1. Batch Serving
1.1 Batch Serving의 구현
- 일정 기간 데이터 수집 후 일괄 학습 및 결과 제공하는 특성이 있음
- 대량의 데이터 처리할 때 효율적
ex) 모델을 주기적으로 학습시킬때
Batch Serving은 예측 코드를 주기적으로 실행해서 예측 결과를 제공
Job Scheduler는 Apache Airflow를 주로 사용
학습과 예측을 별도 설정을 통해 수행
- 학습 : 1주일에 1번
- 예측 : 10분, 30분, 1시간에 1번씩
Jupyter Notebook, Lab 있는 코드를 스크립트로 바꿀 때 편함
-> 절차형으로 작성한 코드를 정리한 후, 주기적으로 실행!
1.2 Batch Serving 예시
스포티파이의 예측 알고리즘 - Discover Weekly
수요 예측 (재고 및 입고 최적화를 위해 매일 매장별 제품 수요 예측)
- sklearn에서 pandas 데이터를 가지고 일괄로 예측
- 데이터베이스나 데이터 웨어하우스에 존재하는 데이터 추출(SQL 쿼리) 후 모든 데이터 일괄로 예측
이미지 예측
- AWS S3 (저장소) 등에 저장된 이미지를 사용해 예측
- 데이터베이스엔 이미지를 바로 저장하지 않고, 이미지의 저장 위치를 기록(s3 등)
- 새로 추가된 이미지를 확인하고 예측(SQL 쿼리 사용)
자연어 예측
- 데이터베이스나 데이터 웨어하우스에 저장한 자연어 데이터를 활용해서 사용
- 새로 추가된 자연어 데이터를 확인하고 예측(SQL 쿼리 사용)
2. Apache Airflow 소개
2.1 Batch Processing
소프트웨어 프로그램을 자동으로 실행하는 방법. 예약된 시간에 자동으로 실행
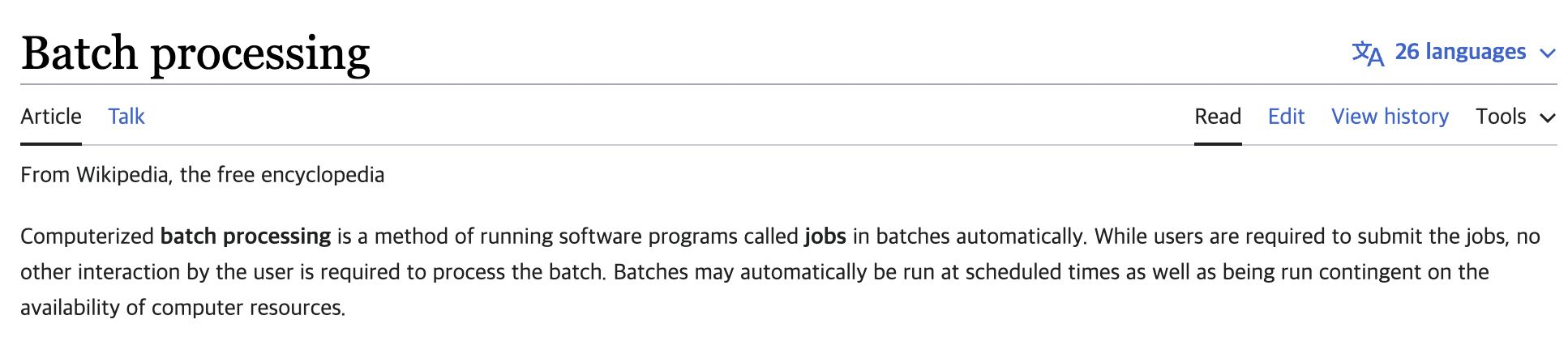
Batch Processing과 Batch Serving의 차이
Batch Processing : 일정 기간 동안 일괄적으로 작업을 수행
Batch Serving : 일정 기간동안 일괄적으로 머신러닝 예측 작업을 수행
Batch Processing이 더 큰 개념이며, Batch로 진행하는 작업에 Airflow를 사용할 수 있음
2.2 Airflow 등장 전 : Crontab
대표적인 구축 방법 : Linux Crontab 활용
cron은 그리스어에서 유래된 것으로 시간을 뜻함.
- (서버에서)
crontab -e입력 - 실행된 에디터에서 0 * * *
predict.py입력(0 * * * 은 매 시 0분을 의미) - OS에 의해 매 시 0분에 predict.py가 실행
- Linux는 일반적인 서버 환경이고, Crontab도 기본적으로 설치되어 있기 때문에 매우 간편
- 간단하게 Batch Processing을 할 때 Crontab도 가능한 선택
Cron 표현식 활용
- Batch Processing의 스케줄링을 정의한 표현식
- 이 표현식은 다른 Batch Processing 도구에서도 자주 사용됨
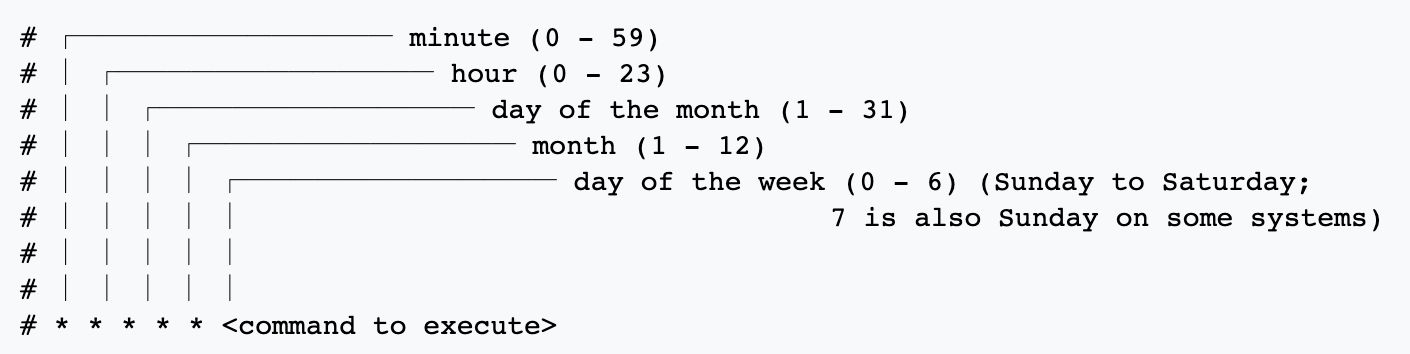
Cron 표현식 예시

Cron 표현식 사이트
http://www.cronmaker.com
https://crontab.guru/
Linux Crontab의 문제 존재
- 재실행 및 알림
- 파일을 실행하다 오류가 발생한 경우, Crontab이 별도의 처리를 하지 않음
예) 매주 일요일 07:00에 predict.py를 실행하다가 에러가 발생한 경우, 알림을 별도로 받지 못함 - 실패할 경우, 자동으로 몇 번 더 재실행(Retry)하고, 그래도 실패하면 실패했다는 알림을 받아야 대응할 수 있음
- 과거 실행 이력 및 실행 로그를 보기 어려움
- 여러 파일을 실행하거나, 복잡한 파이프라인을 만들기 힘듦
Crontab은 간단히 사용할 수는 있지만, 실패 시 재실행, 실행 로그 확인, 알림 등의 기능은 제공하지 않음
=> 좀 더 정교한 스케줄링 및 워크플로우 도구가 필요함
2.3 Airflow 소개
Linux Crontab 문제를 해결하기 위해 다양한 스케줄링/워크플로우 전용 도구의 등장

Airflow 등장 후, 스케줄링 및 워크플로우 도구의 표준
- 스케줄링 도구로 무거울 수 있지만, 거의 모든 기능을 제공하고, 확장성이 좋아 일반적으로 스케줄링과 파이프라인 작성 도구로 많이 사용
Airflow를 많이 사용하는 이유
- 워크플로우 관리 도구
- 코드로 작성된 데이터 파이프라인 흐름을 스케줄링하고 모니터링하는 목적
- 데이터 처리 파이프라인을 효율적으로 관리하여 시간과 자원을 절약하도록 함
Airflow 주요 기능
파이썬을 사용해 스케줄링 및 파이프라인 작성
DAG는 Directed Acyclic Graph의 약자
- Directed: 작업 간의 관계(Edge)가 방향성을 가집니다. 즉, 어떤 작업이 먼저 실행되고, 이후 어떤 작업이 실행되어야 하는지 나타냅니다.
- Acyclic: 순환(Cycle)이 없는 그래프입니다. 즉, 작업이 다시 자신으로 돌아오는 순환이 존재하지 않음을 보장합니다.
DAG의 기능
DAG는 Apache Airflow에서 워크플로우를 정의하는 핵심 구조입니다.
DAG는 작업(Task)들 간의 실행 순서를 정의하며, 이러한 작업은 각 노드(Node)로 표현됩니다.
워크플로우 전체를 표현하고 스케줄링 및 실행을 자동으로 관리합니다.
스케줄링 및 파이프라인 목록을 볼 수 있는 웹 UI 제공
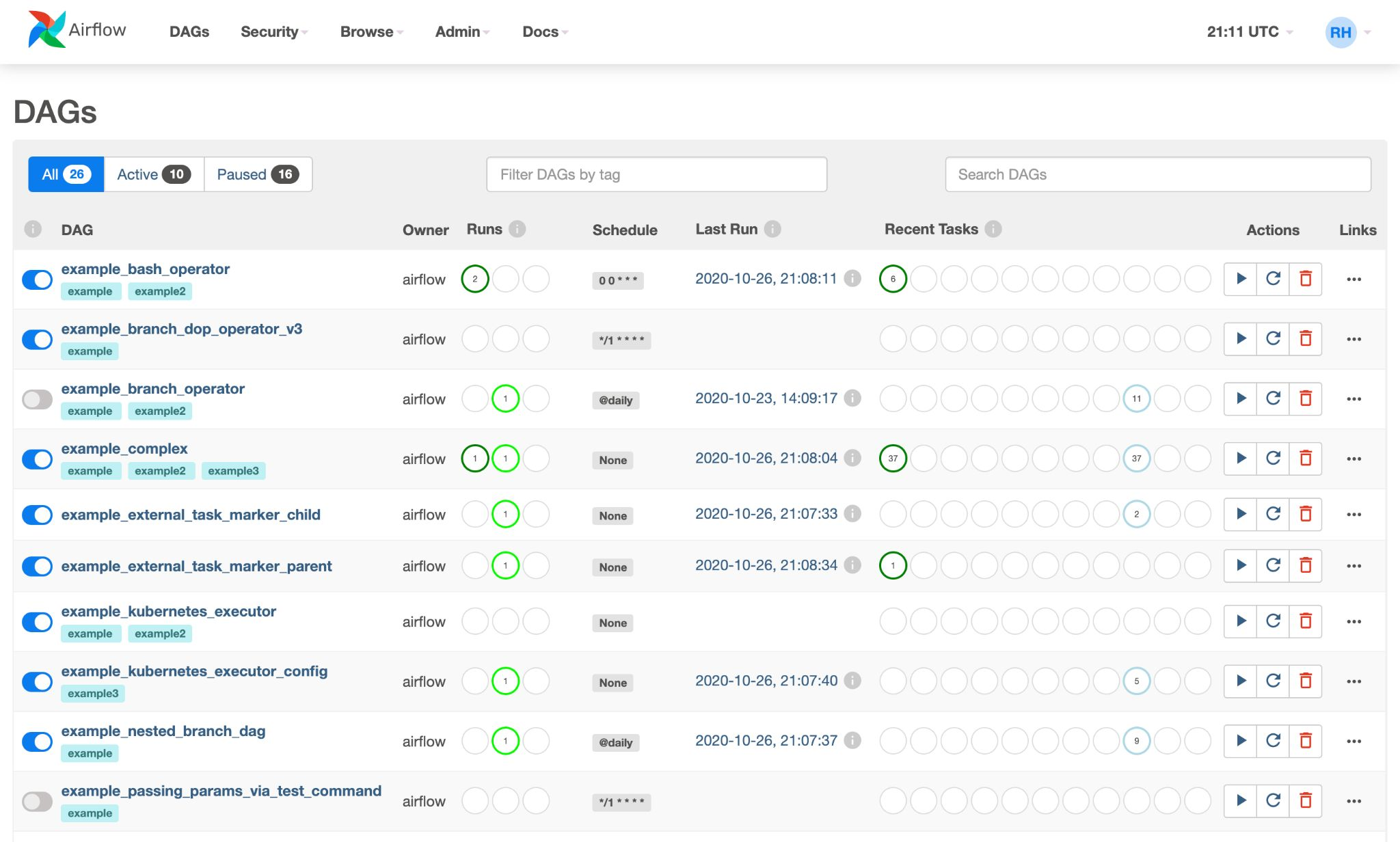
스케줄링 및 파이프라인 목록을 볼 수 있는 웹 UI 제공
특정 조건에 따라 작업을 분기할 수도 있음(Branch 사용)
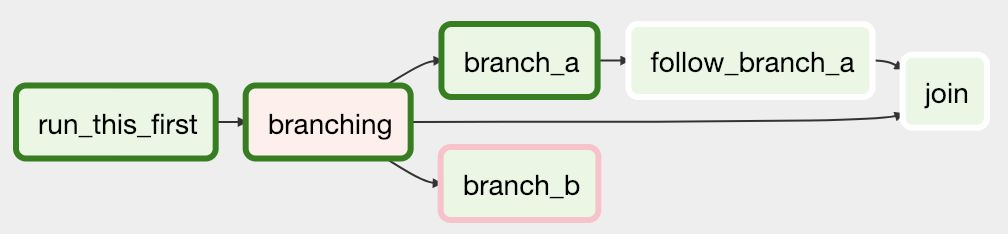
Airflow 핵심개념
1) DAGs (Directed Acyclic Graphs)
- Airflow에서 작업을 정의하는 방법, 작업의 흐름과 순서 정의
2) Operator
- Airflow의 작업 유형을 나타내는 클래스
- BashOperator, PythonOperator, SQLOperator 등 다양한 Operator 존재
3) Scheduler
- Airflow의 핵심 구성 요소 중 하나. DAGs를 보며 현재 실행해야 하는지 스케줄을 확인
- DAGs의 실행을 관리하고 스케줄링
4) Executor
- 작업이 실행되는 환경
- LocalExecutor, CeleryExecutor 등 다양한 Executor가 존재
기본아키텍처
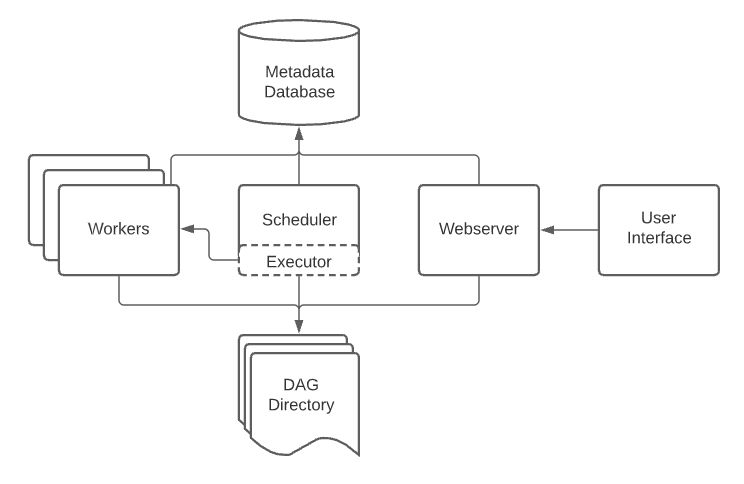
DAG Directory
DAG 파일들을 저장
- 기본 경로는
$AIRFLOW_HOME/dags - DAG_FOLDER 라고도 부르며, 이 폴더 내부에서 폴더 구조를 어떻게 두어도 상관없음
- Scheduler에 의해
.py파일은 모두 탐색되고 DAG이 파싱
Operator
Batch Scheduling을 위한 DAG 생성
- Airflow에서는 스케줄링할 작업을 DAG이라고 부름
- DAG은 Directed Acyclic Graph의 약자로, Airflow에 한정된 개념이 아닌 소프트웨어
자료구조에서 일반적으로 다루는 개념 - DAG은 이름 그대로, 순환하지 않는 방향이 존재하는 그래프를 의미

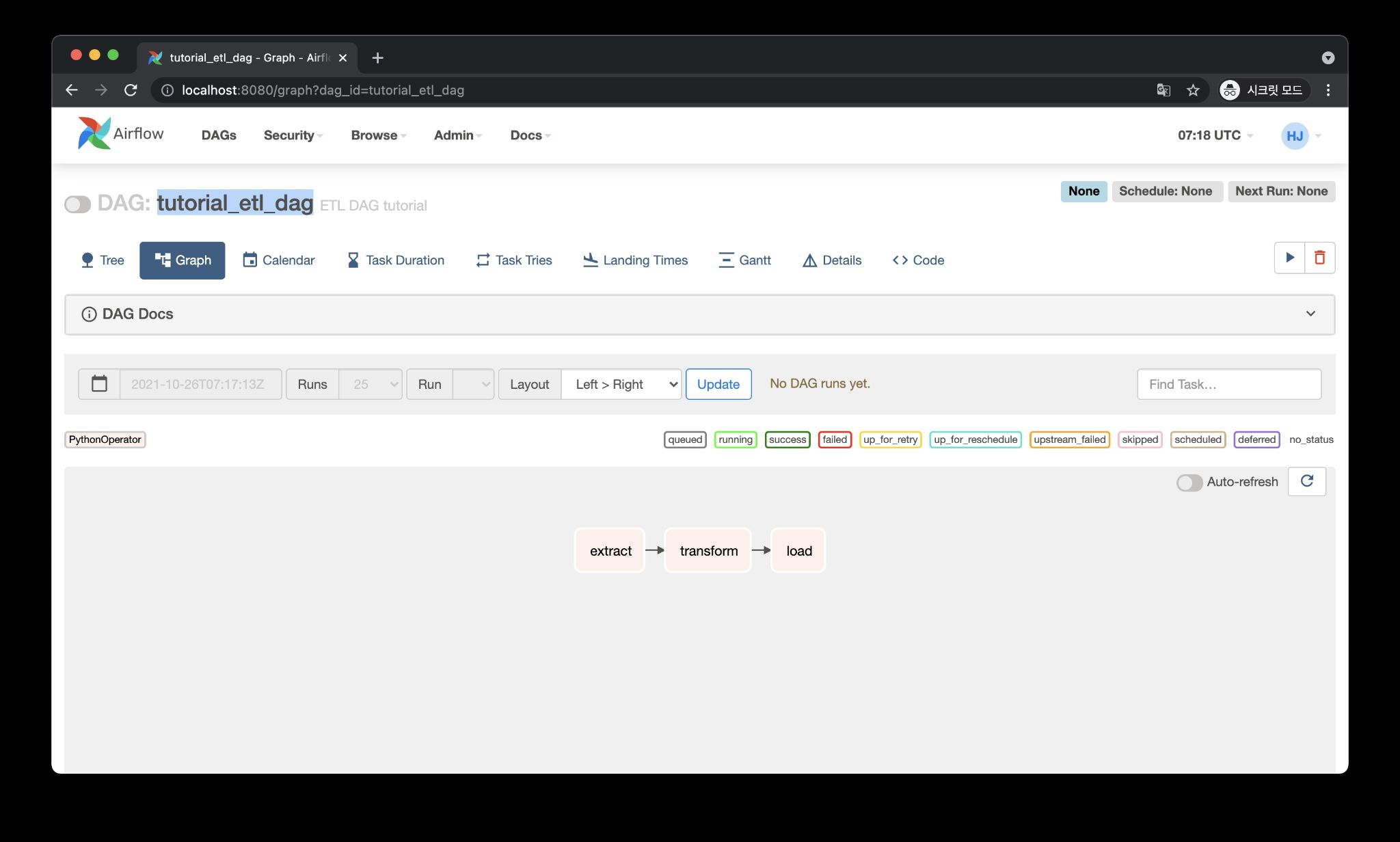
DAG 1개 : 1개의 파이프라인
Task : DAG 내에서 실행할 작업
=>하나의 DAG에 여러 Task의 조합으로 구성. task들의 묶음이 DAG이다.
ex1) tutorial_etl_dag라는 DAG은 3가지 Task로 구성
tutorial_etl_dag라는 DAG을 실행하면 이 3가지 Task(extract,transform
,load)을 순차적으로 실행
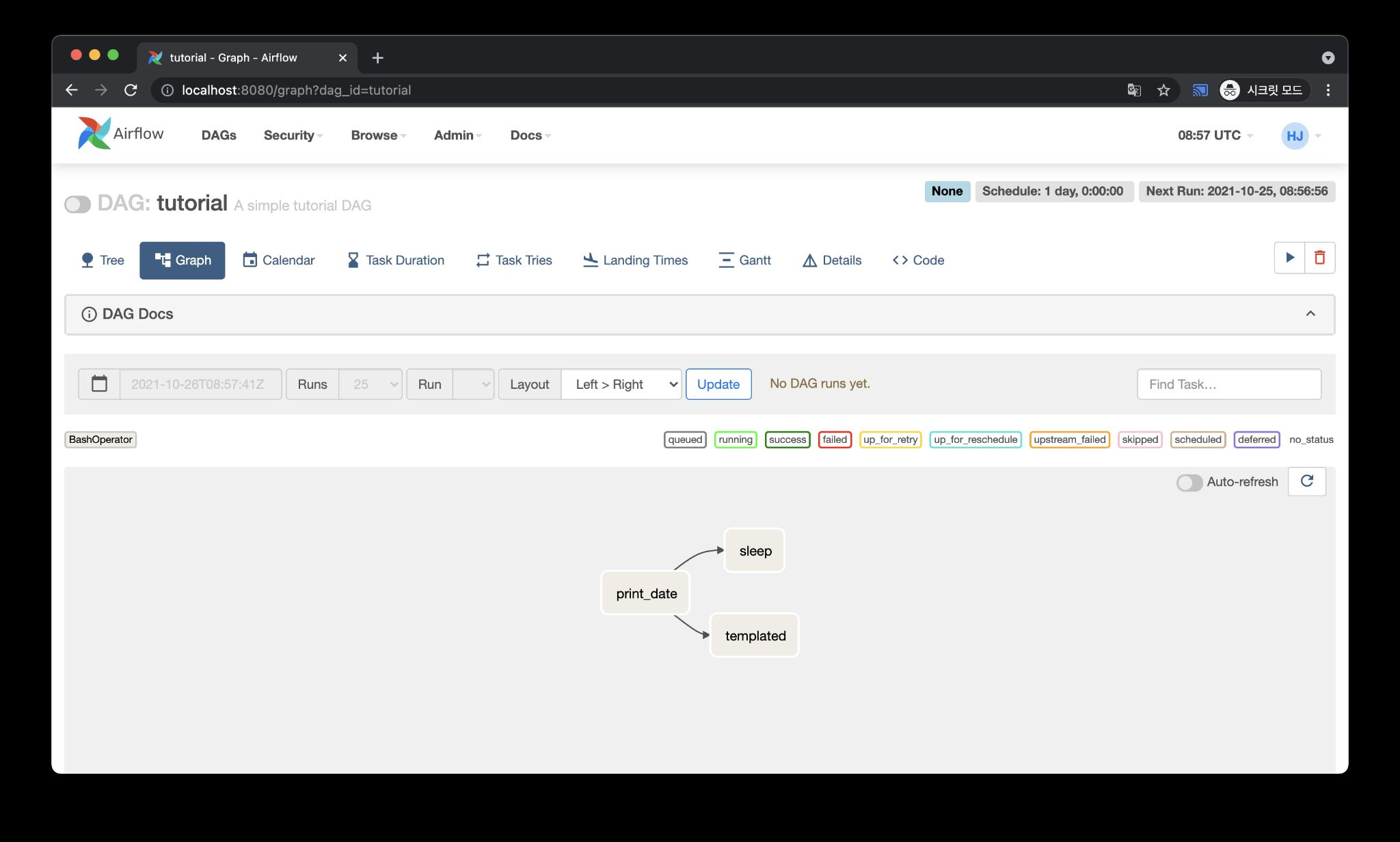
ex2) 병렬적으로 실행
3. Apache Airflow 실습
Apache는 apache재단에서 만들었기 때문에 앞에 apache라고 붙고 '강인함'이라는 인디언부족에서 유래함.
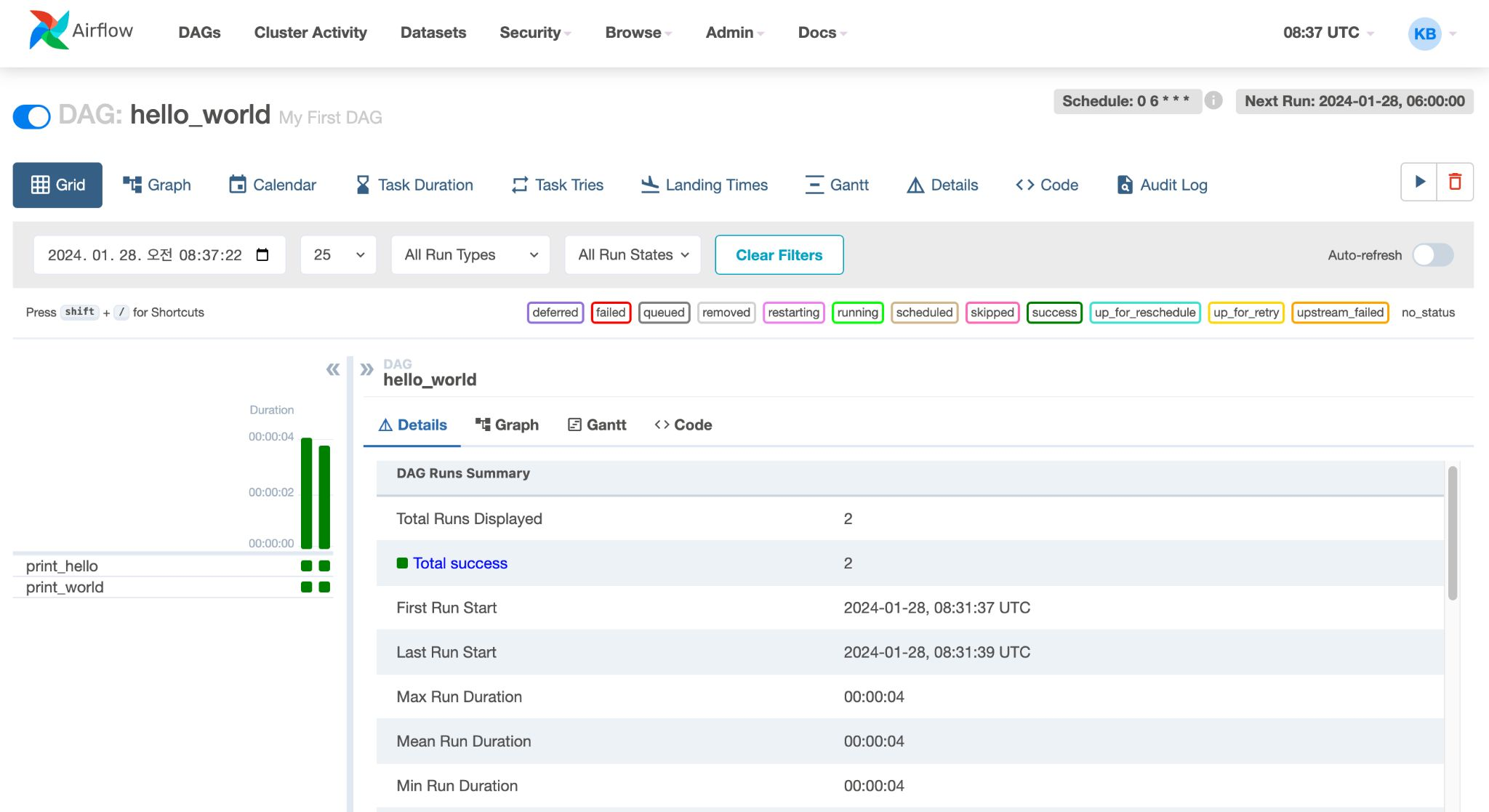
- print_date Task 이후 sleep, templated Task 동시 실행
3.1 Airflow 설치
가상환경설치
python -m venv .venv
source .venv/bin/activateairflow 설치
# pip3 설치된 pip을 최신 버전으로 업그레이드
pip3 install pip --upgrade
# Airflow 설치할 버전을 환경 변수로 지정
AIRFLOW_VERSION=2.6.3
# 현재 설치된 Python 버전을 확인하고, 주 버전과 부 버전만 추출하여 환경 변수로 저장
# 파이썬 python 3.10.2 -> 3.10.2 -> 3.10 으로 추출하는 과정.
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
# Apache Airflow 설치 시 사용할 제약 조건(constraint) 파일의 URL 설정
# 제약 조건 파일은 특정 버전의 Python과 Airflow에 맞는 종속성을 명시
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# Apache Airflow를 지정한 버전으로 설치하며, 제약 조건 파일을 참조하여 올바른 종속성을 설치
pip3 install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"Airflow에서 사용할 DB 초기화
export AIRFLOW_HOME=`pwd`
echo $AIRFLOW_HOME
airflow db initDB를 초기화하면 기본 파일이 생성
airflow.cfg : Airflow 설정 파일
airflow.cfg 파일 : Airflow 각종 설정이 존재하며, load_examples = True를 주면 예제 파일이 포함됨
airflow.db : Airflow DB(여기선 SQLite 사용)
Airflow에서 사용할 어드민 계정 생성
airflow users create \
--username admin \
--password '0123' \
--firstname lee \
--lastname jaegun \
--role Admin \
--email leejken530@naver.com 3.2 Airflow Webserver, Scheduler 실행
Airflow Webserver 실행
airflow webserver --port 8080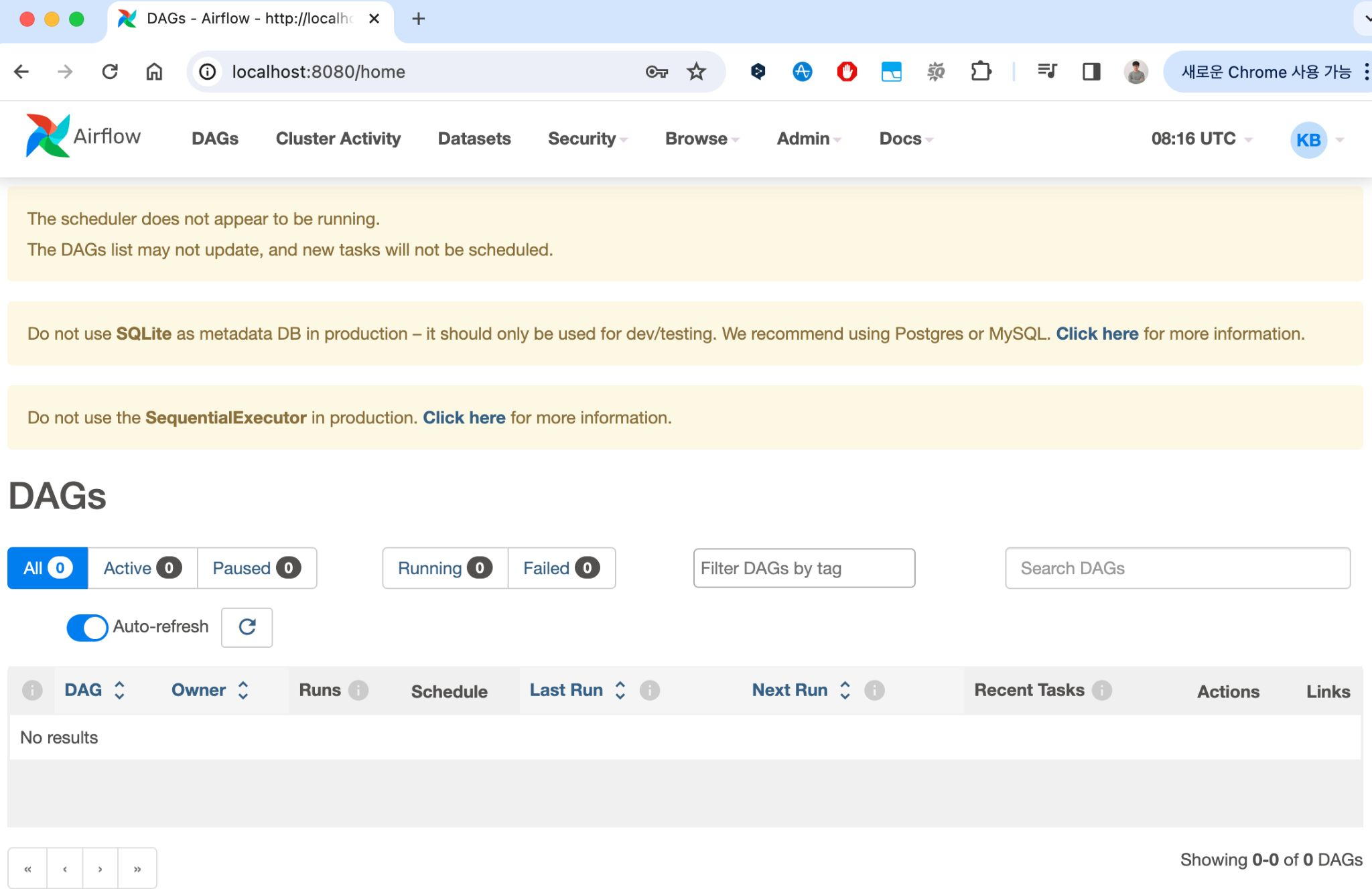
별도의 터미널 창을 띄워 다음처럼 Airflow Scheduler를 실행
(Webserver를 실행한 상황에서 Scheduler를 또 실행)
export 항상 해주고 실행
#!/bin/bash
# 1. 프로젝트 디렉토리로 이동
cd boostcamp
# 2. 가상 환경 활성화
source .venv/bin/activate
# 3. Airflow 작업 디렉토리 설정
export AIRFLOW_HOME=$(pwd)
# 4. Airflow 스케줄러 실행
airflow schedulerAirflow Webserver, Scheduler를 실행할 때 Port의 이슈가 있는 경우
[2024-01-29 12:01:09 +0900][66714] [ERROR] Connection in use: ('::', 8793)
8793 port에 연결할 수 없음 = port의 process id를 찾아서 Kill
kill $(lsof -t -i:8793
환경 설정 요약
- Airflow 설치: pip install "apache-airflow==2.6.3" --constraint
"https://raw.githubusercontent.com/apache/airflow/constraints-2.6.3/constraints-3.9.txt" - Airflow 기본 디렉토리 설정
환경변수 AIRFLOW_HOME에 사용할 기본 디렉토리 경로 설정
export AIRFLOW_HOME=pwd - Airflow DB 초기화
Airflow에서 사용할 DB를 초기화
airflow db init - Airflow 어드민 계정 생성: airflow user create
- Airflow 웹서버 실행: airflow webserver –-port 8080
- Airflow 스케줄러 실행: airflow scheduler
3.3 Airflow DAG 작성
[실습] Airflow Hello World!
새 터미널을 띄우고 AIRFLOW_HOME에서 DAG을 저장할 디렉토리 생성(이름은 무조건 dags)
mkdir dagsdags 폴더안데 hello_world.py생성
Airflow DAG 파일은 크게 3가지 파트로 나뉨
- DAG 정의
- Task 정의
Task에서 사용할 함수가 있다면 정의 (PythonOperator) - Task 순서 정의(연결)
from datetime import timedelta
from airflow import DAG
from airflow.utils.dates import days_ago
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
# PythonOperator에서 호출할 함수 정의
def print_world() -> None:
print("world")
# with 구문으로 DAG 정의 시작
with DAG(
dag_id="hello_world", # DAG의 식별자용 아이디
description="My First DAG", # DAG 설명
start_date=days_ago(2), # DAG 정의 기준 2일 전부터 시작
schedule_interval="0 6 * * *", # 매일 06:00에 실행
tags=["my_dags"], # 태그 설정
) as dag:
# 테스크 1: bash 커맨드로 echo Hello 실행
t1 = BashOperator(
task_id="print_hello", # 테스크 ID
bash_command="echo Hello", # 실행할 bash 명령어
owner="heumsi", # 테스크 오너 (담당자)
retries=3, # 실패 시 3번 재시도
retry_delay=timedelta(minutes=5), # 재시도 간격은 5분
)
# 테스크 2: Python 함수 print_world 실행
t2 = PythonOperator(
task_id="print_world", # 테스크 ID
python_callable=print_world, # 실행할 Python 함수
depends_on_past=True, # 이전 테스크의 성공 여부에 따라 실행
owner="heumsi", # 테스크 오너
retries=3, # 실패 시 3번 재시도
retry_delay=timedelta(minutes=5), # 재시도 간격은 5분
)
# 테스크 순서 정의: t1 실행 후 t2 실행
t1 >> t2
실무에서 Airflow를 사용할 때 중요한 인자
catchup
- 과거에 지나간 일자의 DAG을 실행할지를 결정하는 옵션(따라잡다)
True : DAG에서 정의한 start_date부터 현재까지 미실행된 모든 스케줄에 대해 DAG을 실행-> 과거 데이터를 처리할 필요 있을 때 유용
False : DAG에서 정의한 start_date와 상관없이 앞으로 실행될 DAG을 실행
depends_on_past
- 특정 Task가 이전 DAG 실행 결과에 의존할지 여부 결정
- 이전 Task와 상관없이 작업을 수행하고 싶은지 고민
- 하루 단위의 작업들이 의존성이 있다면 True를 주고 순차적으로 실행
True : 이전 DAG이 성공으로 완료되어야 이후의 DAG이 실행
False : 이전 DAG의 성공 여부 상관없이 스케줄이 되면 DAG이 실행
-> Executor에 따라 여러가지 작업을 한번에 실행할 수도 있음
hello_world.py을 저장한 후, 웹 UI 확인해 보면 DAG 생성됨
예제 DAG 파일도 보임
Filter DAGs by tag -> my_dags를 검색
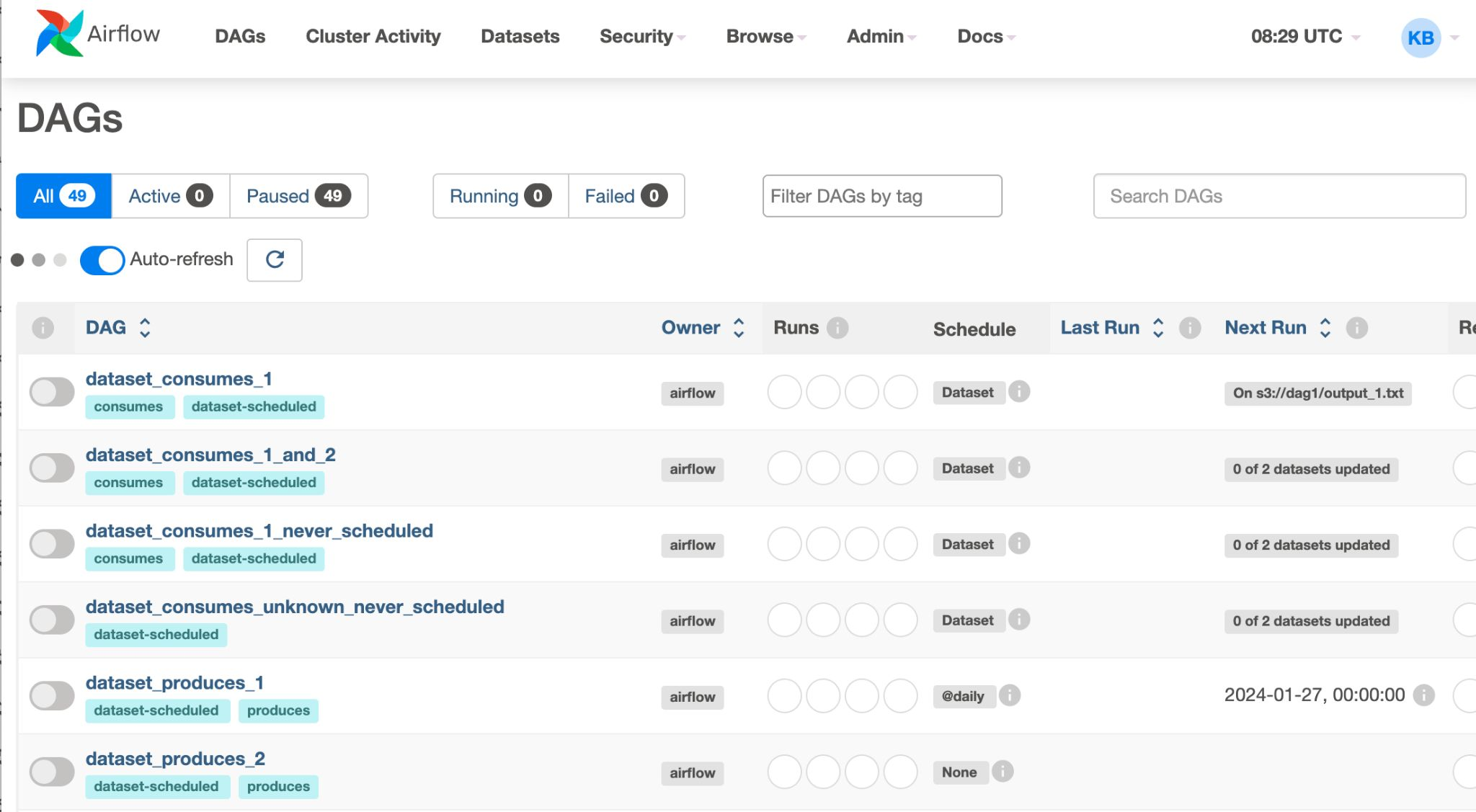
토글을 클릭해서 DAG 상태를 ON으로 만들면 우측에 연두색 불이 들어오기 시작(찰나의 시간)
이제 DAG의 이름을 클릭

3.4 Airflow의 다양한 Operator
Operator란?
Airflow에서는 다양한 Operator를 제공. 이 중 자주 사용하는 Operator를 소개
Airflow Operator는 Airflow로 워크플로우를 구성할 때 "한 개의 실제 실행 단위를 정의하는 핵심 요소"

PythonOperator

BashOperator
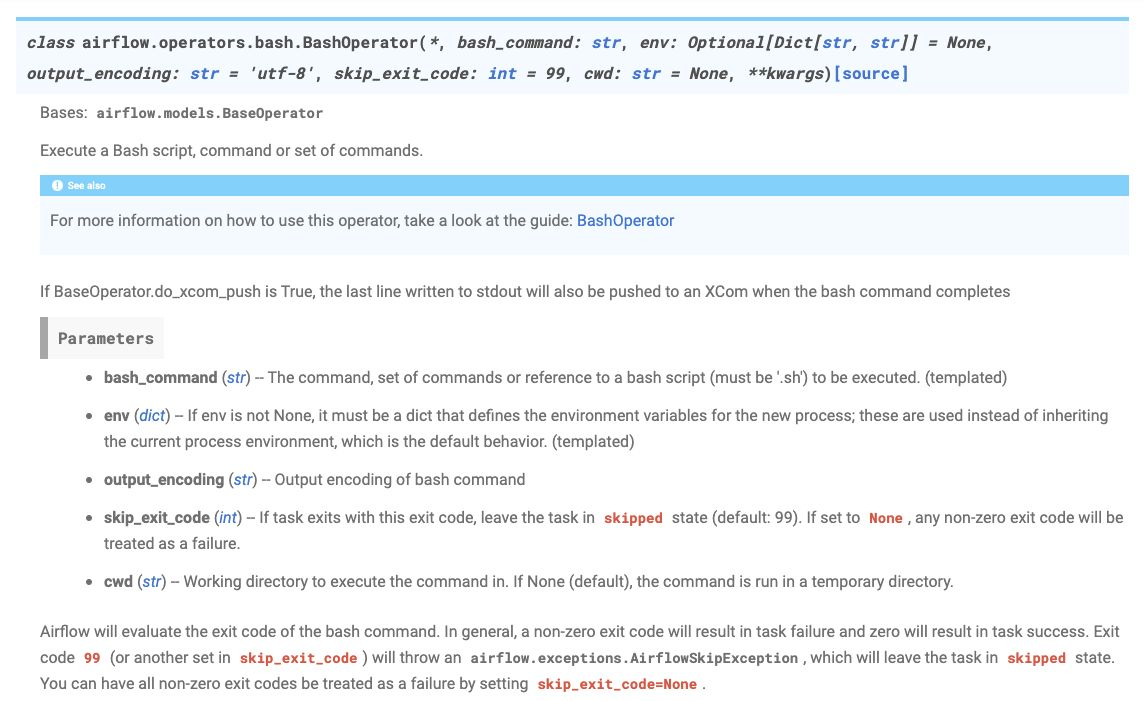
DummyOperator
작업 B,C,D 모두 Success 하면 F실행.
-> 이처럼 E는 사실상 아무런 작업을 하지않고, 작업을 모아두는 역할을 함.
Simple HttpOperator
특정 호스트로 HTTP 요청을 보내고 Response를 반환
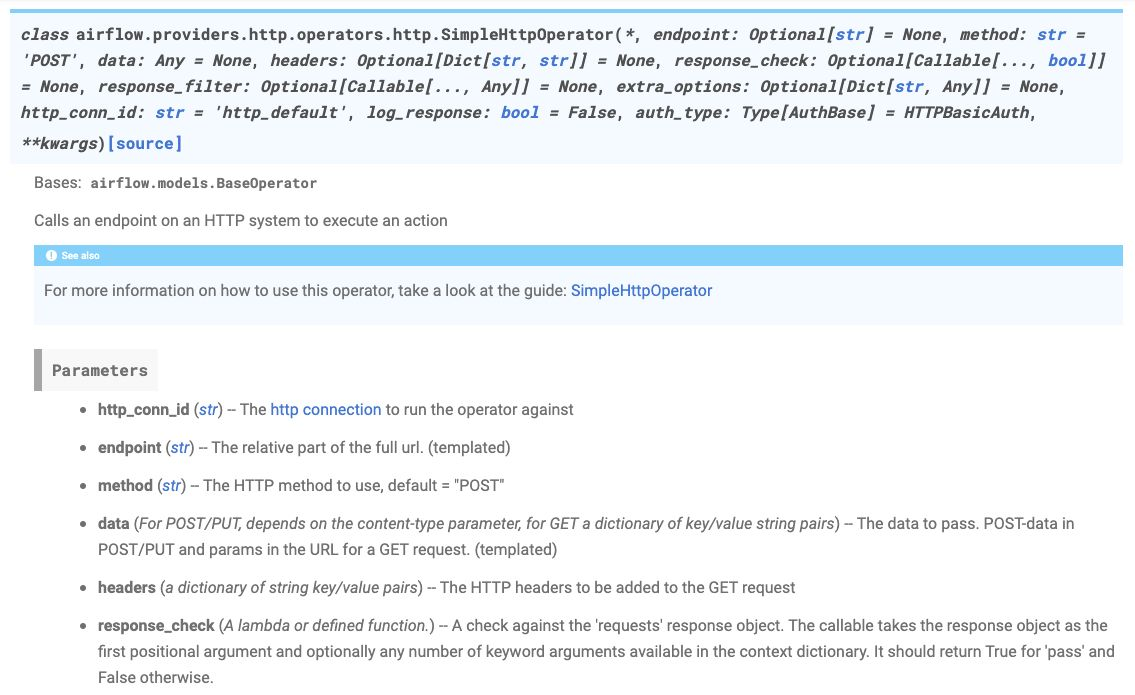
BranchPythonOperator
- 특정 조건에 따라 실행을 제어하는 Operator
- 특정 상황엔 A 작업, 없으면 Pass
Operator 외
- Variable : Airflow Console에서 변수(Variable)를 저장해 Airflow DAG에서 활용
- Connection & Hooks : 연결하기 위한 설정(MySQL, GCP 등)
- Sensor : 외부 이벤트를 기다리며 특정 조건이 만족하면 실행
- XComs : Task 끼리 결과를 주고받은 싶은 경우 사용
- Jinja Template : 파이썬의 템플릿 문법. FastAPI에서도 사용
3.5 Task가 실패할 때 Slack 메시지 전송하기
Airflow Slack Provider 설치
pip3 install 'apache-airflow-providers-slack[http]'==8.6.0
(1) Slack API Key 발급 : Slack API Apps에서 Create APP 클릭
From scratch -> App Name 지정하고 설치할 Slack Workspace 지정
(2) 생성된 URL 저장 (https://hooks.slack.com/services/T*****/B*****/*********)
(3) Webserver 통해 [Admin] - [Connections] - [Add a new record] 경로로 Connection 생성
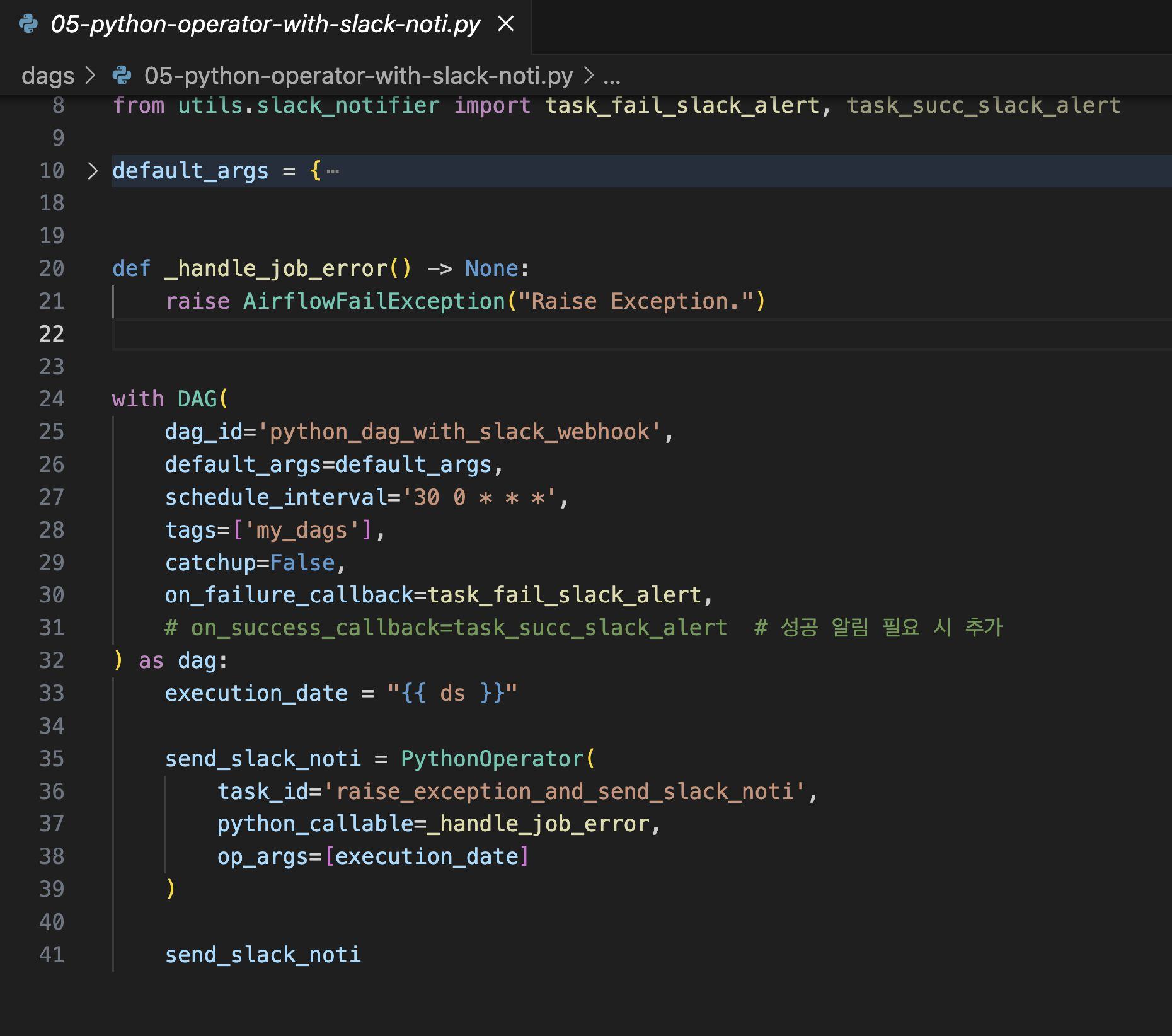
(4) Task가 실패할 때 알림 코드 작성
dags/utils 폴더 생성 후, __init__.py, slack_notifier.py 생성
utils 폴더 안에서 작성한 파일을 import해서 사용할 수 있음
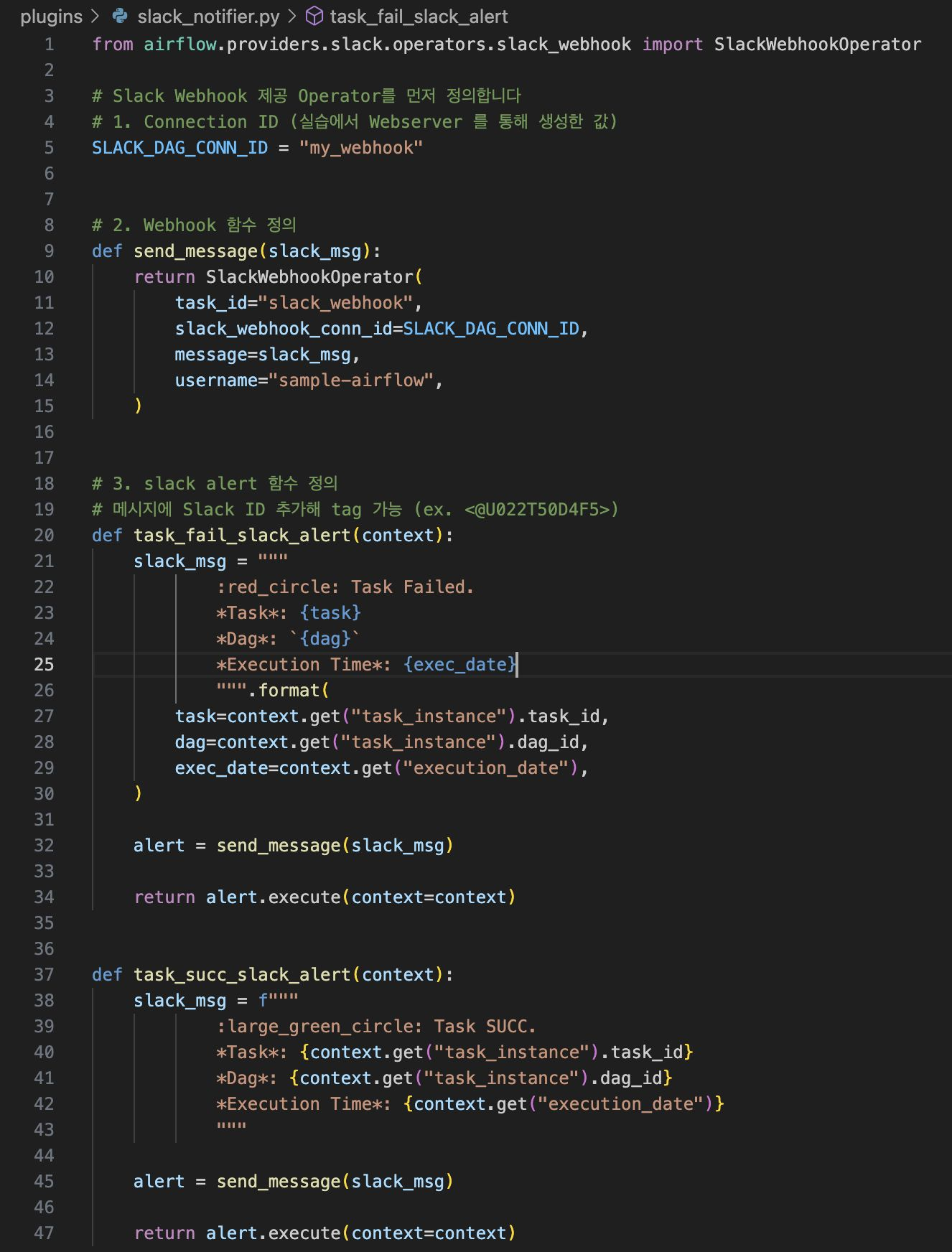
(5) DAG 코드 작성 : DAG 코드
4. Airflow 아키텍처 및 활용
전체적인 흐름
4.1 Airflow 아키텍처
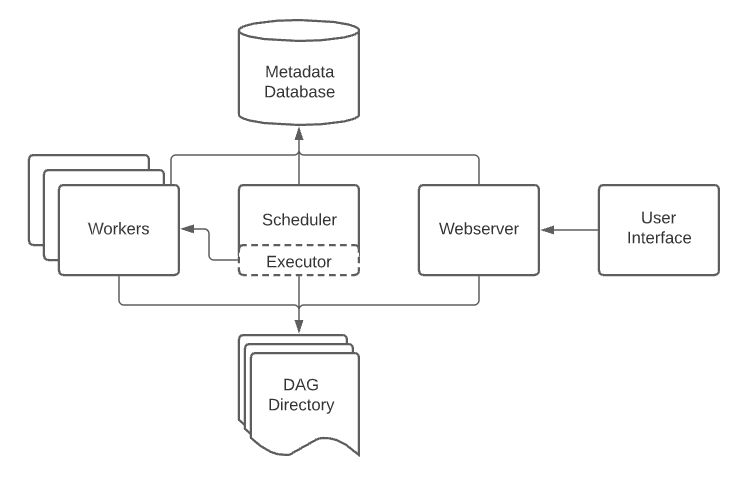
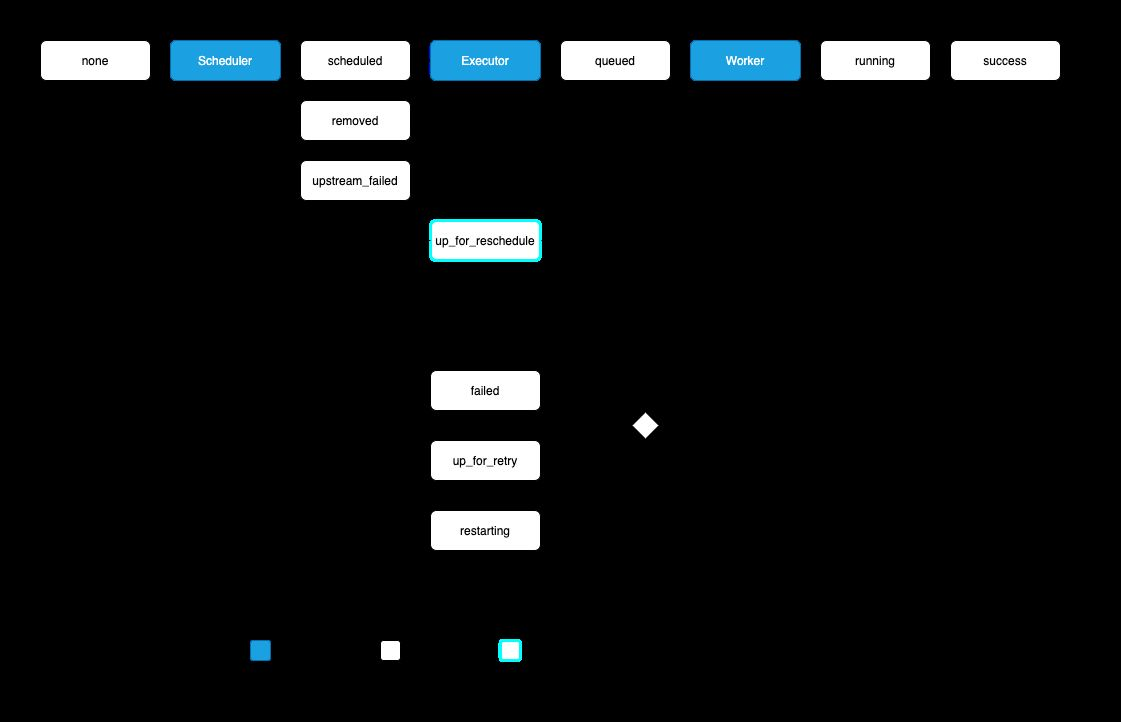
Scheduler
Scheduler는 각종 메타 정보의 기록을 담당
- DAG Directory 내 .py 파일에서 DAG을 파싱하여 DB에 저장
- DAG들의 스케줄링 관리 및 담당
- 실행 진행 상황과 결과를 DB에 저장
- Executor를 통해 스케줄링 기간이 된 DAG을 실행
- Airflow에서 가장 중요한 컴포넌트
Executor
Executor는 스케줄링 기간이 된 DAG을
실행하는 객체. 크게 2종류로 나뉨
Scheduler - Local Executor
DAG Run을 프로세스 단위로 실행
- Sequential Executor
하나의 프로세스에서 모든 DAG Run들을 처리
Airflow 기본 Executor로, 별도 설정이 없으면 이 Executor를 사용
Airflow를 테스트로 잠시 운영할 때 적합하거나 잘
사용하진 않음 - Local Executor
하나의 DAG Run을 하나의 프로세스로 띄워서 실행
최대로 생성할 프로세스 수를 정해야 함
Airflow를 간단하게 운영할 때 적합
Scheduler - Remote Executor
DAG Run을 외부 프로세스로 실행
- Celery Executor
DAG Run을 Celery Worker Process로 실행
보통 Redis를 중간에 두고 같이 사용
Local Executor를 사용하다, Airflow 운영 규모가 좀 더 커지면 Celery Executor로 전환 - Kubernetes Executor
쿠버네티스 상에서 Airflow를 운영할 때 사용
DAG Run 하나가 하나의 Pod(쿠버네티스의 컨테이너 같은 개념)
Airflow 운영 규모가 큰 팀에서 사용
Workers
DAG의 작업을 수행
- Scheduler에 의해 생기고 실행
- DAG Run을 실행하는 과정에서 생긴 로그를 저장
Metadata Database
메타 정보를 저장
- Scheduler에 의해 Metadata가 저장
- 보통 MySQL이나 PostgresQL를 사용
- 파싱한 DAG 정보, DAG Run 상태와 실행 내용, Task 정보 등을 저장
- User와 Role (RBAC)에 대한 정보 저장
- Scheduler와 더불어 핵심 컴포넌트
- 트러블 슈팅 시, 디버깅을 위해 직접 DB에 연결해 데이터를 확인하기도 함
- 실제 운영 환경에서는 GCP Cloud SQL이나,AWS Aurora DB 등 클라우드 DB를 사용
Webserver
WEB UI를 담당
- Metadata DB와 통신하며 유저에게 필요한 메타 데이터를 웹 브라우저에 보여주고 시각화
- 보통 Airflow 사용자들은 이 웹서버를 이용하여 DAG을 ON/OFF 하며, 현 상황을 파악
- REST API도 제공하므로, 꼭 WEB UI를 통해서 통신하지 않아도 괜찮음
- 웹서버가 당장 작동하지 않아도, Airflow에 큰 장애가 발생하지 않음(반면 Scheduler의 작동 여부는 매우 중요)
4.2 실무에서 Airflow를 구축하는 과정
실무에서 어떻게 쓰이는지 알고 공부한다면?
Airflow를 구축하는 방법으로 보통 3가지 방법을 사용
- 1) Managed Airflow (GCP Composer, AWS MWAA)
- 2) VM + Docker compose
- 3) Kubernetes + Helm
4.2.1 Managed Airflow
-> 보통 별도의 데이터 엔지니어가 없고, 분석가로 이루어진 데이터 팀의 초기에 활용하기 좋음
장점
- 설치와 구축을 클릭 몇번으로 클라우드 서비스가 다 진행
- 유저는 DAG 파일을 스토리지(파일 업로드) 형태로 관리
단점
- 높은 비용과 적은 자유도, 클라우드에서 기능을 제공하지 않으면 불가능한 제약이 많음
4.2.2. VM + Docker compose - 직접 VM 위에서 Docker compose로 Airflow를 배포하는 방법
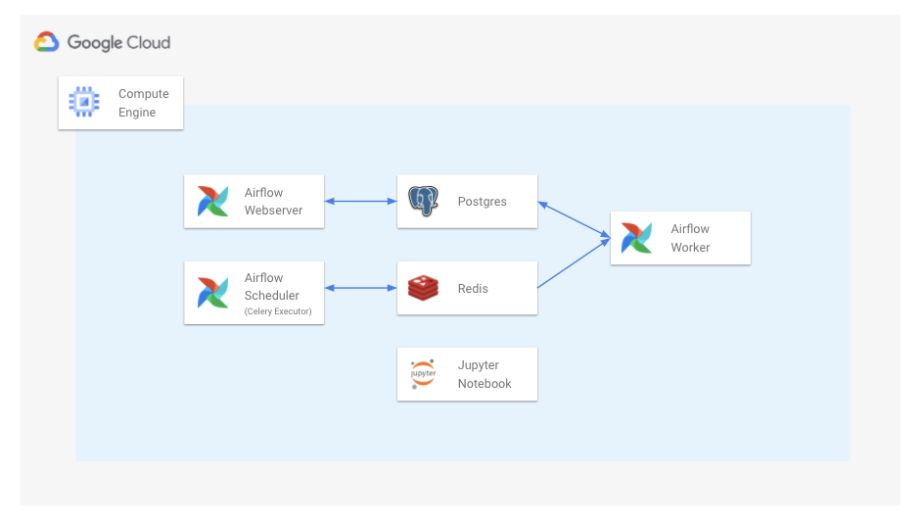
장점
- Managed Service 보다는 살짝 복잡하지만, 어려운 난이도는 아님
- (Docker와 Docker compose에 익숙한 사람이라면 금방 익힐 수 있음)
- 하나의 VM만을 사용하기 때문에 단순
단점
- 각 도커 컨테이너 별로 환경이 다르므로, 관리 포인트가 늘어남
- 예를 들어, 특정 컨테이너가 갑자기 죽을 수도 있고, 특정 컨테이너에 라이브러리를 설치했다면, 나머지 컨테이너에도 하나씩 설치해야 함
4.3.3. Kubernetes + Helm: Kubernetes 환경에서 Helm 차트로 Airflow를 배포하는 방법
- Kubernetes는 여러 개의 VM을 동적으로 운영하는 일종의 분산환경으로, 리소스 사용이 매우 유연한게 대표적인 특징(필요에 따라 VM 수를 알아서 늘려주고 줄여줌)
- 이런 특징 덕분에, 특정 시간에 배치 프로세스를 실행시키는 /Airflow와 궁합이 매우 잘 맞음
- Airflow DAG 수가 몇 백개로 늘어나도 노드 오토 스케일링으로 모든 프로세스를 잘 처리할 수 있음
- 하지만 쿠버네티스 자체가 난이도가 있는만큼 구축과 운영이 어려움
- 보통 데이터 팀에 엔지니어링 팀이 존재하고, 쿠버네티스 환경인 경우에 적극 사용
5. 관련 추천글
관련 추천 글
1. 버킷플레이스 - Airflow 도입기
- 라인 엔지니어링 - Airflow on Kubernetes
- 쏘카 Airflow 구축기 & Advanced
- https://tech.socarcorp.kr/data/2021/06/01/data-engineering-with-airflow.html
- https://tech.socarcorp.kr/data/2022/11/09/advanced-airflow-for-databiz.html
- Airflow Executors Explained
