[번역] 몽고 디비 복합 인덱스 최적화하기

이 글은 ALEX BEVILACQUA의 글 "Optimizing MongoDB Compound Indexes - The "Equality - Sort - Range" (ESR) Rule"을 번역한 글입니다.
나는 MongoDB Techinical Services로 일하면서, 인덱스가 어떤 경우에 효과적으로 동작하지 않을 수 있는지 몽고디비 사용자들이 쉽게 이해할 수 있게 도울 필요가 있다는 것을 깨달았다.
보통 인덱스 최적화에 관한 문서를 추천할 때 A. Jesse Jiryu Davis의 "몽고디비 복합 인덱스 최적화하기"가 가장 먼저 생각나는데, 아쉽게도 아직 이 주제에 대한 공식 문서는 존재하지 않는다.
나는 몽고디비 토론토 2019나 몽고디비 월드 2019에서 이 주제에 대해 몇 번 다룬적이 있고, 동료인 Chris Harris도 몽고디비 월드 2019와 몽고디비 휴스턴 2019에서 같은 주제에 대해 얘기한 적이 있다.
이번 기회에 Jesse의 글과 나의 예전 발표 내용을 바탕으로 인덱스를 최적화하기 위한 몇 가지 규칙에 대해 이야기해보려 한다.
ESR "규칙"
복합 인덱스(compound index)에서 인덱스를 구성하는 개별 키(index key)의 순서는 굉장히 중요하며, ESR 규칙을 통해 거의 모든 경우에 적용할 수 있는 최적의 키 순서를 찾을 수 있다.
"규칙"을 강조하는 이유는 이 규칙에 몇 가지 예외가 있기 때문인데, 예외에 대한 자세한 정보는 "Tips and Tricks for Effective Indexing" 발표를 참고하길 바란다.
규칙 1) 동등 조건자(equality predicates)를 맨 앞에 위치시킨다
동등 조건자는 어떤 값이 다른 값과 동일한지 비교한다.
find({ x: 123 })
find({ x: { $eq: 123 } })
aggregate([ { $match:{ "x.y": 123 } } ])위 쿼리들에서 동등 조건자는 실행 계획(explain plan)의 indexBounds 상에서 밀접한 경계(tightly bounded)를 가진다.
"indexBounds" : {
"x" : [
"[123.0, 123.0]"
]
}복합 인덱스에서 여러 동등 조건자를 배치할 때 중요한 점은 굳이 선택성(selectivity)이 높은 키를 먼저 배치하지 않아도 된다는 것이다.
이는 B-Tree 인덱스의 성질을 생각해보면 더 분명해지는데,
B-Tree는 키가 어떤 순서로 배치되든 각 노드(주: 원문은 page를 사용)에 가능한 모든 값을 저장할 것이므로 결과적으로 키 순서에 상관없이 항상 동일한 수의 조합이 존재하게 된다.
규칙 2) 정렬 조건자(sort predicates)는 동등 조건자 뒤에 위치해야 한다
정렬 조건자는 쿼리 결과의 정렬 순서를 결정한다.
find().sort({ a: 1 })
find().sort({ b: -1, a: 1 })
aggregate([ { $sort: { b: 1 } } ])위 쿼리들은 결과를 정렬하기 위해 전체 키 범위를 스캔해야하므로 무경계(unbounded)한 쿼리가 된다.
"indexBounds" : {
"b" : [
"[MaxKey, MinKey]"
],
"a" : [
"[MinKey, MaxKey]"
]
}규칙 3) 범위 조건자(range predicates)는 동등 조건자와 정렬 조건자 뒤에 위치해야 한다
범위 조건자는 어떤 값에 정확히 일치하는 키를 찾는 대신 여러 키를 스캔할 수 있다.
find({ z: { $gte: 5} })
find({ z: { $lt: 10 } })
find({ z: { $ne: null } })위 쿼리에서 범위 조건자는 조건을 만족하는 모든 키를 스캔해야하므로 느슨한 경계(loosely bounded)를 가진다.
"indexBounds" : {
"z" : [
"[5.0, inf.0]"
]
}
"indexBounds" : {
"z" : [
"[-inf.0, 10.0)"
]
}
"indexBounds" : {
"z" : [
"[MinKey, undefined)",
"(null, MaxKey]"
]
}세 규칙은 쿼리가 인덱스를 어떤 방식으로 사용하고, 조건에 맞는 결과를 돌려주는지와 관련이 있다.
테스트 데이터
이번에는 아래 데이터를 이용해 위 규칙이 실제로 어떤 식으로 적용되는지 알아보려 한다.
{ name: "Shakir", location: "Ottawa", region: "AMER", joined: 2015 }
{ name: "Chris", location: "Austin", region: "AMER", joined: 2016 }
{ name: "III", location: "Sydney", region: "APAC", joined: 2016 }
{ name: "Miguel", location: "Barcelona", region: "EMEA", joined: 2017 }
{ name: "Alex", location: "Toronto", region: "AMER", joined: 2018 }쿼리가 어떤 식으로 실행되는지 확인하기 위해 실행계획의 executionStats 필드도 확인해본다.
find({ ... }).sort({ ... }).explain("executionStats").executionStats(E) 동등 조건
선택성은 인덱스를 활용하여 쿼리 대상을 줄이는 것을 의미한다.
효과적인 인덱스는 선택성이 더 좋고, 몽고디비로 하여금 더 큰 데이터에서도 효과적으로 동작할 수 있게끔 한다.
동등 조건자는 인덱스의 앞 부분에 위치하여 선택성을 보장해야 한다.
(E → S) 동등 조건자가 정렬 조건자의 앞에 위치하는 경우
정렬 조건자를 동등 조건 뒤에 위치시키면
- 논블로킹 정렬을 가능하게 한다
- 스캔의 범위를 최소화한다
이를 이해하기 위해 아래 쿼리를 살펴보자.
// operation
createIndex({ name: 1, region: 1 })
find({ region: "AMER" }).sort({ name: 1 })정렬 조건자가 더 앞에 위치하면서 전체 범위를 스캔한 뒤에야 좀 더 선택성이 높은 동등 조건자를 사용할 수 있다.
// execution stats
"nReturned" : 3.0,
"totalKeysExamined" : 5.0,
"totalDocsExamined" : 5.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"name" : [
"[MinKey, MaxKey]"
],
"region" : [
"[MinKey, MaxKey]"
]
},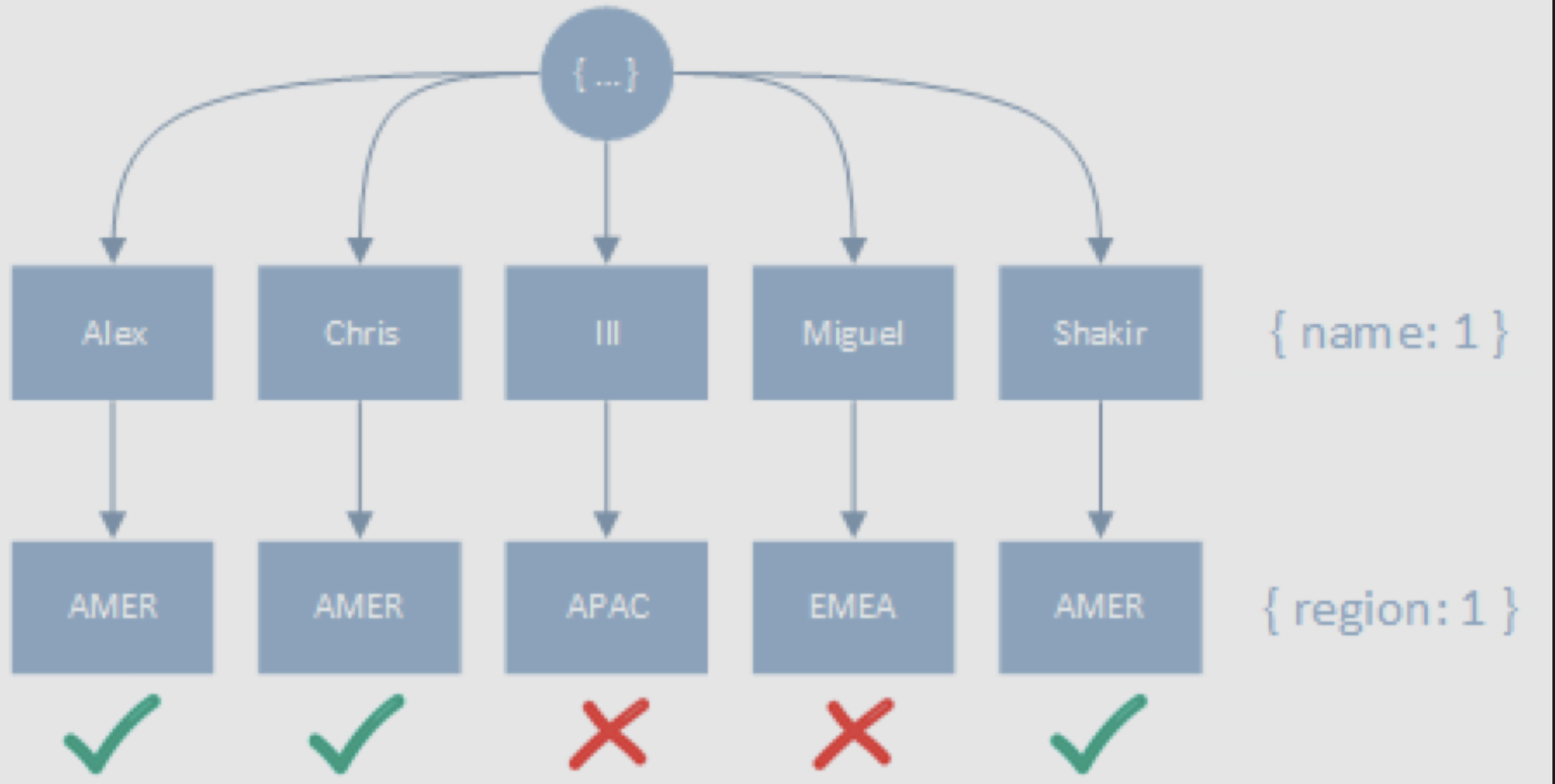
결과적으로 위와 같이 배치된 인덱스를 사용하면 3개의 도큐먼트를 반환하기 위해 5개의 키 전부를 스캔해야만한다.
// operation
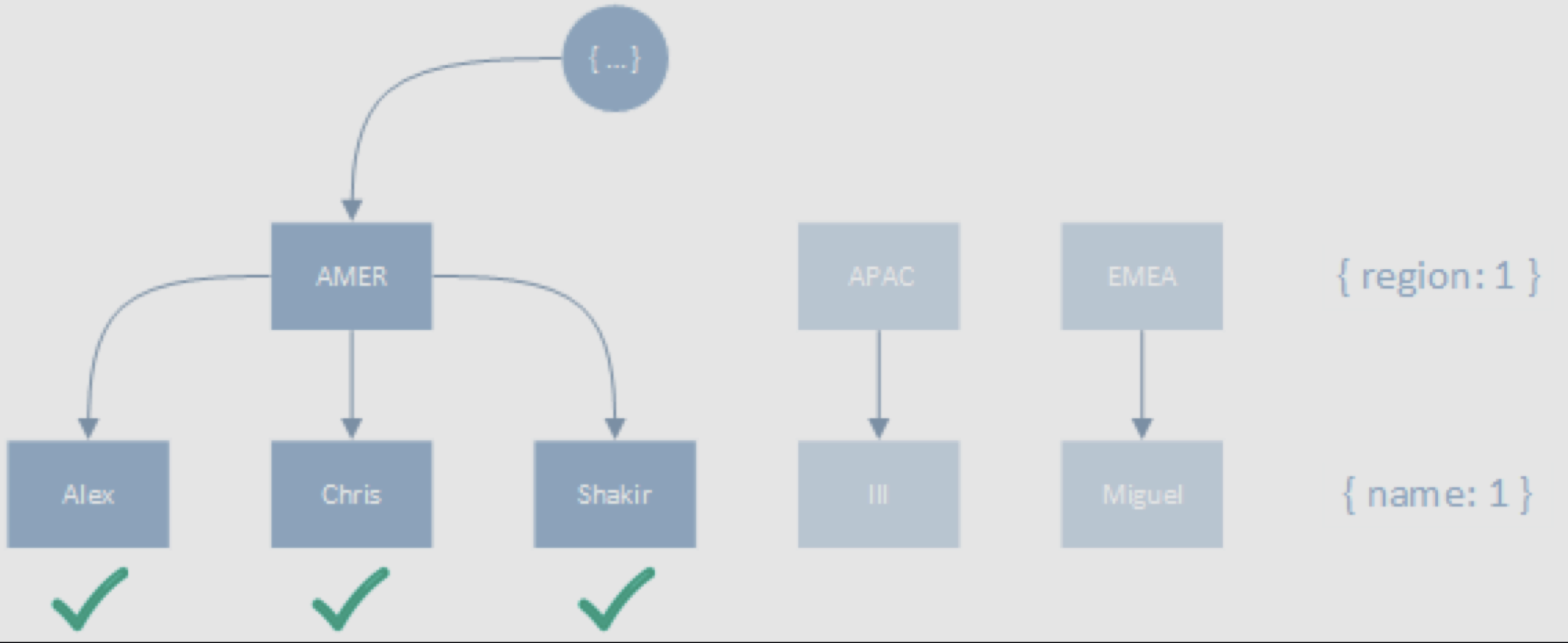
createIndex({ region: 1, name: 1 })
find({ region: "AMER" }).sort({ name: 1 })이와 반대로 동등 조건자를 먼저 위치시키면 밀접한 경계를 통해 더 적은 키를 스캔하면서 필터 조건을 만족시킬 수 있다.
// execution stats
"nReturned" : 3.0,
"totalKeysExamined" : 3.0,
"totalDocsExamined" : 3.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[\"AMER\", \"AMER\"]"
],
"name" : [
"[MinKey, MaxKey]"
]
},
(E → R) 범위 조건자 앞에 동등 조건자를 배치한 경우
범위 조건자는 정렬 조건자보다 적은 키를 스캔하지만 더 높은 선택성을 보장하려면 여전히 동등 조건자 뒤에 배치하는 것이 좋다.
// operation
createIndex({ joined: 1, region: 1 })
find({ region: "AMER", joined: { $gt: 2015 } })범위 조건자를 동등 조건자보다 먼저 명시하면 조건에 맞는 도큐먼트를 반환하기 위해 더 많은 키를 스캔해야 한다.
// execution stats
"nReturned" : 2.0,
"totalKeysExamined" : 4.0,
"totalDocsExamined" : 2.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"joined" : [
"(2015.0, inf.0]"
],
"region" : [
"[\"AMER\", \"AMER\"]"
]
},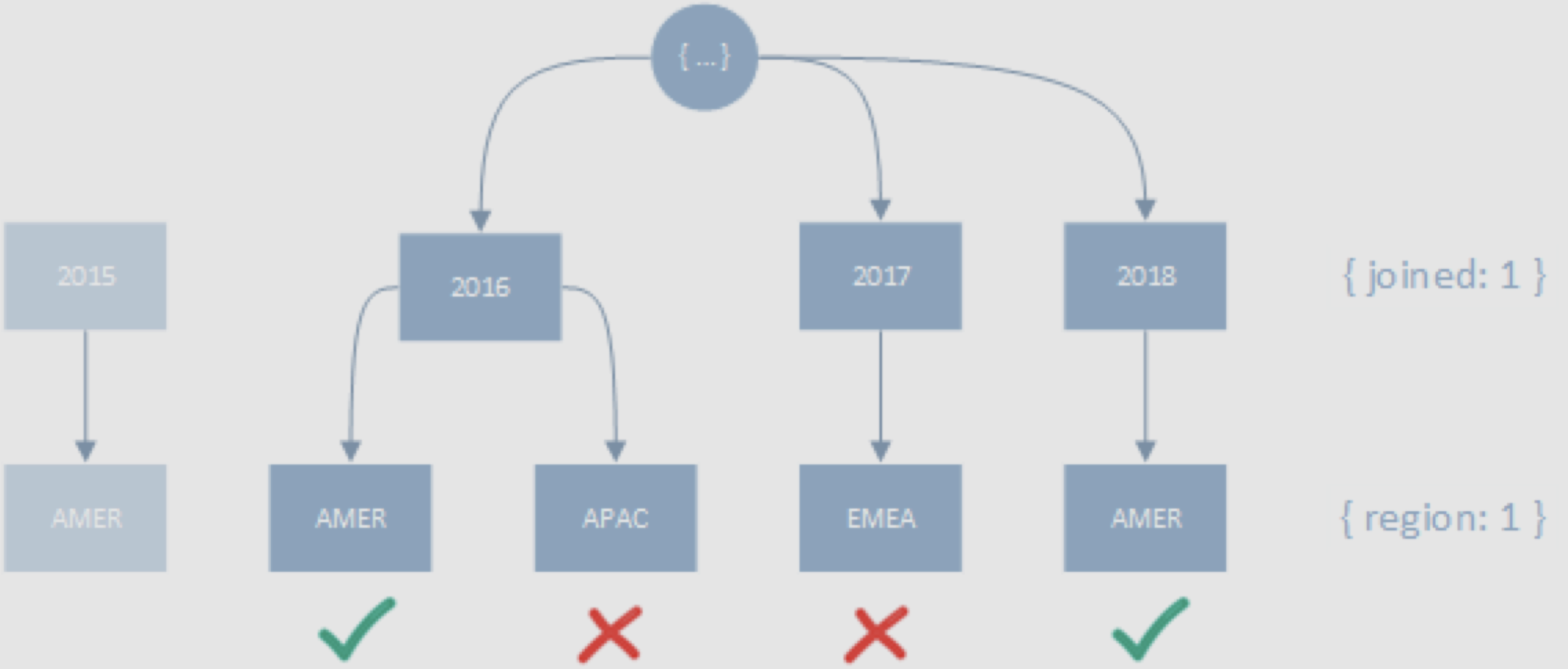
위 예시에서는 2개의 도큐먼트를 반환하기 위해 4개의 키를 스캔했다.
이와 반대로 동등 조건자가 먼저 오게끔 배치하면 스캔해야하는 키를 줄일 수 있다.
// operation
createIndex({ region: 1, joined: 1 })
find({ region: "AMER", joined: { $gt: 2015 } })// execution stats
"nReturned" : 2.0,
"totalKeysExamined" : 2.0,
"totalDocsExamined" : 2.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[\"AMER\", \"AMER\"]"
],
"joined" : [
"(2015.0, inf.0]"
]
},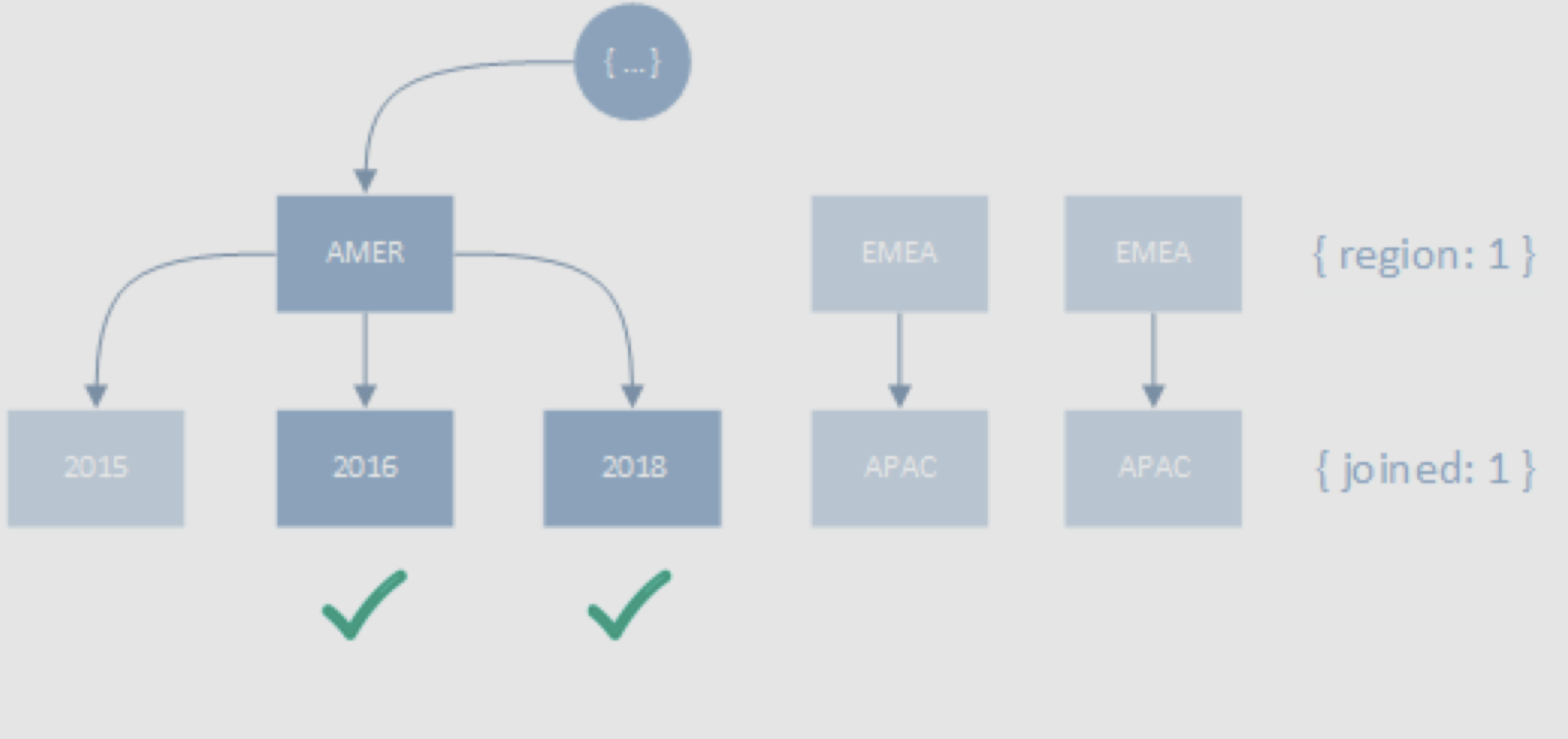
동등 조건자를 범위 조건 앞에 배치하면 정확히 필요한 만큼만 스캔할 수 있다.
(S → R) 범위 조건자 앞에 정렬 조건자를 배치한 경우
범위 조건자를 정렬 조건자 앞에 배치하면 정렬에 인덱스를 사용할 수 없으므로 정렬이 블로킹(blocking)을 유발할 수 있다.
// operation
createIndex({ joined: 1, region: 1 })
find({ joined: { $gt: 2015 } }).sort({ region: 1 })// execution stats
"nReturned" : 4.0,
"totalKeysExamined" : 4.0,
"totalDocsExamined" : 4.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "SORT",
...
"sortPattern" : {
"region" : 1.0
},
"memUsage" : 136.0,
"memLimit" : 33554432.0,
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"joined" : [
"(2015.0, inf.0]"
],
"region" : [
"[MinKey, MaxKey]"
]
},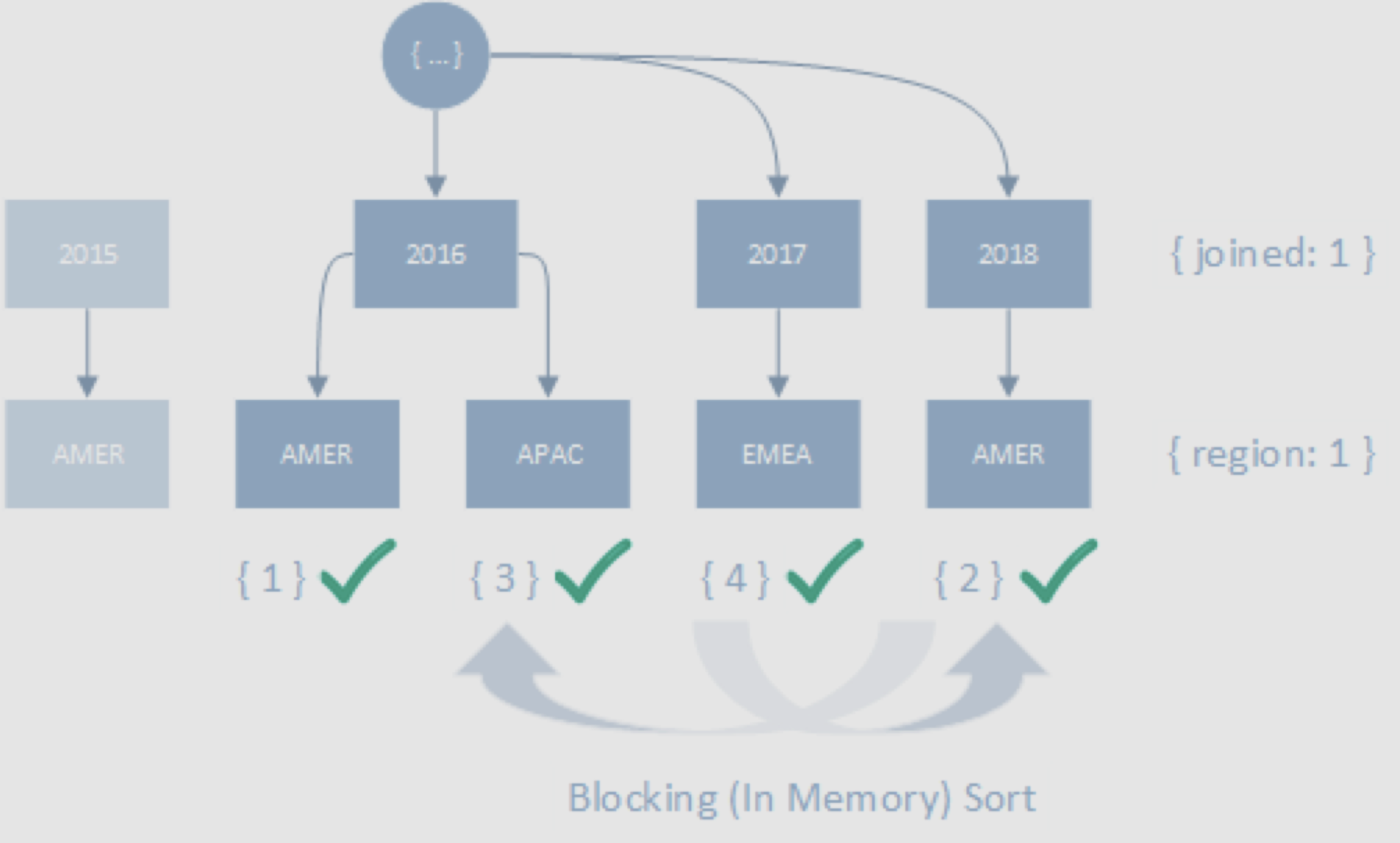
위에서 범위 조건자를 사용해 조건을 만족하는 4개의 키를 찾을 수 있었지만 쿼리 결과는 정렬되어 있지 않으므로 결과를 반환하기 전에 인메모리 정렬을 해야만 했다.
정렬 조건자를 범위 조건자 앞으로 옮기면 더 많은 키를 스캔해야 하지만 별도의 정렬 없이 결과를 반환할 수 있게 된다.
// operation
createIndex({ region: 1, joined: 1 })
find({ joined: { $gt: 2015 } }).sort({ region: 1 })// execution stats
"nReturned" : 4.0,
"totalKeysExamined" : 5.0,
"totalDocsExamined" : 5.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[MinKey, MaxKey]"
],
"joined" : [
"[MinKey, MaxKey]"
]
},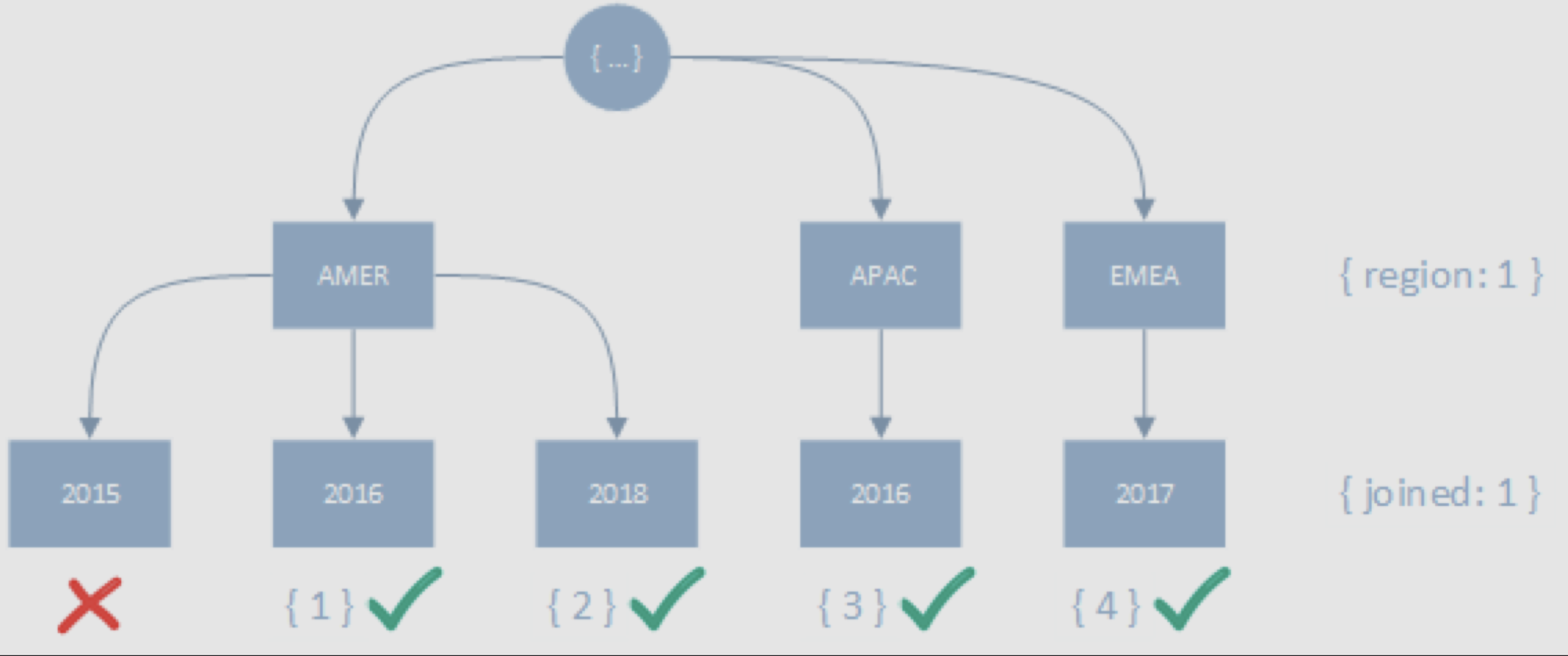
이 방식은 좀 더 많은 키를 스캔하지만 블로킹한 정렬이 수반되지 않으므로 일반적으로 더 좋은 성능을 보여준다.
마무리
ESR 규칙을 통해 몽고 디비 인덱스를 최적화하고 쿼리 성능을 향상시킬 수 있길 바라고, 질문이 있다면 댓글을 남기거나 몽고디비 개발자 커뮤니티 포럼을 이용하길 바란다.
세부적인 도움이 필요하다면 아틀라스 개발자 서포트나 엔터프라이즈 서포트를 찾아보길 바란다.
행복한 최적화가 되기를 바라며!
