GPU 관련 필자가 경험한 이슈들
1.[과정0] 서버 GPU 연결 실패...
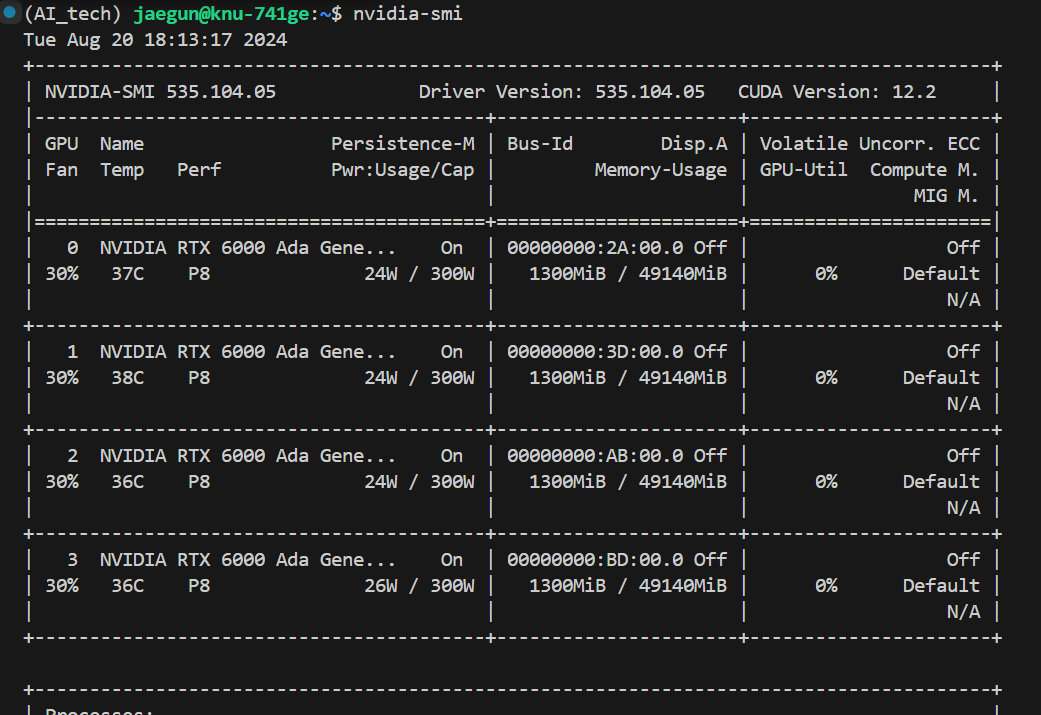
서버 연결 과정은 참으로 까다롭니다.먼저①NDriver 를 설치해야 한다. ② (거기에 맞는)Cuda 도 설치③ (또 거기에 맞는)cuDNN 도 설치해야함근데 여기서 또 함정은 tensorflow 도 버전에 맞게 설치해아함;;nvidia-smi 로 확인.. gpu 확
2.[과정1] 서버 GPU 연결 성공?
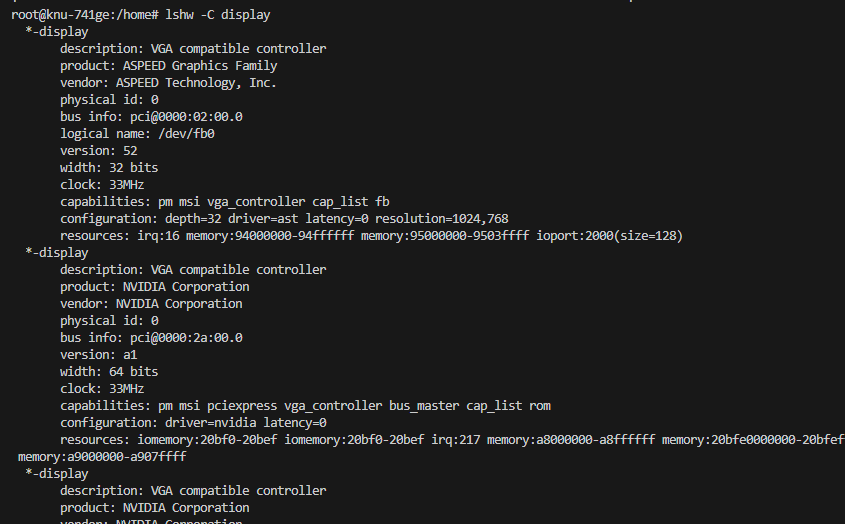
① Cuda 제거② Cuda 파일 삭제여기서 파일 cuda-12.2는 그전에 cuda 를 12.2로 설치해서 그렇다 ㅎㅎlshw: list hardware 로 설치가 GPU 가 정상적으로 설치되었는지 확인해줌.이렇게 VGA ~ 어쩌구 저쩌구 하면 됨!(참고로 VGA는
3.[과정2] 서버 GPU 연결 성공!
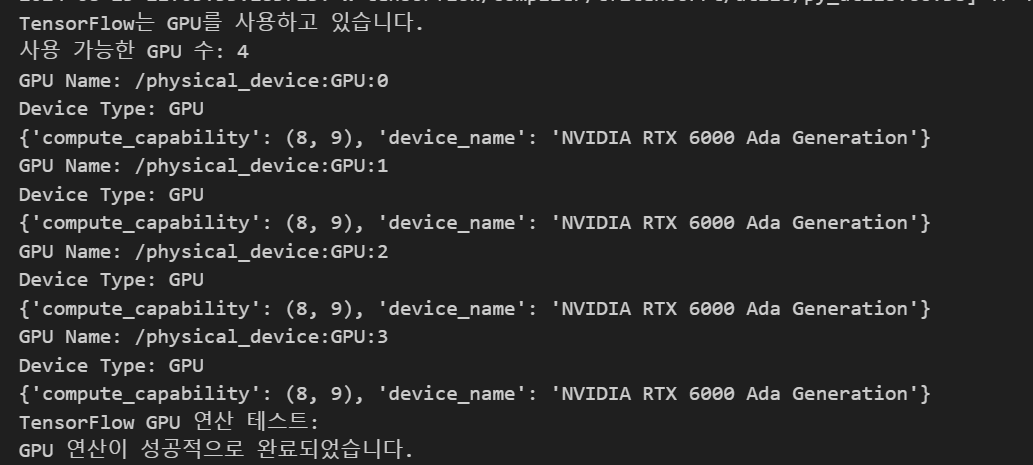
아 진짜 너무너무 힘들었다ㅠㅠㅠㅠ 이게 뭐라고 이렇게 까지 힘들게 만들었을까?? 진짜 tensorflow 는 전설이다(역으로) 순서는 대략 $0.$ 기존에 설치된 ndriver, cuda, cuDNN전부 제거. $1.$ Nvidia Ndriver 를 설치해주어야한다.
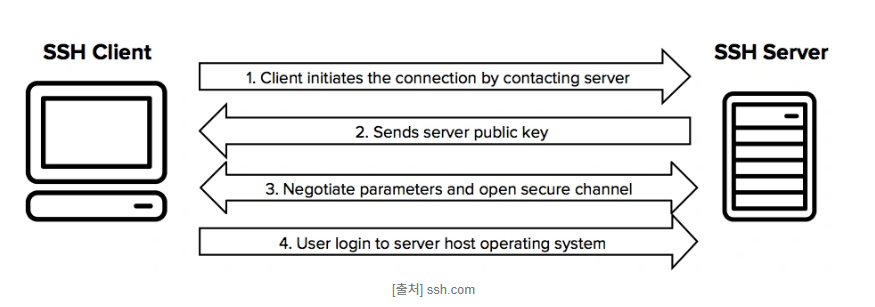
4.서버 연결 자동로그인 방법
서버연결을 자주 하다 보면은 비밀번호를 자주 입력해야 하는데 이게 아\~\~~주 귀찮아서 그냥 빨리 볼 수 있도록 여기에 적어본다.①ssh-keygen은 ssh-key-generation으로 ssh 키 쌍을 생성하는 명령어. ssh는 네트워크를 통한 안전한 통신을 제공
5.모델이 GPU 를 모두 쓰지 않을때...
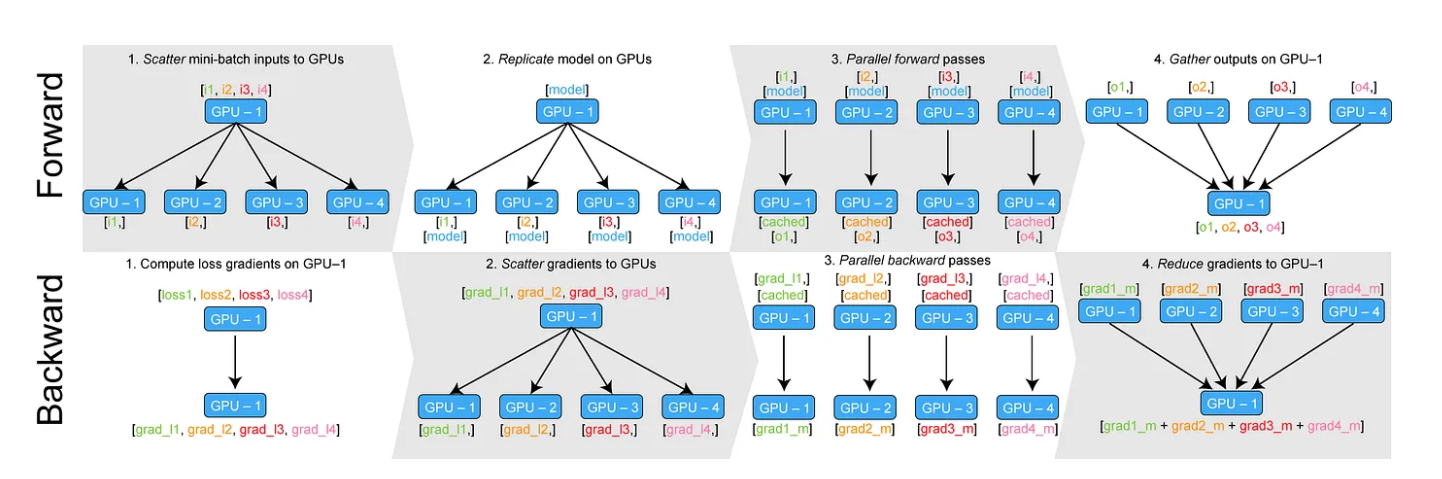
좋은 GPU 가 있어도 왜 쓰지를 못하니... 이럴때는 정말 아이고 頭 야... (연결 겨우 했는데,연결해서 쓰질 않고 있넼ㅋㅋㅋ) https://medium.com/daangn/pytorch-multi-gpu-%ED%95%99%EC%8A%B5-%EC%A0%9C%
6.torch cuda GPU사용중 확인코드

7.GPU 가 이상한 곳에서 너무 많이 할당되어 있을때
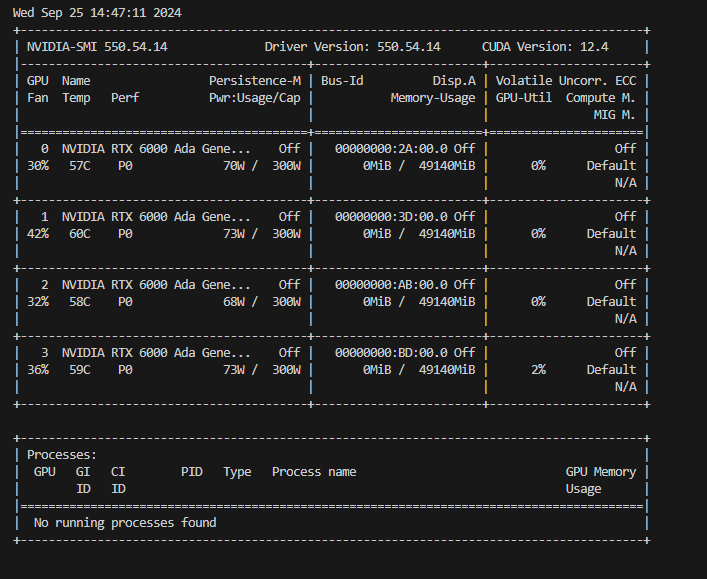
지금 어떠한 코드를 돌아가지 않는데도 불구하고, 계속 이상한 곳에서 코드가 돌아가는 버그 발생.GPU 아래에 보면 PID(Process ID)가 보일 것인데, 여기에 있는 넘버들을 적어주면 됨 만약에, 391829 302103 이렇게 돌아가고 있을때, 터미널에서kill
8.GPU의 PID가 안 보일때
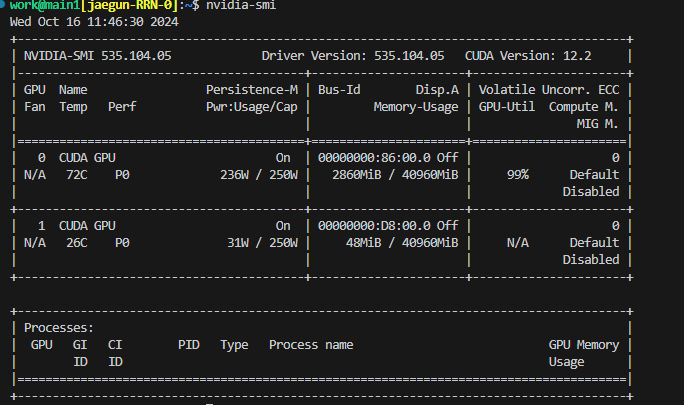
nvidia-smi를 했을 때, 원래 같으면 몇번 PID 가 나와야 하는데 나오지 않을 떄가 있다.ps aux | prep python <- 입력이걸 치면 work 후에 PID가 나와서 kill \[pid] 를 입력해주면 된다.🤔 ps aux | prep py
9.gpu - nvtop 에 대한 설명
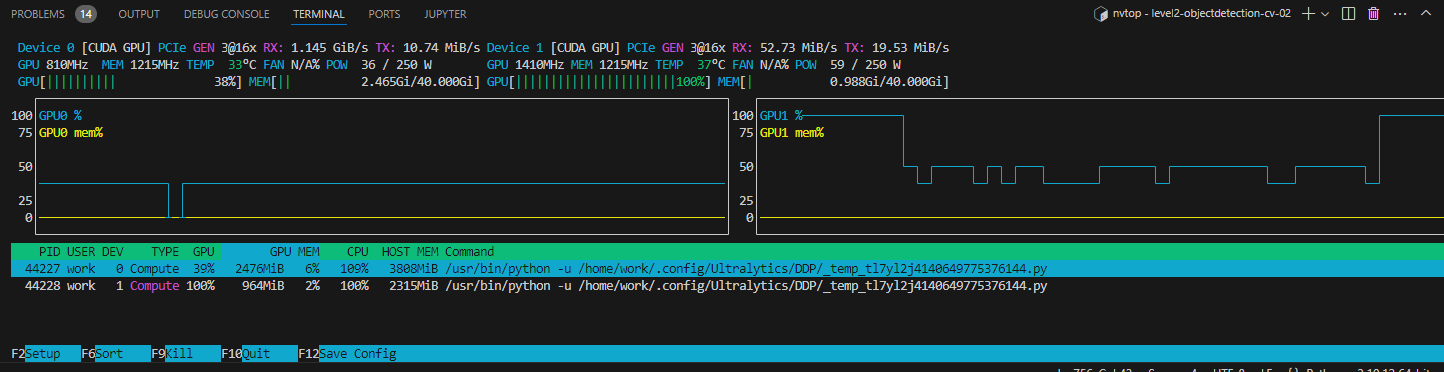
nvtop은 NVIDIA GPU를 실시간으로 모니터링할 수 있는 대화형 도구입니다. htop과 유사한 방식으로, 터미널에서 직관적인 그래픽 UI를 제공하여 GPU의 상태를 한눈에 파악할 수 있다!!이런 식으로 실시간으로 GPU 사용률과 메모리 사용량 모니터링GPU에 연
10.쓸데없는 PID 한번에 종료
ps aux | grep '\_temp_e_sim' | awk '{print $2}' | xargs kill -9각 의미 ① ps aux1.ps약자: "Process Status"의미: 현재 실행 중인 프로세스의 상태를 보여주는 명령어입니다. 시스템에서 실행 중인 프로
11.shm 부족문제
이런 문제가 났다. 이는 shared memory 부족문제이다.이렇게 하면 된다. 참고로 /dev/shm의 공간은 시스템의 물리적 RAM에서 직접 가져오며, 이로 인해 다른 프로세스나 시스템 작업에 사용할 수 있는 RAM 용량이 줄어들게 된다..
12.tmux,.sh에 관하여
내가 쓰는 경북대 서버에서는 .hat/tmux.sh등이 있다. 이에 대해 궁금하고 어떠한 것인지 알고 싶어서 적는다.tmux는 "terminal multiplexer"의 약자이다. 이는 하나의 터미널 창 내에서 여러 가상 터미널을 생성하고 관리할 수 있게 해주는 유틸리
13.[Python 에러] ImportError: module 'cv2.dnn' has no attribute 'DictValue'
attribute 가 사라진건지,, 갑자기 인자가 없다는 말도 안되는? 오류들은 그냥 맞는 버전 찾으면 된다. ㅋㅋㅋ (대충 막노동하면 된다는 이야기)
14.gpu 여러개쓰면 안될떄
GPU가 10개있는 서버가 있어서 6개 정도를 device 에 할당해서 python train.py 했는데 epoch가 전혀 돌아가질 않았다.그런데 device 2개로 할당하면 train이 되면서 epoch가 나온다. 이는 무슨 문제일까? \->이는 NCCL의 문제이다
15.bitsandbytes
모델 로딩 중 에러 발생:→ bitsandbytes 라이브러리에서 .so 파일이 특정 심볼을 못 찾는 심각한 문제 발생.추가적인 오류 메시지:→ GPU는 잘 인식되지만, bitsandbytes에서 CUDA 연동에 실패.python -m bitsandbytes 실행 결과