현재 모델을 돌리고 있는데, 좋은 GPU 4개가 있음에도 불구하고, 시간이 오래 걸리는 겁니다.. 그래서 왜 이러지? 하고 watch -d n 2 nvidia-smi(-d는 diffrence, n 2 는 2초마다, nvidia-smi 봄 ) 를 입력하니까 그냥 답도 없이 하나만 쓰고 있고 심지어 10% 정도만 쓰고 있었음..
이렇게 열 받게 하는건 빨리 고쳐야한다 진짜..
1. 문제점
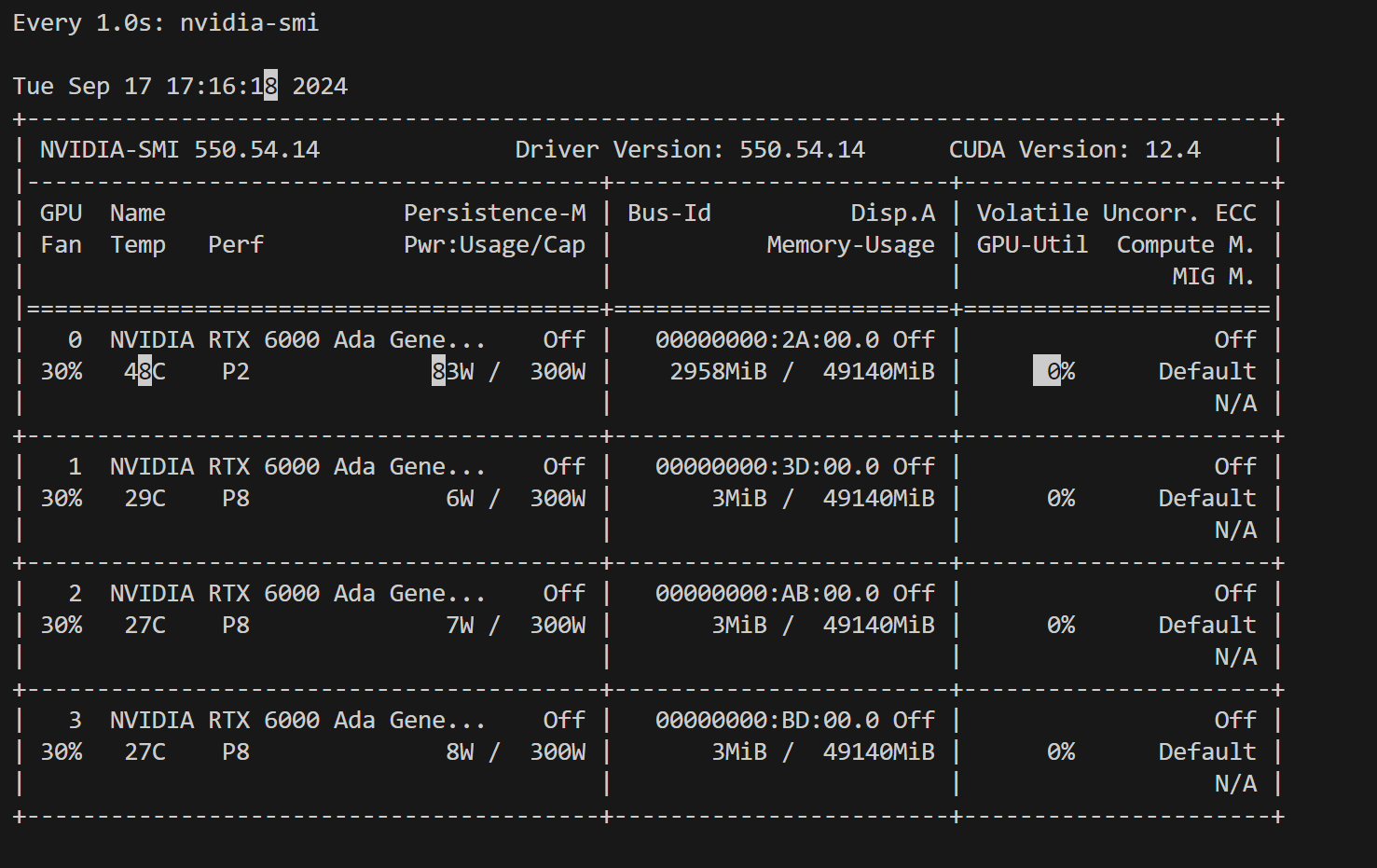
GPU를 하나만 쓰고 있고, 심지어 쓰고 있는 하나도 2~10% 만 쓰고 있는 미친상황 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
좋은 GPU 가 있어도 왜 쓰지를 못하니...
아이고 頭 야...

(연결 겨우 했는데,연결해서 쓰질 않고 있넼ㅋㅋㅋ)
2. 해결방안
2.1 PyTorch Data Parallel 기능 사용하기
Pytorch 에서는 병렬학습을 지원해줍니다 .Multi-GPU 학습을 위한 Data-Parallel이라는 기능 제공.
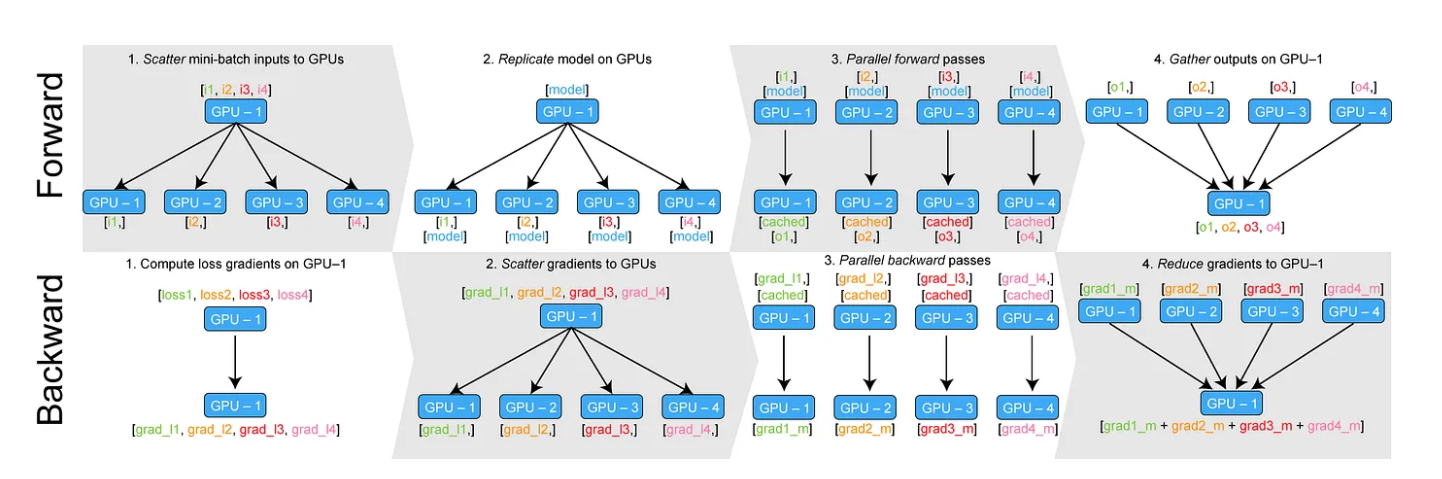
Data Parallel 하는 과정(replicate → scatter → parallel_apply → gather)
① GPU 할당(scatter)
딥러닝을 여러 개의 GPU에서 사용하려면, 일단 모델을 각 GPU에 복사해서 할당해야함.그리고 iteration을 할 때마다 batch를 GPU의 개수만큼 누는데, 이렇게 나누는 과정을 ‘scatter’ 한다고 하며 실제로 Data Parallel에서 scatter 함수를 사용해서 이 작업을 수행!!
② GPU 모음(Gather)
이렇게 입력을 나누고 나면 각 GPU에서 forward 과정을 진행합니다. 각 입력에 대해 모델이 출력을 내보내면 이제 이 출력들을 하나의 GPU로 모읍니다. 이렇게 tensor를 하나의 device로 모으는 것은 ‘gather’ 이라고 합니다.
③ Loss function 계산하기.
보통 딥러닝에서는 모델의 출력과 정답을 비교하는 loss function이 있습니다. Loss function을 통해 loss를 계산하면 back-propagation을 할 수 있습니다. Back-propagation은 각 GPU에서 수행하며 그 결과로 각 GPU에 있던 모델의 gradient를 구할 수 있습니다. 만약 4개의 GPU를 사용한다면 4개의 GPU에 각각 모델이 있고 각 모델은 계산된 gradient를 가지고 있습니다. 이제 모델을 업데이트하기 위해 각 GPU에 있는 gradient를 또 하나의 GPU로 모아서 업데이트를 합니다. 만약 Adam과 같은 optimizer를 사용하고 있다면 gradient로 바로 모델을 업데이트하지 않고 추가 연산을 합니다. 이러한 Data Parallel 기능은 코드 한 줄로 간단히 사용 가능합니다.
🚀 Pytorch Code적용
import torch.nn as nn
model = nn.DataParallel(model) <- 이렇게 한 줄로 가능!그리고 data_parallel의 코드를 자세히 살펴보면 Gather에서 하나의 gpu로 각 모델의 출력을 모아주어서, 하나의 gpu 메모리 사용량이 많을 수 밖에 없다!!
def data_parallel(model, input, decive_ids, output_device):
replicas = nn.parallel.replicate(module, device_ids) # replicate 에서 model을 device_ids에 지정된 각 GPU 에 복사함.
inputs = nn.parallel.scatter(input, device_ids)
replicas = replicas[:len(inputs]
outputs = nn.parallel.parallel_apply(replicas, inputs)
return nn.parallel.gather(outputs, output_device)DataParallel을 사용한다면 코드는 다음과 같이 작성한다.
import torch
import torch.nn as nn
model = BERT(*args)
model = torch.nn.DataParallel(model)
model.cuda()
...
for i, (inputs, labels) in enumerate(trainloader):
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
그런데 이렇게 하면 메모리 불균형을 겪을 수 있음. 따라서 디폴트로 설정되어 있는 GPU번호를 바꿔서 바꾸어서 출력GPU를 다른 곳으로 바꾸면 됨.(메모리 사용은 같은거 아니냐? -> 아니다! 디폴트로 설정되어 있는 GPU 에 gradient 또한 디폴트 GPU 에 모이기 때문에 다른 GPU 에 비해 메모리 사용량이 상당히 많은 상태에서 출력까지 디폴트로 모이니까 하나만 폭발적으로 늘어나는 거임. )
import os
import torch.nn as nn
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"
model = nn.DataParallel(model, output_device =1) #디폴트로 되어 있는 0번에서 1번으로 바꿈.2.2 Custom으로 DataParallel 사용하기
2.2.1 기존 방법 문제점
pytorch Data_Parallel의 메모리 출력을 지정하는 것은 임시방편에 불과하다. 왜냐하면 결국 하나의 GPU 에 모든GPU 출력을 모은 것이기 떄문이다.
🤔 왜 출력을 하나의 GPU 에 모았었나?
👉 왜냐하면, loss function을 계산해야 하기 떄문이다. 모델은 DataParallel을 통해 병렬로 연산하였지만 loss function 은 그대로였기 때문에 하나에 모을 수 밖에 없었다.
따라서, loss function 또한 병렬로 연산하도록 만든다면 해결 가능.
2.2.2 해결방법_이론
👉 loss function 또한 병렬로 연산하도록 만든다면 해결 가능하다고 배웠다.
🤔 그렇다면 어떻게 loss function을 병렬 연산하게 할 수 있을까?
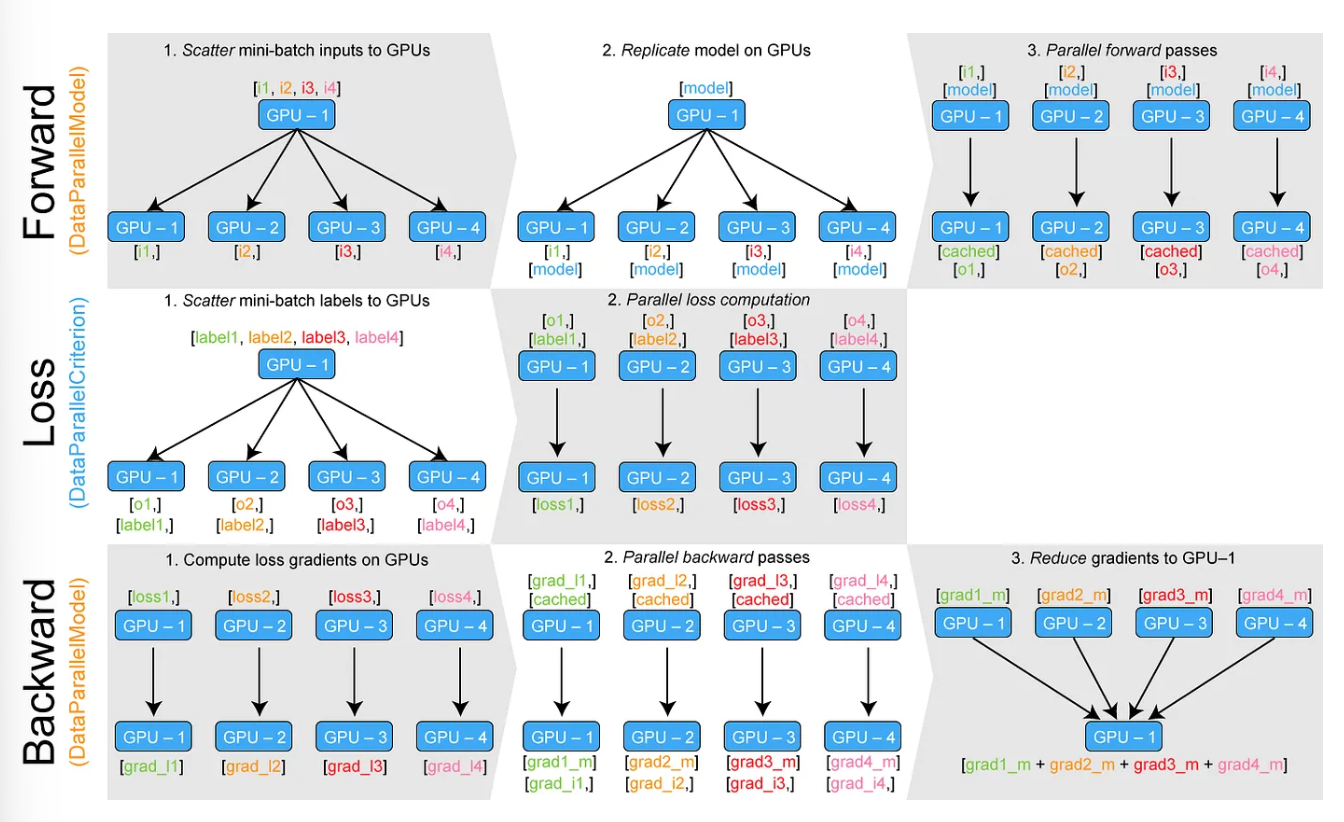
① loss function 모듈을 각 GPU에 replicate
pytorch 에서는 loss function 도 하나의 모듈
② 정답에 해당하는 tensor를 각 GPU 에 scatter
이제 각 GPU 에 loss 를 계산하기 위한 모델의 출력, 정답, loss function을 모두 각 GPU에 연산할 수 있도록 바뀐 상태.
③ 각 GPU 에서 loss 값으로 바로 Backward수행
2.2.3 해결방법_코드
class DataParallelCriterion(DataParallel):
def forward(self, inputs, *targets, **kwargs):
targets, kwargs = self.scatter(targets, kwargs, self.device_ids)
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
targets = tuple(targets_per_gpu[0] for targets_per_gpu in targets)
outputs = _criterion_parallel_apply(replicas, inputs, targets, kwargs)
return Reduce.apply(*outputs) / len(outputs), targets
import torch
import torch.nn as nn
from parallel import DataParallelModel, DataParallelCriterion
model = BERT(args)
model = DataParallelModel(model)
model.cuda()
criterion = nn.NLLLoss()
criterion = DataParallelCriterion(criterion)
...
for i, (inputs, labels) in enumerate(trainloader):
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()2.3 PyTorch에서 Distributed 패키지 사용하기
2.3.1 기존 방법 문제점
2.3.2 해결방법_이론
2.3.3 해결방법_코드
3. ⭐해결⭐
3.1 nn.DataParallel 사용
3.1.1 문제 발생(1)
바로 문제 발생함 ^^(역시 바로 되면 이상하지!)
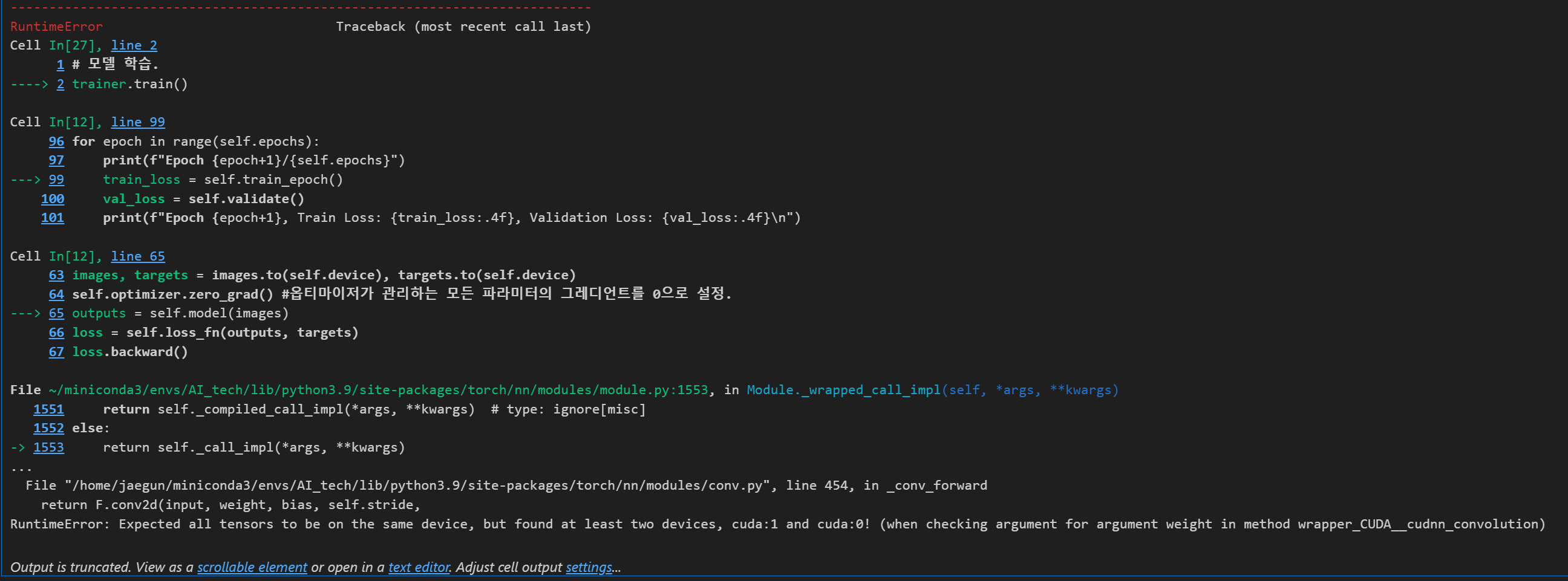
오류 메세지는 RuntimeError로
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument weight in method wrapper_CUDA__cudnn_convolution)
이런 식으로 왔는데 , 결국 모든 tensor가 같은 device에 있길 원하는데 적어도 2개 device에서 발견했다는 의미
아니 4개 있으니까 당연히 2개 이상 발견해야지 ^^!! (이걸 죽여 말어)
3.1.2 문제 해결(1)
코드를
import os
import torch
import torch.nn as nn
# GPU 사용 가능 여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 사용할 GPU 지정
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"
# 모델 정의 (여기서는 생략)
model = YourModel()
# 모델을 지정된 디바이스로 이동
model = model.to(device)
# DataParallel로 모델 래핑
# model = nn.DataParallel(model, output_device=1)
model = nn.DataParallel(model)output_device를 빠로 설정하기 않고, 모델을 설정하고 device에 이동하고 그 다음에 nn.DataParallel(model)하니까 병렬적으로 사용한다.
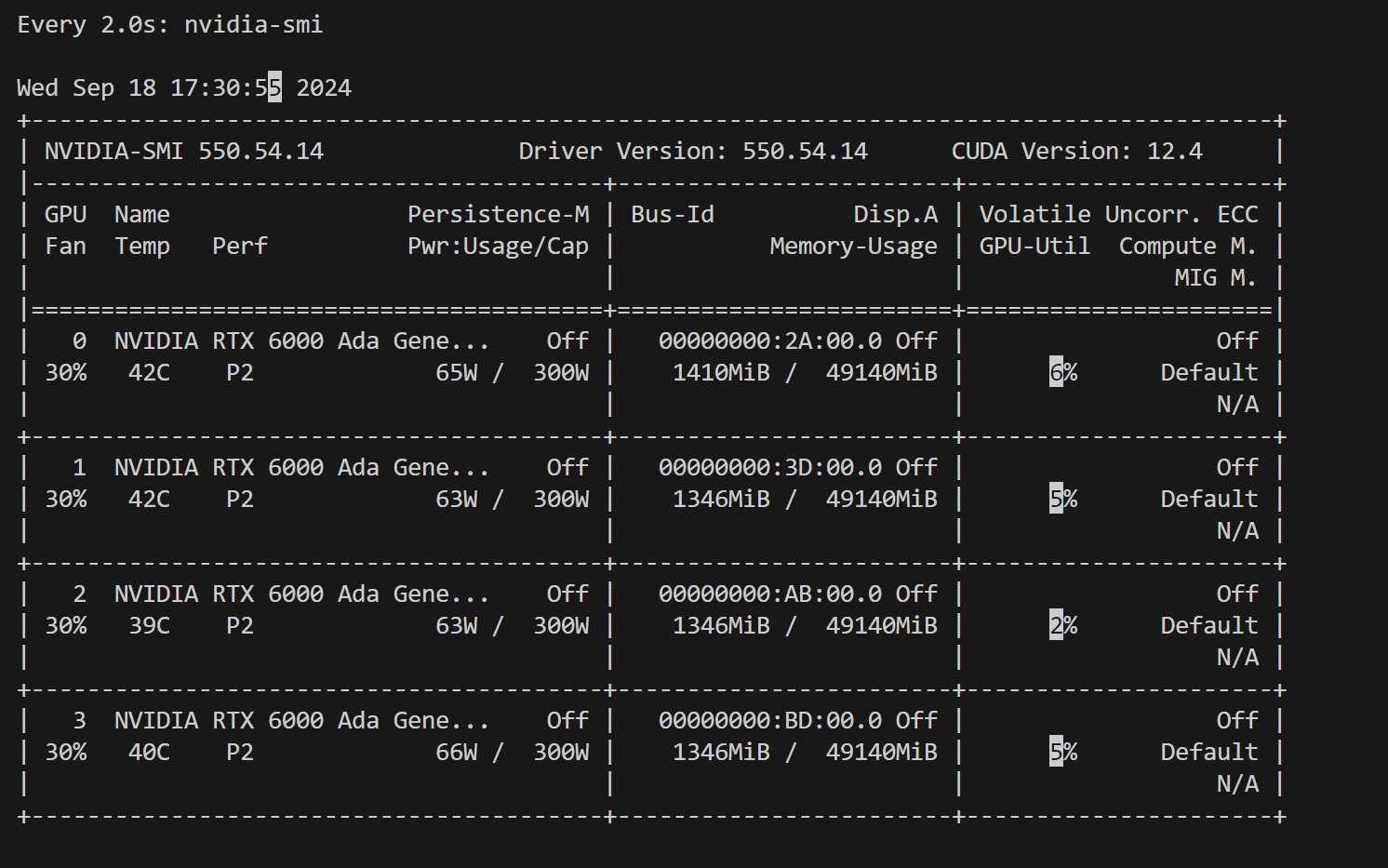
근데.. 2~7% 정도만 사용함^^ 아오 ...메모리고 뭐고 아예 사용을 잘 안 하노...
계속 100% 쓰는 방법을 알아봐야지..
3.1.3 문제 발생(2)
문제점 : GPU 가 2~10 % 만 쓰고 있는 미친상황... 그래서 data_loader에 batch_size와 num_workers를 max 로 끌어올렸다.
3.1.4 문제 해결(2)
- batch_size :
train_loader에서의batch_size를 다르게 함. - num_workers : num_workers는 데이터 로딩을 병렬로 처리하기 위해 사용하는 CPU subprocess의 수를 결정함 -> 본인의 CPU 정보를
lscpu를 통해 살펴볼 수 있고 서버에 cpu 가 코어 16 스레드 32 길래 그냥 max로 32 넣었음.
batch_size를 256 했을때
-> 대략 각 GPU 마다 30% 씩 쓴다.
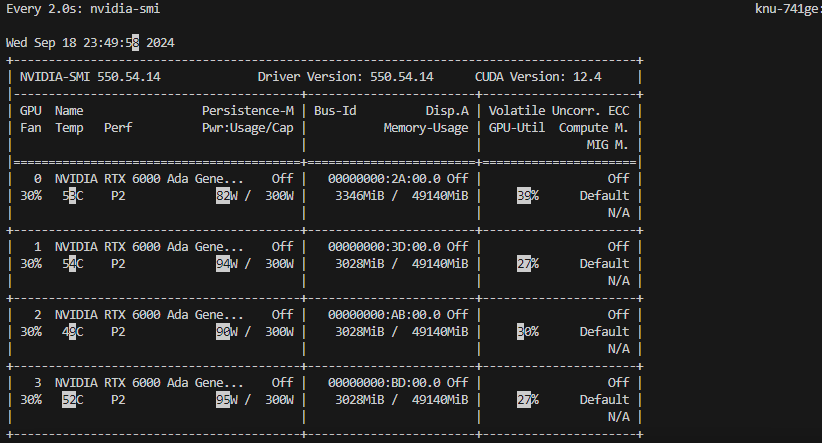
batch_size를 512 했을때
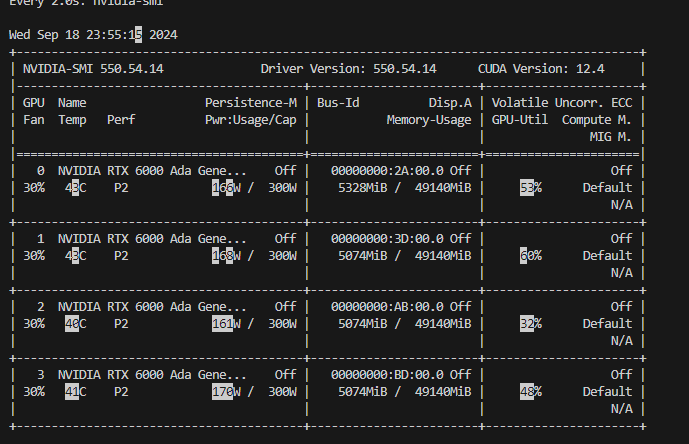
각 GPU를 50~60 % 씩 쓴다.

앙 기모찡~~ 해결 했오~~~!!

짤방 활용이 찰떡같네요 ^-^