AI_tech_CV트랙 여정
1.AI_Tech부스트캠프 week1

1. 배운점 (0) cuda 0-0) cuda 를 사용할 수 있는 환경인지 검토 0-1) cuda device이름을 확인하는 코드 0-2) Tensor를 GPU 에 할당하는 코드표현 (1) torch 1-0) torch.cat()함수는 기존의 차원을 유지하면서 T
2.AI_Tech부스트캠프 week2_ML
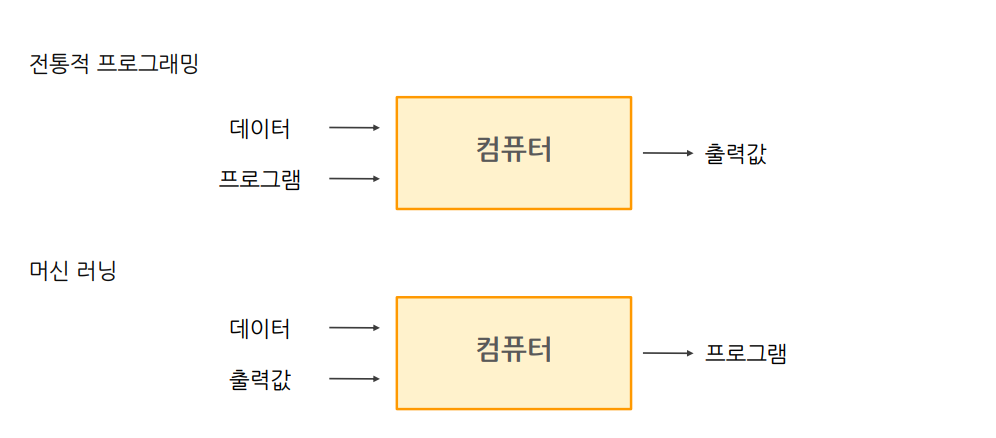
① 어떠한 작업 T에 대해서② 경험E와 함께③ 성능P를 향상시킨다. 즉, 데이터와 출력값을 주어서 컴퓨터가 스스로 프로그램을 만드는 것 학습데이터와 레이블(원하는 출력)을 세트로 제공해서 컴퓨터가 최대한 맞는 답을 찾도록 하는 것.학습데이터만이 제공되면 원하는 출력이
3.AI_Tech부스트캠프 week3_시각화
0. 데이터 분석이 필요한 이유 해석(Interpret) -> 과거/현재 데이터 기반으로 현상태 파악 또는 발견하지 못했던 사실을 데이터분석으로 새롭게 파악 의사결정(Decision Making) -> 특정 목적 하에 구성된 데이터를 바탕으로 의사결정 예측(pre
4.AI_Tech부스트캠프 week4_CV모델
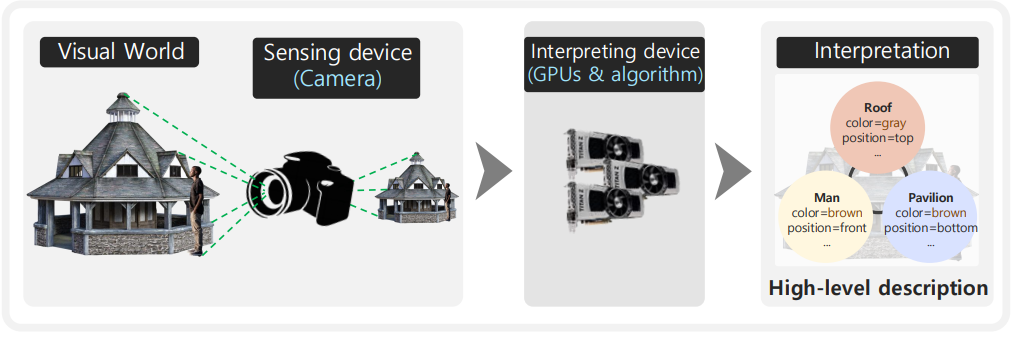
The human visual system is responsible for up to 80%(?) of sensory dataAlmost 50%(?) of our brain is involved in visual processingThe most of informat
5.AI_Tech부스트캠프 week5...(1)(Segmentation)

1. Semantic Segmentation 1.1 What is semantic Segmentation? 📖 Semantic Segmentationis a deep learning algorithm that associates a label or category
6.AI_Tech부스트캠프 week6...[1]AI 개발기초(1) 소프트웨어 엔지니어링과 AI 엔지니어링
1. Software Engineering 이란 ->소프트웨어를 개발하는 과정에서 체계적이고 효율적인 방법을 사용하여 소프트웨어의 품질과 유지보수성을 보장하는 학문분야 (Software is a set of Computer program and associated do
7.AI_Tech부스트캠프 week6...[1]AI 개발기초(2) Linux, Shell script

1. Linux ???: 헤헤 (겁나 멍청해보임;) 1.1 이름 유래 창시자 이름 Linus + unix -> Linux라고 명명됨 1.2 CLI, GUI CLI:Command Line Interface GUI:Graphic User Interface  Streamlit 을 활용한 웹 프로토타입 구현

1. Streamlit 활용한 웹 프로토타입 구현하기 1.1 웹 서비스의 필요성과 개발과정 >프토토타입이란? 릴리즈하기 전에 샘플버전 Test 하기 위해 개발 AI 모델의 input -> output을 확인. -> AI 모델을 활용하여 titanic 예측 생존을
9.AI_Tech부스트캠프 week6...[1]AI 개발기초(4) 파이썬 환경 설정과 디버깅

1
10.AI_tech 서버 사용 방법
1. VPN 만들기 1.1 openVPN 설치 1.2 openVPN config파일설치 1.3 VPN 계정생성 2. SSH 키 만들기 3. 데어터 받기
11.AI_Tech부스트캠프 week6...[1]CV 기초대회(1) CV basic Competition

(we are not a team)Data Science Challenge: 데이터 사이언스 문제를 해결하기 위해 서로 경쟁하는 대회 ① Problem 해결해야하는 과제 ② Data 문제 해결에 필요한 데이터셋 ③ Competitors 경쟁에 뛰어드는 사람
12.AI_Tech부스트캠프 week6...[1]CV 기초대회(2) Image
Image is a visual representation하나의 이미지내에서는 여러가지 정보가 담길 수 있으며\-> 모델이 어떻게 이미지에서 정보를 추출하고 잘 활용할 것인지 고민해보자.이미지는 Data이다.① 해상도(resolution)이미지의 가로 세로 픽셀 개수로
13.AI_Tech부스트캠프 week6...[1]CV 기초대회(3) Image Processing
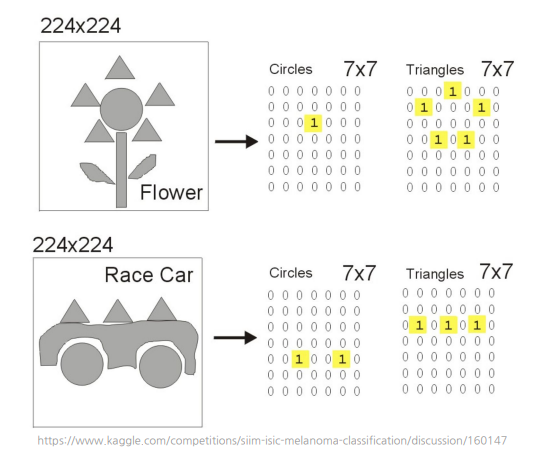
0. Intro Image Processing -> 의미있는 feature와 representation을 추출하는데 도움을 줌., 1. Color Space Color space : Image의 색 공간을 정의 -> 색을 디지털적으로 표현하고 해석하기 위해 정의된
14.AI_Tech부스트캠프 week6...[1]CV 기초대회(4) Image Classification
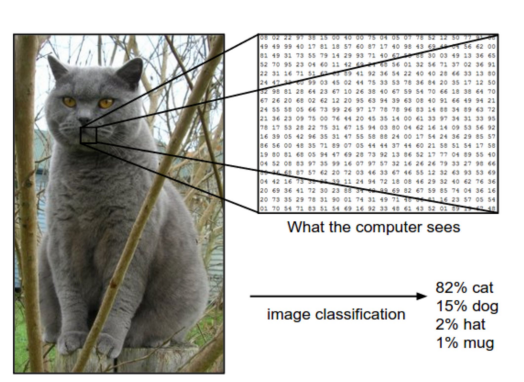
👉 주어진 입력 데이터를 사전에 정의된 클래스로 할당하는 작업👉 이미지 데이터가 내포하는 의미에 대해 사전 정의된 클래스로 할당컴퓨터는 0,1 밖에 모르는 바보.. 그래서 그걸 CNN으로 특성을 파악하고 그걸 통해 Classification 을 자주함. 데이터를 두
15.AI_Tech부스트캠프 week6...[1]CV 기초대회(5) Model
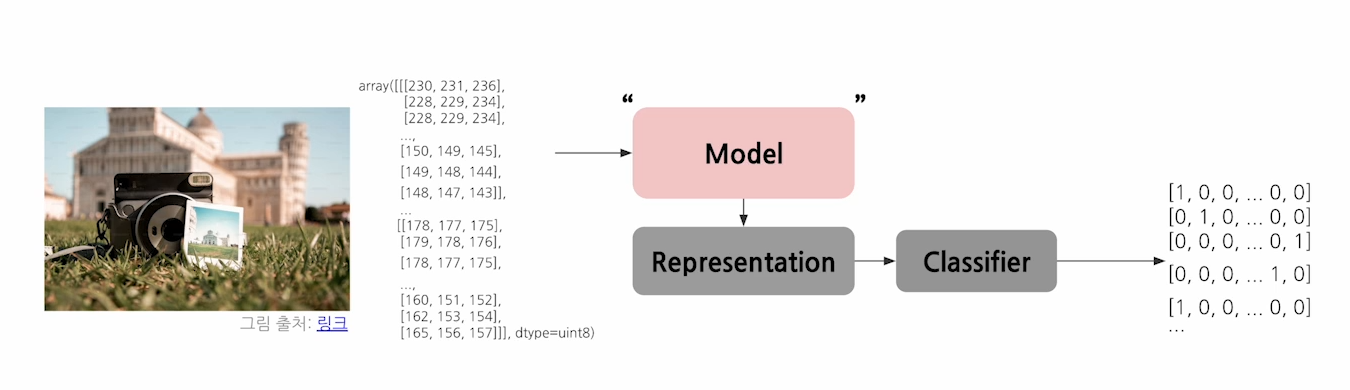
🤔 어떻게 모델은 그러한 복잡한 data들을 다 이해하는 것일까?Model is an informative representation of an object, person, or systemInductive Bias 란, 모델 학습과정에서 특정 유형의 패턴을 잘 학습
16.AI_Tech부스트캠프 week6...[1]CV 기초대회(6) Representation.
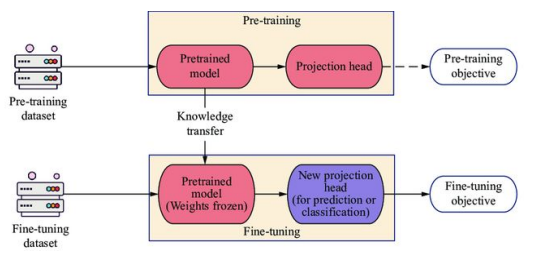
0. Intro Representation은 같은 대상이라도 상황에 따라, 관점에 따라 의미가 바뀌기도 한다. 같은 이미지의 고양이라도 표현은 모두 다르다. 1. Understanding Representation 1.1 Representation Represent
17.AI_Tech부스트캠프 week6...[1]CV 기초대회(7) Training Process
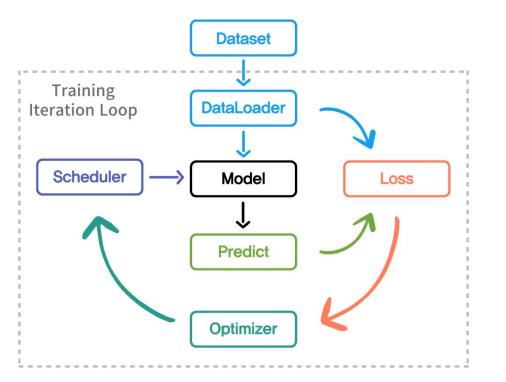
1. 학습 파이프라인 전체 개요 1.1 전체적인 프로세스 ① 학습 Task 선언 무엇을 학습할지? 데이터를 구성하고 Dataset class 와 DataLoader를 선언 적절한 Model 선별 ② 학습 방법 선정 손실함수 선언(Loss) 학습의 최적화 방법(o
18.AI_Tech부스트캠프 week6...[1]CV 기초대회(8) Efficient Training
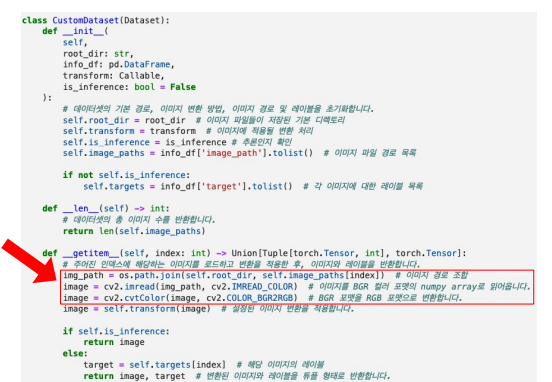
데이터 캐싱은 빈번하게 사용하는 데이터를 더욱 효율적으로 재사용할 수 있도록, 반복적인 작업을 미리 처리하고 별도의 데이터로 저장하거나 메모리에 일시적으로 저장해두는 과정.\-> 즉, 반복적인 과정을 미리 처리해서 전체적인 데이터 처리 속도 증가.빨간색 부분이 매번의
19.AI_Tech부스트캠프 week6...[1]CV 기초대회(9) Evaluation

성적표 주셈.잘하고 있는지 나침반 같은 것.지표(Metric)이란, 모델이 올바르게 학습되고 있는지 그 수치를 정량적으로 나타낸것.$Precision = \\frac{TP}{TP+FP}$ : 예측한 것들 중에서 얼마나 잘 맞추었냐$Recall = \\frac{TP}{T
20.AI_Tech부스트캠프 week8...[1]Object_Dectection overview

Classification : object 전체에 대해 하나의 레이블을 할당하는 작업 Object Detection : 객체 검출은 이미지 내에서 여러 객체를 식별하고 각 객체의 위치를 찾아내는 작업 Semantic Segmentation : 객체에 영역을 구분하는
21.AI_Tech부스트캠프 week8...[2]Object_Dectection 2 Stage Detectors
0. Intro 1 Stage Detection 이미지 내에서 한번에 classification + detect! 즉, 분류(classification)와 위치 검출(localization)을 동시에 수행 2 Stage Detection 이미지 내에서 classfif
22.AI_Tech부스트캠프 week8...[3]Object_Dectection Library

0. Intro 앞서 Object detection 같은 경우에는, 통합된 라이브러리가 없어 처음에 어떤 라이브러리를 선택할지가 굉장히 중요하다. 1. MMDetection Pytorch 기반의 Object Detection 오픈소스 라이브러리. MM은 Multi-
23.AI_Tech부스트캠프 week8...[4]Object_Dectection neck
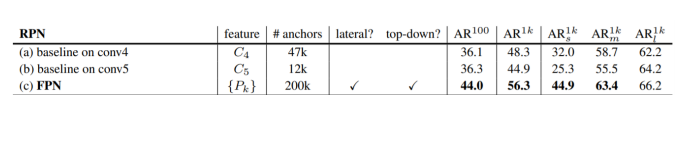
0. Intro 이번 장에서는 Object Detection 아키텍처의 핵심 요소인 Neck과 Feature Pyramid Network(FPN)에 대해 심도 있게 살펴보겠습니다. 이 두 가지 개념은 현대 Object Detection 시스템의 성능을 크게 향상시키는
24.AI_Tech부스트캠프 week8...[5]Object_Dectection 1 stage detectors
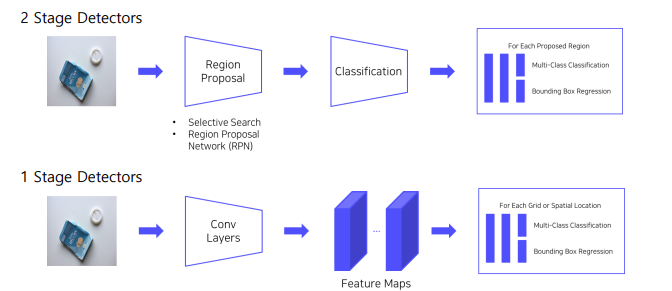
그전까지 2 Stage Detectors는, ① 객체가 있을 법한 후보 영역을 찾고 -> ② 그 object 가 무엇인지 classification 하는 2가지 단계를 거쳤다.2 stage DetectorsRCNN,FastRCNN, SPPNet, FasterRCNN\-
25.AI_Tech부스트캠프 week8...[6]Object_Dectection EfficientDet
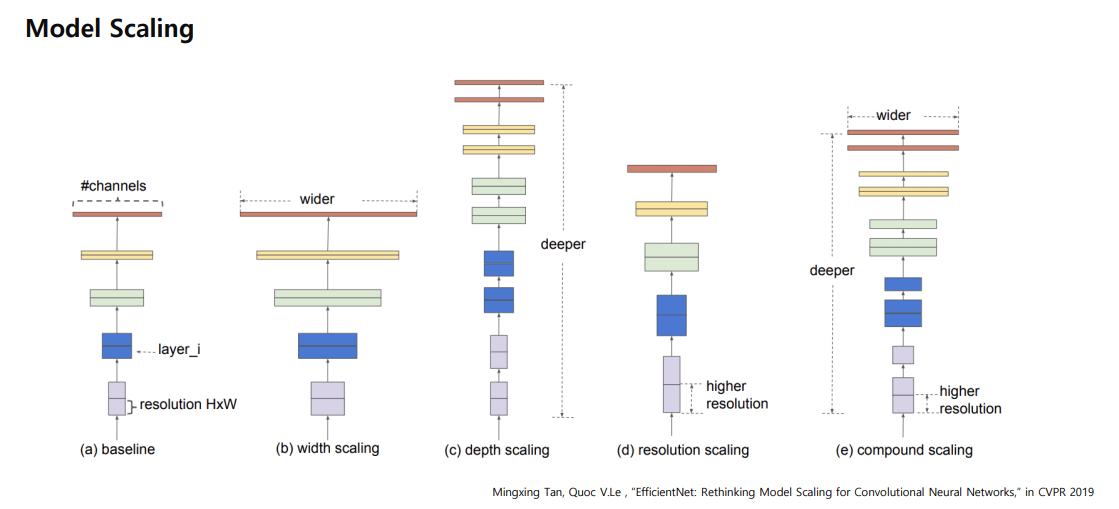
Detection 부분에서는 속도와 처리가 효율적(efficient)하게 이루어줘야 한다.이를 위해 Effecient Detection 이 나왔다..!!Model Scaling모델을 쌓는 것을 Model Scaling 이라고 하는데, 기존 연구들은Baseline 모델이
26.AI_Tech부스트캠프 week8...[7]Object_Dectection Advanced

0. Intro 2 stage detector에서 더 나아간 모델들에 대해서 공부해보자. 1. Cascade RCNN 1.1 Contribution FastR-CNN에 대해서 다시 한번 살펴보자. Convnet 을 이용하여 RPN 추출후 -> image classi
27.AI_Tech부스트캠프 week9...[1] Data-Centric AI 개요

OCR(Optical Character Recognization)ProgrammingOurDailyLifeCreationArtDating,Friends이루다 처음 봤을때 정말 신기해서 계속 대화했던 기억이 난다. 속도가 너무 빨라서 사람같지 않았지만, 내용 자체는 사람
28.AI_Tech부스트캠프 week9...[2] Data-Centric AI 의 중요성
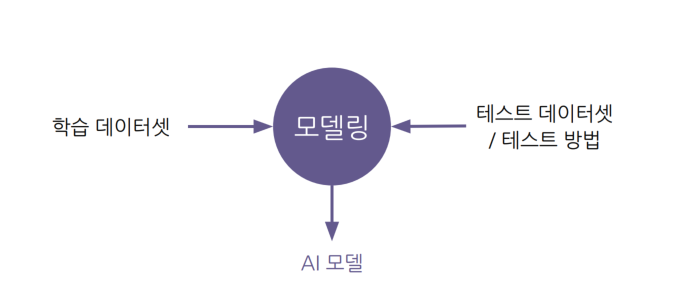
수업/학교/연구\-> 정해진 데이터셋/평가 방식에서 더 좋은 모델을 찾는일을 한다.서비스 개발시\-> 데이터셋은 준비되어 있지 않고, 요구사항만 존재.\-> 서비스에 적용되는 AI 개발의 상당부분이 데이터셋을 준비하는 작업.AI모델 개발 4단계이 과정의 목표: 요구사항
29.AI_Tech부스트캠프 week9...[3] OCR Tasks

1. OCR Basics 1.1 OCR 정의 OCR : Optical Character Recognition STR : Scene Text Recognition 글자를 읽는다 = 글자영역찾기 + 영역 내 글자인식 = OCR Off line Handwriting V
30.AI_Tech부스트캠프 week9...[4] 거대 모델을 활용한 OCR 및 문서 이해
1. Transformer Recap 1.1 Vision Transformer 논문리뷰 : https://velog.io/@leejken530/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B06-ViT VisionTransformer의 특징 패치 임베딩: 이미지를 패치로 분할하고 각 패치를 선형 투영을 통해 임베딩 벡터로 변환합니다. 위치...
31.AI_Tech부스트캠프 week9...[5] OCR Services & Application
외국어, 다량의 글자 외에도 사진만 찍어서 바로 wifi 비밀번호를 얻는 것도 있다.구글에 "업스테이지"만 쳐도 업스테이지의 이미지 text들이 있는 것들도 자동으로 나오게 함.광고성/혐오성 이미지text들도 자동으로 제거. (근데 저기에 뭐라고 적혀있을려나..)외국
32.AI_Tech부스트캠프 week9...[6] OCR 및 문서데이터셋 소개
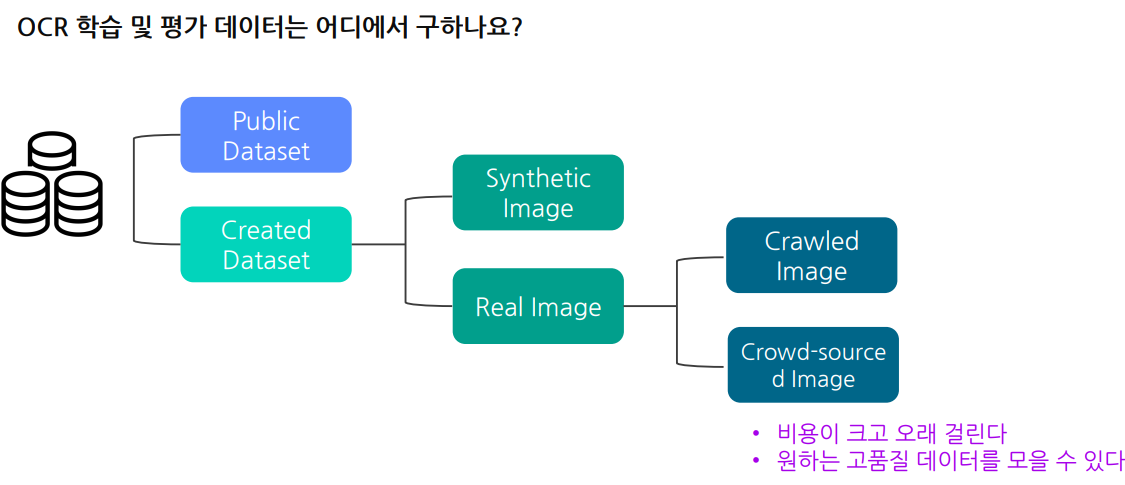
서비스향 AI모델 개발시 한시라도 빨리 답을 가지고 있어야 하는 질문들몇 장을 학습을 시키면 어느정도 성능이 나오는가?어떤 경우가 일반적이고 어떤경우가 희귀케이스인가?현재 최신 모델의 한계는 무엇인가?검색방법ICDAR(International Conference on
33.AI_Tech부스트캠프 week9...[7] OCR 성능 평가

1.성능평가개요 1.1 성능평가의 중요성 성능평가 == 새로운 (학습에서 사용되지 않은) 데이터가 들어왔을 때 얼마나 잘 동작하는가? 성능평가시 데이터 분리방법 모델 성능이 올라감에 따라,pre-trained model로 inference한 결과를 평가에 활용하는것이
34.AI_Tech부스트캠프 week9...[8]
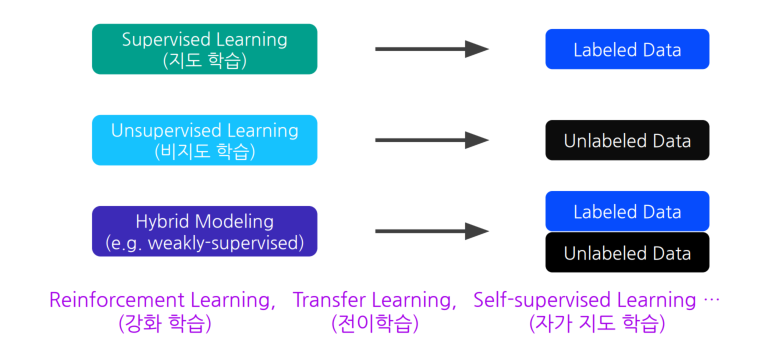
좋은 모델을 얻기 위해서는 일관된 방식으로 고르게 라벨링된 데이터가 필수적Data모델 학습과정 -Supervised Learning좋은데이터란? 1) 골고루 모여 있고2) 일정하게 라벨리된 데이터https://github.com/wkentaro/labelme오
35.AI_Tech부스트캠프 week9...[9] 데이터 구축 작업 설

1. 데이터셋 제작과 가이드라인 가이드라인은 좋은 데이터를 확보하기 위한 과정을 정리한 문서 1.1 가이드라인이란? 가이드라인: 좋은데이터를 확보하기 위한과정을 정리해 놓은 문서 데이터 구축의 목적 라벨링 대상 이미지 소개 기본적인 용어 정의 BBOX,“전사”,“
36.AI_Tech부스트캠프 week9...[10] Data-Centric AI 를 위한 데이터후처
1. 데이터증강 데이터증강(Data augmentation)은 기존 데이터를 다양한 방식으로 변형하여 , 데이터셋의 크기와 다양성을 증가시키는 방법. 1.1 Image Data Augmentation 데이터 증강이란 무엇? 데이터를 증강시켜 모델을 일반화하는 것.
37.AI_Tech부스트캠프 week13...[1] Segment Introduction
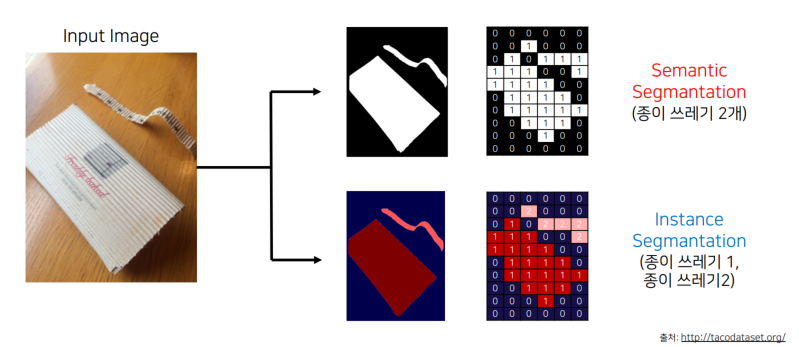
Semantic Segmentation :Dice Coefficient집합이 얼마나 겹치는지 나타내며 0에서 1 사이의 값을 가짐$$\\text{Dice}(A, B) = \\frac{2 |A \\cap B|}{|A| + |B|}$$이 수식에서:( A )와 ( B )는
38.AI_Tech부스트캠프 week13...[2] Segment Competition Overview
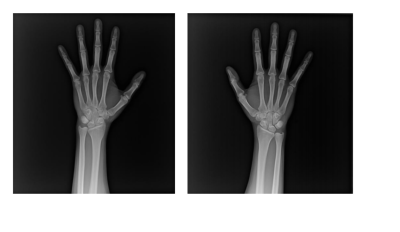
목표 : X-ray 이미지에서 사람의 손 뼈를 Segmentation 하는 인공지능 만들기 Input : 손 뼈가 담긴 X-ray image Output : 각 pixel 좌표에 따른 class 값Image file format➢ 한 사람의 왼손, 오른손에 해당하는 X
39.AI_Tech부스트캠프 week13...[3] Semantic Segmentation의 기초와 이해
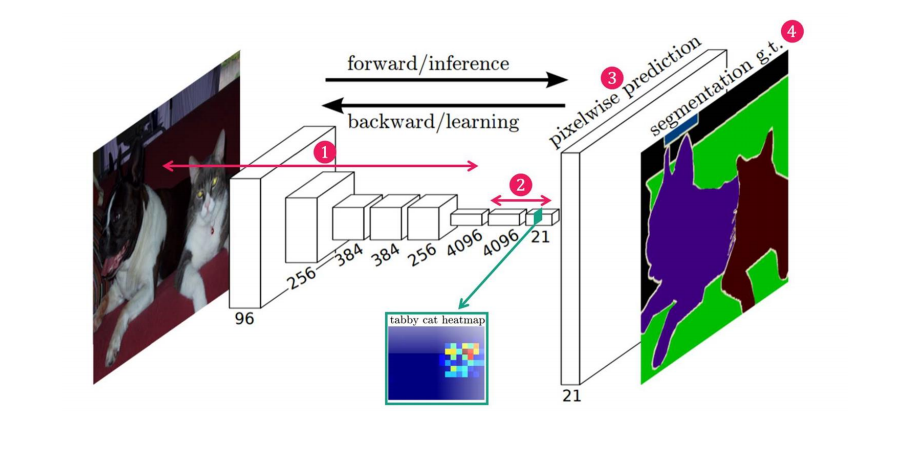
논문 :https://arxiv.org/abs/1411.4038요약: 이 연구는 완전한 합성곱 네트워크(fully convolutional networks)를 사용하여 이미지의 임의 크기 입력에 대해 효율적으로 크기에 맞는 출력을 생성하고, 학습 및 추론 속도
40.AI_Tech부스트캠프 week13...[4] FCN 한계를 극복한 model1
1. FCN의 한계점 (1).객체의 크기가 크거나 작은 경우 예측을 잘 하지 못하는 문제 • 큰 Object의 경우 지역적인 정보만으로 예측 • 버스의 앞 부분 범퍼는 버스로 예측하지만, 유리창에 비친 자전거를 보고 자전거로 인식하는 문제 발생하기도 함 • 같은 Obj
41.AI_Tech부스트캠프 week13...[5] FCN의 한계를 극복한 model 2 성능적인 측면에서의 극복

1. Receptive Field를 확장시킨 models 1.1 DeepLab v2 DeepLab v2는 다양한 스케일의 정보를 효과적으로 결합하여 이미지 내의 객체를 정확히 분할하는 데 특화된 구조를 가진 아키텍처 특징(feature) 기본 컨볼루션 레이어: D
42.AI_Tech부스트캠프 week13...[6] High Performance를 자랑하는 U-Net 계열의 모델들 U-Net, U-Net++, U-Net 3+
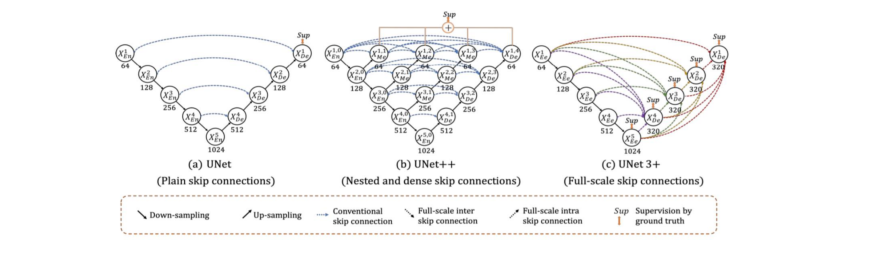
1. U-Net 1.1 U-Net Intro 의료 계열에서의 문제 상황 I (데이터 부족) • 기본적인 Deep Learning은 파라미터 수가 많고 네트워크가 깊어서 train data가 많이 필요 • 특히, biomedical의 특성상 data의 수가 많이 부족할
43.AI_Tech부스트캠프 week13...[7] Semantic Segmentation 대회에서 사용하는 방법들1

library설치pip install git+https://github.com/qubvel/segmentation_models.pytorchArchitectures 및 Encoders1.디버깅 모드 :실험 환경이 잘 설정되었는지 체크하기 위한 과정(1). 샘플
44.AI_Tech부스트캠프 week13...[8] SemanticSegmentation 대회에서 사용하는 방법들 2
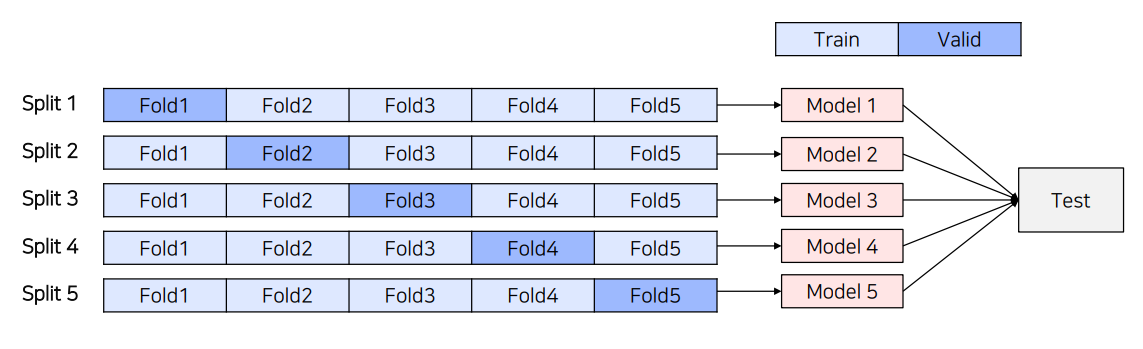
(1) 5-Fold Ensemble5-Fold Cross validation을 통해 만들어진 5개의 모델을 Ensemble하는 방법(2) Epoch Ensemble학습을 완료한 후, 마지막부터 N개의 Weight를 이용해 예측한 후 결과를 Ensemble하는 방법(3)
45.AI_Tech부스트캠프 week14...[1] Generative AI Introduction
1.Generative AI 개요 및 흐름 1.1 GenerativeAI:NLP Large Language Model이란? 텍스트를 입력으로 받아 적절한 출력을 산출하는 언어모델 Large LanguageModel 발전현황 InstructGPT/ChatGPT출현 이
46.AI_Tech부스트캠프 week14...[2] Generative AI Introduction
범용적인 태스크 수행이 가능한 Language Model\-> 사전학습 데이터 및 파라미터 수가 매우 큰 모델의 종합적 지칭Pretrained LMDownstream 태스크 별 Finetune을 통해 목적 별 모델 구축\-> 하나의 모델을 사용해 하나의 태스크 해결LL
47.AI_Tech부스트캠프 week14...[3] Text Generation2: Parameter EfficientTuning
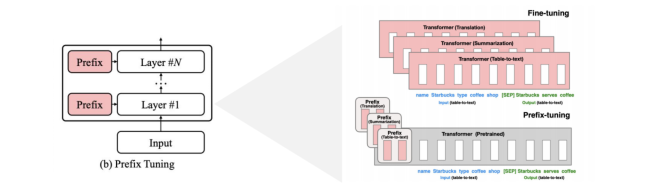
1. LLM발전과 PEFT방법론의 중요성 1.1 LLM의 발전과정 • 언어모델을 활용하기 위해서는 일반적으로 범용웹데이터를 기반으로 • 1)사전학습을수행하고 2)Downstreamtask에 맞추어fine-tuning을 진행해왔음=>이러한 학습방법은 특정 task에서
48.AI_Tech부스트캠프 week14...[4] Text Generation 3 : sLLM Models

Open-SourceLicense:소프트웨어의 코드 공개를 통한 복제/배포/수정에 대한 명시적 권한다른 소프트웨어를 활용하여 개발을 진행할 경우 해당 소프트웨어 라이센스 고려 필요ex)• MITLicense:자유로운 복사 및 배포 가능,유료화 불가능• CC-BY-SA4
49.AI_Tech부스트캠프 week14...[5] Image Generation 1 : Image Generation Models Overview
1. Generative Adversarial Networks, GANs 1.1 GANs 판별자와 생성자를 적대적으로 학습하는 모델 구조 $Loss function$: $$ L{GAN} = \minG \maxD V(D, G) = \mathbb{E}{x \sim p{d
50.AI_Tech부스트캠프 week15...[1] Serving의 정의와 다양한 패턴
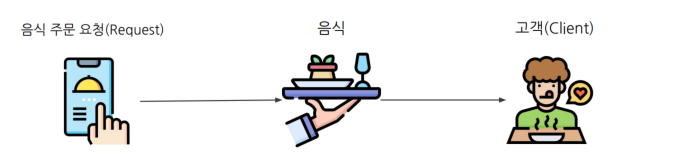
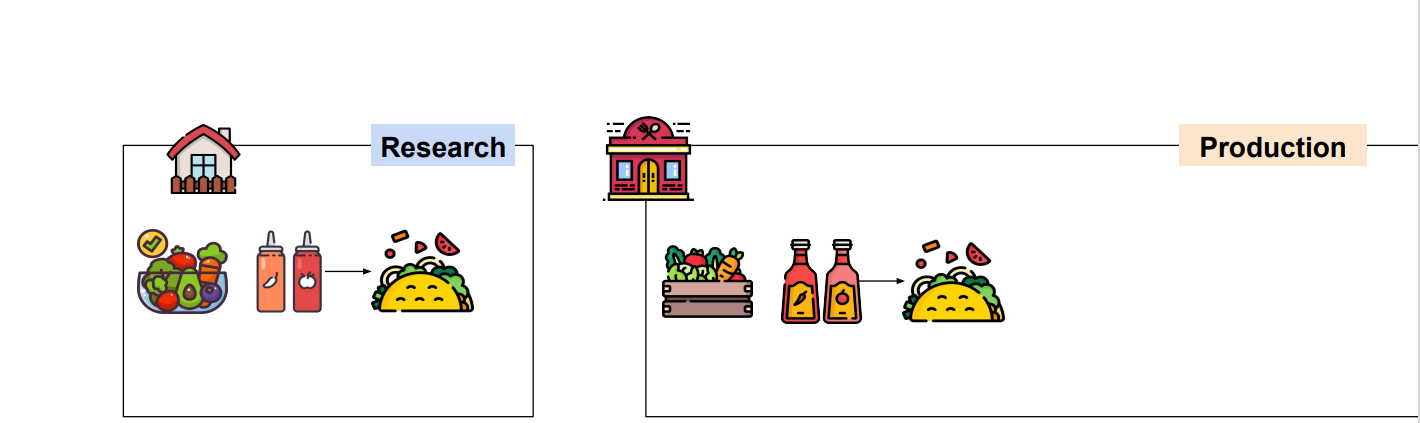
serve: 음식을 나르는 행위 자체. 머신러닝 모델 Serving모델의 예측 결과를 요청한 Client에게 제공하는 과정데이터에 기반하여 모델 예측 결과를 제공하는 것Research vs ProductionResearch는 집에서 요리, Production 은 고객에
51.AI_Tech부스트캠프 week15...[2] Batch Serving과 Airflow

1. Batch Serving 1.1 Batch Serving의 구현 일정 기간 데이터 수집 후 일괄 학습 및 결과 제공하는 특성이 있음 대량의 데이터 처리할 때 효율적 ex) 모델을 주기적으로 학습시킬때 Batch Serving은 예측 코드를 주기적으로 실행해서 예
52.AI_Tech부스트캠프 week15...[3] 웹프로그래밍 지식

1.OnlineServing 1.1OnlineServing의구현 1.2OnlineServing에서고려할것 2.Server아키텍처 2.1모놀리스아키텍처 2.2마이크로서비스아키텍처 2.3무엇을사용해야할까? 3.API 3.1WebAPI 3.2RESTAPI 4.RESTAPI
53.AI_Tech부스트캠프 week15...[4] FastAPI(1)
fastapi github: https://github.com/fastapi/fastapi간단한 프로젝트구조프로젝트의 코드가 들어갈 모듈 설정(app).대안:프로젝트이름,src등main.py는간단하게 애플리케이션을 실행할 수 있는 entrypoint역할(참고공
54.AI_Tech부스트캠프 week15...[5] FastAPI(2)

1.Pydantic사용법 1.1 Pydantic 소개&기능 DataValidation/SettingsManagement라이브러리 TypeHint를 런타임에서 강제해 안전하게 데이터핸들링 머신러닝 FeatureDataValidation으로도 활용가능 pydantic은
55.AI_Tech부스트캠프 week15...[6] Docker
개발할때,서비스운영에 사용하는 서버에 직접들어가서 개발하지않음Local환경에서 개발하고,완료되면 Staging서버,Production서버에배포🤔 이 부분에서 생기 는고민:서버 환경까지도 모두 한번에 소프트웨어화 할 수 없을까?특정 소프트웨어 환경을 만들고,Local,
56.AI_Tech부스트캠프 week15...[7] 클라우드서비스스

본인의 컴퓨터로 웹, 앱 서비르 만들기도 가능함 -> 하지만 이런 경우 자신의 컴퓨터가 종료되면 웹,앱 서비스도 종료.이런 경우 전통적인 접근 방법물리적 공간, 확장성을 고려한 서버실을 만들고 운영IDC(Internet Data Center)서버 컴퓨터를 넣을 공간 +
57.AI_Tech부스트캠프 week15...[8] 모델과 코드 배포
1. 환경분리와 배포 1.1 현업의개발 프로세스 Local 각자의 컴퓨터에서 개발 각자의 환경을 통일시키기위해 Docker등을 사용 Dev Local에서 개발한 기능을 테스트 할 수 있는 환경 Test서버 Staging Production환경에 배포하기 전에 운영하
58.AI_Tech부스트캠프 week15...[9] 모델관리
1.모델관리 1.1 왜 모델관리가 필요할까? 즉, 고객들도 안심하고 먹게 할려고 모델 관리는 모델의 성능에 직접적인 영향을 주지는 않습니다. 모델 관리는 모델의 버전 관리, 협업, 업데이트 관리 등을 통해 모델의 효율적인 운영을 지원합니다. 모델의 성능을 개선하기
59.AI_Tech부스트캠프 week15...[10] AI공부하면 좋을것들.

pythonLinuxclean codeAI Engineer는 데이터모델링+데이터개발영역을 커버하길 원하는 추세실시간 데이터처리 : Kafka,ApacheSparkStreaming...메세지 시스템: Kafka,Redis,AWSSQS,GCPPubSub,Celery분산 처
60.AI_Tech부스트캠프 week16...[1] 모델 최적화 및 경량
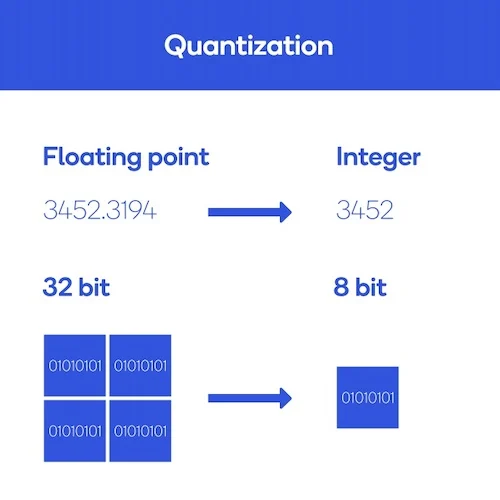
Necessity of Light-weighting and Acceleratio 전력사용 , 자율주행, on-device 모델에서는 경량화 모델이 필요함. AI 모델의 거대화로 인해 계산 자원량의 기하급수적 증가. 다양한 환경에서 이러한 거대 모델을 운영하기는 다양한
61.AI_Tech부스트캠프 week16...[2] Pruning(1)
1. Concept of Pruning 1.1 What is Pruning? Pruning(가지치기)란, 신경망 모델에서, 노드(뉴런)나 연결(시냅스)을 제거하여 모델의 크기와 계산 비용을 줄이는 기법 High-level illustration of Pruning
62.AI_Tech부스트캠프 week16...[3] Pruning(2)
1. Advanced Concepts 1.1 Matrix Sparsity 희소(sparse)행렬: 행렬의 대부분의 요소가 0인 행렬 정확히 몇 퍼센트 이하면 희소하다 라는 개념은 아님. 아주 sparse 한 경우: Sparse Matrix Representation
63.AI_Tech부스트캠프 week16...[4] Knowledge distillation(1)
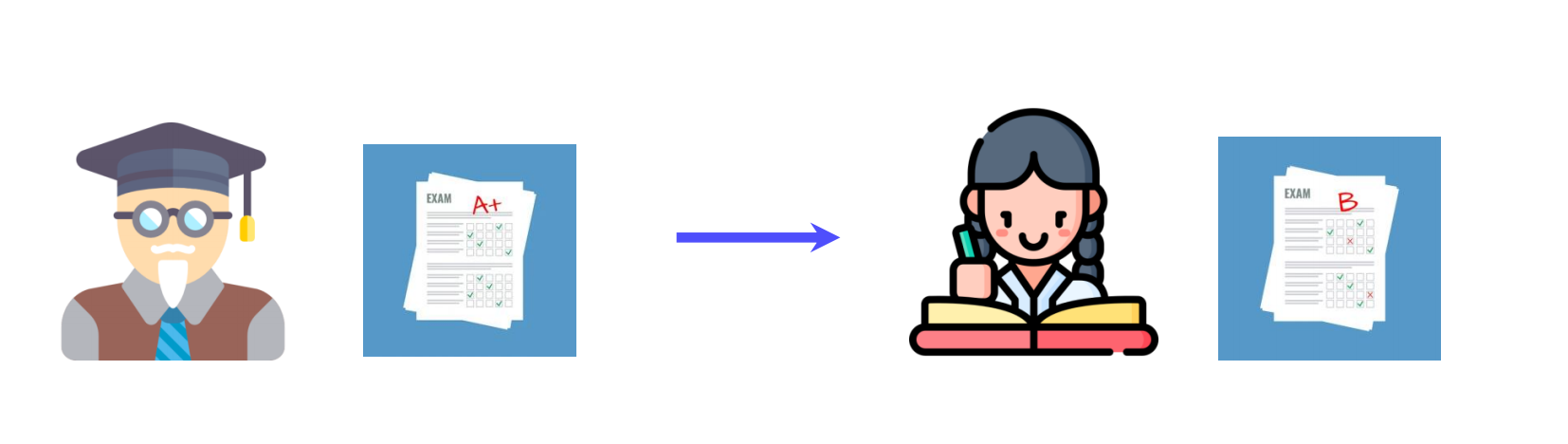
경량화의 한 종류로써, 고성능의 Teacher 모델로부터 지식을 전달 받아서 Student 모델을 학습 시키는 기법{"White-box KD" : Feature based,"Gray-box KD": Logit-based,"Black-box KD: Imitation-le
64.AI_Tech부스트캠프 week16...[5] Knowledge distillation(2)
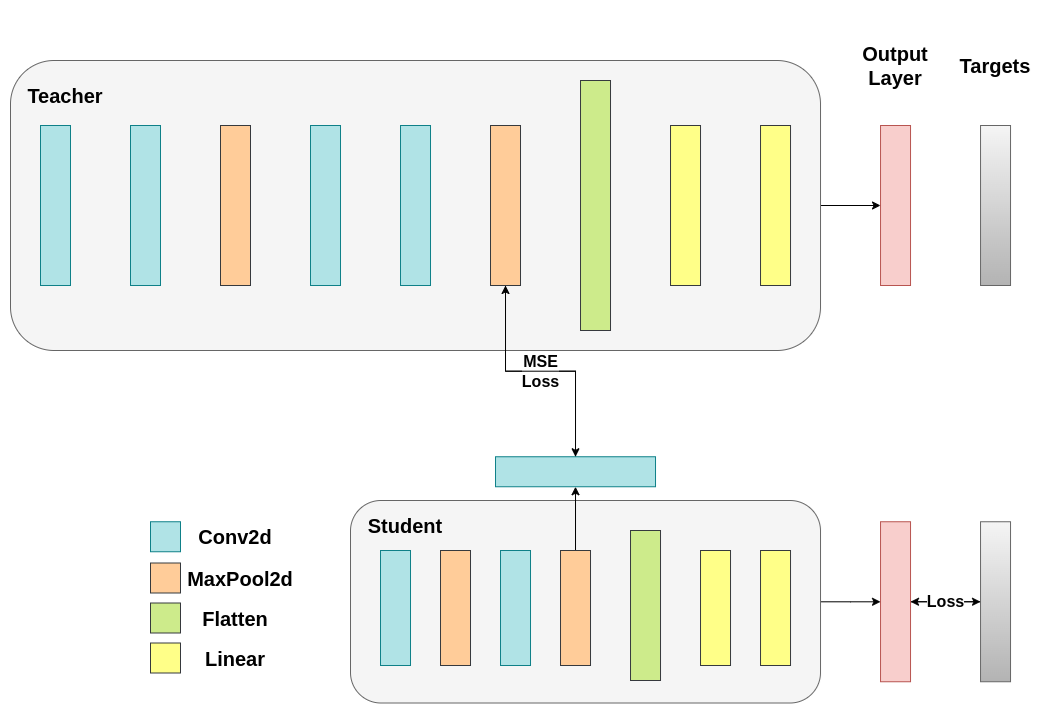
1. Feature-based KD Teacher 모델의 레이어 특징값(feature)을 사용. 1.1 Feature-based logit-based 와 다른점 Logit-based: KL Loss 추가 Feature-based: MSE Loss 추가 Regres
65.AI_Tech부스트캠프 week16...[6] Quantization
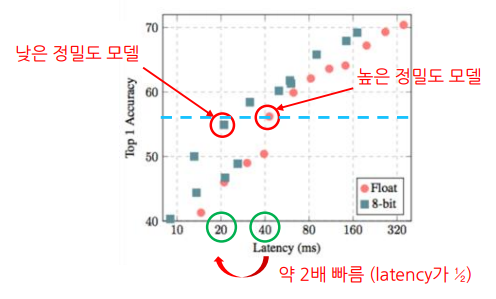
Quantization (양자화)이란, 숫자의 정밀도(precision)를 낮추는 최적화 및 경량화 기법정밀도란, 의도한 숫자를 얼마나 정확하게 표현할 수 있는지를 타나내는 것으로ex) $\\pi$의 값을 나타낼때,3.141592가 3.14보다 더 높은 정밀도의 값을
66.AI_Tech부스트캠프 week16...[7] PEFT(1)
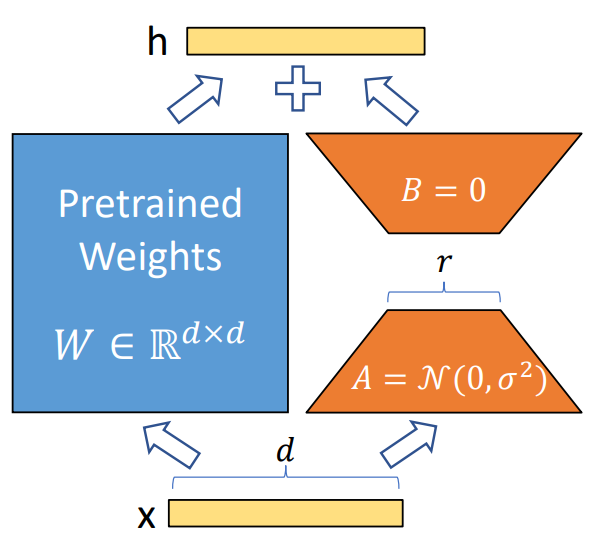
1. Transfer Learning 1.1 Transfer Learning Transfer Learning (전이학습)이란, 이미 학습이 완료된 모델을 새로운 작업의 시작점으로 모델을 재사용하는 기계학습 방법론 -> 특정 데이터셋을 이용해서 사전 학습된 모델의 가중치
67.AI_Tech부스트캠프 week16...[8] PEFT(2)
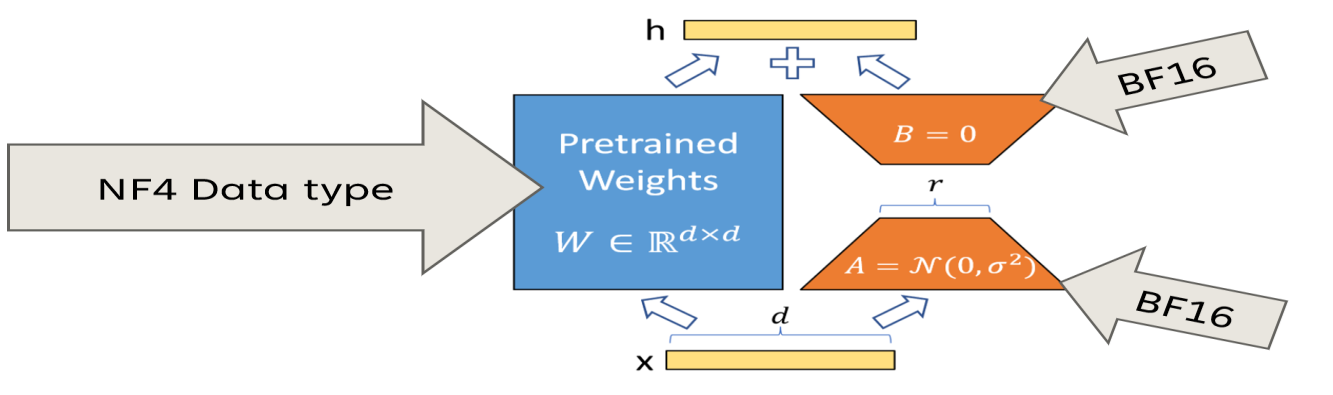
1. Applying LoRA 1.1 Applying LoRA 2. Advanced PEFT 2.1 AdapterFusion https://arxiv.org/abs/2005.00247 motivation: Adapter를 결합하여 여러 task를 해결하는 모델을 만
68.AI_Tech부스트캠프 week16...[9] Distributed Training(1)
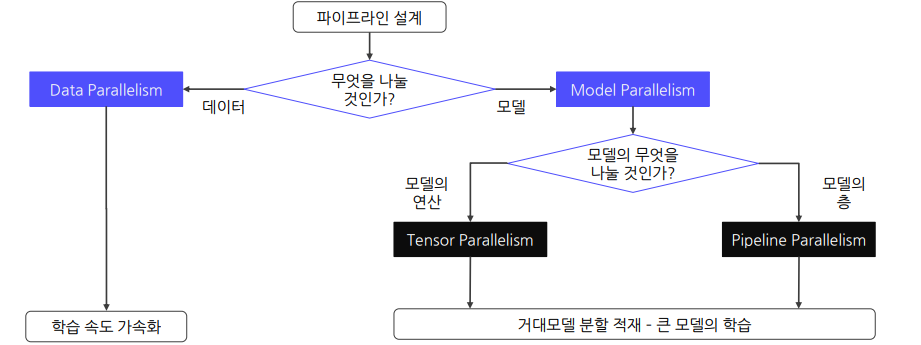
Distributed Training: 모델을 여러 개의 GPU로 분산시켜 GPU에 한 번에 들어가지 않는 큰 모델도 학습 가능하도록 함Data Parallelism큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임GPU간의 출력값들을 바탕으로
69.AI_Tech부스트캠프 week16...[10] Distributed Training(2)
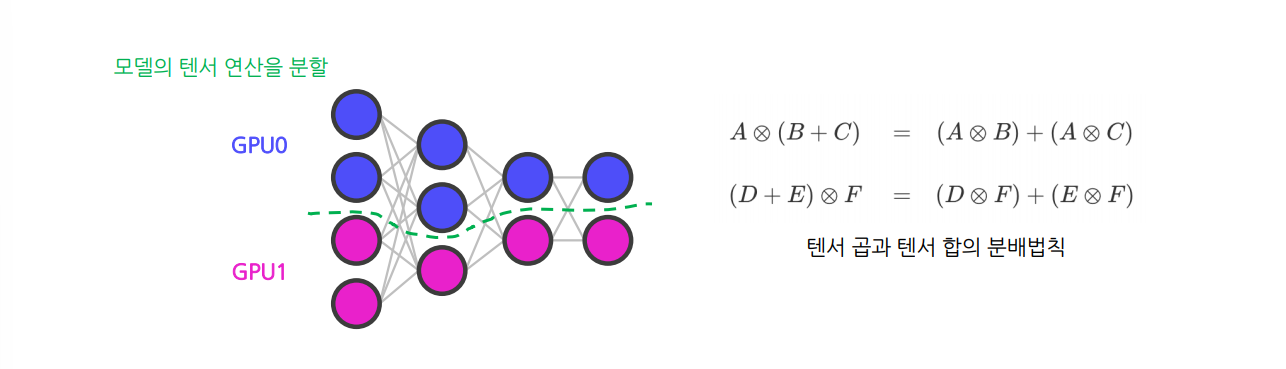
Tensor Parallelism : 모델을 텐서 연산 단위로 여러 GPU에 나누어 계산하는 방식텐서 연산을 여러 차원의 슬라이스(slice)로 나눈 후 GPU들에 할당하여 처리하는 패러다임텐서 연산을 나누어 수행해도 똑같은 값을 얻을 수 있다는 개념에서 시작크기가 큰
70.AI_Tech부스트캠프 week20...[1] Introduction to Generative Models: What, Why and How
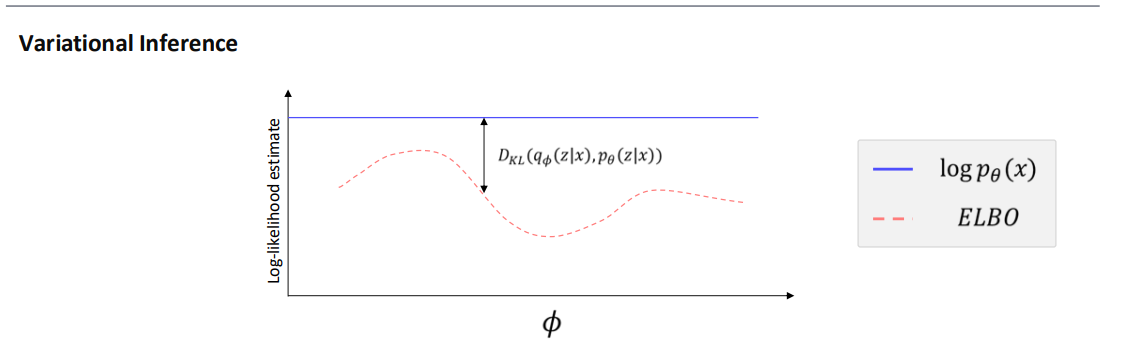
0. 사전지식 KL Divergence $KL(q\|p)$ 는 “$q$ 분포에서 뽑힌 표본을 $p$로 설명하려고 할 때 드는 정보 손실”로 해석할 수 있습니다. $KL(p\|q)$ 는 “$p$ 분포에서 뽑힌 표본을 $q$로 설명하려고 할 때 드는 정보 손실”에 가깝습
71.AI_Tech부스트캠프 week20...[2] From VAE to Diffusion
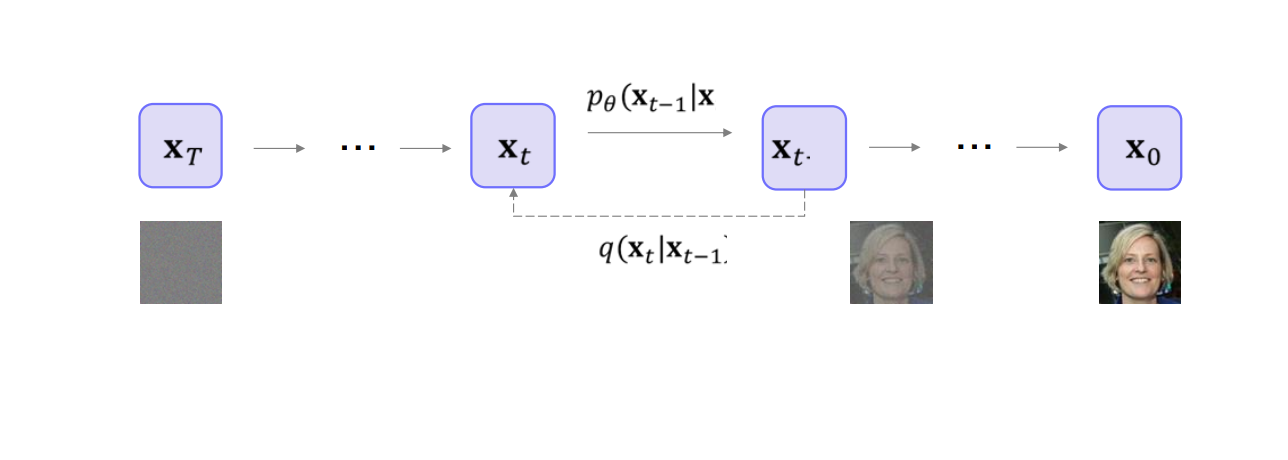
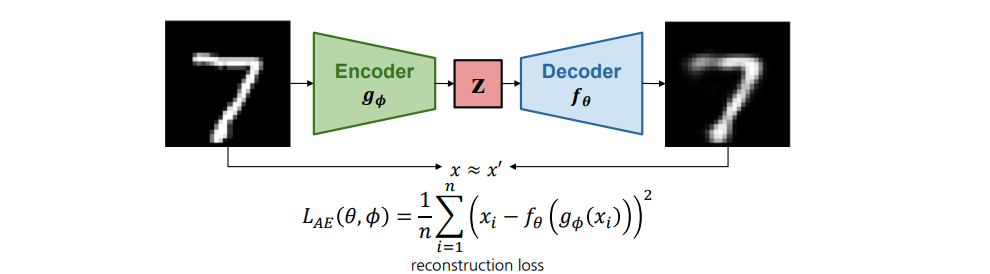
1. Recap (1). Latent Variable Models 잠재변수 모델은 관측 데이터 $\mathbf{x}$와 잠재 변수 $\mathbf{z}$를 활용하여, 복잡한 확률 분포 $p(\mathbf{x})$를 단순한 조건부 분포(예: $p(\mathbf{x} \
72.AI_Tech부스트캠프 week20...[3] Score based Generative Model
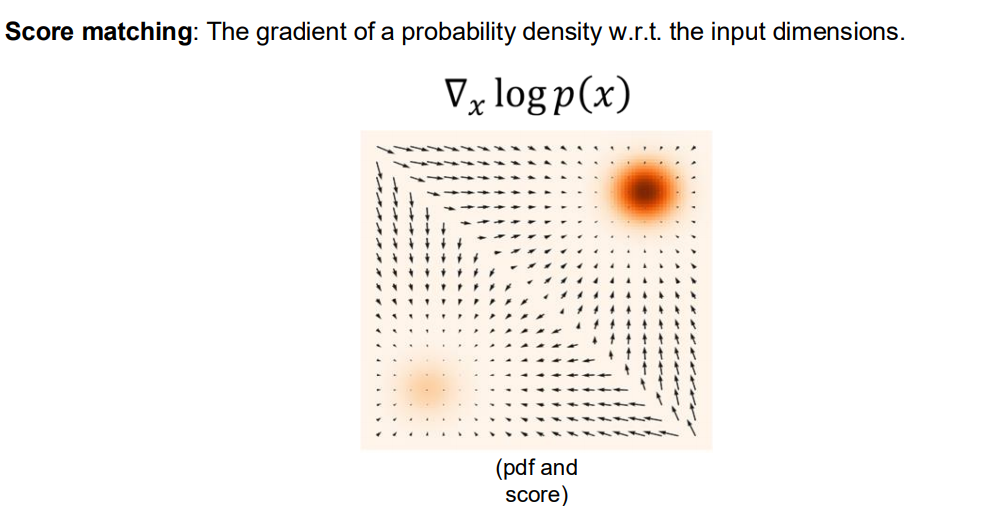
생성 모델(Generative Model)에서 확률분포를 어떻게 표현하고 학습할 수 있는지를 설명하겠습니다.다음과 같은 핵심 아이디어들이 포함되어 있습니다:식:$p\\theta(x) = \\dfrac{e^{-f\\theta(x)}}{Z\_\\theta}$ 여기서 $
73.AI_Tech부스트캠프 week20...[4] Recent Applications in Diffusion Models(1)

1. Unconditional Image Generation Unconditional Generation 개요 Unconditional Generation이란, 사전에 주어진 레이블(label)이나 추가 조건 없이, 모델이 오직 데이터 분포만 학습하여 새로운 이미지를
74.AI_Tech부스트캠프 week20...[5] Recent Applications in Diffusion Models(2)
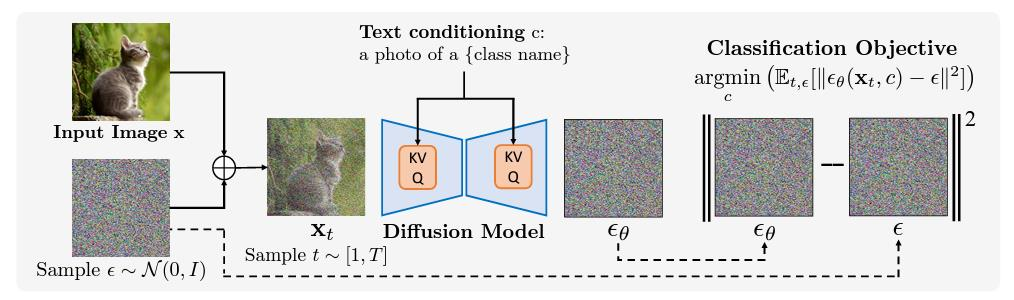
8. Video Generation Video generation involves the model's creation of a new video, with or without specific conditions. Why Video Generation is neces