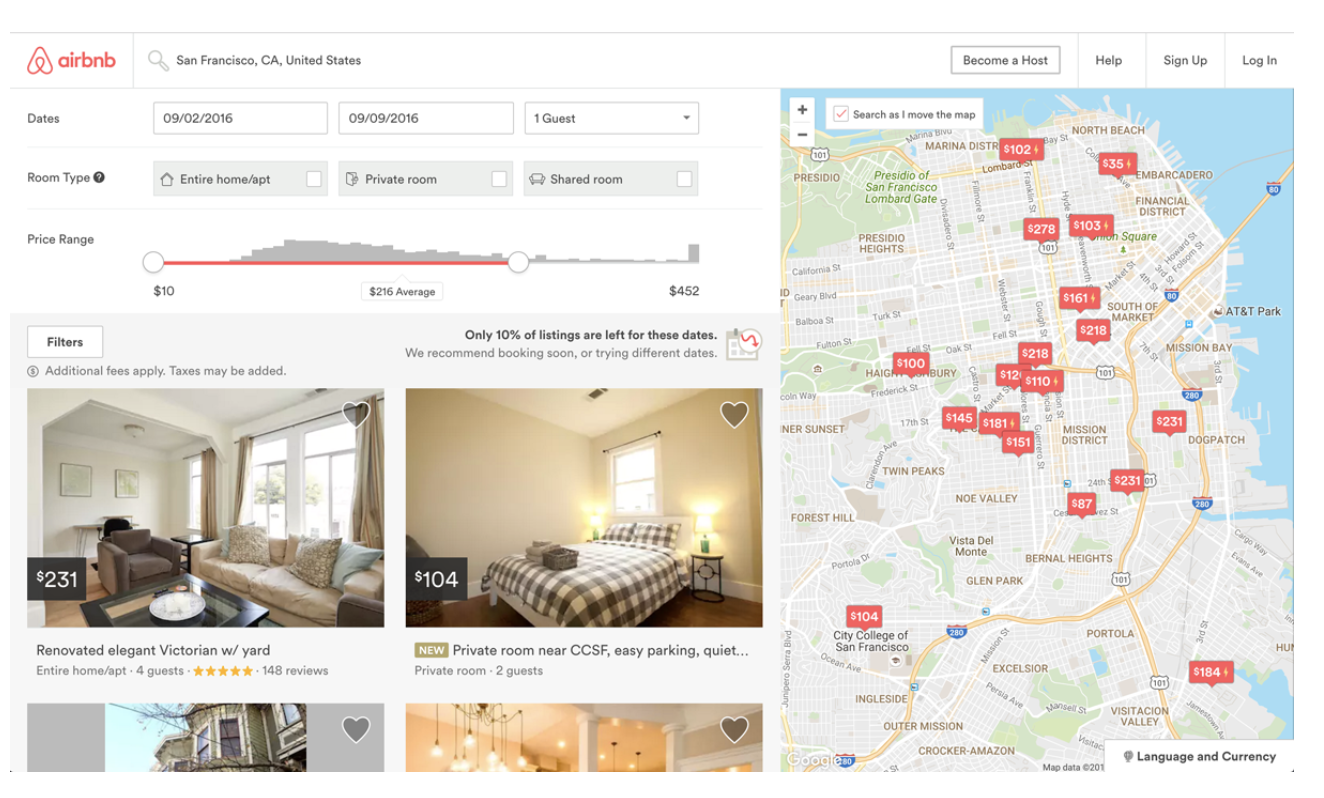
만약 호스트가 시장 가격 이상으로 숙박료를 비싸게 매기면 숙박객은 다른 숙소를 찾을 것입니다. 반대로 숙박료를 너무 낮게 매기면 충분한 이윤을 얻을 수 없습니다.
이때 가능한 한 가지 전략은:
내 숙소와 비슷한 몇 개의 숙소를 찾은 다음, 이들 숙소의 평균 가격을 숙박료로 정하는 것입니다. 우리는 k-nearest neighbors라고 불리는 알고리즘을 이용해 이 과정을 자동화해줄 머신러닝 모델을 만들겁니다.
먼저 데이터셋부터 살펴봅시다.
Our Airbnb Data
Airbnb 측에서 숙소 관련 데이터를 직접 제공하지는 않지만 Inside Airbnb라는 사이트에서 세계 주요 대도시의 숙소 데이터 샘플을 제공하고 있습니다. 이 포스트에서는 Washington, D.C.의 2015년 10월 3일 숙소 데이터를 사용할 것입니다. 엑셀 파일의 각 행은 실제 Washington, D.C. 지역에서 그 날 예약 가능한 숙소 데이터입니다.
데이터셋을 조금 더 사용하기 편한 형태로 만들기 위해 쓸모 없는 몇 개 칼럼을 제거하고 파일 이름을 dc_airbnb.csv로 바꿨습니다. 다음은 몇 가지 중요한 칼럼입니다.
accommodates: 수용 가능 인원
bedrooms: 침실 개수
bathrooms: 욕실 개수
beds: 침대 개수
price: 숙박료
minimum_nights: 최저 숙박료
maximum_nights: 최고 숙박료
number_of_reviews: 후기 개수
이제 이 데이터를 pandas로 읽고, 데이터의 크기와 첫 몇 개 숙소를 살펴봅시다.
import pandas as pd
dc_listings = pd.read_csv('dc_airbnb.csv')
print(dc_listings.shape)
dc_listings.head()(3723, 19)테이블 사진은 가로로 너무 길어서 보기가 불편할 것 같아 제외했습니다.
The K-nearest neighbors algorithm
K-nearest neighbors (knn) 알고리즘은 이전에 예시로 들었던 과정과 매우 흡사합니다. 그 과정을 더 자세하게 들여다봅시다.
가장 먼저 비교를 위해 내 숙소와 유사한 숙소들을 선택합니다.
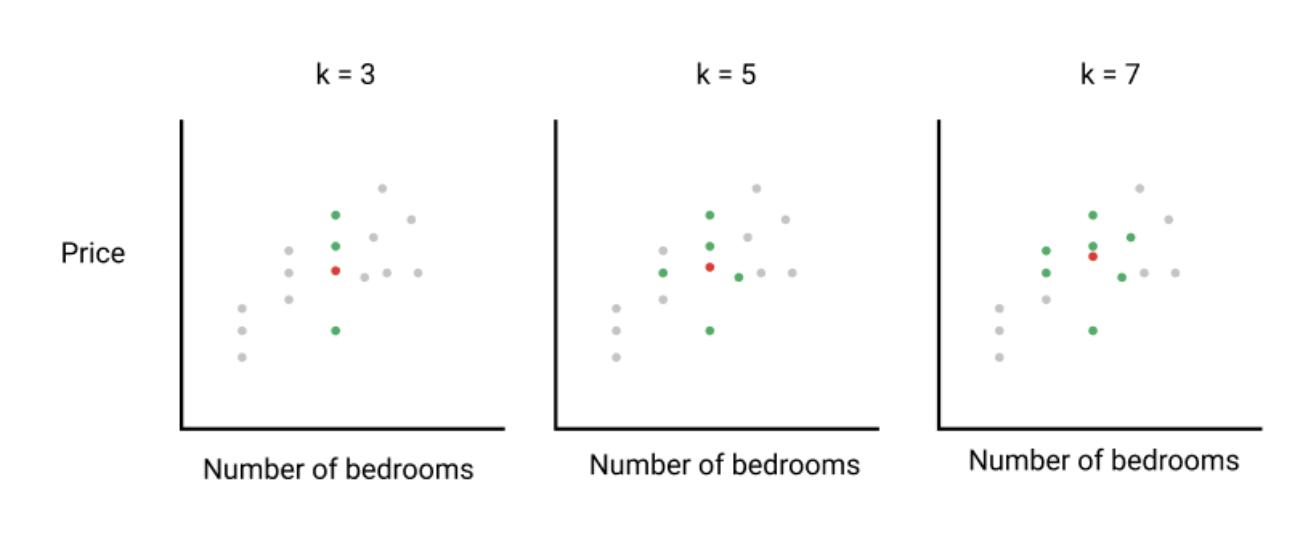
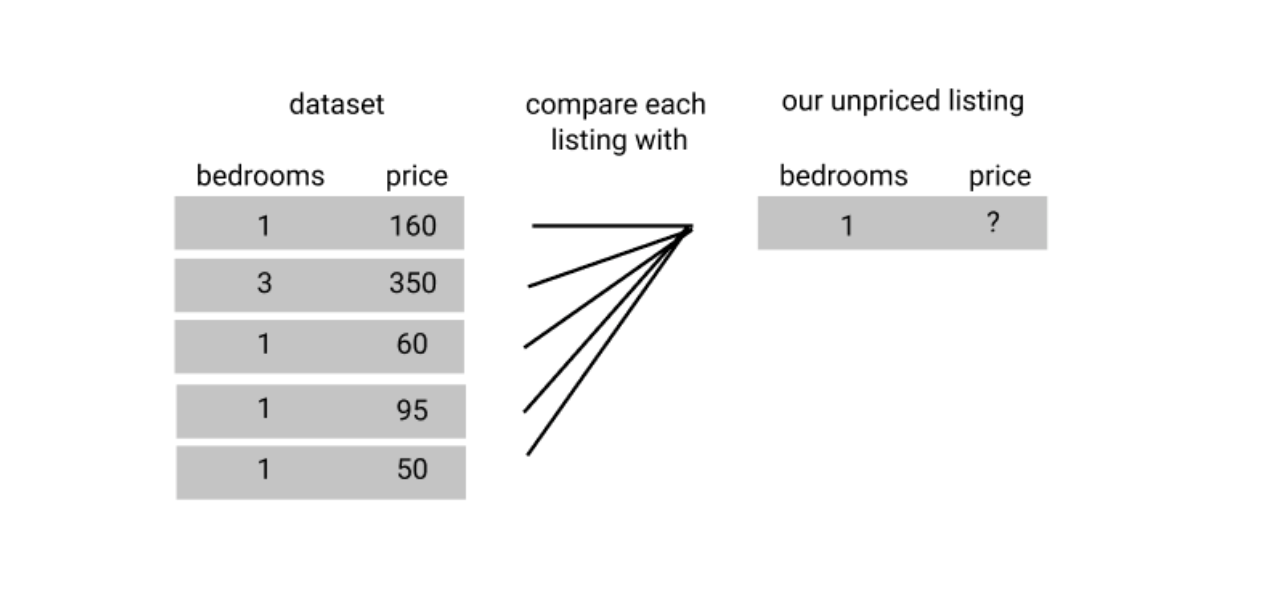
다음으로 similar metric (주: 두 개의 대상이 얼마나 유사한 가를 거리로 수치화하는 함수)을 이용해 각 숙소가 얼마나 유사한가를 계산합니다.
이제 가장 유사도가 높은 k개의 숙소를 골라냅니다.
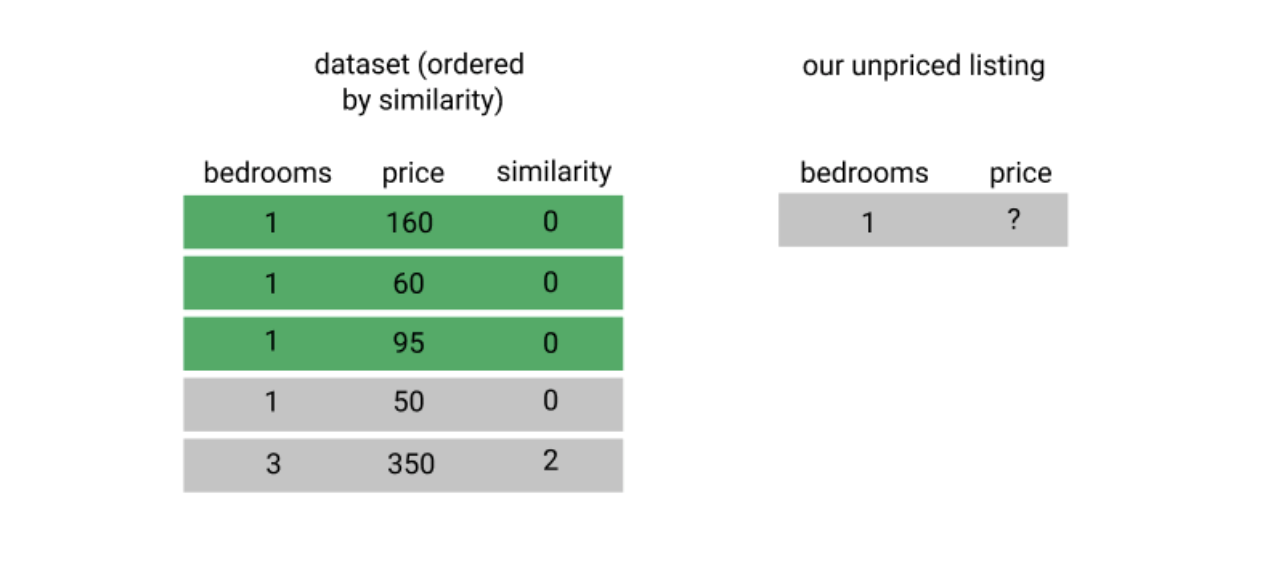
마지막으로 선택된 k개 숙소의 평균 숙박료를 계산해서 이 가격을 우리 숙소의 숙박료로 정합니다.
이제 계산에 어떤 similarity metric을 사용할 것인지 알아본 뒤, k-nearest neighbors을 구현하고, 아직 숙박료를 매기지 않은 숙소의 가격을 예측합니다.
튜토리얼에서는 k를 5로 고정하였지만 튜토리얼이 끝나고 스스로 모델을 학습시킬 때에는 좀 더 높은 혹은 낮은 k 값을 가지고 실험을 해보는 것도 좋습니다.
Euclidean distance
가격과 같은 연속적인 값을 예측할 때 주로 사용하는 similarity metric은 Euclidean distance입니다. 아래는 Euclidean distance를 구하는 공식입니다.
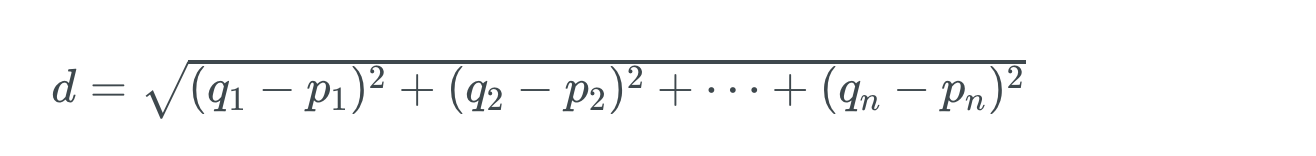
q1에서 qn 그리고 p1에서 pn은 각각 서로 다른 대상의 feature 값을 의미합니다. (침대 수, 침실 수 등)
Building a simple knn model
일단 간단하게 하나의 로우만 살펴봅시다. 만약 하나의 feature만 사용한다면 공식은:

제곱과 제곱근이 서로 상쇄되므로 더 간단하게 나타내면:

혹은 각 대상들의 feature값 간 차이의 절대값이라고도 말할 수 있습니다.
우리는 최대 세 명을 수용할 수 있는 숙소를 원하므로 일단 수용인원을 가지고 첫 번째 숙소와의 거리값(주: Euclidean distance)를 계산해봅시다.
numpy의 np.abs() 메쏘드를 사용하면 절댓값을 쉽게 구할 수 있습니다.
import numpy as np
our_acc_value = 3
first_living_space_value = dc_listings.loc[0,'accommodates']
first_distance = np.abs(first_living_space_value - our_acc_value)
print(first_distance)1가장 작은 거리값은 0이며, 이 말은 내가 원하는 숙소와 비교되는 대상의 feature 값이 동일하다는 것을 의미합니다. 그러나 한 가지 feature만 비교하는 것은 그다지 큰 의미가 없습니다.
이제 전체 데이터셋에 대해서 거리값을 계산한 뒤에 pd.value_counts()를 통해 어떻게 값이 분포되어 있는지 살펴봅시다.
dc_listings['distance'] = np.abs(dc_listings.accommodates - our_acc_value)
dc_listings.distance.value_counts().sort_index()0 461
1 2294
2 503
3 279
4 35
5 73
6 17
7 22
8 7
9 12
10 2
11 4
12 6
13 8
Name: distance, dtype: int64거리값이 0인 혹은 내가 원하는 수용인원과 정확히 일치하는 숙소가 461개 존재합니다.
이런 상황에서 만약 거리값이 0인 상위 5개 숙소를 선택하면 예측이 데이터셋에서 정해놓은 순서에 의해 왜곡될 수 있습니다.
그러므로 먼저 숙소의 순서를 무작위로 섞은 뒤 거리값이 0인 5개 숙소를 선택해야 합니다.
그러기 위해 DataFrame.sample() 메쏘드를 사용하여 로우의 순서를 무작위로 섞습니다.
이때 random_state값을 주게 되면 항상 같은 결과를 볼 수 있습니다. (주: random_state 파라미터는 난수 생성의 seed와 비슷한 역할을 합니다. 참고)
dc_listings = dc_listings.sample(frac=1,random_state=0)
dc_listings = dc_listings.sort_values('distance')
dc_listings.price.head()2645 $75.00
2825 $120.00
2145 $90.00
2541 $50.00
3349 $105.00
Name: price, dtype: object평균값을 구하기 전에 한 가지 유의할 점은 price 칼럼의 타입이 object라는 것입니다. 이는 price 칼럼이 달러 사인($)과 콤마(,)를 가지고 있기 때문입니다. 이 글자들을 없애고 float타입으로 바꿔야만 평균을 계산할 수 있습니다.
여기서 Series.str.replace() 메쏘드와 정규식을 사용하면 아래와 같은 코드가 됩니다.
dc_listings['price'] = dc_listings.price.str.replace("\$|,",'').astype(float)
mean_price = dc_listings.price.iloc[:5].mean()
mean_price88.0첫 예측을 해냈습니다! -- 간단한 모델을 사용한 결과 수용인원만 놓고 비교를 했을 때 세 명을 수용할 수 있는 숙소의 적정 가격은 $88 입니다.
문제는 아직 예측을 개선하고 최적화하기 위해 필요한, 예측값의 정확도를 계산할 수 있는 방법이 없다는 것입니다.
Evaluating our model
모델의 정확도를 분석하기 위한 간단한 방법은:
- 데이터 셋을 두 개로 분리:
- 트레이닝셋: 전체 로우의 75%
- 테스트셋: 전체 로우의 25% - 테스트셋에 속한 숙소의 값을 예측하기 위해서 트레이닝셋에 있는 데이터로 모델을 훈련시킨다.
- 예측된 값과 실제 숙박료를 차이를 분석한다.
이제 전체 3723개의 로우를 train_df 와 test_df로 나눠줍니다.
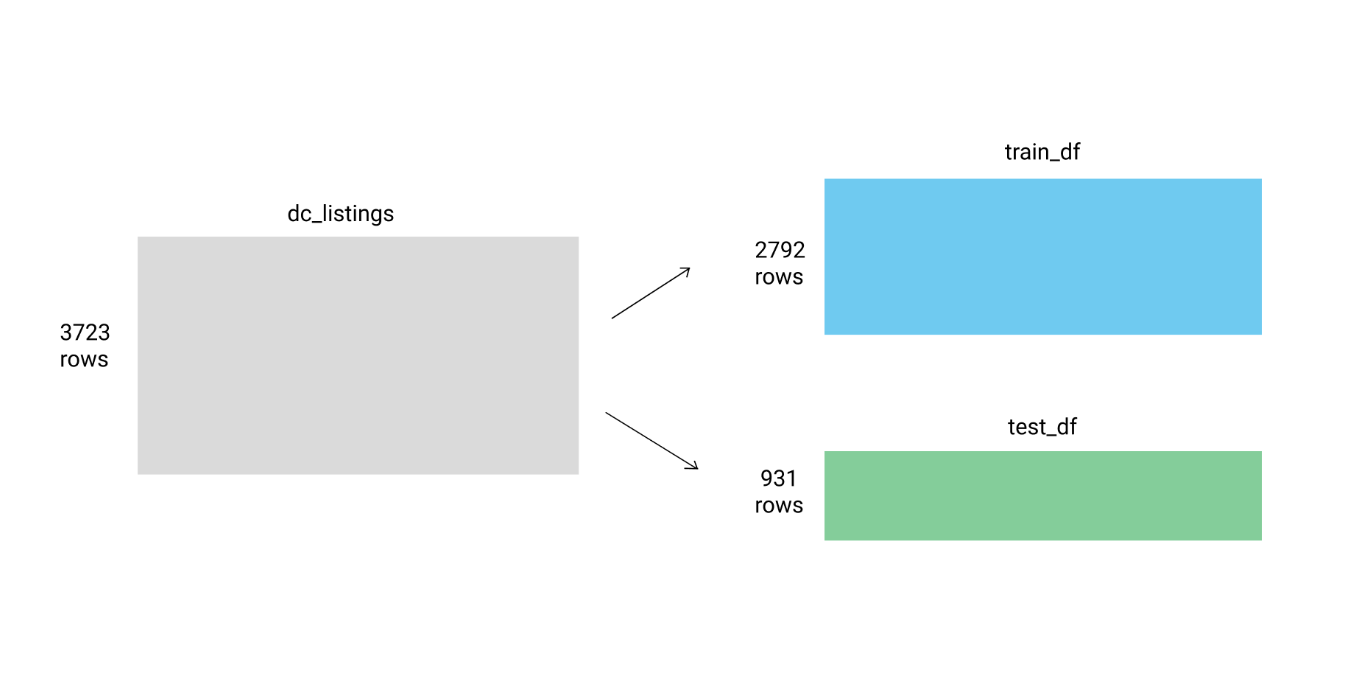
이전에 추가했던 distance 칼럼은 제거합니다.
dc_listings.drop('distance',axis=1)
train_df = dc_listings.copy().iloc[:2792]
test_df = dc_listings.copy().iloc[2792:]다음으로 predict_price 함수에 거리값을 구하고, 상위 5개 숙소의 숙박료 평균을 구하는 코드를 작성합니다.
def predict_price(new_listing_value,feature_column):
temp_df = train_df
temp_df['distance'] = np.abs(dc_listings[feature_column] - new_listing_value)
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)이제 이 함수에 테스트셋과 accommodates 칼럼을 파라미터로 주면 예측값을 얻을 수 있습니다.
test_df['predicted_price'] = test_df.accommodates.apply(predict_price,feature_column='accommodates')Using RMSE to evaluate our model
예측을 정교화하기 위해서는 예측값과 측정값의 차이가 클수록 페널티를 줄 필요가 있습니다.
이를 위해 root mean squared error (RMSE)라고 하는 에러값(주: 예측값과 측정값의 차이)의 평균의 제곱근을 사용할 수 있습니다.
아래는 RMSE를 구하는 공식입니다.
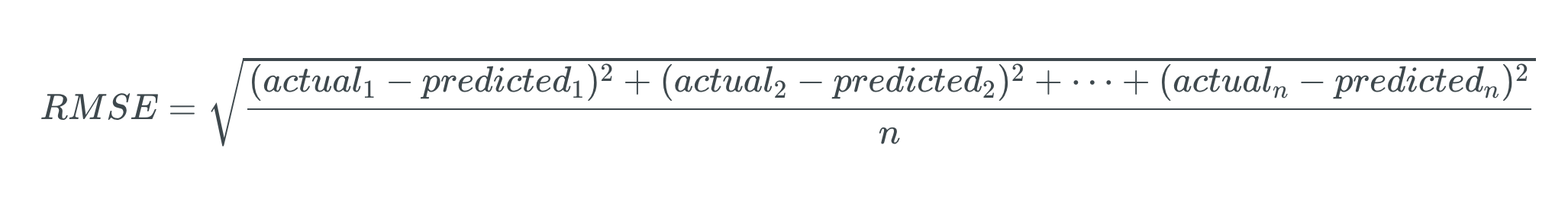
n은 테스트셋의 전체 로우 개수를 의미합니다.
어려워보이는 공식이지만 사실은:
- 에러값(예측값과 측정값의 차이)를 구한다
- 에러값을 제곱한다
- 이렇게 구해진 에러값들을 전부 더한다음 평균낸다
- 이 평균값의 제곱근을 구한다
의 순서로 이루어진 간단한 계산입니다.
이제 우리가 테스트셋에 대하여 계산했던 예측값의 RMSE값을 구해봅시다.
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
rmse212.98927967051529RMSE 값은 $213 정도가 나옵니다. RMSE를 사용할 때 큰 장점 중 하나는 계산 과정에서 제곱을 취한 뒤에 제곱근을 취하기 때문에 에러값의 크기가 실제 값에 비례한다는 것입니다. $213이라는 값을 보면 예측에 어느 정도 오차가 있는지 쉽게 파악할 수 있죠.
Comparing different models
이제 본격적으로 다양한 칼럼을 예측 파라미터로 주고 에러값에 어떤 차이가 생기나 지켜봅시다.
for feature in ['accommodates','bedrooms','bathrooms','number_of_reviews']:
test_df['predicted_price'] = test_df.accommodates.apply(predict_price,feature_column=feature)
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
print("RMSE for the {} column: {}".format(feature,rmse))RMSE for the accommodates column: 212.9892796705153
RMSE for the bedrooms column: 216.49048609414766
RMSE for the bathrooms column: 216.89419042215704
RMSE for the number_of_reviews column: 240.2152831433485위의 결과를 보면 수용인원을 파라미터로 준 모델의 에러값이 가장 작은 것을 알 수 있습니다. 하지만 에러값의 절대적인 크기가 여전히 꽤 큰 것을 알 수 있습니다.
지금까지는 하나의 feature만 이용해서 모델을 학습시켰습니다. 이런 방식을 univariate model이라고 합니다. 여기서 더 정확도를 높이기 위해서는 여러가지 feature를 같이 사용해야합니다. 이런 방식은 multivariate model이라고 부릅니다.
그 전에 예측값을 개선하기 위해서 데이터셋을 cleaning(주: 데이터를 정리하는 일련의 과정)할 필요가 있습니다. cleaning 과정은 아래와 같습니다.
- 모든 행을 숫자값으로 변경합니다. (숫자값이 아닌 경우 거리값을 계산할 수 없기 때문)
- 그러므로 숫자값이 아닌 행을 제거합니다.
- 특정 행에 값이 존재하지 않는 행도 제거합니다.
- 더 정확한 값을 얻기 위해 각 행의 값은 정규화합니다.
만약 데이터 cleaning과 머신러닝을 위한 데이터셋 준비에 관심이 있다면 Preparing and Cleaning Data for Machine Learning을 참조해주세요.
데이터를 cleaning한 다음 파일명을 dc_airbnb.normalized.csv로 바꾸고 파일을 읽어들입니다.
normalized_listings = pd.read_csv('dc_airbnb_normalized.csv')
print(normalized_listings.shape)
normalized_listings.head()(3671, 8)테이블 사진은 가로로 너무 길어서 보기가 불편할 것 같아 제외했습니다.
아까와 마찬가지로 전체 데이터셋을 테스트셋과 트레이닝셋으로 나눕니다.
normalized_listings = normalized_listings.sample(frac=1,random_state=0)
norm_train_df = normalized_listings.copy().iloc[0:2792]
norm_test_df = normalized_listings.copy().iloc[2792:]Calculating Euclidean distance with multiple features
Euclidean distance를 구하는 공식을 다시 떠올려봅시다.
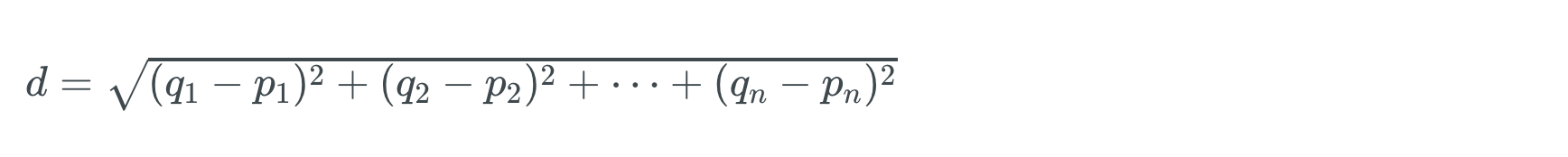
만약 수용인원과 욕실 수를 feature로 사용한다면 Euclidean distance는 아래와 같이 구할 수 있을 것입니다.
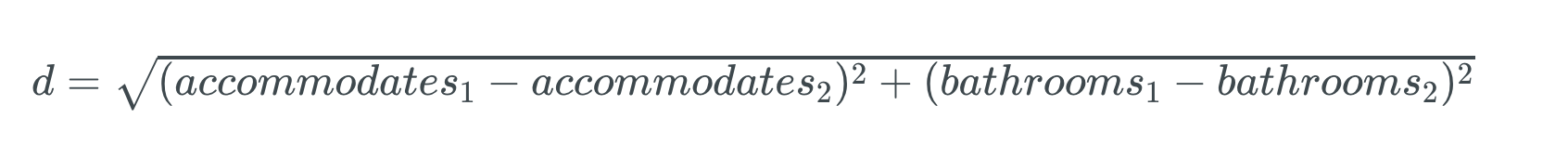
두 숙소 간의 거리값을 계산하려면 위의 공식에서처럼 숙소1과 숙소2 간의 수용인원의 차와 욕실 수의 차를 제곱해서 더하고 제곱근을 취하면 됩니다.
데이터셋의 2개 숙소에 대해서 직접 거리값을 계산하면 아래와 같이 나옵니다.

지금까지는 거리값을 직접 계산했지만, scipy.spatial에 포함된 distance.euclidean() 메쏘드를 사용하면 쉽게 거리값을 구할 수 있습니다. distance.euclidean()의 파라미터는:
- 두 개의 벡터 (Python list, NumPy array, or pandas Series 등에 해당되는)
- 두 벡터는 1차원 벡터여야하고 같은 사이즈여야 합니다.
distance.euclidean()를 사용해 첫번째와 다섯번째 로우에 해당하는 숙소의 거리값을 계산해봅시다.
from scipy.spatial import distance
first_listing = normalized_listings.iloc[0][['accommodates', 'bathrooms']]
fifth_listing = normalized_listings.iloc[20][['accommodates', 'bathrooms']]
first_fifth_distance = distance.euclidean(first_listing, fifth_listing)
first_fifth_distance0.9979095531766813Creating a multivariate KNN model
이제 이전에 만들었던 predict_pricemode가 여러 feature를 사용하도록 개선해봅시다. 편의를 위해 distance.euclidean() 대신 한 번에 여러 로우를 계산할 수 있는 distance.cdist() 메쏘드를 사용하겠습니다. (cdist 메쏘드는 Euclidean distance이외에도 여러가지 distance function을 사용할 수 있지만 기본값은 Euclidean distance입니다.)
def predict_price_multivariate(new_listing_value,feature_columns):
temp_df = norm_train_df
temp_df['distance'] = distance.cdist(temp_df[feature_columns],[new_listing_value[feature_columns]])
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)
cols = ['accommodates', 'bathrooms']
norm_test_df['predicted_price'] = norm_test_df[cols].apply(predict_price_multivariate,feature_columns=cols,axis=1)
norm_test_df['squared_error'] = (norm_test_df['predicted_price'] - norm_test_df['price'])**(2)
mse = norm_test_df['squared_error'].mean()
rmse = mse ** (1/2)
print(rmse)122.702007943한 개의 feature를 사용할 때 212였던 에러값이 두 개의 feature를 사용하자 122로 감소한 것을 알 수 있습니다.
Introduction to scikit-learn
이제까지는 k-nearest neighbor 모델을 직접 구현했습니다. 직접 구현은 모델의 작동 방식을 이해하는데는 도움이 되지만 라이브러리를 사용할 때보다 생산성이 떨어집니다.
Scikit-learn은 파이썬으로 구현된 머신러닝 라이브러리 중 가장 유명한 라이브러리입니다. 또한Scikit-learn은 주요 머신러닝 알고리즘을 포함하고 있습니다. 그러므로 데이터 사이언스를 하는 사람이라면 이 라이브러리를 활용할 때 좀 더 빠르게 모델을 구현하고 실험해볼 수 있습니다.
Scikit-learn을 활용하는 workflow는 아래와 같습니다.
- 사용하고 싶은 머신러닝 알고리즘을 고른다
- 트레이닝셋을 활용해서 모델을 학습시킨다
- 모델을 사용해 예측을 한다
- 예측값의 정확도를 평가한다
scikit-learn의 각 모델은 각각 클래스의 형태로 구현되어 있습니다. 그러므로 가장 먼저 할 일은 어떤 클래스를 사용할 것인지를 파악하는 일입니다. 여기서는 KNeighborsRegressor 클래스를 사용하도록 하겠습니다.
숙박료와 같은 숫자값을 예측하는데 사용되는 모델을 regression model이라고 합니다. 머신러닝의 또 다른 분야 중 하나는 classification(분류)이며, 이 경우에는 여러 성격을 가진 서로 다른 집단에서 한 집단이 어떤 집단에 가까운 지를 추측합니다. regressor라는 단어에서 알 수 있듯이 KNeighborsRegressor 클래스는 regression model에 속합니다.
Scikit-learn의 모델 생성은 Matplotlib과 비슷한 object-oriented 스타일로 빈 생성자를 호출하여 새로운 인스턴스를 생성하는 방식입니다.
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor()문서에 따르면, 파라미터 값은 기본적으로:
n_neighbors:k의 크기, 기본값은 5algorithm: 유사도 분석 알고리즘, 기본값은autop: 거리값 계산 방식, 기본값은Euclidean distance
이제 algorithm 파라미터를 brute로 바꿔봅시다.
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(algorithm='brute')Fitting a model and making predictions
이제 fit 메쏘드를 이용해서 데이터를 학습시킬 수 있습니다. fit 메쏘드는 두 개의 파라미터를 받습니다:
matrix-like object, 트레이닝셋에 포함된feature들list-like object, 트레이닝셋의target값이 포함된 칼럼의 데이터들
(주:target이란 예측의 대상이 되는feature를 말한다. 여기서는 숙박료)
Matrix-like object라는 것은 Dataframe이나 Numpy 2D array 등도 사용할 수 있다는 것을 의미합니다.
그리고 list-like objects에는 다음이 포함됩니다.
NumPy arrayPython listpandas Series object
그러므로 Dataframe에서 특정 칼럼을 선택해서 두 번째 파라미터로 넘겨줄 수 있습니다.
knn.fit(train_features, train_target)fit() 메쏘드를 호출하면 scikit-learn은 KNearestNeighbors의 인스턴스에 트레이닝 데이터를 저장합니다. 이때 숫자가 아닌 값이나 특정 값이 없는 불완전한 데이터를 넘겨줄 경우 에러를 발생시킵니다. 이처럼 Scikit-learn은 흔하게 일어나는 실수를 방지하는 다양한 기능을 제공합니다.
트레이닝셋을 이용해서 학습을 시킨 이후에는 predict 메쏘드를 사용해서 테스트셋에 대해 예측을 할 수 있습니다. predict 메쏘드는 한 가지 인자만 받습니다:
matrix-like object, 예측을 할 때 사용할feature칼럼
주의할 점은 학습 과정에 사용되는 feature 칼럼과 예측에 사용되는 feature 칼럼은 반드시 일치해야한다는 것입니다.
predictions = knn.predict(test_features)predict() 메쏘드는 테스트셋에 대해 예상 가격이 들어있는 Numpy 배열을 리턴합니다. 이렇게 scikit-learn을 활용한 전체 workflow를 살펴보았습니다.
knn.fit(norm_train_df[cols], norm_train_df['price'])
two_features_predictions = knn.predict(norm_test_df[cols])Calculating MSE using Scikit-Learn
지금까지는 에러값을 Numpy와 Scipy를 사용하여 직접 계산했지만, sklearn.metrics.mean_squared_error 메쏘드를 사용하면 간단하게 에러값을 계산할 수 있습니다. 이렇게 scikit-learn 라이브러리를 사용하면 직접 계산하는 것보다 더 실수를 줄일 수 있고 더 편리하게 계산할 수 있습니다.
mean_squared_error() 메쏘드는 2개의 인자를 받습니다.
- list-like object, 실제값
- 두 번째 list-like object, 모델을 사용한 예측값
from sklearn.metrics import mean_squared_error
two_features_mse = mean_squared_error(norm_test_df['price'], two_features_predictions)
two_features_rmse = two_features_mse ** (1/2)
print(two_features_rmse)124.834722314코드 작성이 쉬울 뿐만 아니라 실행 속도도 scikit-learn을 사용하는 편이 더 빠르다는 것을 알 수 있습니다.
여기서 우리가 직접 계산한 에러값과 scikit-learn 라이브러리를 사용한 에러값에 약간의 차이가 있다는 것을 알 수 있습니다. (이 차이는 구현 방식의 미세한 차이에서 발생했을 가능성이 큽니다.)
Using more features
scikit-learn을 사용할 때 얻는 이점 중 하나는 좀 더 빠르게 workflow를 반복할 수 있다는 것입니다.
직접 예시를 살펴봅시다. 이제 모델이 2 개가 아닌 4개의 feature를 사용하도록 바꿔봅시다.
knn = KNeighborsRegressor(algorithm='brute')
cols = ['accommodates','bedrooms','bathrooms','beds']
knn.fit(norm_train_df[cols], norm_train_df['price'])
four_features_predictions = knn.predict(norm_test_df[cols])
four_features_mse = mean_squared_error(norm_test_df['price'], four_features_predictions)
four_features_rmse = four_features_mse ** (1/2)
four_features_rmse120.92729413345498이번 경우엔 에러값이 조금 떨어졌지만 feature를 추가한다고해서 항상 에러값이 나아지는 것은 아닙니다.
여기서 알 수 있는 사실은 더 많은 feature를 사용하는 것이 필연적으로 모델의 정확도를 개선시키는 것은 아니라는 것입니다. (이는 target이 되는 feature에 직접적으로 관련이 없는 feature의 경우에는 noise(주: 왜곡)를 늘릴 수 있기 때문입니다.)
Summary
배운 것들을 정리해봅시다.
- 머신러닝이 무엇인지에 대해 배웠습니다.
k-nearest neighbors algorithm을 배우고univariate model을 직접 구현해서 예측을 해봤습니다.RMSE값을 활용해 모델의 정확도를 평가할 수 있다는 사실을 배웠습니다.- 그리고
multivariate model을 직접 구현해서 예측을 해봤습니다. - 마지막으로
scikit-learn library의KNeighborsRegressor클래스를 사용해서 예측을 했습니다.
Next Steps
더 많은 것을 배우고 싶다면 Dataquest Machine Learning Fundamentals course를 참조하시면 됩니다. 이 강좌는 머신러닝을 더 세부적으로 살펴보고, 그 과정 중에서 직접 코드를 작성해볼 수도 있습니다.
만약 우리가 만든 모델을 개선시키고 싶다면 다음 몇 가지 방법을 시도해볼 수 있습니다:
k값을 바꿔보기- 이전에 제거했던 숫자값이 아닌 행을 숫자값으로 변형시키고 예측을 위한
feature에 포함시켜보기 - feature engineering 시도해보기: Kaggle 시작하기
후기
에어비앤비의 숙박료를 책정하는건 머리 아픈 일입니다. 너무 싸서도 안 되고, 그렇다고 너무 비싸서도 안 됩니다. 그러던차에 머신러닝을 활용해서 숙박료를 예측할 수 있다는 말을 듣고 바로 튜토리얼을 따라서 모델을 만들어봤습니다. 결과는 그닥 유용하지는 않은 것 같습니다. 그 이유는 Inside Airbnb 같은 곳에서 제공하는 데이터는 대부분 유럽/미국 국가의 대도시에 치중돼 있어서 매뉴얼하게 데이터를 크롤링하는 수밖에 없었는데, 그러다보니 데이터를 대량으로 수집하기가 어려웠고, 또 머신러닝에 대해 잘 모르다보니 어떤 식으로 feature engineering을 해야 가장 정확한 모델을 만들 수 있을까 파악하는 것도 힘들었습니다.
결과적으로 그럭저럭(?) 결과값을 뱉어내는 코드를 짜긴 했지만 신뢰성은 믿기 힘든 모델이 되어버렸죠. 저는 강남/춘천/포항/수원/서울 등의 도시의 데이터를 수집하고 모델에 적용시켜봤는데, 공통적으로:
1) 가격이 비싼 고급 숙소의 경우 왜곡이 심하다 (아무래도 비슷한 특징을 가진 숙소를 찾기 어려울테니 당연한 현상이겠죠?)
2) Non numeric한 fearure 들 중 적용이 힘든 것도 많다. (이를 테면 썸네일 사진 같은 feature는 숙박객이 숙소를 고를 때 꽤 중요한 요소지만 숫자로 변환하기가 어렵죠)
3) 데이터셋의 크기가 작을 경우 왜곡이 심하게 일어난다. (저는 많아봐야 300~400개 정도의 숙소를 대상으로 했기 때문에 더 심할 것입니다.)
4) KNN 알고리즘은 숙소의 시기적 요인(seasonality)를 고려하지 않는다. 숙박료는 성수기/비성수기 혹은 축제와 같은 이벤트에 의해 급격하게 변합니다.
-> 4)와 관련해서는 굉장히 흥미로운 글이 있었습니다. 궁금하신 분들은 한 번 살펴보셔도 좋을 것 같습니다.
참고
튜토리얼에서는 data cleaning을 어떻게 하는지 자세하게 이야기하지는 않았습니다. 그러니 튜토리얼을 따라가다 막히는 부분이 있거나 실제 자료를 가지고 실험을 해보고 싶으신 분들은 아래 레포지토리를 참고해주세요 :)


LaTeX Renderer 빨리 연동하겠습니다!!