[번역] 서버 I/O 성능 비교: Node vs PHP vs Java vs Go
이 글은 BRAD PEABODY의 글 Server-side I/O Performance: Node vs. PHP vs. Java vs. Go를 번역한 글입니다.
원문은 링크에서 찾아보실 수 있습니다.
애플리케이션의 I/O 모델은 애플리케이션 부하(load)를 처리하는 방식의 차이로 이해할 수 있습니다.
I/O 모델을 잘못 이해할 경우, 애플리케이션의 규모가 상대적으로 작고 부하가 높지 않을 때는 별 문제가 되지 않지만, 부하가 커졌을 때 큰 낭패를 겪을 수 있습니다.
모든 I/O 모델에는 장단점이 있기 때문에, 각 방식의 트레이드오프(trade-off)를 제대로 이해할 필요가 있습니다.
이번 글에서는 Node, Java, Go 그리고 PHP (Apache) 이상 4가지 언어의 I/O 모델이 가진 장점단점을 비교한 뒤 기초적인 벤치마크 결과도 측정해보겠습니다. I/O 성능에 관심이 있다면 끝까지 글을 읽어주세요.
I/O에 대한 기본적인 지식
I/O와 관련된 기본적인 것들을 이해하려면 운영체제 관련 몇 가지 컨셉을 이해해야 합니다. 이 컨셉을 직접 다룰 일은 없겠지만 애플리케이션의 런타임을 통해 간접적으로 접근하게 됩니다. 그리고 여기서 디테일을 이해하는 것이 중요합니다.
시스템 호출(System Calls)
시스템 호출이란
- (사용자 영역에서 실행되는) 프로그램이 I/O 작업을 수행하려면 운영체제의 커널에 허락을 구해야합니다.
- 여기서 시스템 호출이란 프로그램이 그 허락을 구하는 수단입니다. 각 운영체제마다 구현은 다를 수 있지만 기본적인 컨셉은 동일합니다. 프로그램이 커널에 특정 요청을 담은 함수를 호출합니다. 그리고 커널이 응답을 보내올 때까지 기다립니다. (일반적인 시스템 호출은 블로킹합니다.)
- 커널은 프로그램의 요구에 맞는 디바이스에 I/O 작업을 수행한 뒤 시스템 호출에 응답합니다. 실제로 커널이 프로그램의 요청에 응답하려면 한 가지 이상의 일을 해야될 수 있습니다. (디바이스가 준비될 때까지 기다리거나 내부 상태를 변경하는 등) 물론 그 부분은 커널의 일이고, 애플리케이션 개발자는 따로 신경쓰지 않아도 됩니다.
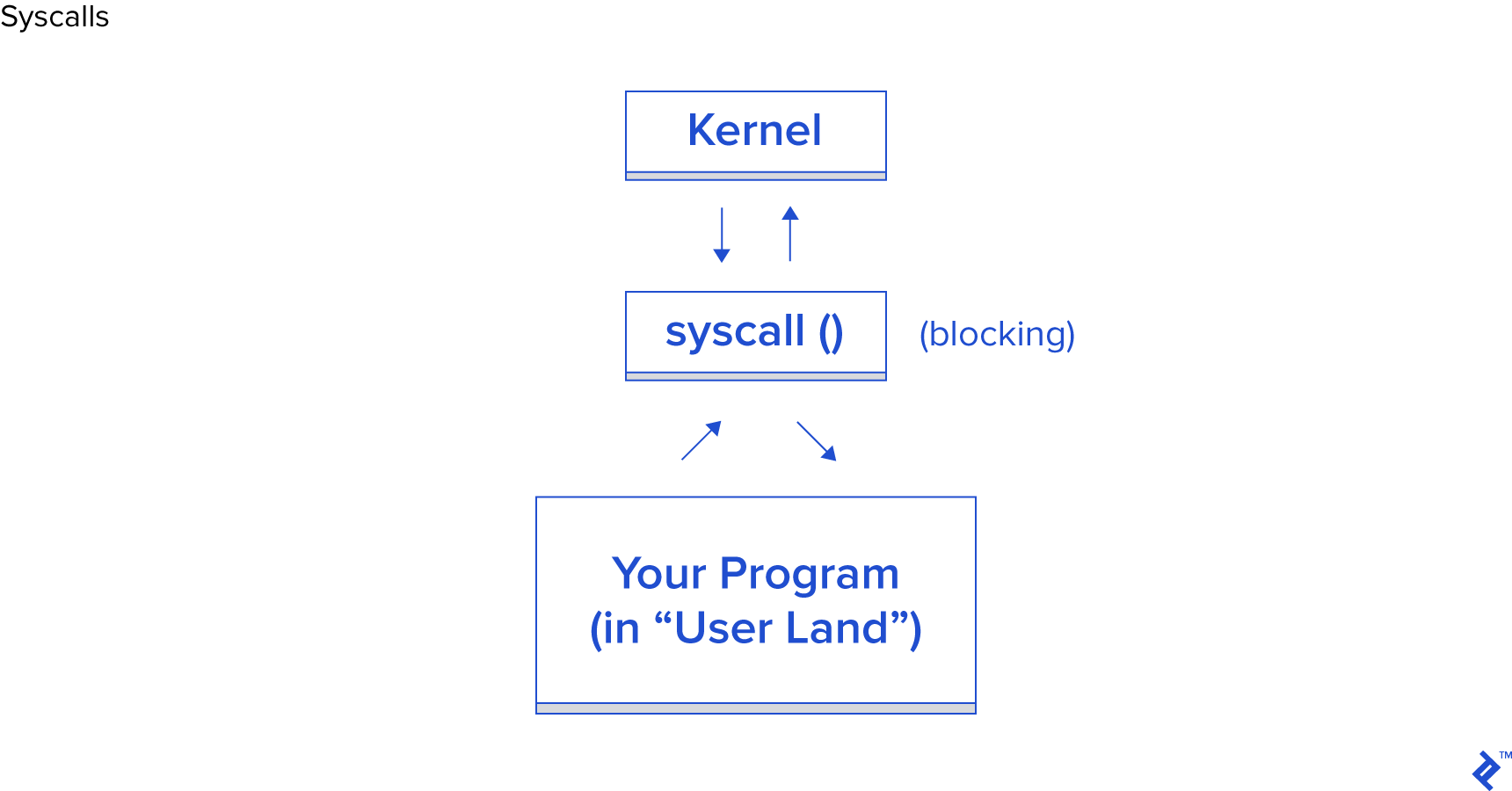
<시스템 호출은 커널과 프로그램이 상호작용하기 위한 일련의 인터페이스를 가리킨다>
블록킹 vs. 논 블록킹 호출
시스템 호출은 일반적으로 블록킹한 작업이라고 했습니다. 여기에도 예외는 있습니다. 커널이 특정 호출을 큐나 버퍼 같은 곳에 저장하고, 실제 I/O가 이뤄지기 전에 즉각적으로 응답을 보낼 수도 있습니다. 이때 해당 요청은 커널이 요청을 큐에 저장하는 동안만 블록킹하게 됩니다. 이러한 요청을 논 블록킹하다고 말합니다.
이제 리눅스의 시스템 호출 몇 가지를 살펴봅시다. read()는 블록킹한 호출입니다. read()는 파일 디스크립터와 읽은 데이터를 전달할 버퍼를 전달받아 데이터를 모두 읽은 뒤 요청을 종료합니다. 사용자는 read()의 리턴 결과에 따라 성공/실패 여부를 바로 판단할 수 있습니다. 따라서 read()는 사용하기 쉽고 단순합니다. 반대로 epoll_create(), epoll_ctl(), epoll_wait() 같은 함수는 각각 파일 디스크립터 그룹을 생성, 추가 혹은 제거하거나 I/O 이벤트를 기다리면서 블록킹합니다. 위 세 가지 함수를 사용하면 싱글 쓰레드로도 대량의 I/O 작업을 통제할 수 있습니다. 이는 큰 장점이지만 read()같은 단순한 함수를 사용할 때보다 복잡성이 올라갑니다.
중요한 점은 얼마나 큰 규모로 시간 차이가 발생하는지를 이해하는 것입니다. 어떤 CPU 코어가 별도의 최적화 없이 3GHz로 실행 중이라면 해당 CPU는 초당 30억 사이클을 수행합니다. 이 경우 논 블록킹 호출은 십여 사이클 혹은 수 나노초 안에 완료됩니다. 반면 네트워크를 통해 이뤄지는 블록킹 호출에는 긴 시간이 필요합니다. (200 밀리초가 걸린다고 합시다.) 그리고 논 블록킹 호출이 20 나노초 정도 걸렸다고 하면, 그 차이는 1000만배에 달합니다.

<블록킹 호출과 논 블록킹 호출 간의 시간 차이 - 무려 1000만배의 시간 차이가 발생했다.>
커널은 블록킹 방식("이 네트워크 연결로부터 데이터를 읽어서 전달해줘")과 논 블록킹 방식("이 중에 어떤 네트워크 연결에서 새로운 데이터가 도착하면 알려줘") 모두를 지원합니다. 그리고 위에서 살펴봤듯 어떤 방식을 사용하느냐에 따라 수 나노초에서 수백 밀리초까지 차이가 벌어질 수 있습니다.
스케쥴링
세번째로 알아볼 것은 다수의 쓰레드와 프로세스가 블록킹을 시작할 때 어떤 일이 일어나는가 입니다.
서버 I/O 성능 비교 측면에서 쓰레드와 프로세스 간에 구별되는 큰 차이는 없습니다. 차이라고 할 만한 점은 쓰레드는 메모리를 공유하지만 프로세스는 각각이 별도의 메모리 공간을 가지기 때문에 더 많은 메모리를 사용하게된다는 정도입니다. 하지만 CPU 사용 측면에서는 별반 다르지 않습니다. 스케쥴링의 가장 중요한 특징은 각각의 프로세스 혹은 쓰레드가 CPU 코어의 실행시간을 나눠가진다는 점입니다. 8코어 머신에 300개의 쓰레드가 실행될 때 각 쓰레드는 짧은 시간동안 실행되고 다음 쓰레드에 실행시간을 넘겨줍니다. 이 과정은 컨텍스트 스위칭(context switch)를 통해 수행됩니다.
컨텍스트 스위칭이 일어날 때마다 얼마간 시간이 소요됩니다. 소요 시간은 구현의 차이나 프로세서의 아키텍쳐나 속도, CPU 캐시 등의 요인에 의해 빠르면 100 나노초 미만에서 길게는 1000 나노초 이상 걸릴 수도 있습니다. 쓰레드(혹은 프로세스)가 증가할수록 컨텍스트 스위칭이 더 자주 발생하며 만약 수 천개의 쓰레드가 실행되고 있다면 각 쓰레드마다 수백 나노초의 컨텍스트 스위칭이 발생하게 되고 요청에 대한 처리가 굉장히 느려질 수 있습니다.
반면 논 블록킹 호출은 커널에 대해 "여기 연결들 중에 새로운 데이터가 도착하거나 새로운 이벤트가 발생하면 알려줘" 라고 말하는 것과 같으며 대규모 I/O 부하에 상대적으로 더 적은 컨텍스트 스위칭을 발생시키면서 처리할 수 있게 디자인되었습니다.
이제부터 인기있는 프로그래밍 언어가 어떤 I/O 모델을 채택했는지를 살펴보고 사용 편의성과 성능 간의 트레이드오프에 대해 알아보도록 합시다.
다음에 보여줄 예시는 간단한 요청을 예시로 들지만 데이터베이스 엑세스, 외부 캐싱시스템 혹은 I/O를 수반하는 어떠한 호출이라도 같은 영향을 미친다는 점 참고 부탁드립니다. 또한 블록킹 I/O로 묘사된 경우 (PHP, Java), HTTP 요청과 응답에 대한 읽기/쓰기 역시 블록킹 호출입니다.
프로젝트에 사용할 언어는 수 많은 요인에 의해 결정됩니다. 그리고 성능은 더 많은 요인에 의해 결정됩니다. 하지만 프로그램의 성능이 주로 I/O 성능에 의해 결정된다면 여기에 나오는 개념을 잘 이해할 필요가 있습니다.
최대한 단순하게: PHP
사람들이 컨버스를 신고 다니고 Perl로 CGI 스크립트를 짜던 90년대에 PHP는 혜성처럼 등장해서 동적인 웹페이지를 훨씬 쉽게 만들수 있게 만들어줬습니다.
PHP의 I/O 모델은 굉장히 단순합니다. 몇 가지 세부적인 차이를 제외하면 말이죠:
사용자의 브라우저로부터 발생한 HTTP 요청이 Apache 웹 서버로 전달됩니다. 서버는 각 요청에 대해 별도의 프로세스를 생성합니다. (재사용을 위한 약간의 최적화와 함께) 서버는 PHP에, 알맞은 .php 파일을 실행할 것을 요청합니다. PHP는 블록킹 I/O 요청을 수행합니다. PHP의
file_get_contents()함수는read()시스템 호출을 실행하고 그 결과를 기다립니다.
<?php
// blocking file I/O
$file_data = file_get_contents(‘/path/to/file.dat’);
// blocking network I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// some more blocking network I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>위 코드가 시스템과 상호작용하는 모습을 나타내면
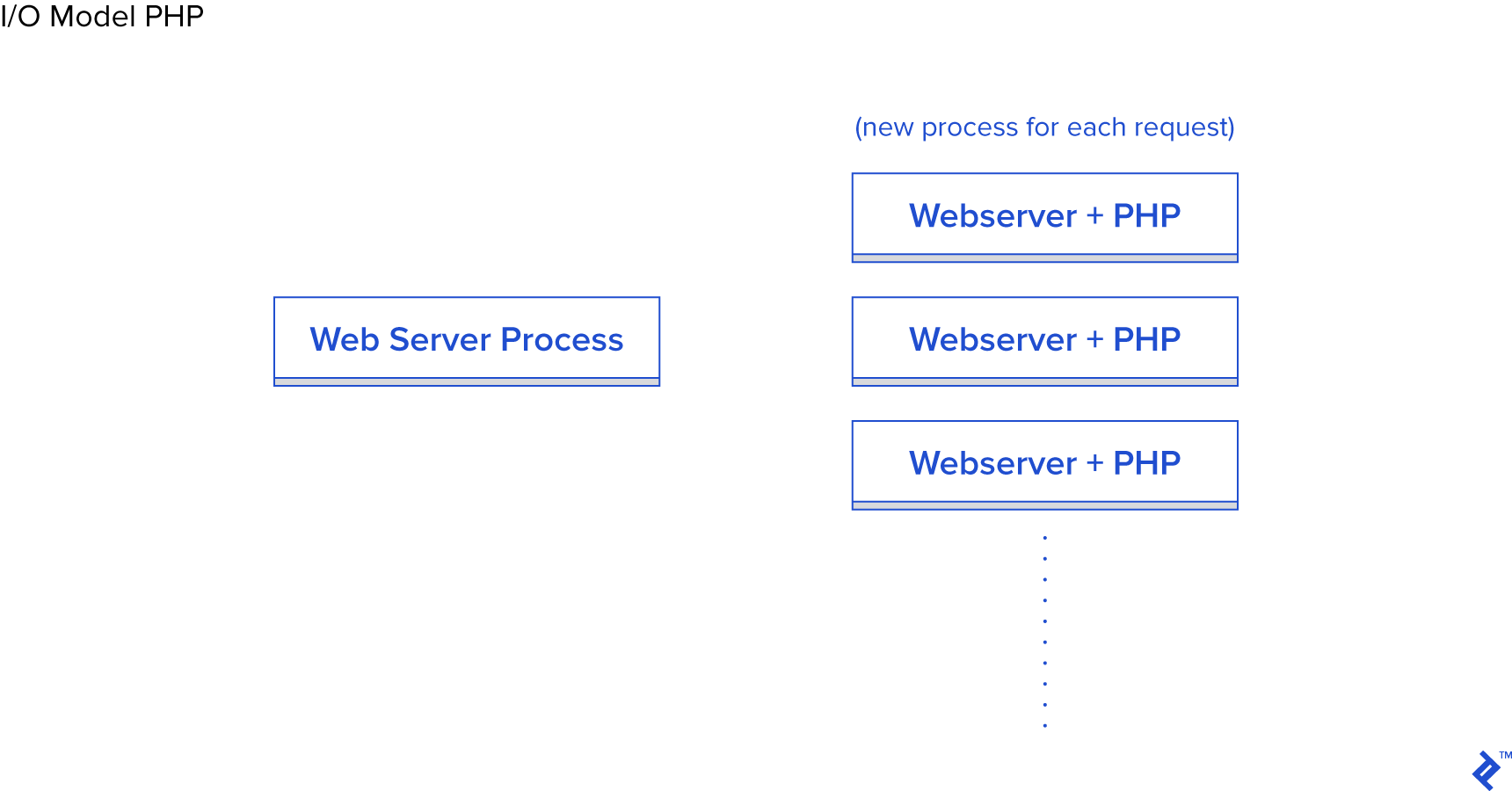
<PHP의 I/O 모델>
PHP 방식은 각 요청마다 별도의 프로세스를 할당하며 I/O 호출은 블록킹합니다. 이 모델의 장점은 모델 자체가 단순하고 별 문제없이 동작한다는 것입니다. 반면에 단점은 동시에 여러 클라이언트가 요청을 보낼 경우 서버에 큰 부담을 주게된다는 것입니다. 이 방식은 확장성이 부족하며, 각 요청에 대해 별도의 프로세스를 생성하는 방식은 많은 시스템 자원을 잡아먹고 심한 경우에는 메모리 부족을 초래하게 됩니다.
멀티쓰레딩 방식: Java
생애 최초로 도메인을 구입하고, 아무 문장에나 "닷컴"을 붙이던게 유행이던 시절, (역자주: 90년대 후반 2000년대 초반의 닷컴버블을 가리킴) 자바가 등장했습니다. 자바는 멀티쓰레딩 방식을 언어 차원에서 지원했으며, 이는 굉장한 기능이었습니다.
자바 웹 서버는 새로운 요청이 들어올 때마다 새로운 쓰레드를 생성하여 해당 쓰레드에서 개발자가 작성한 코드를 실행하는 방식으로 작동합니다.
자바 웹 서버가 I/O 작업을 수행하는 모습은 다음과 같습니다.
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// blocking file I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// blocking network I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// some more blocking network I/O
System.out.println("...");
}위 코드에서 doGet 메쏘드는 각 요청에 대해 별도의 프로세스를 생성하는 대신 별도의 쓰레드를 생성합니다. 이를 통해 각 쓰레드는 상태나 캐쉬된 데이터 등을 공유할 수 있게 됩니다. 물론 스케쥴링에 대해서는 PHP 모델과 바뀐 것이 없습니다. 쓰레드를 효율적으로 사용하기 위해 풀을 구성하긴하지만 수 천개의 동시 요청이 들어오면 여전히 수 천개의 쓰레드를 생성해야만 합니다. 그리고 이는 스케쥴링에 부정적인 영향을 미칩니다.
자바 1.4버전에서 주목할만한 점은 자바에서 논 블록킹 I/O 호출을 할 수 있는 수단이 생겼다는 점입니다. 대부분의 웹 애플리케이션에서 이를 사용하지는 않지만 적어도 논 블록킹 호출이 가능은 하다는 것이죠.

<Java의 I/O 모델>
자바는 PHP 모델에서 일보 전진한 모습을 보여줬지만 주로 I/O 작업이 많은 애플리케이션이 가진 문제점(동시에 수많은 요청이 들어왔을 때 수많은 쓰레드를 생성해야만함)을 완전히 해결하지는 못했습니다.
논 블록킹 I/O가 일등시민: Node
진보적인 I/O 모델에 대해 얘기할 때면 빠지지 않는 언어가 Node.js입니다. Node.js에 대해 아는 것이 거의 없더라도 Node.js가 "논 블록킹"이며 효율적으로 I/O를 처리한다는 것쯤은 들어봤을 것입니다.
Node.js의 패러다임은 요약하면 요청을 처리하기 위한 코드를 작성하는 대신 요청 처리를 시작하기 위한 코드를 작성하는 것입니다. I/O 작업을 처리할 때마다 해당 요청이 처리되었을 때 실행할 콜백함수를 작성하는 방식인거죠.
Node.js에서 일반적인 I/O 작업은 아래 코드와 같은 방식으로 이뤄집니다.
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});위 코드에는 두 가지 콜백 함수가 존재합니다. 첫 번째 함수는 요청이 시작될 때, 두 번째 함수는 파일을 모두 읽은 뒤 호출됩니다.
Node.js는 이러한 방식을 통해 I/O 요청을 효율적으로 처리합니다. 효율성이 더 도드라지는 경우는 데이터베이스 요청을 할 경우인데, 이 과정에서 유저가 데이터베이스 호출과 그에 대한 콜백함수를 넘기면, 논 블록킹 호출을 통해 I/O 작업을 완료한 뒤 필요한 데이터가 도착하면 콜백함수를 실행시킵니다. 이러한 메커니즘을 이벤트루프(Event Loop)라고 부릅니다.
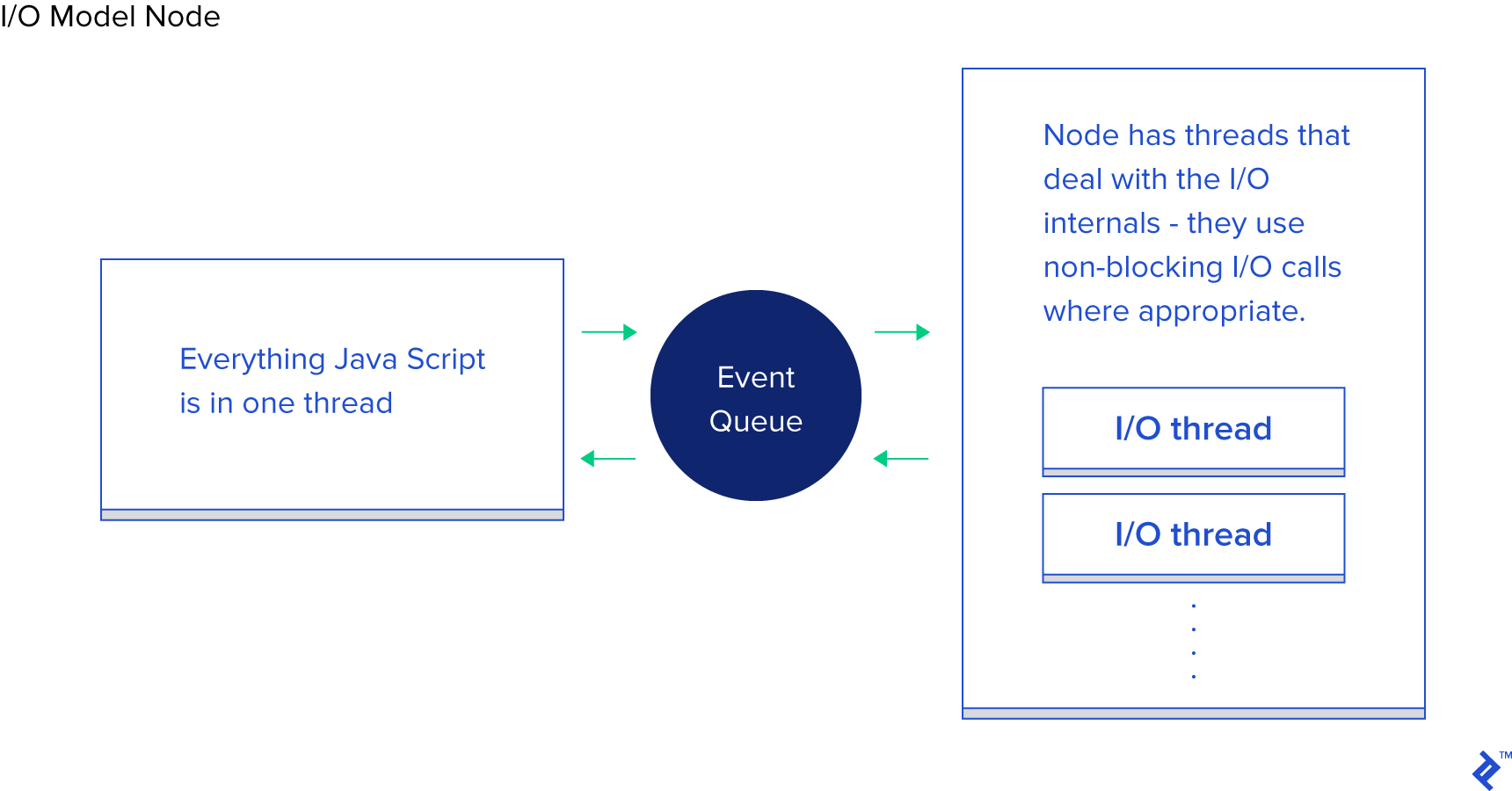
<Node.js의 I/O 모델>
하지만 이 모델에도 한 가지 단점은 있습니다. 이는 JavaScript의 V8 엔진이 동작하는 방식과 관련이 있는데, 바로 Node.js가 싱글 쓰레드에서 동작한다는 점입니다. 그리고 이는 I/O 작업은 효율적인 논 블록킹 메커니즘을 통해 처리되지만 CPU 집중적인 작업은 블록킹 방식으로 처리될 수밖에 없다는 것을 의미합니다. 한 예로 데이터베이스에서 필요한 레코드를 가져와서 클라이언트에게 전달하는 경우를 생각해보면,
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// do processing on each row
}
response.end(...); // write out the results
})
};I/O 작업은 효율적으로 처리될지 모르지만, for 문은 메인 쓰레드 상에서 CPU 사이클을 사용하여 처리됩니다.
이는 연결이 많아지면 for 문의 실행속도에 따라 어플리케이션의 성능저하를 불러올 수 있다는 것을 의미합니다. 각 요청이 반드시 메인 쓰레드 상에서 일정 시간만큼 CPU를 점유하면서 실행되어야하기 때문이죠.
Node.js 모델은 I/O 작업이 통상적으로 가장 느리다는 믿음에 기반합니다. 그러므로 I/O 작업을 제외한 다른 모든 작업을 순차적으로 처리하더라도 I/O 작업을 효율적으로 처리하는 것이 가장 중요합니다. 이는 어떤 경우에는 들어맞지만 아닐 때도 있습니다.
또 다른 단점은 중첩된 콜백 코드를 쓰고 읽는 것이 가독성에 영향을 미친다는 점입니다. Node.js 코드에서 4단계, 5단계 혹은 그 이상 중첩된 코드를 보는 일은 드문 일이 아닙니다.
이제 Node.js 모델의 트레이드오프를 생각해봅시다. Node.js 모델은 주요 성능 문제가 I/O 작업에서 발생할 경우에는 효율적으로 동작하지만, 만약 CPU 집중적인 코드가 끼어든다면 전체 요청 처리 속도를 심각하게 저하할 수 있습니다.
처음부터 논 블록킹: Go
Go에 대한 이야기를 하기 전에 제가 Go를 개인적으로 좋아한다는 얘기를 먼저 해야겠군요. 저는 개인적으로 다수의 프로젝트에 Go를 사용해왔고, Go를 사용함으로써 생산성을 높힐 수 있다고 생각합니다.
자 이제, Go가 어떤 식으로 I/O를 처리하는지 살펴봅시다. Go의 핵심 기능 중 하나는 Go 런타임이 자체 스케쥴러를 포함한다는 점입니다. 각 쓰레드가 운영체제 쓰레드 하나에 대응되는 대신 Go는 고루틴(goroutines)를 사용해 I/O 작업을 처리합니다. Go 런타임은 각 고루틴을 운영체제 쓰레드에 할당하여 코드를 실행하거나 잠시 멈추거나(suspend) 운영체제 쓰레드에서 할당해제할 수 있습니다. Go HTTP 서버에 도착한 각 요청은 별도의 고루틴에서 처리됩니다.
이를 다이어그램으로 나타내면:
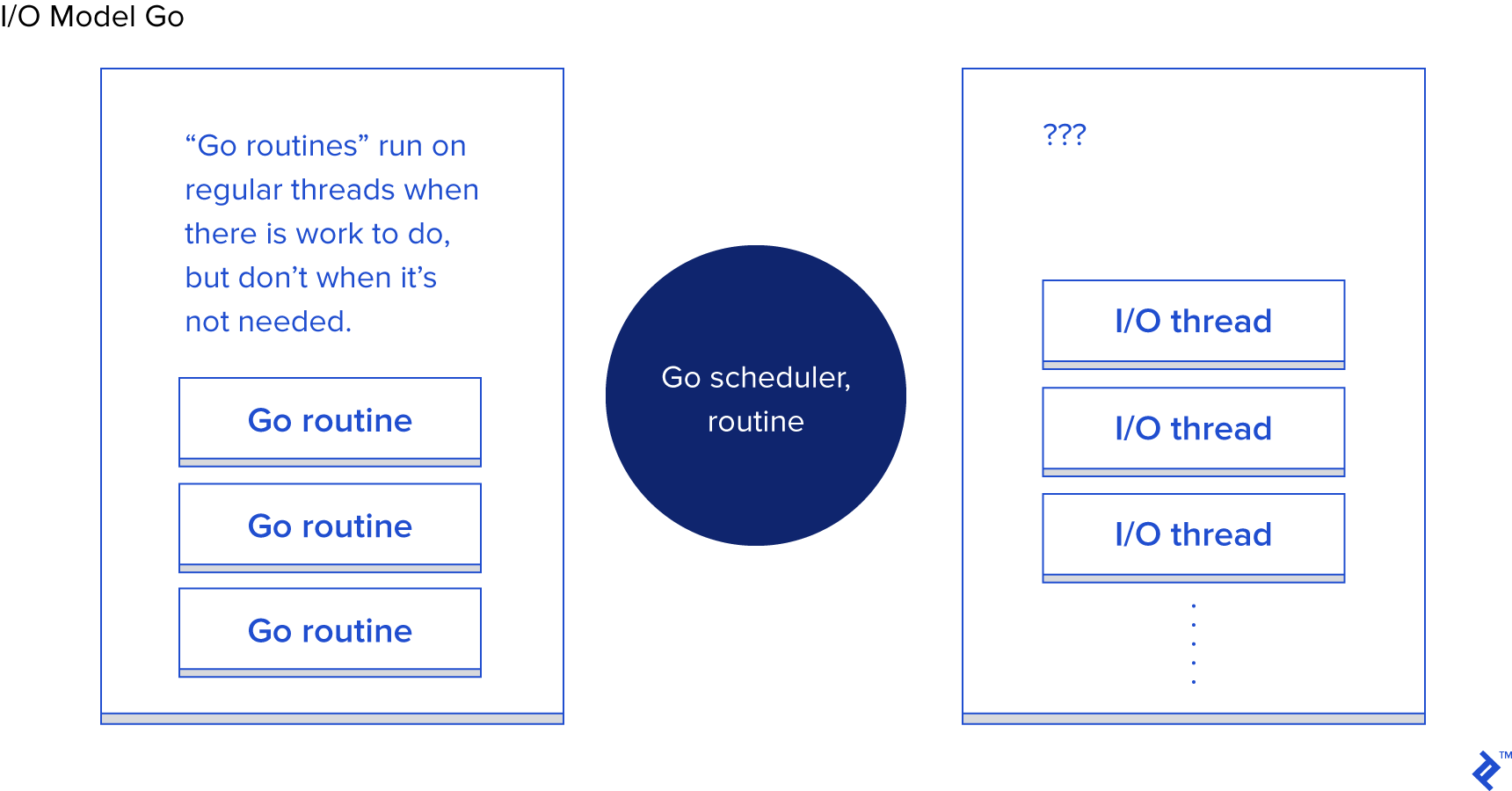
<Go의 I/O 모델>
실제로 Go 런타임은 Node.js와 비슷한 일을 하고 있지만 Go에서는 콜백 방식을 사용하지 않더라도 해당 메커니즘이 자동적으로 처리됩니다. 또한 모든 코드를 같은 쓰레드에서 실행시켜야한다는 제약(역자주: Node.js 코드는 싱글쓰레드 상에서 동작한다)에서도 자유롭습니다. Go는 자체 스케쥴러를 활용해서 각 고루틴을 적절한 운영체제 쓰레드에 분배합니다. 이를 코드로 나타내면 아래와 같습니다.
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// the underlying network call here is non-blocking
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// do something with the rows,
// each request in its own goroutine
}
w.Write(...) // write the response, also non-blocking
}위에서 볼 수 있듯이 코드 구조는 Java나 PHP의 단순한 구조와 비슷한 모습을 하고 있지만 동작할 때는 논 블록킹 I/O를 활용하고 있습니다.
대부분의 경우 이는 각 방식의 장점을 합친 것(the best of both worlds)입니다. 중요한 I/O 작업은 모두 논 블록킹 방식으로 처리되면서도 코드는 여전히 블록킹 방식일 때와 차이가 없기 때문에 단순하고 이해하기 쉽습니다. Go 런타임의 스케쥴러와 운영체제의 스케쥴러가 나머지를 모두 처리해줍니다. 물론 이는 완전히 마법같은 일은 아니며 거대한 시스템을 만들기 위해서는 Go 런타임의 동작 방식에 대해 이해할 필요가 있습니다. 물론 Go 런타임은 특별한 트릭 없이도(out-of-the-box) 잘 동작하며 쉽게 확장 가능합니다.
Go에도 몇 가지 단점이 존재하지만 적어도 I/O 처리는 단점이라고 생각하지 않습니다.
벤치마킹
컨텍스트 스위칭이 미치는 정확한 영향에 대해 측정하는 일은 굉장히 까다롭기 때문에 대신 전체 HTTP 요청에 대한 간단한 벤치마크를 비교하고자 합니다. 이에 앞서 해당 수치는 기본적인 비교에 지나지 않으며 실제 HTTP 요청/응답에 영향을 미치는 요소는 굉장히 다양하다는 점을 항상 기억해두길 바랍니다.
벤치마킹을 진행한 환경은 아래와 같습니다.
- PHP v5.4.16; Apache v2.4.6
- Java (OpenJDK) 1.8.0_131-b11; Tomcat v7.0.69 (without APR/native)
- Node.js v6.10.3
- Go v1.8.1
각 언어에 대해 저는 N번 SHA-256 해쉬를 실행한 64000개 파일을 읽은 뒤 그 결과를 hex로 보여주는 코드를 작성했습니다.
먼저 동시성이 낮은 경우를 한 번 비교해봅시다. 300개의 동시 요청에 2000회를 반복하며 N이 1일 경우:
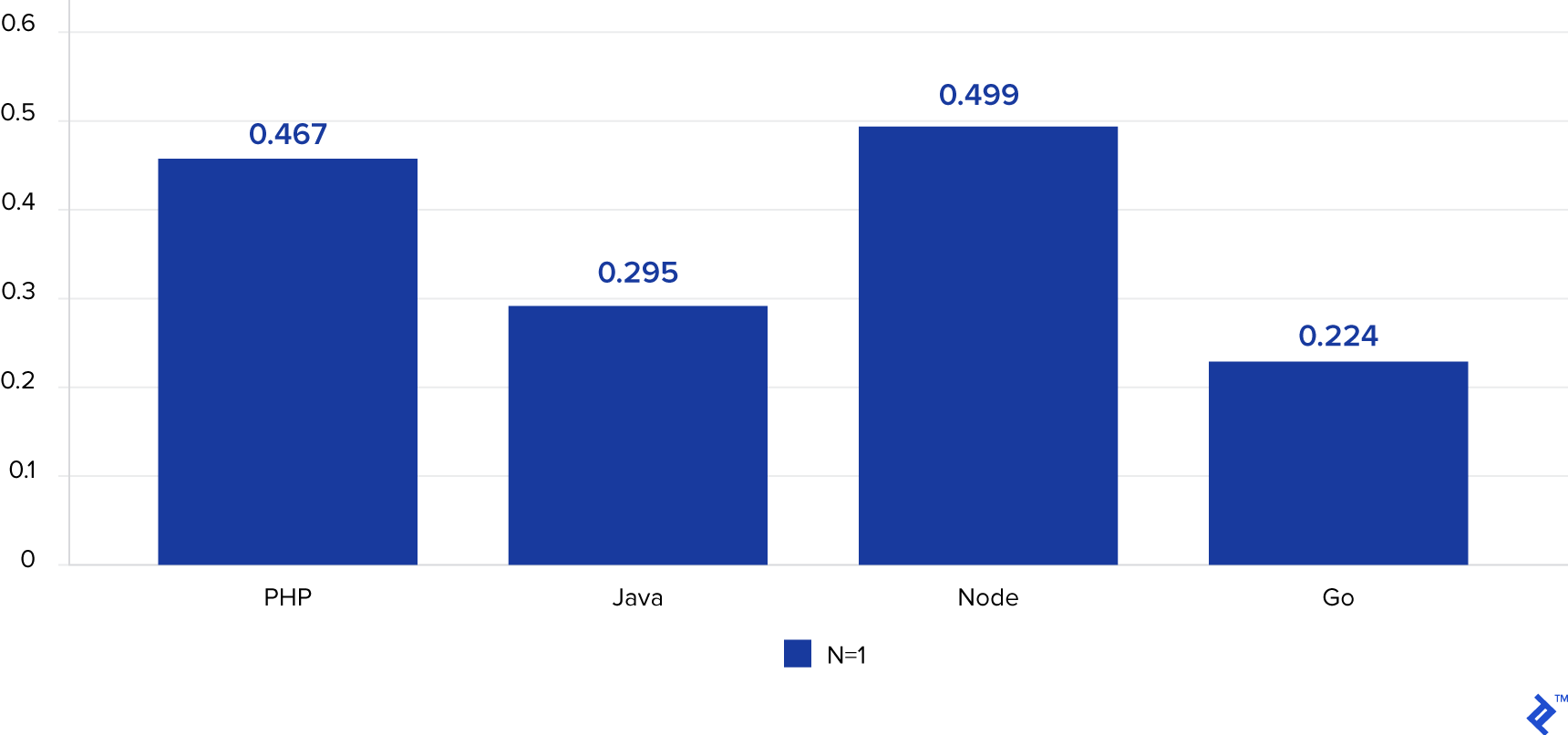
시간은 요청을 완료하기까지 걸린 시간의 평균 밀리초입니다. 작을 수록 성능이 더 낫습니다.
그래프 하나만 보고 결론을 내리기는 어렵지만 결과를 보니 이 정도 요청 개수와 연산이라면 처리 속도는 언어 자체의 처리 속도와 더 큰 관련이 있는것 처럼 보입니다. 즉, 일반적으로 "스크립트 언어"로 분류된 언어들이 더 느린 것으로 나타났습니다.
이제 다른 조건은 동일한 상태에서 N을 1000으로 올리면 어떻게 될까요? (더 많은 CPU 부하)
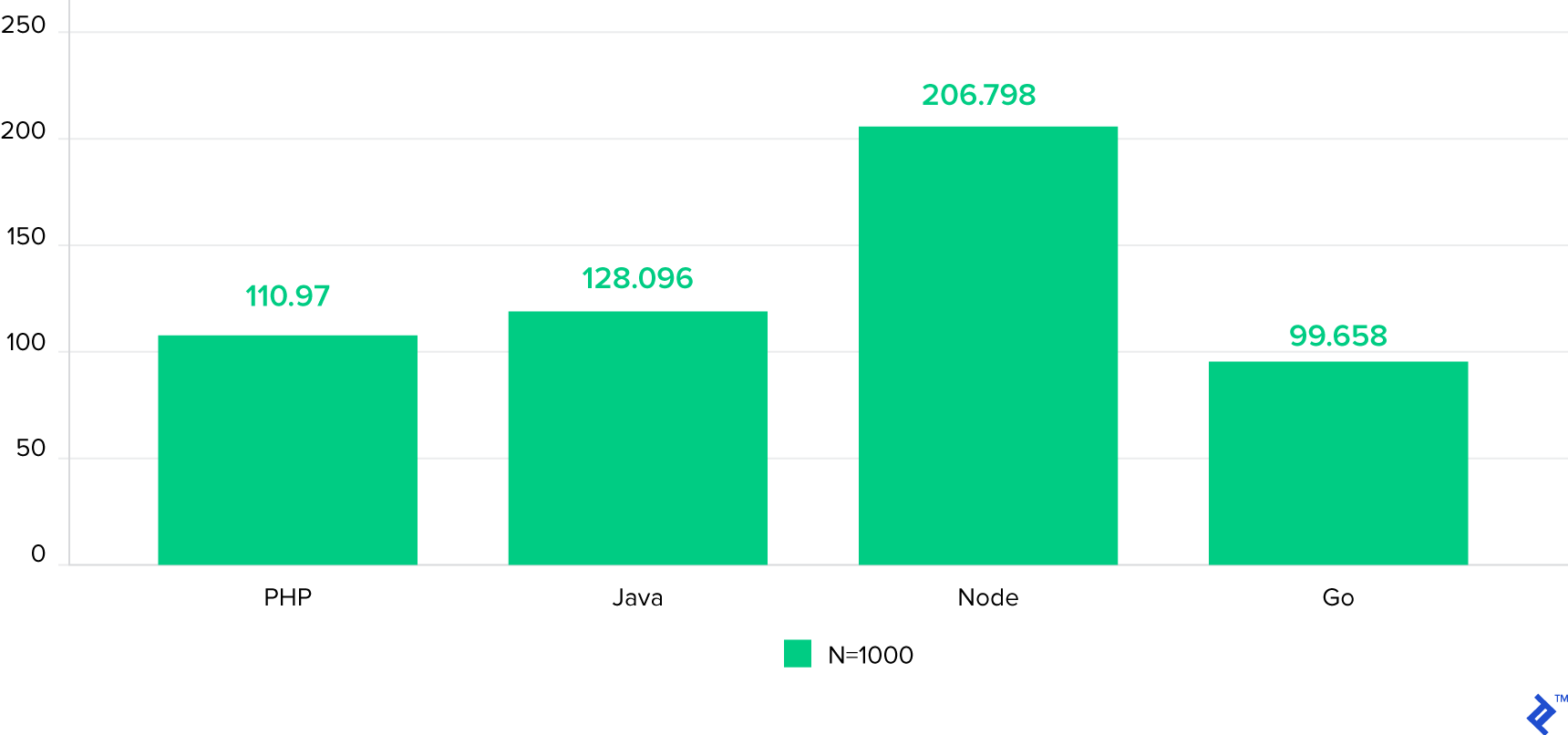
시간은 요청을 완료하기까지 걸린 시간의 평균 밀리초입니다. 작을 수록 성능이 더 낫습니다.
갑자기 Node.js의 성능이 확연히 감소했는데 이는 CPU 집중적인 작업이 각 요청을 블록킹하기 때문입니다. 그리고 흥미롭게도 PHP가 상대적으로 선전하여 자바를 제쳤습니다.
이제 N은 1이고 5000개의 동시요청을 처리하는 경우를 살펴봅시다. 이번 차트에서는 시간 당 전체 요청 개수를 살펴보겠습니다. 클수록 성능이 더 낫다는 것을 의미합니다.
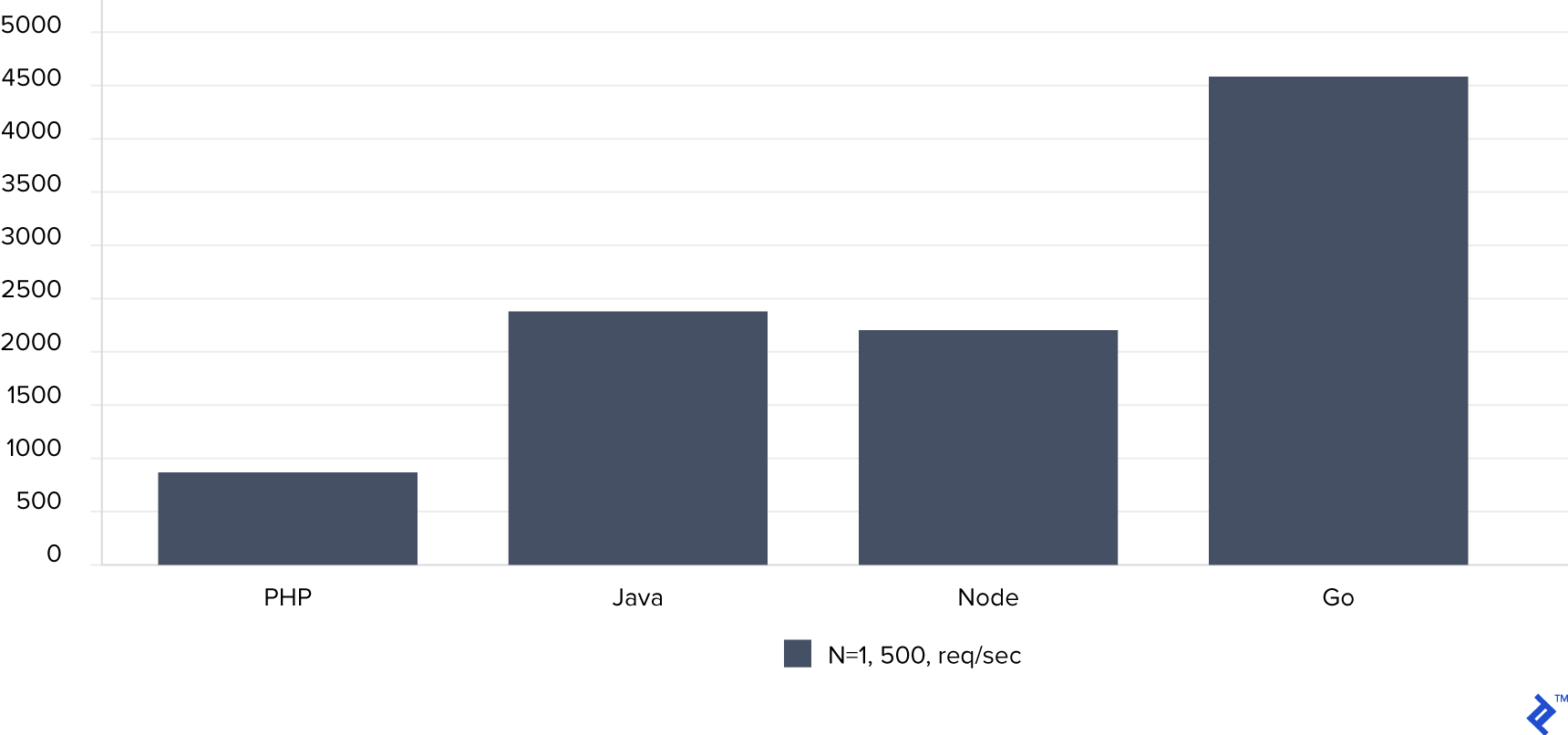
시간 당 처리할 수 있는 요청의 개수입니다. 클수록 성능이 더 낫습니다.
추측에 불과히지만 연결의 개수가 많아질수록 새로운 프로세스를 띄우는 오버헤드가 커져 PHP의 성능에 큰 영향을 미친 것 같습니다. 분명한 점은 Go의 시간당 처리할 수 있는 요청 개수가 가장 많으며, 다음은 Java, Node 그리고 PHP순이라는 것입니다.
애플리케이션에 따라 성능에 영향을 미칠 수 있는 요소가 다를 수 있겠지만 애플리케이션의 작동 방식에 대해 더 많이 이해하고 어떤 트레이드오프가 있는지 명확하게 이해할수록 더 높은 성능을 끌어낼 수 있을 것입니다.
정리
위 벤치마킹 결과를 보면 확실히 언어가 발전하면서 대규모 I/O를 처리하는 능력도 발전해왔습니다.
사실 PHP와 Java에는 본문의 설명과는 달리 논 블록킹 호출에 대한 구현이 존재합니다. 하지만 위의 접근방식보다는 흔하지 않은 편입니다. 또한 논 블록킹으로 돌아가는 코드를 작성하려면 "일반적인" PHP/Java 애플리케이션 코드를 크게 수정해야만 합니다.
본문의 내용을 표로 정리하면 아래와 같습니다.
| 언어 | 쓰레드 vs 프로세스 | 논 블록킹 I/O | 사용의 편의성 |
|---|---|---|---|
| PHP | 프로세스 | X | - |
| Java | 쓰레드 | 존재함 | 콜백 |
| Node.js | 쓰레드 | O | 콜백 |
| Go | 쓰레드(고루틴) | O | 콜백이 필요없음 |
이 중에서 최고를 뽑아야만 한다면 저는 망설임없이 Go를 선택할겁니다.
그럼에도 실제 개발 환경에서 더 중요한 요소는 1) 개발언어에 대한 친숙함 2) 해당 언어를 사용했을 때 얻을 수 있는 생산성 같은 것들입니다. 그러니 갑자기 모든 팀이 Node나 Go를 사용하는 것이 타당하지 않을 수도 있습니다. 실제로 개발자 구직이나 현재 사용 중인 언어에 대한 친숙함 등이 새로운 언어/환경을 사용하지 않을 이유로 뽑히곤 합니다.
이 글이 각 언어가 가진 I/O 모델에 대한 인사이트를 제공하고 실제 환경에서 확장성이 어떤 식으로 동작하는지 이해하는데 도움이 되었으면 좋겠습니다. Happy I/O!
후기
저자가 Go를 편애한다는 점과 벤치마킹 결과가 그다지 정확하지 않을 수 있다는 점만 빼면 일반적으로 I/O 모델이 각 언어에서 어떤 식으로 동작하는지 높은 레벨에서 알려주는 영양가 높은 글 같다.
5년도 더 지난 글이기 때문에 지금과는 맞지 않는 내용도 다수 있지만 그럼에도 동작 원리 등은 거의 변하지 않았기 때문에 벤치마킹 부분을 제외하고 본다면 재밌게 읽을 수 있을 것 같다.
잘못된 번역 혹은 개선점이 있으시다면 댓글로 알려주세요 🎉

12개의 댓글

Go 개발자 신가요? 결과를 보면 node와 php가 구리고 Go가 가장 좋다는 소리군요. Go이외에 다른 언어들을 몇년 전 버전과 비교한 것이 Go에 대한 신뢰도를 오히려 떨어지게 만드는것 같습니다. 좋은 정보 감사드려요.

저거 실험 결과가....좀.
Node.js의 버전이 낮은건 둘째치고 (다른것들도 낮은것 같음.)
같은 머신이라고 했을 때
배포 시 cpu 놀지 말라고 클러스터링 셋팅하고 하는데
그에 대한 말이 없네요.
다른 언어들은 전부 멀티스레드 사용하는데
노드만 서버에서 자원하나만 돌린것 같은데요.
맞다면 너무 편파적인것 같습니다.
cpu집중 작업은 당연히 성능 딸리겠지만...



< 테스트 시 사용된 버전 비교 >
1. PHP v5.4.6 : 2013년 5월 Release / Apache v2.4.6 : 2013년 7월 Release
2. Java OpenJDK v1.8.0_131 : 2017년 4월 Release / Tomcat v7.0.69 : 2016년 4월 Release
3. NodeJS v6.10.3 : 2017년 5월 Release
4. Golang v1.8.1 : 2017년 Release
의도적으로 태클 걸고 싶진 않았습니다만
테스트에 사용된 각각의 버전을 확인해 보니 그냥 넘어갈 수가 없네요.
Java, NodeJS, Golang 모두 비슷한 시기의 버전을 사용했으나
유독 PHP와 Apache는 심하게 구버전을 사용하셨네요. ㅡ_ㅡ
비슷한 시기라면 PHP는 최소 7점대 버전으로 테스트 하는게 맞을텐데요.
게다가 웹서버로 사용하는 Apache도 덩달아 구버전을 사용하시니
당연히 다른 언어에 비해 성능이 현저하게 낮게 나올 수 밖에 없지요.
의도적으로 PHP를 까고 싶으셨던 것인지는 모르겠으나
애초에 형평성에 맞지 않는 불공정한 테스트를 하셨습니다.
정말 공정한 성능 테스트를 하려면 테스트 시점일 기준으로
각각 최신안정화버전(LTS) 으로 테스트를 해야 합니다.
테스트에는 공정성이 기본 입니다.
그걸 뺴고 테스트하면 그게 무슨 테스트 입니까?
테스트를 통해 GO 언어를 자랑하고싶은 마음은 확인된 것 같네요.

번역은 재미있게 봤습니다만 논란의 여지가 많은 글이였네요.
실제 원글작성자는 io에 대해 설명하기 위함일 뿐이라고 하지만
사용된 벤치마크가 원래 얘기하고자 하는 요지를 흐릴 정도네요.
cenos 배포판에 들어있는 패키지로 테스트했다지만 다른 언어들보다 4년이나 전에 출시한 php 구버전으로
벤치마크를 뽑아낼 생각을 한다는게;;

좋은 글 감사합니다.
Node.js의 콜백이 사용자 편의성을 저해한다는 부분에 대해서는 지금 기준으로는 맞지 않는 부분인 거 같습니다.
1. Promise를 통한 콜백 지옥 탈출
2. async/await keyword를 통해 promise를 함수 형태로 작성
하면 해결될 수 있는 부분이기 때문입니다.
원문 추가 댓글 (feat. 울며 지나가던 PHP개발자)