Audio AI에서 굉장히 많은 citation을 받은 SALMONN을 리뷰해보도록 하겠습니다.
SALMONN 논문 링크
SALMONN 깃헙

이와 관련된 논문들이 있는데, 이는 밑에 참고사항에 적어보도록 하겠습니다.
0. Abstract
Introduction
SALMONN는 사전 학습된 텍스트 기반 대형 언어 모델(LLM)을 음성 및 오디오 인코더와 통합하여 멀티모달 모델로 개발된 시스템입니다. 이 모델은 다양한 음성 및 오디오 입력을 직접 처리하고 이해할 수 있는 능력을 갖추고 있습니다.
Key Features
-
훈련 작업 성능:
- 음성 인식(ASR) 및 번역
- 청각 정보 기반 질문 응답
- 감정 인식
- 화자 검증
- 음악 및 오디오 캡셔닝
-
Emergent Abilities (훈련되지 않은 작업):
- 훈련되지 않은 언어로 음성 번역
- 음성 기반 슬롯 채우기(Slot Filling)
- 음성 쿼리를 통한 질문 응답
- 오디오 기반 스토리 생성
- 음성과 오디오의 공동 추론(Co-Reasoning)
Innovation
- Cross-Modal Emergent Abilities:
- 다양한 멀티모달 작업에서 새로운 능력이 자발적으로 나타남.
- Few-Shot Activation Tuning:
- 새로운 작업 능력을 활성화하기 위한 효율적인 미세 조정 방법을 제안.
Significance
SALMONN은 일반적인 청각 능력을 갖춘 AI 개발을 향한 중요한 발걸음을 제시합니다. 공개된 소스 코드, 모델 체크포인트, 데이터는 연구자들이 활용할 수 있도록 제공됩니다.
1. Introduction
SALMONN 개요
SALMONN은 음성, 오디오 이벤트, 음악과 같은 세 가지 기본 유형의 소리를 이해할 수 있는 멀티모달 오디오-텍스트 LLM입니다.
Whisper 모델과 BEATs 오디오 인코더를 결합한 듀얼 인코더 구조를 사용하며, Q-Former와 LoRA를 활용하여 텍스트-오디오 정렬을 효과적으로 수행합니다.
주요 문제
- Task Over-Fitting:
- Instruction Tuning 단계에서 학습된 작업(예: 음성 인식, 오디오 캡셔닝)에는 높은 성능을 보이나, 새로운 작업에 대한 Emergent Abilities는 상실되는 문제.
- Emergent Abilities 활성화:
- 훈련되지 않은 작업(예: 새로운 언어 번역, 스토리 생성)을 수행할 수 있는 능력을 활성화하는 추가 학습 단계(Few-Shot Activation Tuning)를 제안.
평가 및 성능
-
벤치마크 레벨:
- Level 1: 음성 인식, 번역, 오디오 캡셔닝(훈련된 작업).
- Level 2: 번역(훈련되지 않은 언어), 슬롯 채우기.
- Level 3: 오디오 기반 스토리 생성, 음성과 비음성 공동 추론.
-
실험 결과:
- SALMONN은 단일 모델로 모든 작업을 수행하며 경쟁력 있는 성능을 입증.
- 일반적인 청각 데이터를 이해할 수 있는 AI 가능성을 제시.
기여 요약
- SALMONN 제안:
- 음성, 오디오 이벤트, 음악을 처리할 수 있는 최초의 멀티모달 오디오-텍스트 LLM.
- Emergent Abilities 활성화:
- LoRA 스케일링 계수를 조정하여 Emergent Abilities를 활성화하고, Catastrophic Forgetting 문제를 완화하는 Few-Shot Activation Tuning 제안.
- 광범위한 평가:
- 음성, 오디오 이벤트, 음악에 대한 벤치마크 작업 평가를 통해 일반 청각 인공지능의 가능성을 검증.
2. Related Work
LLM과 Speech
- LLM을 직접 음성 입력을 처리할 수 있도록 확장하려는 연구들이 진행됨:
- 프레임 속도 감소 방법:
- 고정 속도 기반(Stacking): Fathullah et al., 2023; Yu et al., 2023.
- 가변 속도 기반(Speech Recognition)
- Q-Former 기반
- 음성 합성까지 포함한 모델:
- 프레임 속도 감소 방법:
Audio Events
- 오디오 이벤트 입력은 고정 크기의 스펙트로그램 이미지로 처리되며, 시각-언어 기반 LLM 방식을 사용:
- Gong et al., 2023a;b; Zhang et al., 2023b.
- 그러나 이는 음성을 처리하지 못하는 한계가 있음.
- Whisper 기반 오디오 이벤트 모델(Lyu et al., 2023)도 음성과 비음성을 통합 처리하지 못함.
Music
- MERT 음악 인코더를 LLM에 통합(Liu et al., 2023).
- AudioGPT(Huang et al., 2023b)는 사전 정의된 작업 기반 파이프라인으로 음성, 오디오 이벤트, 음악을 처리.
SALMONN과의 차별점
- SALMONN은 엔드 투 엔드 모델로, 열린 작업(Open-Ended Tasks)을 위한 크로스모달 Emergent Abilities를 가짐.
멀티모달 LLM
- 시각 기반 연구(이미지, 비디오, 오디오-비주얼):
- Q-Former 구조는 MiniGPT-4 (Zhu et al., 2023), InstructBLIP (Dai et al., 2023), Video-LLaMA (Zhang et al., 2023b) 등에 적용됨.
- SALMONN은 Q-Former를 음성, 오디오 이벤트, 음악 입력으로 확장.
Q-former은 BLIP-2라는 논문에서 처음 소개됨.
3. METHODOLOGY
3.1 MODEL ARCHITECTURE
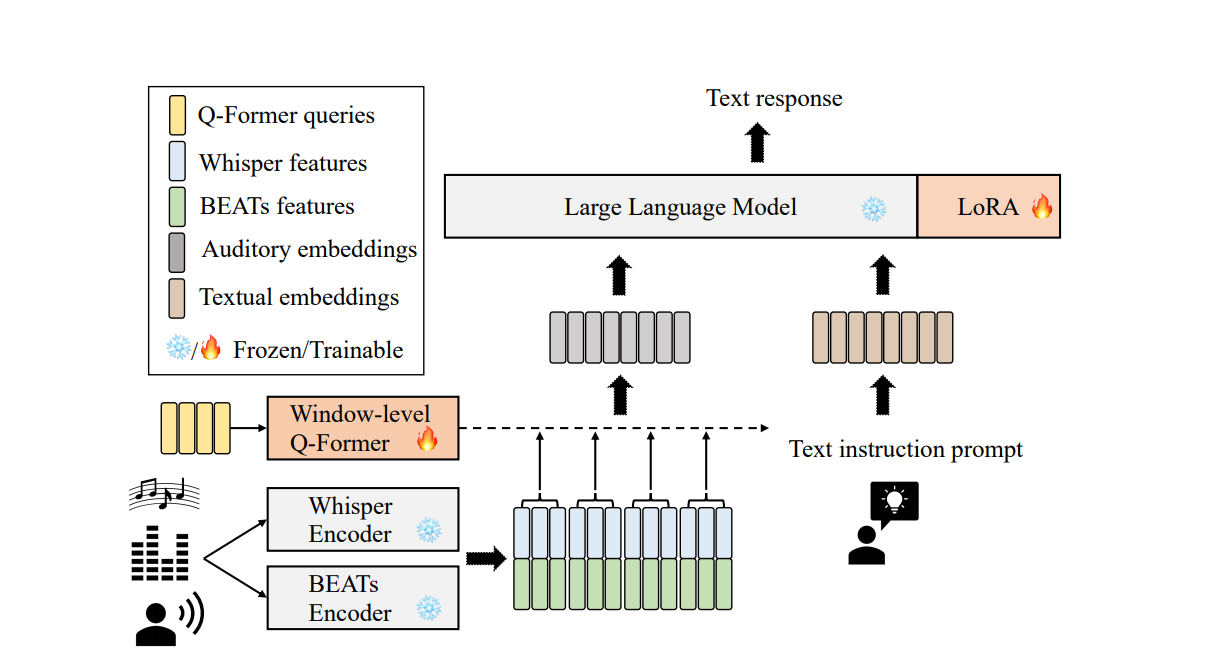
1. Whisper와 BEATs의 출력 결과
- Whisper와 BEATs 인코더에서 나온 출력은 각각의 특징(feature)들이고, 이 두 특징을 concat하여 하나의 시퀀스를 만듭니다:
- 여기서 는 길이가 인 프레임 시퀀스입니다.
- 는 Whisper와 BEATs가 각각 생성한 음성 정보와 비음성 정보를 결합한 것입니다.
2. Window로 나누는 과정
- 는 길이가 인 시퀀스지만, 이를 직접적으로 처리하면 너무 길어서 효율성이 떨어질 수 있습니다. 따라서 다음 과정을 따릅니다:
-
윈도우(window) 단위로 나눔:
- 각 윈도우의 크기를 로 설정합니다.
- 마지막 윈도우는 부족한 데이터를 으로 패딩(padding)하여 동일한 크기를 유지합니다.
- 결과적으로 는 여러 개의 윈도우 로 분할됩니다:
- 여기서 은 윈도우의 총 개수입니다.
-
윈도우별로 처리:
- 각 윈도우 은 Q-Former의 입력으로 들어가며, 텍스트 토큰 로 변환됩니다.
3. Q-Former의 역할
- 각 윈도우 은 Q-Former를 통해 개의 텍스트 토큰 로 변환됩니다.
- 변환 과정:
- : Q-Former 내부에서 사용되는 학습 가능한 쿼리(queries)입니다.
- Q-Former는 의 정보를 학습 가능한 쿼리 와 상호작용하여 텍스트 토큰 을 생성합니다.
4. 전체 과정의 결과
- 모든 윈도우에서 을 생성한 뒤, 최종 텍스트 시퀀스 는 다음과 같이 구성됩니다:
- 최종적으로 는 개의 텍스트 토큰을 포함합니다.
예시
-
: Whisper와 BEATs의 출력 특징 시퀀스
- 는 총 프레임으로 구성된 시퀀스라고 가정:
- 는 총 프레임으로 구성된 시퀀스라고 가정:
-
윈도우 크기 :
- 한 번에 개의 프레임씩 처리:
- 첫 번째 윈도우 :
- 두 번째 윈도우 :
- 세 번째 윈도우 :
- 네 번째 윈도우 : (패딩 포함)
- 한 번에 개의 프레임씩 처리:
-
Q-Former를 통한 변환:
- 각 윈도우를 Q-Former로 처리:
- 각 윈도우를 Q-Former로 처리:
-
최종 텍스트 시퀀스:
- 모든 윈도우의 결과를 결합:
- 최종 의 길이는 .
- 모든 윈도우의 결과를 결합:
정리
- Whisper와 BEATs의 출력(특징) 는 시퀀스 형태로 결합됩니다.
- 를 크기의 윈도우로 나눕니다.
- 각 윈도우 은 Q-Former를 통해 개의 텍스트 토큰 로 변환됩니다.
- 최종적으로 는 모든 윈도우의 텍스트 토큰을 결합한 시퀀스입니다.
🚀 Q-former/Whisper/BEATs 가 무엇인가?
Q-former
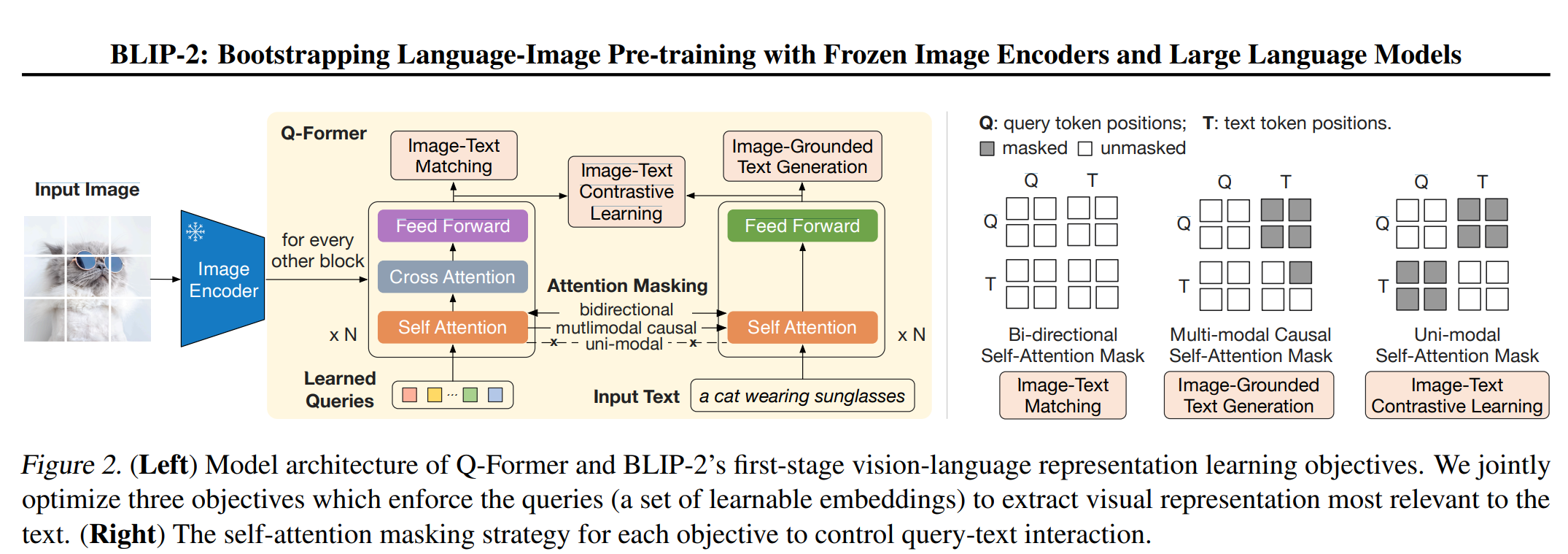
Q-Former가 작동하는 순서
-
이미지 입력 및 특징 추출
- 입력된 이미지는 사전 학습(frozen)된 이미지 인코더를 통해 먼저 처리된다.
- 이미지 인코더는 이미지로부터 시각적 특징(visual features)을 추출해내며, 이 특징들은 Q-Former에 전달될 준비가 된다.
-
쿼리(Queries) 초기화
- Q-Former는 학습 가능한 쿼리 임베딩(learned queries)를 여러 개 갖고 있다.
- 이 쿼리들은 이후 이미지 특징과 상호작용하며, 이미지와 텍스트 사이에서 중요한 정보를 추출하기 위한 핵심 역할을 수행한다.
-
Q-Former 블록 반복 구조
- Q-Former는 일반적으로 여러 개의 블록(레이어)으로 구성되어 있으며, 각 블록마다 다음 연산이 수행된다:
- Self-Attention(자체 어텐션): 쿼리들 간의 상호작용을 통해, 쿼리들이 서로의 정보(문맥)를 인지할 수 있게 한다.
- Cross-Attention(크로스 어텐션): 이미지 인코더가 추출한 이미지 특징과 쿼리들 간에 어텐션을 수행하여, 각 쿼리가 이미지의 중요한 부분을 집중해서 파악하도록 한다.
- Feed Forward(피드포워드): 어텐션 출력을 추가로 변환(비선형 변환 등)해 더 풍부한 임베딩을 형성한다.
- Q-Former는 일반적으로 여러 개의 블록(레이어)으로 구성되어 있으며, 각 블록마다 다음 연산이 수행된다:
-
어텐션 마스킹 방식(Attention Mask)
- Q-Former는 각기 다른 학습 목표에 맞추어 서로 다른 어텐션 마스킹 방식을 사용한다:
- Bi-directional Self-Attention Mask: 이미지-텍스트 매칭과 같은 양방향 이해가 필요한 경우 사용.
- Multi-modal Causal Self-Attention Mask: 이미지와 텍스트를 함께 보고 순차적으로 예측(생성)해야 하는 경우(이미지 기반 텍스트 생성 등).
- Uni-modal Self-Attention Mask: 이미지와 텍스트를 분리하여 대조 학습(contrastive learning)을 수행할 때.
- Q-Former는 각기 다른 학습 목표에 맞추어 서로 다른 어텐션 마스킹 방식을 사용한다:
-
최종 출력 및 다운스트림 활용
- 각 블록을 거치며 업데이트된 쿼리들은 최종적으로 이미지와 텍스트 간의 의미적 관계를 잘 반영하게 된다.
- 이렇게 얻어진 쿼리 임베딩 또는 Q-Former의 출력은 다음과 같은 다운스트림 작업에 활용된다:
- 이미지-텍스트 매칭(Image-Text Matching): 이미지와 텍스트가 서로 호응하는지 판별.
- 이미지-텍스트 대조 학습(Image-Text Contrastive Learning): 시각-언어 임베딩을 같은 공간에서 학습하여 유사도 기반 검색 등에 활용.
- 이미지 기반 텍스트 생성(Image-Grounded Text Generation): 이미지 내용을 설명하는 문장이나 캡션 등을 생성.
위 과정을 거쳐, Q-Former는 이미지와 텍스트 간의 시각-언어적 상호작용을 풍부하게 학습하게 되며, 이를 바탕으로 다양한 멀티모달(vision-language) 작업을 효과적으로 수행할 수 있게 된다.
Whisper & BEATs
| 요소 | Whisper | BEATs |
|---|---|---|
| 초점 | 음성 및 언어 처리 | 비음성 오디오 정보 처리 |
| 입력 데이터 | 음성 데이터 | 비음성 오디오 및 음악 |
| 주요 특징 | 텍스트 기반 음성 내용 학습 | 비언어적 의미 학습 |
| 적용 범위 | 음성 인식, 번역 | 음악 이해, 오디오 이벤트 분석 |
-> Salmonn은 multimodal 성능을 달성하기 위해 음성 및 비음성을 인코더 할 수 있는 모델이 필요했고, 그결과 위 두 모델을 썼다.
3.2 TRAINING METHOD
SALMONN의 3단계 크로스 모달 학습 방법
SALMONN에서 제안하는 3단계 크로스 모달 학습 방법을 설명합니다. 최근의 다양한 비주얼 LLM(예: Dai et al., 2023; Zhang et al., 2023b)과 유사하게, SALMONN은 사전 학습(Pre-training) 단계와 명령어 튜닝(Instruction Tuning) 단계를 거칩니다.
그러나 이와 별개로, Activation Tuning이라는 추가 단계를 도입하여, 명령어 튜닝 중 발생하는 특정 태스크(예: 음성 인식, 오디오 캡셔닝 등)에 대한 과적합(over-fitting) 문제를 완화합니다.
1. Pre-training Stage
목적
- LLM과 오디오 인코더(encoders)는 이미 사전 학습된 가중치를 갖고 있지만, 커넥션 모듈(connection module)과 어댑터(adaptor)는 무작위로 초기화된 상태입니다.
- 이 차이를 줄이기 위해, 대규모 음성 인식(speech recognition)과 오디오 캡셔닝(audio captioning) 데이터를 활용하여, 윈도우 단위 Q-Former(window-level Q-Former)와 LoRA를 사전 학습합니다.
이유
- 음성 인식과 오디오 캡셔닝은 둘 다 오디오 콘텐츠를 풍부하게 반영하며, 복잡한 추론보다는 핵심 청각 정보를 모델에 학습시키기에 적합합니다.
- 이를 통해 오디오-텍스트 정렬(alignment)을 고품질로 학습하고, 이후 단계에서 복잡한 태스크를 다룰 기반을 마련합니다.
2. Instruction Tuning Stage
개요
- NLP 분야(Wei et al., 2022a)나 비전-언어 분야(Dai et al., 2023)에서와 마찬가지로, SALMONN은 오디오-텍스트 명령어 튜닝(audio-text instruction tuning)을 수행합니다.
- 명령어 튜닝 시에는 지도(supervised) 학습 데이터를 사용:
- 음성 인식, 오디오 이벤트 인식(audio event), 음악 태스크 등 다양한 태스크로 구성.
- 중요도가 높은 태스크(예: 음성 인식, 오디오 캡셔닝) + 테스트에서 필요성이 높은 태스크(예: 중첩 음성 인식, 음소 인식, 음악 캡셔닝 등)를 선정.
명령어 튜닝 시 문제(태스크 과적합)
- 명령어 튜닝 단계에서 학습한 태스크에는 좋은 성능을 내지만, 학습하지 않은 새로운 크로스 모달 태스크에 대해서는 성능이 떨어집니다.
- 모델이 특정(학습된) 태스크에만 집착하여, 새로운 지시문(prompt)에 대해서도 이미 학습된 태스크처럼 반응하는 현상이 발생합니다.
- 예: 실제 지시문은 "오디오 질문 응답"인데, 모델이 "음성 인식" 결과만 내놓으려 함.
3. Task Over-fitting (태스크 과적합)에 대한 이론적 분석
논문에서는 이러한 현상(태스크 과적합)을 "Task Over-fitting"이라 부르며, 다음 두 가지 주요 원인을 제시합니다:
-
간단한 명령어와 단순한 응답
- 텍스트 전용 LLM 학습과 달리, 오디오-텍스트 명령어 튜닝에서는 비교적 간단한 지시문과 제한적인 응답 패턴을 학습합니다.
- 예: 음성 인식(ASR) 태스크는 "짧고 결정적인(deterministic) 출력"을 요구하기 때문에, 모델이 이 형태로 과도하게 편향됩니다.
-
음성 인식 및 오디오 캡셔닝 태스크의 결정론적 성격
- 음성 인식과 오디오 캡셔닝은 정답이 어느 정도 고정된(deterministic) 특성을 가집니다.
- 반면, 오디오 질문 응답(답변이 다양할 수 있음) 같은 태스크는 더 개방적(open-ended)이지만, 학습 데이터가 부족하면 모델이 편향을 보입니다.
수식으로 보는 문제
텍스트 입력 와 오디오 입력 가 주어졌을 때, 모델이 생성해야 할 응답 텍스트 시퀀스 는 다음을 최대화하도록 학습됩니다:
베이즈 정리를 사용하면:
- 문제: SALMONN 훈련 시 제한적인 응답(예: 음성 인식 결과)을 많이 보게 되면, 모델의 내재적 조건부 언어 모델 가 ASR(Automatic Speech Recognition) 같은 짧고 단순한 답변에 과도하게 치우침(bias) → 새로운 지시문 이 들어올 때, 값이 작아져서 다양한 응답을 제대로 생성하지 못합니다.
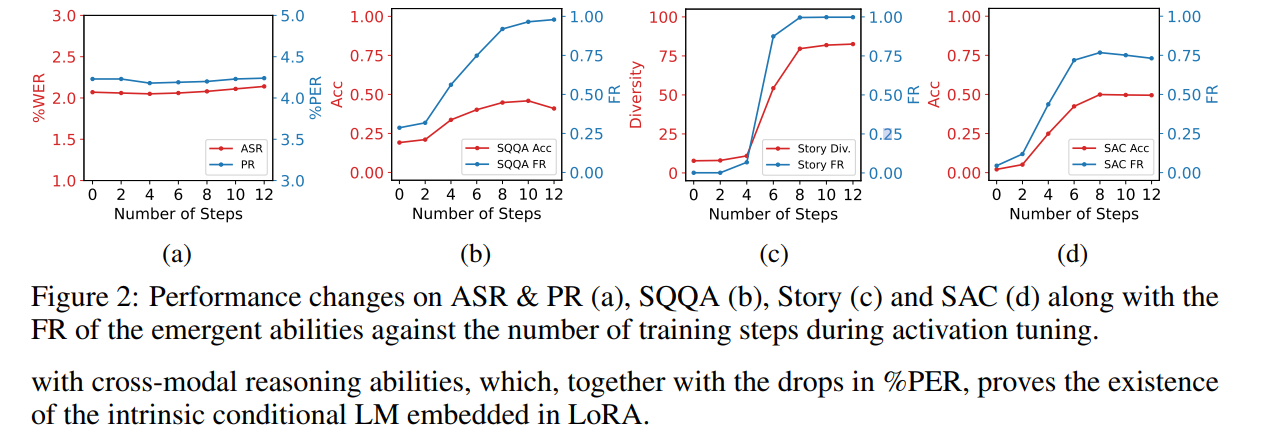
4. Activation Tuning Stage
개념
- 태스크 과적합을 완화하기 위해, Activation Tuning 단계를 추가로 수행합니다.
- 핵심 아이디어: 모델이 보다 길고 다양한 응답을 학습하도록 내재적 조건부 언어 모델 를 정규화(regularize)하는 것입니다.
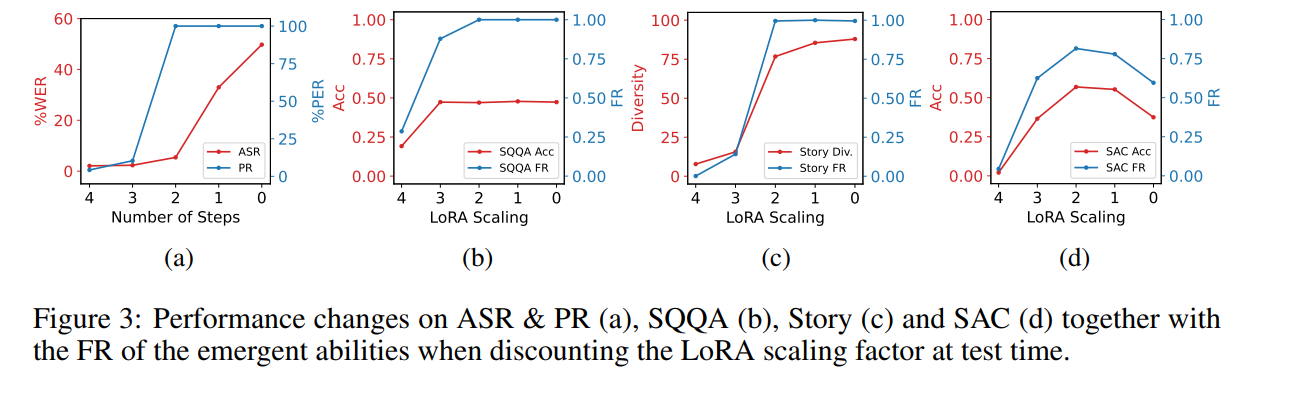
방법 1: LoRA 스케일링 인자 축소
- LoRA 스케일링 인자(LoRA scaling factor)를 낮춰서, 모델이 오디오-텍스트 데이터에서 좀 더 다양한 응답(예: Q&A, 스토리텔링)으로 활성화되도록 유도합니다.
- 이 방식은 실제로 모델이 장문·다양한 답변을 생성하게 만들지만, 이미 학습된 ASR 같은 태스크의 성능을 떨어뜨리는 문제가 발생합니다.
방법 2: Activation Tuning(세 번째 파인튜닝 단계)
- 할인된 LoRA 스케일링 인자로 생성한 모델 응답을 다시 학습 데이터로 사용(자기지도 학습, few-shot 등).
- 결과적으로, 이미 학습된 태스크 성능을 유지하면서, 새로운 지시문에 대해 길고 창의적인 응답을 할 수 있게 모델을 튜닝합니다.
- 실험(섹션 5.4)에서, 적은 양의 데이터(few-shot)만으로도 효과적인 크로스 모달 능력을 되살릴 수 있음이 확인되었습니다.
요약
-
Pre-training:
- 대규모 음성 인식 및 오디오 캡셔닝 데이터로 윈도우 단위 Q-Former와 LoRA 사전 학습.
-
Instruction Tuning:
- 음성 인식, 오디오 이벤트, 음악 관련 태스크 등 오디오-텍스트 명령어 튜닝 수행.
- 하지만 태스크 과적합 문제로 인해, 새로운 유형의 질문이나 지시문에 제대로 대응하지 못하는 한계가 드러남.
-
Activation Tuning:
- LoRA 스케일링 인자를 낮춘 상태로 모델이 생성한 답변을 재학습(추가 파인튜닝)하는 기법.
- 기존 태스크 성능과 새로운 태스크에 대한 적응력을 동시에 확보.
위 방식으로 SALMONN은 오디오-텍스트 간의 풍부한 정렬과 다양한 태스크 수행 능력을 갖추도록 훈련될 수 있습니다.
4. EXPERIMENTAL RESULTS
결과는 당연히 우수한 성능을 강조하고 있습니다. 이는 대부분의 새로운 논문이 공통적으로 주장하는 부분이므로 간략히 살펴보고 넘어가겠습니다.
| 평가지표 | 약자 | 정의 | 설명 |
|---|---|---|---|
| 단어 오류율 | %WER (Word Error Rate) | 음성 인식 태스크(ASR(Automatic Speech Recognition))에서 단어 오류율을 측정 | 값이 낮을수록 성능이 좋음 |
| 음소 오류율 | %PER (Phone Error Rate) | 음소 인식 태스크(PR(Phone Recognition))에서 음소 오류율을 측정 | 값이 낮을수록 성능이 좋음 |
| 정확도 | ACC (Accuracy) | 태스크의 정확도를 측정 (예: SQQA, SAC) | 값이 높을수록 성능이 좋음 |
| 세밀한 추론 능력 | FR (Fine-grained Reasoning) | 복잡한 태스크에서 세밀한 추론 능력을 측정 | 값이 높을수록 추론 능력이 뛰어남 |
| 다양성 | Diversity (Diversity) | 생성된 결과(예: 스토리 생성)의 다양성을 측정 | 값이 높을수록 다양한 응답을 생성할 수 있음 |
6. CONCLUSION
This work proposes SALMONN, a speech audio language music open neural network that can be regarded as a step towards generic hearing abilities for LLMs.
7. 참고사항
위 3가지 논문을 짬뽕 + LoRA 사용해서 Audio generalation 모델 SALMONN을 만든 것입니다..!
