🧢이번글에 대한 소개
- 이번 글 에서는 Language Models are Unsupervised Multitask Learners 논문을 리뷰하고자 합니다.
🧢GPT2
1. Introduction
-
우리는 좀 더 General한 모델을 원한다.
-
대량의 데이터셋으로 사전 훈련한 뒤 테스크게 맞게 지도 학습하는 머신러닝 방법이 좋은 성능을 내고 있다. 하지만, 이런 시스템은 데이터의 분포와 테스크의 특징의 변화에 따라서 민감하게 반응한다. 즉, 데이터의 분포와 테스크에 따라서 변형이 필요하다.
-
본 논문에서는 다양한 테스크에서 좋은 성능을 낼 수 있는 더 General System을 만들기 원하고, 최종적으로는 추가적인 지도학습이 필요 없는 모델을 만들기를 희망한다.
-
-
Specialist를 만들고 있는 작금의 현실이 Generalist를 만들지 못하고 있는 게 아닐까?
-
기존의 ML 시스템(지도학습)의 접근 방식은 구체적으로 정의된 테스크에 대해서 좋은 성능을 내고 있지만 "Captioning", "Reading comprehension", "Image Classifiers"과 같이 다양한(diversity and variety)한 입력이 주어지는 상황에서 어려움을 겪고 있다.
-
본 논문에서는, 하나의 모델을 하나의 도메인 하나의 테스크에 맞춰 학습하고 있는 지금의 연구 상황이 Gerneralization Observe의 가장 큰 걸림돌이라고 생각한다.
-
현재, GLUE, decaNLP등 자연어 이해 모델에서 범용적으로 사용되고 있는 벤치마크 지표가 제안되고 있다.
-
- Generalist를 만드는 방안들 Multitask learning, Meta-Learning
-
그림 출처 : https://gaussian37.github.io/dl-concept-mtl/
-
Multitask Learning and Meta Learning
Multitask Learning: 같은 network를 공유하는 모델을 사용해 여러 테스크를 동시에 학습하는 방법. 테스크 간의 loss의 가중치를 조절하는 것이 중요하다.Meta Learning: 다른 Task를 위해 학습된 AI 모델을 이용해서, 적은 데이터셋을 가진 다른 Task도 잘 수행할 수 있도록 학습시키는 방법.
-
Multitask learning은 general performance를 향상시키는 좋은 방법이다. 하지만, NLP 분야에서는 아직 연구가 부족하다. Meta-Learning도 결국은 하나의 테스크에 맞게 학습된 모델이다. 현재의 ML system에서 잘 일반화된 모델을 만들기 위해서 수백 ~ 수천개의 훈련 데이터가 필요하다. 이는, Multitask 훈련 과정에서 각 훈련 테스크에 맞게 데이터가 필요하다는 의미가 된다.
-
이러한 이유로 본 논문에서는 Multitask Learning을 위한 추가적인 방안을 찾는다.
-
- Best Performance System : Pre-training and Supervised Fine Tuning
- 현재 NLP 테스크에서 가장 좋은 성능을 보여주고 있는 System은 Pre-training과 Supervised Fine Tuning으로 이루어진 조합이다. 이런 system은 transfer 과정을 더 유연하게 하도록 발전하고 있다. 최근 연구(BERT)에 따르면 전이 훈련 과정은 많은 self-attention 구조로만 충분하며 추가적인 테스크에 부합하는 transfer architecture가 필요 없다. 하지만, 이런 방법들도 여전히 테스크에 부합하는 지도학습이 필요하다.
- Zero-shot setting에서 좋은 성과를 내는 모델을 만들었다.
- 본 논문에서는 어떠한 파라미터 튜닝과 모델 변형 없이 Zero-shot 환경에서 좋은 성능을 내는 모델을 만들었다.
2. Approach
-
Self-Attention을 활용하여 언어의 결합 확률 분포를 잘 학습할 수 있다.
-
우리의 접근 방식의 핵심은 Language Modeling이다. 언어는 본연의 연속성과 순서를 가지고 있기 때문에 조건부 확률의 곱으로서 결합 확률을 분해(factorize)될 수 있다.
-
이러한 접근은 뿐만 아니라, 어떤 조건부 형태 에서 샘플링과 추정을 가능하게 한다. 최근 연구에 따르면, Transformer와 같은 self-attention 구조를 활용하여 이러한 조건부 확률 분포를 잘 계산할 수 있게 되었다.
-
-
General System을 위한 확률 모델링 :
-
하나의 테스크를 학습하는 과정은 확률의 관점에서 라는 조건부 확률로 표현할 수 있다. 하지만, General System은 같은 input에 대해서 다양한 테스크에서 성능을 낼 수 있어야 하기 때문에, 와 같이 모델링 되어야 한다. 일반적으로 task를 조건으로서 넣기 위해서는 모델의 구조 단계(task specific encoder and decoder), 알고리즘 단계(inner and outer loop optimization framework)에서 설계를 해준다.
-
하지만, 자연어 처리에서는 task와 input, output을 순서대로 연결하여 사용함으로서 더 유연하게 테스크에 대한 조건을 넣어줄 수 있다.
- 번역 과제 :
(translate to french, english text, french text) - QA 과제 :
(answer the question, document, question, answer)
- 번역 과제 :
-
-
대용량 언어모델은 자연어 시퀀스 내에서 테스크를 추론할 수 있을 것이다.
-
언어 모델링은 원칙적으로 테스크를 지도학습 없이 학습할 수 있다. Weston(2016)은 대화의 맥락에서 자연어를 직접 학습할 수 있는 시스템을 개발해야 한다고 주장했고 질문에 대한 Answer를 생성하며 보상 신호 없이 QA 테스크를 학습한 증거를 제시했다.
-
본 논문에서는 충분한 용량의 언어 모델이 자연어 시퀀스 데이터 내에서 더 좋은 예측을 하기 위해 테스크를 추론할 수 있을 것이라고 생각한다. 이것이 가능하다면 결국 비지도 multitask learning이 가능할 것이다.
-
2.1 Training Dataset
-
기존의 낮은 퀄리티의 데이터셋을 사용하지 않고 인간에 의해 검증된 데이터셋을 사용했다.
-
본 논문에서는 다양하고 대량의 데이터셋을 사용하여 여러 도메인 그리고 문맥 안에서 발생하는 테스크의 언어 표현을 확보하고자 했다. Web scraping을 통해 수집된 Common Crawl 데이터셋는 대량의 데이터셋 이지만 대부분의 내용이 '이해하기 어려운' 내용들이 많다는 문제 제기가 있었다. 본 연구에서 Common Crawl을 활용한 초기 연구에서도 같은 문제를 나타냈다.
-
문서의 질을 높이기 위해서 Reddit, Social media platform에서 높은 평점을 받은 페이지의 문서를 확보하였다. 이를 통해 WebText 데이터셋을 구성하였고, 총 4천 5백만 개의 링크의 텍스트 데이터를 확보하였다. 2017년 12월 이전의 데이터셋을 사용하였고 문서의 중복을 제거했으며 Heuristic based cleaning을 적용하여 총 8백만개의 문서와 40GB의 텍스트를 확보하였다. 또한, 대부분의 문서에 기반이 되는 Wikipedia 문서는 포함하지 않았다.
-
2.2 Input Representation
- BPE를 사용하여 모든 데이터셋에서 사용할 수 있는 언어 모델을 만들었다.
- 현대 대규모 언어 모델에는 대소문자 변환, 토큰화, 어휘에 없는 토큰 처리와 같은 전처리 단계가 포함되어 있어 모델이 사용할 수 있는 단어의 종류를 제한하는 문제가 있다. Unicode의 문자열("word")을 UTF-8 바이트의 시퀀스("w", "o", "r", "d")로 처리하면 이러한 문제를 해결할 수 있지만 대규모 언어 모델에서 byte-level 언어모델은 word-level 언어 모델에 비해 좋은 성능을 내지 못하고 있다.
- 문자 수준과 단어 수준의 실용적인 중간지점인 BPE(Byte Pair Encoding)을 적용하였다. BPE는 빈도 기반 휴리스틱 알고리즘을 사용하기 때문에 같은 "dog"에 대해서도 "dog!", "dog?"등의 다양한 형태의 단어가 생성되는 문제가 있다. 이를 피하기 위해 BPE가 문자 범주를 넘어서 병합하지 못하도록 했다. 추가로, 공백에 대한 예외를 적용하여 압축 효율을 향상시켰다.
- 이러한 방법은 모든 Unicode 문자열에 확률값을 할당할 수 있기 때문에, 전처리, 토큰화 또는 언어의 크기에 상관없이 어떤 데이터셋에서든 언어 모델을 평가할 수 있다.
- 현대 대규모 언어 모델에는 대소문자 변환, 토큰화, 어휘에 없는 토큰 처리와 같은 전처리 단계가 포함되어 있어 모델이 사용할 수 있는 단어의 종류를 제한하는 문제가 있다. Unicode의 문자열("word")을 UTF-8 바이트의 시퀀스("w", "o", "r", "d")로 처리하면 이러한 문제를 해결할 수 있지만 대규모 언어 모델에서 byte-level 언어모델은 word-level 언어 모델에 비해 좋은 성능을 내지 못하고 있다.
2.3 Model
- GPT2는 GPT1 모델에 약간의 변형을 했다
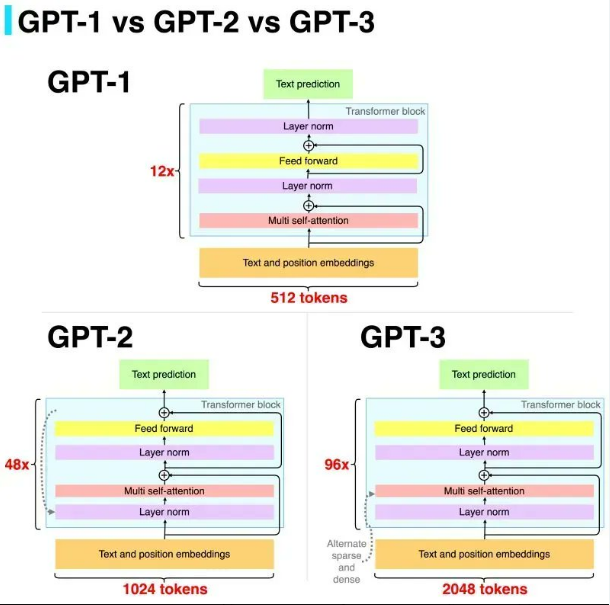
- 출처 : https://twitter.com/kenovy_it/status/1624797983328854016
- Transformer 기반의 구조를 사용했고 GPT1 모델에 약간의 변형을 하였다.
- Layer Normalization을 sub-block 입력 후에서 입력 전으로 배치하였고, 마지막 self attention block 이후 layer normalization을 추가했다.
- Residual layer의 가중치를 (
N:number of residual layers)으로 초기화했다. - 단어의 사이즈는 50,257개 였고, 입력 문장을 512 토큰에서 1024 토큰으로 증가시켰다. Batch size도 512로 더 크게 사용했다.
3. Experiments
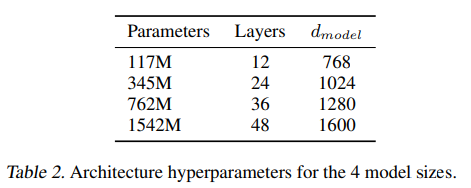
- 4개의 언어모델을 만들어서 테스트를 진행했다.
117M: GPT1과 같은 크기345M: BERT와 같은 크기1542M:GPT2
3.1 Language Modeling
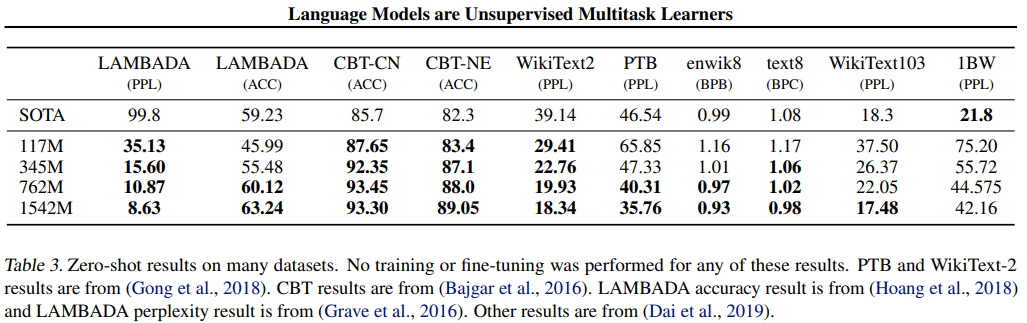
- Zero-shot 상황에서도 좋은 성능을 냈다.
- PPL(Perplexity) : 텍스트 생성 언어 모델의 성능 평가지표(헷갈리는 정도). 낮을수록 좋음.
- BPC(bits-per-character) : 압축 방법의 성능을 측정. 좋은 성능의 모델은 문자를 정확하게 예측하여 bit squence가 짧아지기 때문에 문자당 총 비트 수가 낮다. 낮을수록 좋음.
- BPB(bits per byte) : word LM은 단어당 PPL을 기준으로 결과를 기록하지만, byte LM은 BPB로 결과를 기록한다. 낮을수록 좋음.
- 어떠한 훈련, fine-tuning이 없는, Zero-shot 상황에서도 8개 중7개의 데이터셋에 대해서 SOTA를 달성하며 여러 domain, dataset에 대해서 잘 전이되는 것을 알 수 있었다. Byte level로 처리되었기 때문에 target task에 대해서 추가 전처리와 토큰화가 필요하지 않다.
- 주목할만한 성과
- Zero-shot 상황에서도 8개 중7개의 데이터셋에 대해서 SOTA를 달성.
- PTB(Penn Treebank), WikiText-2와 같은 작은 데이터셋에서도 좋은 성능을 보임
- LAMBDA, CBT(Children's Book Test)와 같이 긴 문장의 데이터셋에서도 좋은 성능을 보임.
- 좋지 않은 부분
- 1BW(One Billion Word Benchmark)에서는 기존의 연구보다 크게 안 좋은 성과를 내었는데 이는 데이터셋이 엄청 크고, 문장 단위의 shuffling이 긴 문장 구조를 제거했기 때문이라고 생각한다.
3.2 Chidren's Book Test
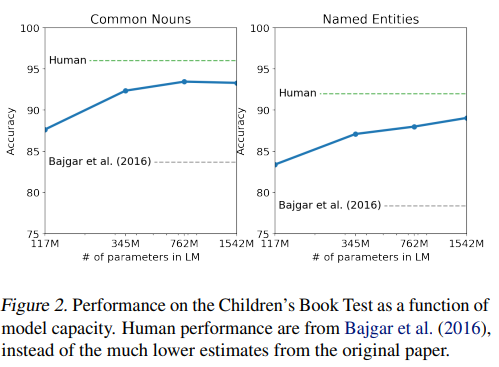
- CBT는 언어모델이 단어를 잘 분류(개체명 인식, 명사, 동사, 전치사) 할 수 있는지 테스트.
- 모델의 크기가 커질 수록 사람의 능력과 갭을 점점 줄여나가고 있다.
3.3 LAMBDA
- LAMBDA 데이터셋은 언어 모델이 긴 문장(long-range depenency)을 잘 이해하는지를 테스트. 최소 50개 이상의 토큰으로 구성된 문장의 마지막 단어를 예측하는 방식으로 진행된다.
- GPT-2는 LAMBDA 데이터셋에서 SOTA를 달성했다.
- LAMBDA 테스트에서 틀린 부분을 살펴봤는데 문장의 마지막 단어로는 유효하지 않았지만, 문장의 연속성인 부분에서는 유효했다. 이를 통해 GTP2가 "이 단어가 마지막 단어야"라는 유용한 추가 제약을 적용하고 있지 않다는 것을 알 수 있었다.
- Stop-word 필터를 추가했을 때 현 SOTA에서 4%가 높은 63.24%의 정확도를 기록하였다.
3.4 Winograd Schema Challenge
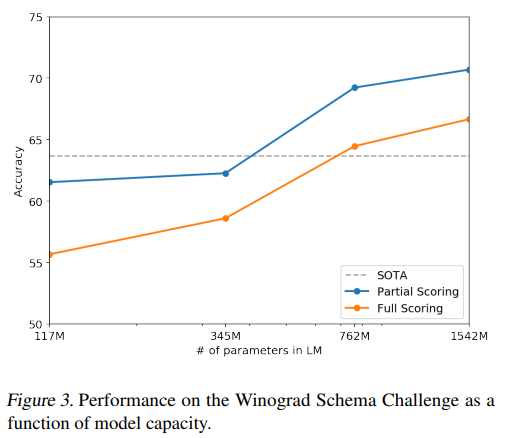
- Winograd Schema challenge는 commonsense reasoning(상식적 추론)을 얼마나 잘 수행하는가를 테스트함.
- GPT2는 부분점수, 총점수에서 모두 SOTA를 달성했다.
3.5 Reading Comprehension
- CoQA(Conversation Question Answering) 데이터셋은 7개의 서로 다른 도메인의 질의 응답 대화로 이루어져있다. CoQA 테스트는 대화에 기반해서 질문에 대한 대답을 잘 하는지 여부를 테스트한다.
- 대화 내용 마지막에 token
A:를 추가해서 인코딩했다. - 어떠한 추가적인 데이터 학습 없이 55 F1 score를 달성했고 기존의 언어모델들의 3/4보다 좋은 성과를 내었다는 점이 흥미롭다. 현재 SOTA는 지도 학습을 추가한 BERT 베이스의 모델이며 89 F1 score를 달성하며 인간과 같은 성능을 내고 있다.
3.6 Summarization
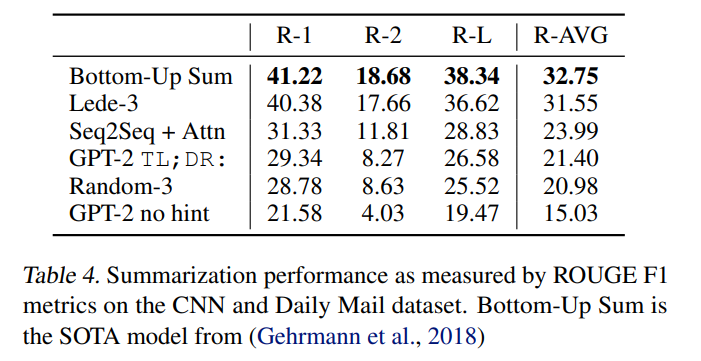
- CNN, Daily Mail 데이터셋을 통해 요약 성능을 테스트했다. 요약 테스크임을 알리기 위해
TL;DR:라는 텍스트를 추가했다.

- Summary 결과를 보면 문서의 최근 내용에 집중하는 경향이 있으며, 구체적인 디테일을 혼동하는 경우가 많았다. 또한, R-AVG 지표에서 질의응답 힌트
TL;DR:를 제거하면 점수가 6.4가 떨어졌다.
3.7 Translation
-
GPT-2의 번역 성능을 테스트했다. 테스크를 인식시키기 위해
english sentence = french sentence의 구조라는 조건을 사용했다.english sentence =이후 greed decoding으로 생성되는 첫 번째 문장을 번역 문장으로 사용하였다. -
WMT-14 English-French 테스트셋 5 BLEU로 좋지 않은 성능을 보였지만 WMT-14 French-English에서는 11.5 BLEU를 달성하며 몇몇의 비지도학습 모델보다 좋은 성능을 보여주었다. 하지만, 현재 가장 좋은 성능의 비지도학습 모델의 점수( 33.5 BLEU)에는 많이 미치지 못한다.
-
그럼에도 불구하고 이 결과가 흥미로운 이유는 WebText 데이터셋을 확보하는 과정에서 영어 이외의 페이지를 고의로 제거하여 프랑스 언어 데이터를 10MB밖에 확보하지 못했는데 어느정도 성과가 났다는 점이다.
3.8 Question Answering
-
Factoid-style의 질문에 대해서 얼마나 자주 정답을 대답하는지를 측정하여 언어 모델이 어떤 정보를 포함하고 있는지 테스트 해볼 수 있다.
-
GPT2는 질문들에 대해서 4.1% 정답률을 기록했고 이는 가장 작은 모델(GPT1)에 비해 5.3배였다. 이를 통해 QA 테스크에서 모델의 용량이 중요한 요소임을 알 수 있다.
4 Generalization vs Memorization
- 컴퓨터 비전 연구에서 발견된 바에 따르면, 일반적인 이미지 데이터셋에는 중복된 이미지가 많아서(CIFAR : 3.3%) 모델의 일반화 능력이 과대 보고될 수 있다. 이런 문제는 WebText에서도 발생할 가능성이 있기 때문에 테스트 데이터가 훈련 데이터에 얼마나 포함되어 있는지 분석이 필요하다.
- 8-gram을 포함하는 Bloom필터를 사용하여 WebText 훈련 세트의 중복을 조사했다. 문자열을 소문자 알파벳 단어와 구분자로 정규화하여 거짓 양성 비율(Recall)을 조절했다.
- 일반적은 LM 데이터셋은 WebText 훈련 세트와 1-6%정도 겹치는 것을 파악할 수 있었다.
- WebText 훈련 데이터와 특정 평가 데이터간 중복은 결과에 작지만 일관된 이점을 제공한다. 그러나 대부분의 기존 데이터셋에서 발견된 훈련 및 테스트 세트 간의 중복과 큰 차이가 없었다.
5. Conclusion
- 거대 언어 모델이 충분히 크고 다양한 데이터셋에서 훈련되면 많은 도메인 및 데이터셋에서 우수한 성능을 발휘할 수 있다. GPT-2는 8개의 데이터셋 중 7개에서 제로샷으로 SOTA를 달성했다. 위 실험들은 비지도 학습으로 훈련한 대용량 언어 모델이 추가적인 지도학습 없이 다양한 작업을 수행하는 방법을 학습하기 시작했다는 것을 시사한다.
