✏️1. 논문을 읽게 된 배경
- 네이버 부스트캠프 AI-Tech에서 RE(Relation Extraction) 문제를 해결하는 대회를 주최했습니다. RE 테스크는 예를 들어 "이순신은 조선 중기의 무신이다."라는 문장과 문장 내 두 단어(이순신, 무신)이 주어질 때 두 단어 사이의 관계를 추론하는 문제입니다.
-
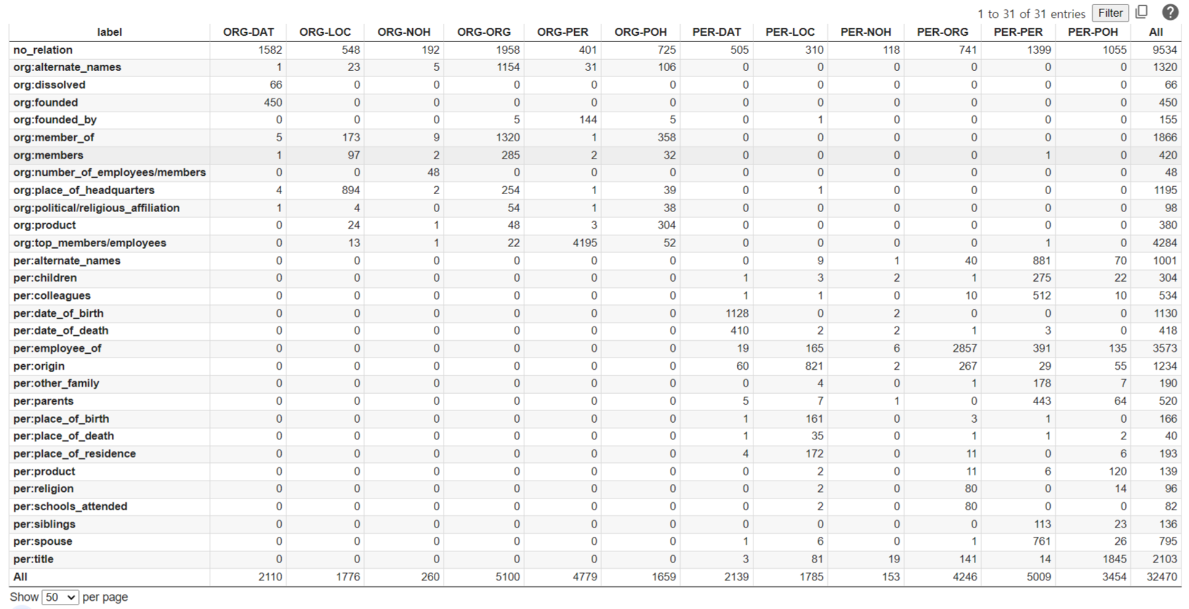
주어진 데이터를 활용하여, subject entity와 object entity type의 type set별로 label이 어떻게 분포하는지 분석하였습니다. 이를 통해 entity들의 type으로 추론할 수 있는 라벨을 한정지어 볼 수 있었습니다. 이를 통해 entity type을 입력 데이터에 추가한다면 성능 향상을 이뤄낼 수 있을 것이라고 생각했습니다.
-
paper with code에서 RE와 관련된 논문을 찾던 중
An Improved Baseline for Sentence-level Relation Extraction논문이 관련 내용을 연구했다는 것을 알게되어 이를 구현하였습니다.
✏️2. 논문 내용 요약

An Improved Baseline for Sentence-level Relation Extraction에서는 Typed entity marker (punct) 라는 기법을 제시합니다. 이 기법은 새로운 speical token을 추가하지 않고 입력 문장에 entity의 범위와 type을 넣어 줌으로서 당시에 SOTA를 달성했습니다.
✏️3. 코드 구현 및 결과 확인
- 주어진 데이터에서 어떤 marker 방식이 더 좋은 성능을 내는지 확인하기 위해
Entity mask,Entity marker,Entity marker punct,Typed entity marker,Typed entity marker pucnt를 구현했습니다. 또한, marker 적용 전 Prompt 부분이 있어서 Prompt에도 marker가 일관적으로 적용될 수 있도록 구현했습니다.
3.1 Marker Class 구현
import pandas as pd
from typing import List
from ast import literal_eval
from tqdm import tqdm
class Marker:
"""dataset 내의 `sentence`를 전처리하는 class"""
def make_sentence(self, sentence, sub_e_info, sub_e_marker, obj_e_info, obj_e_marker, add_question, and_marker):
""" 주어진 문장, entity, marker를 활용하여 새로운 sentence를 생성하는 메서드"""
# Sentence : ... [object_entity] ... [subject_entity] ...
if sub_e_info['end_idx'] > obj_e_info['end_idx']:
sentence = sentence[:obj_e_info['start_idx']] + obj_e_marker + sentence[obj_e_info['end_idx']+1 :sub_e_info['start_idx']] + sub_e_marker + sentence[sub_e_info['end_idx']+1 :]
# Sentence : ... [subject_entity] ... [object_entity]
else:
sentence = sentence[:sub_e_info['start_idx']] + sub_e_marker + sentence[sub_e_info['end_idx']+1 :obj_e_info['start_idx']] + obj_e_marker + sentence[obj_e_info['end_idx']+1 :]
# 뒤에 붙는 Prompt : Question
if add_question:
sentence += f" [SEP] {sub_e_marker} {and_marker} {obj_e_marker}의 관계는 무엇입니까?"
return sentence
def baseline_preprocessor(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : 이순신은 조선의 무신이다.
Question : 이순신은 조선의 무신이다. [SEP] 이순신 와 무신의 관계는 무엇입니까?
"""
change_sentences = []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - no marker working ...!!'):
sub_e, obj_e = literal_eval(dataset['subject_entity'][i])['word'], literal_eval(dataset['object_entity'][i])['word']
sentence = dataset['sentence'][i]
if add_question:
sentence += f" [SEP] {sub_e} {and_marker} {obj_e}의 관계는 무엇입니까?"
change_sentences.append(sentence)
return change_sentences, tokenizer
def entity_mask(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : [SUB-PER]은 조선의 [OBJ-JOB] 이다.
Question : [SUB-PER]은 조선의 [OBJ-JOB] 이다. [SEP] [SUB-PER] 와 [OBJ-JOB]의 관계는 무엇입니까?
"""
new_token, change_sentences = set(), []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - entity mask working ...!!'):
sub_e_info, obj_e_info = literal_eval(dataset['subject_entity'][i]), literal_eval(dataset['object_entity'][i])
sub_e_mask, obj_e_mask = f"[SUBJ-{sub_e_info['type'].upper()}]", f"[OBJ-{obj_e_info['type'].upper()}]"
sentence = dataset['sentence'][i]
# new sentence 생성
sentence = self.make_sentence(sentence, sub_e_info, sub_e_mask, obj_e_info, obj_e_mask, add_question, and_marker)
change_sentences.append(sentence)
# 신규 토큰 추가.
new_token.add(sub_e_mask)
new_token.add(obj_e_mask)
add_tokens = new_token - set(tokenizer.vocab.keys())
print(f'Added New Token Cnt : {len(add_tokens)} List : {add_tokens}')
special_tokens_dict = {'additional_special_tokens': sorted(list(new_token))}
tokenizer.add_special_tokens(special_tokens_dict)
return change_sentences, tokenizer
def entity_marker(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : [E1] 이순신 [/E1]은 조선의 [E2] 무신 [/E2]이다.
Question : [E1] 이순신 [/E1]은 조선의 [E2] 무신 [/E2]이다. [SEP] [E1] 이순신 [/E1] 와 [E2] 무신 [/E2]의 관계는 무엇입니까?
"""
new_token, change_sentences = set(['[E1]', '[/E1]', '[E2]', '[/E2]']), []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - entity marker working ...!!'):
sub_e_info, obj_e_info = literal_eval(dataset['subject_entity'][i]), literal_eval(dataset['object_entity'][i])
sub_e_marker, obj_e_marker = f"[E1] {sub_e_info['word']} [/E1]", f"[E2] {obj_e_info['word']} [/E2]"
sentence = dataset['sentence'][i]
# new sentence 생성
sentence = self.make_sentence(sentence, sub_e_info, sub_e_marker, obj_e_info, obj_e_marker, add_question, and_marker)
change_sentences.append(sentence)
# token 추가
print(f'Added New Token Cnt : {len(new_token)} List : {new_token}')
special_tokens_dict = {'additional_special_tokens': sorted(list(new_token))}
tokenizer.add_special_tokens(special_tokens_dict)
return change_sentences, tokenizer
def entity_marker_punct(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : @ 이순신 @ 은 조선의 # 무신 # 이다.
Qestion : @ 이순신 @ 은 조선의 # 무신 # 이다. [SEP] @ 이순신 @ 와 # 무신 #의 관계는 무엇입니까?
"""
new_token, change_sentences = set(['@', '#']), []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - entity marker punct working ...!!'):
sub_e_info, obj_e_info = literal_eval(dataset['subject_entity'][i]), literal_eval(dataset['object_entity'][i])
sub_e_marker, obj_e_marker = f"@ {sub_e_info['word']} @", f"# {obj_e_info['word']} #"
sentence = dataset['sentence'][i]
# new sentence 생성
sentence = self.make_sentence(sentence, sub_e_info, sub_e_marker, obj_e_info, obj_e_marker, add_question, and_marker)
change_sentences.append(sentence)
# token 추가
add_tokens = new_token - set(tokenizer.vocab.keys())
print(f'Added New Token Cnt : {len(add_tokens)} List : {add_tokens}')
special_tokens_dict = {'additional_special_tokens': sorted(list(new_token))}
tokenizer.add_special_tokens(special_tokens_dict)
return change_sentences, tokenizer
def typed_entity_marker(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : <S:PERSON> 이순신 </S:PERSON>은 조선의 <O:JOB> 무신 </O:JOB>이다.
Qestion : <S:PERSON> 이순신 </S:PERSON>은 조선의 <O:JOB> 무신 </O:JOB>이다. [SEP] <S:PERSON> 이순신 </S:PERSON> 와 <O:JOB> 무신 </O:JOB>의 관계는 무엇입니까?
"""
new_token, change_sentences = set(['<O:LOC>', '</O:POH>', '</S:PER>', '<O:POH>', '</O:ORG>', '<O:NOH>', '<O:ORG>', '<O:PER>', '</O:PER>', '</S:LOC>', '</O:NOH>', '<S:ORG>', '</O:LOC>', '</S:ORG>', '<S:PER>', '<O:DAT>', '</O:DAT>', '<S:LOC>']), []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - typed entity marker working ...!!'):
sub_e_info, obj_e_info = literal_eval(dataset['subject_entity'][i]), literal_eval(dataset['object_entity'][i])
sub_e_marker, obj_e_marker = f"<S:{sub_e_info['type'].upper()}> {sub_e_info['word']} </S:{sub_e_info['type'].upper()}>", f"<O:{obj_e_info['type'].upper()}> {obj_e_info['word']} </O:{obj_e_info['type'].upper()}>"
sentence = dataset['sentence'][i]
# new sentence 생성
sentence = self.make_sentence(sentence, sub_e_info, sub_e_marker, obj_e_info, obj_e_marker, add_question, and_marker)
change_sentences.append(sentence)
print(f'Added New Token Cnt : {len(new_token)} List : {new_token}')
special_tokens_dict = {'additional_special_tokens': sorted(list(new_token))}
tokenizer.add_special_tokens(special_tokens_dict)
return change_sentences, tokenizer
def typed_entity_marker_punct(self, dataset:pd.DataFrame, tokenizer, add_question:bool=True, and_marker:str='와'):
"""
Before : 이순신은 조선의 무신이다.
After : @ * 사람 * 이순신 @은 조선의 # ^ 직업 ^ 무신 # 이다.
Qestion : @ * 사람 * 이순신 @은 조선의 # ^ 직업 ^ 무신 # 이다. [SEP] @ * 사람 * 이순신 @ 와 # ^ 직업 ^ 무신 #의 관계는 무엇입니까?
"""
# ORG(조직), PER(인물), DAT(날짜), LOC(지명), POH(기타), NOH(기타 수량 표현)
mapper = {'ORG' : '조직', 'PER' : '인물', 'DAT' : '날짜', 'LOC' : '지역', 'POH' : '기타', 'NOH' : 'noh'}
new_token, change_sentences = set(['@', '$', '*', '^'] + list(mapper.values())), []
for i in tqdm(range(len(dataset)), desc = 'Preprocessor - typed entity marker punct working ...!!'):
sub_e_info, obj_e_info = literal_eval(dataset['subject_entity'][i]), literal_eval(dataset['object_entity'][i])
sub_e_marker, obj_e_marker = f"@ * {mapper[sub_e_info['type']]} * {sub_e_info['word']} @", f"# ^ {mapper[obj_e_info['type']]} ^ {obj_e_info['word']} #"
sentence = dataset['sentence'][i]
# new sentence 생성
sentence = self.make_sentence(sentence, sub_e_info, sub_e_marker, obj_e_info, obj_e_marker, add_question, and_marker)
change_sentences.append(sentence)
# token 추가
add_tokens = new_token - set(tokenizer.vocab.keys())
print(f'Added New Token Cnt : {len(add_tokens)} List : {add_tokens}')
special_tokens_dict = {'additional_special_tokens': sorted(list(new_token))}
tokenizer.add_special_tokens(special_tokens_dict)
return change_sentences, tokenizer
mapper: typed entity marker punct에 존재하며 entity type을 한글로 대체 해주기 위한 mapper.new_token: 각 marker 메서드 별로 신규 토큰을 추가해줘야 함. 학습 모델의 tokenizer에 없는 토큰이라면 special token으로 추가함.sub_e_marker,obj_e_marker: 기본 entity에 entity span과 type을 넣어준 정보로 변경.self.make_sentence: 문장 내에서 subject entity와 object entity가 나온 순서에 맞게 문장을 재 생성해주는 메서드.add_question: 뒤에 질문 프롬프트를 추가할지 여부를 결정하는 파라미터.
3.2 Marker 결과 확인
3.2.1 입력 데이터 형식
3.2.2 marker 변환 결과

AI, Data Scientist 취업 준비생 입니다. 공부한 내용을 포스팅하고자 합니다. 방문해주셔서 감사합니다