이 글은 Vladimir Khorikov의 글 Domain model purity vs. domain model completeness (DDD Trilemma)을 번역한 글입니다.
도메인 모델 완전성
저는 지난 2년간 많은 프로젝트에서 공통적으로 발견되는 트릴레마에 대한 질문을 받았는데요, 오늘은 그 트릴레마에 대해 얘기해보도록 하겠습니다.
이메일 변경 기능만을 가진 간단한 회원 관리 시스템을 떠올려봅시다. 각 회원을 나타내는 도메인 클래스 (User)의 코드는 아래와 같을 것입니다.
public class User : Entity
{
public Company Company { get; private set; }
public string Email { get; private set; }
public Result ChangeEmail(string newEmail)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
Email = newEmail;
return Result.Success();
}
}
public class Company : Entity
{
public string DomainName { get; }
public bool IsEmailCorporate(string email)
{
string emailDomain = email.Split('@')[1];
return emailDomain == DomainName;
}
}그리고 아래는 컨트롤러 코드입니다.
public class UserController
{
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
}위 코드는 모든 비즈니스 규칙 (Business rules)이 도메인 클래스 내에 위치하므로 풍부한 도메인 모델 (Rich Domain Model)을 따르는 예라고 할 수 있습니다. 현재는 본인이 속한 회사의 도메인에 해당되는 이메일만 사용할 수 있다는 규칙이 존재합니다. 클라이언트는 어떤 방법으로도 이 규칙을 우회할 수 없습니다.
또한 위 코드의 도메인 모델은 완전하다고 할 수 있습니다. 모델 내에 애플리케이션의 모든 비즈니스 규칙이 들어있기 때문입니다. 다른 말로 도메인 모델이 파편화되어있지 않다고도 할 수 있습니다.
도메인 로직 파편화는 도메인 로직이 도메인 계층과 다른 계층에 존재하는 것을 말합니다. 위 코드 예시에서 UserController는 어떠한 비즈니스 규칙도 포함하지 않고, 도메인 계층과 데이터베이스 간의 협력에만 관여합니다.
도메인 모델 순수성
위 코드에 다른 비즈니스 규칙이 추가해봅시다. 이제부터 새로운 이메일로 사용하려면 해당 이메일이 이미 사용 중인지 아닌지 확인해야 합니다.
// UserController
public string ChangeEmail(int userId, string newEmail)
{
/* The new validation */
User existingUser = _userRepository.GetByEmail(newEmail);
if (existingUser != null && existingUser.Id != userId)
return "Email is already taken";
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}코드는 분명 의도한 대로 동작하지만 이제 도메인 로직이 파편화되었습니다. 전에는 모든 도메인 로직이 도메인 계층에 속해 있었지만 이제는 일부 로직이 컨트롤러에도 있습니다.
도메인 모델 완전성을 회복하려면 어떻게 해야 할까요?
이메일 중복 여부를 확인하는 로직을 도메인 모델로 옮기면 됩니다.
// User
public Result ChangeEmail(string newEmail, UserRepository repository)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
User existingUser = repository.GetByEmail(newEmail);
if (existingUser != null && existingUser != this)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
// UserController
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail, _userRepository);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}도메인 로직 파편화는 더 이상 일어나지 않지만 도메인 모델 순수성이 깨졌습니다. 순수한 도메인 모델은 프로세스 외부 의존성 (out-of-process dependencies)를 가져서는 안 되기 때문입니다. 순수성을 회복하려면 도메인 클래스가 원시 타입 (primitive types) 혹은 다른 도메인 모델에만 의존하도록 변경해야 합니다.
위에서 순수성을 잃어버린 이유는 User 클래스가 데이터베이스와 직접 통신하게 되었기 때문입니다. 두번째 인자의 UserRepository를 IUserRepository 인터페이스로 치환하더라도 이 문제는 해결되지 않습니다.
public Result ChangeEmail(string newEmail, IUserRepository repository)물론 두 번째 인자를 위임자 (delegate)로 치환하는 방법도 마찬가지입니다.
public Result ChangeEmail(string newEmail, Func<string, bool> isEmailUnique)어떤 방식을 사용하든 User 클래스가 데이터베이스와 직접 통신한다는 사실은 변하지 않기 때문에 도메인 순수성은 회복되지 않습니다.
여기서 알 수 있듯 도메인 모델 순수성과 도메인 모델 완전성 모두를 가지는 것은 불가능합니다.
트릴레마
그렇다면 지금까지 알아본 도메인 모델의 두 가지 속성 외에 트릴레마를 구성하는 세 번째 속성은 무엇일까요? 바로 성능입니다. 가끔은 성능을 위해 앞서 말한 두 가지를 포기해야합니다.
도메인 모델 순수성을 지키기 위해 모든 회원 정보를 데이터베이스로부터 가져와 User 클래스에 전달할 수도 있습니다.
// User
public Result ChangeEmail(string newEmail, User[] allUsers)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
bool emailIsTaken = allUsers.Any(x => x.Email == newEmail && x != this);
if (emailIsTaken)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
// UserController
public string ChangeEmail(int userId, string newEmail)
{
User[] allUsers = _userRepository.GetAll();
User user = allUsers.Single(x => x.Id == userId);
Result result = user.ChangeEmail(newEmail, allUsers);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}하지만 성능 관점에서 위 코드는 현실적이지 않습니다. 이메일을 변경할 때마다 데이터베이스에서 모든 유저를 가져와야한다면 큰 성능 손실이 일어나기 때문입니다.
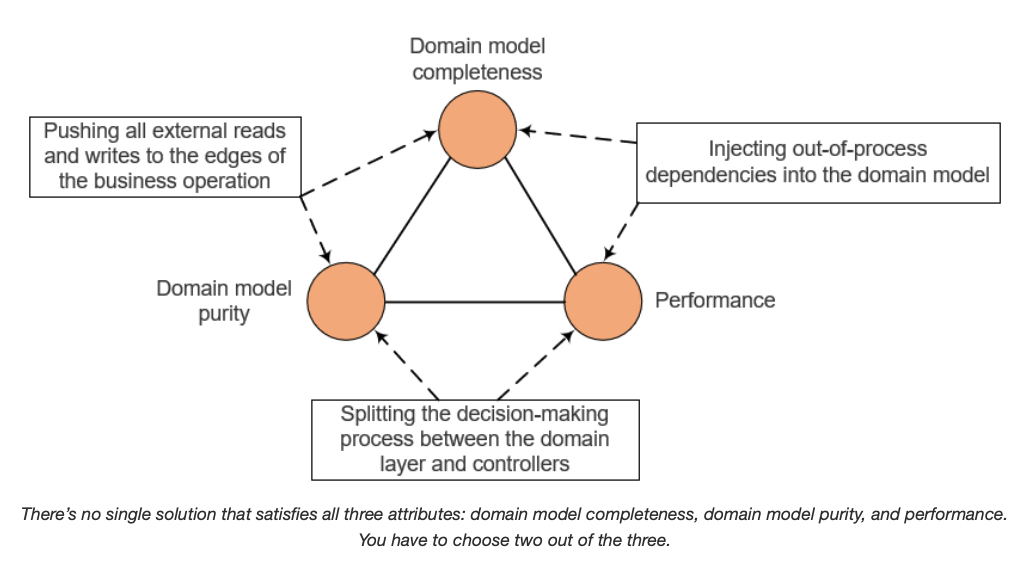
여기서 트릴레마가 발생합니다. 어떤 코드도 세 가지 속성 모두를 만족할 수는 없습니다.
- 도메인 모델 완전성: 모든 도메인 로직이 도메인 계층에 속함 (도메인 로직 파편화가 발생하지 않음)
- 도메인 모델 순수성: 도메인 계층에서 프로세스 외부 의존성에 의존하지 않음
- 성능: 필수적인 경우에만 프로세스 외부 의존성을 호출함
트릴레마에 따르면 최대 두 가지 속성만을 가질 수 있습니다.
- 도메인 모델 완전성과 순수성을 위해 성능을 희생하는 경우
- 도메인 모델 완전성과 성능을 위해 도메인 모델 순수성을 희생하는 경우
- 도메인 모델 순수성과 성능을 위해 도메인 모델 완전성을 희생하는 경우
첫 번째 방식은 특정 상황에서만 사용할 수 있습니다.
이 방식은 애플리케이션 로직이 조회 - 판단 - 행동 (read - decide - act)의 순서를 따르는 경우에만 사용할 수 있습니다.
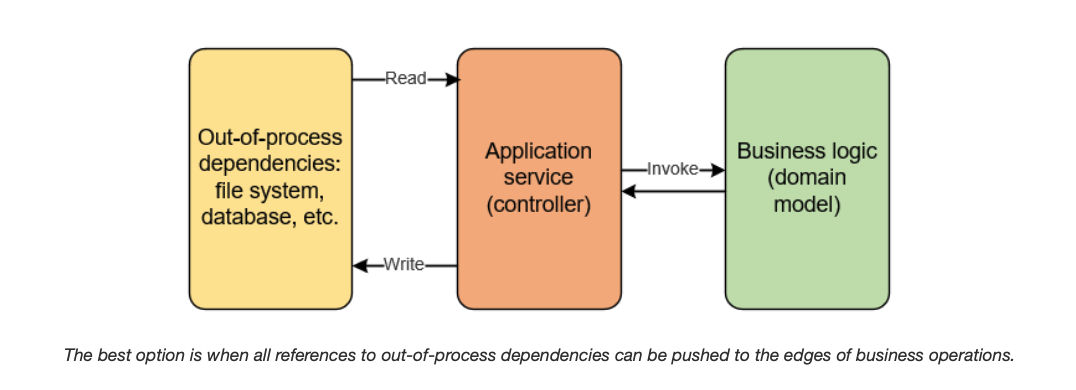
새로운 비즈니스 규칙 (새로운 이메일의 중복 여부 확인)을 도입하기 전의 코드는 위 구조를 따르고 있습니다.
- 데이터베이스에서 회원 정보를 조회해서 (read)
- 해당 이메일이 기업 도메인을 사용하고 있는지 확인하고 (decide)
- 회원의 이메일 정보를 갱신합니다. (act)
분명한 점은 모든 애플리케이션 로직이 위 구조를 따르지 않는다는 것입니다. 판단 혹은 행동 단계에서 프로세스 외부 의존성에서 추가적으로 데이터를 조회해야할 수 있습니다.
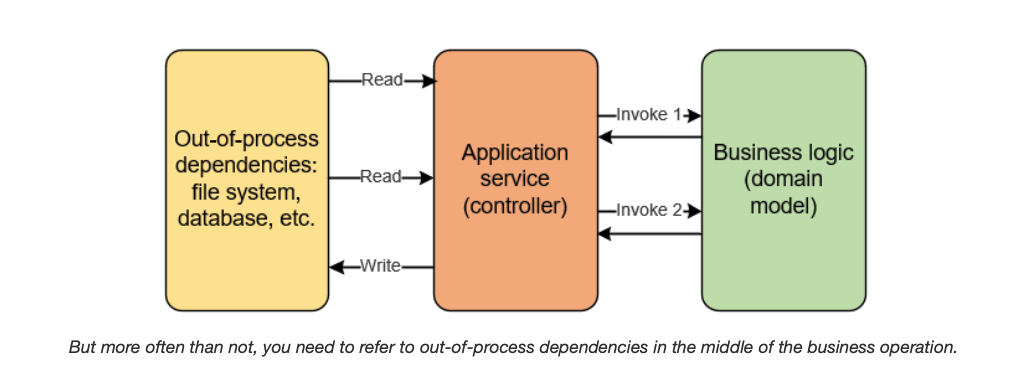
그러므로 첫번째 방식은 보통 고려대상이 아니고, 두번째/세번째 방식 중에서 한 가지를 선택해야 됩니다.
어떤 방식이 더 나을까요?
저는 도메인 모델 순수성을 따르는 쪽을 더 선호합니다.
도메인 계층에 추가적인 책임을 부여하는 것보다 도메인 로직이 파편화되는 것이 더 낫습니다.
도메인 로직은 애플리케이션에서 가장 중요하고, 복잡한 부분입니다. 프로세스 외부 의존성과의 통신을 도메인 계층의 책임으로 이전할 경우 도메인 계층의 코드는 몇 배로 복잡해집니다. 이런 상황은 될 수 있으면 피하는게 좋습니다. 도메인 계층은 도메인 로직에만 집중하는 것이 낫습니다.
이처럼 의사 결정 과정을 두 계층에 위치시키는 방법은 함수형 프로그래밍, 유닛테스트 그리고 도메인 주도 디자인에서 공통적으로 나타나는 패턴입니다.
- DDD는 애플리케이션의 복잡성을 관리 가능한 수준 (manageble)으로 유지하기 위해 이 방식을 사용합니다.
- 함수형 프로그래밍은 함수의 순수성을 유지하기 위해 이 방식을 사용합니다. 함수형 프로그래밍의 핵심은 애플리케이션 중심 계층에서 드러나지 않은 입출력을 피하고 참조 투명성 (referencial transparency)을 유지하는 것입니다.
- 유닛 테스트는 도메인 모델 순수성을 강조하는데 이는 순수한 도메인 모델은 유닛 테스트 가능한 도메인 모델을 의미하기 때문입니다. 비지니스 규칙과 프로세스 외부 의존성에 대한 코드가 분리되어 있지 않다면 테스트 코드를 유지보수하기 훨씬 어려워집니다.
우리의 회원 관리 시스템에서 의사 결정 과정을 도메인 계층과 컨트롤러 두 군데에 위치시킨다는 것은 새로운 이메일의 중복 검사 로직을User 클래스가 아닌 UserController로 이동시키는 것을 의미합니다.
요약
- 도메인 모델 완전성은 도메인 모델이 애플리케이션의 모든 비즈니스 규칙이 도메인 모델에 속하는 것을 의미합니다.
- 반대로 도메인 로직이 도메인 계층 뿐만 아니라 다른 계층에도 존재한다면 도메인 모델이 파편화되었다고 합니다. - 도메인 모델 순수성은 도메인 모델이 프로세스 외부 의존성에 직접 통신하지 않는 것을 의미합니다.
- 대부분의 경우 어떤 코드도 도메인 모델 완전성, 도메인 모델 순수성과 성능 세 가지 속성을 모두 만족시킬 수 없습니다.
- 성능에 큰 영향을 끼치지 않고 도메인 모델 순수성과 완전성을 보장하는 것이 가장 좋습니다.
- 그렇지 않은 경우 도메인 모델 순수성을 도메인 모델 완전성보다 우선시해야 합니다.
