이제 4학년이라 열심히 해봤자 복구도 못하는 학점.. 내가 하고싶은 공부를 한다고 생각하자^^~
출처
목차
- perceptron
- Biological/aritificial neural network
- multi-layered neural network
- deep learning: softmax, activation functions
목표!
그래프와 equation(matrix) 간 conversion을 알자
perceptron
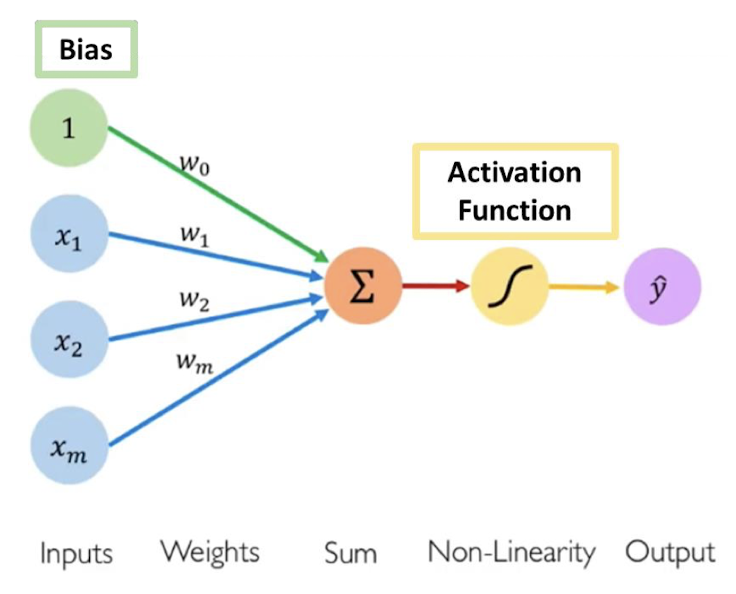
퍼셉트론은 binary classifier들의 지도학습을 위한 알고리즘임!
따라서 0과 1로만 답이 나오는 sigmoid 함수를 activation function으로 많이 사용
Biological/aritificial neural network
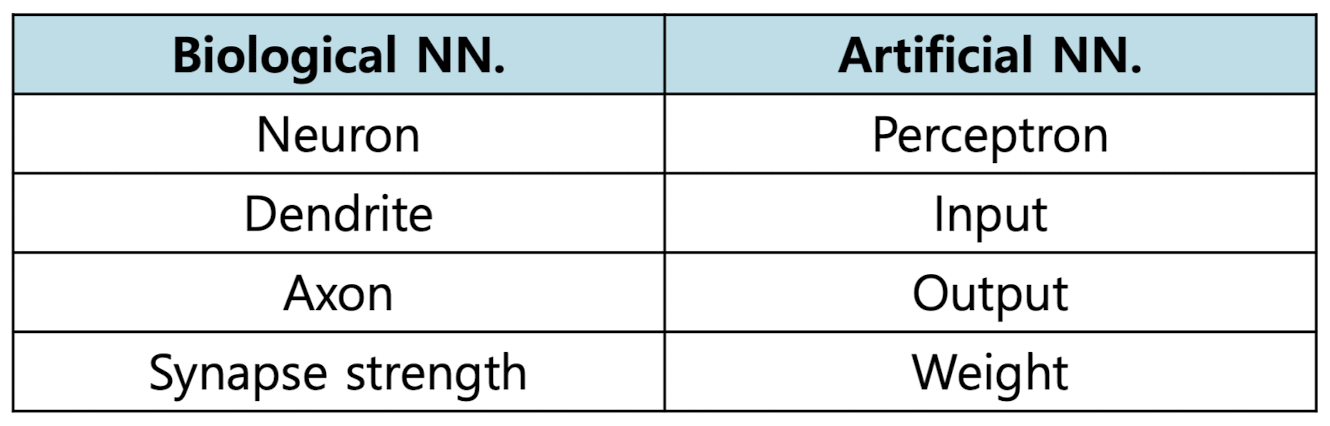
biological과 artificial neural network의 차이를 잘 보여주는 표이다.
인공지능은 인간의 카피라는 점을 잊지 말자!
ANN to equation
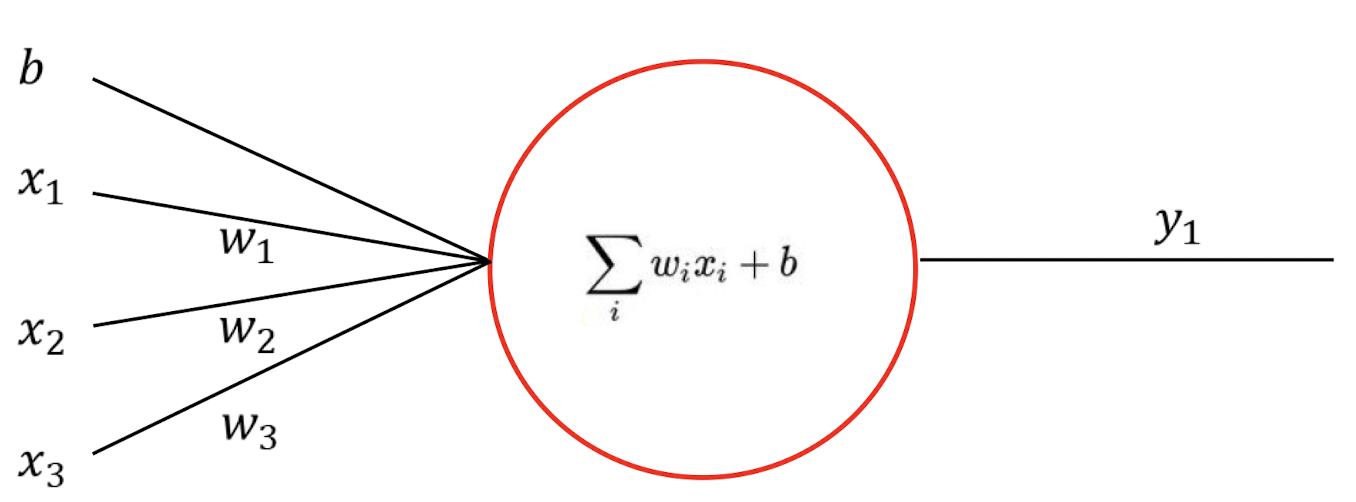
위의 network를 함수로 나타내면 어떤 형식이 되어야 할까??
당연히 multiple linear regression을 이용하여 아래와 같은 식이 나올 것이다.
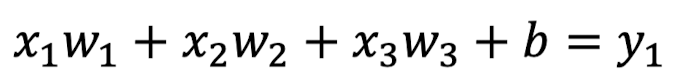
ANN to matrix
그렇다면 위의 network를 matrix form으로 나타내게 된다면??
(XW = Y 형식을 사용하자)
답은
.
.
.
.
.
.
.
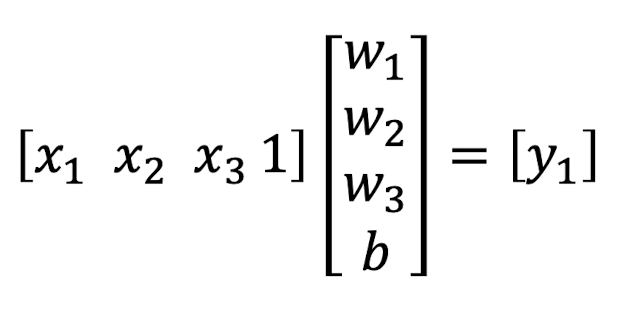
이렇게 될 것이다.
사실 equation과 거의 동일하다. 초심자라면 b 처리를 어떻게 해야하나 고민했을텐데 간단하다! x부분에 1을 추가해주면 된다.
ANN to matrix 2
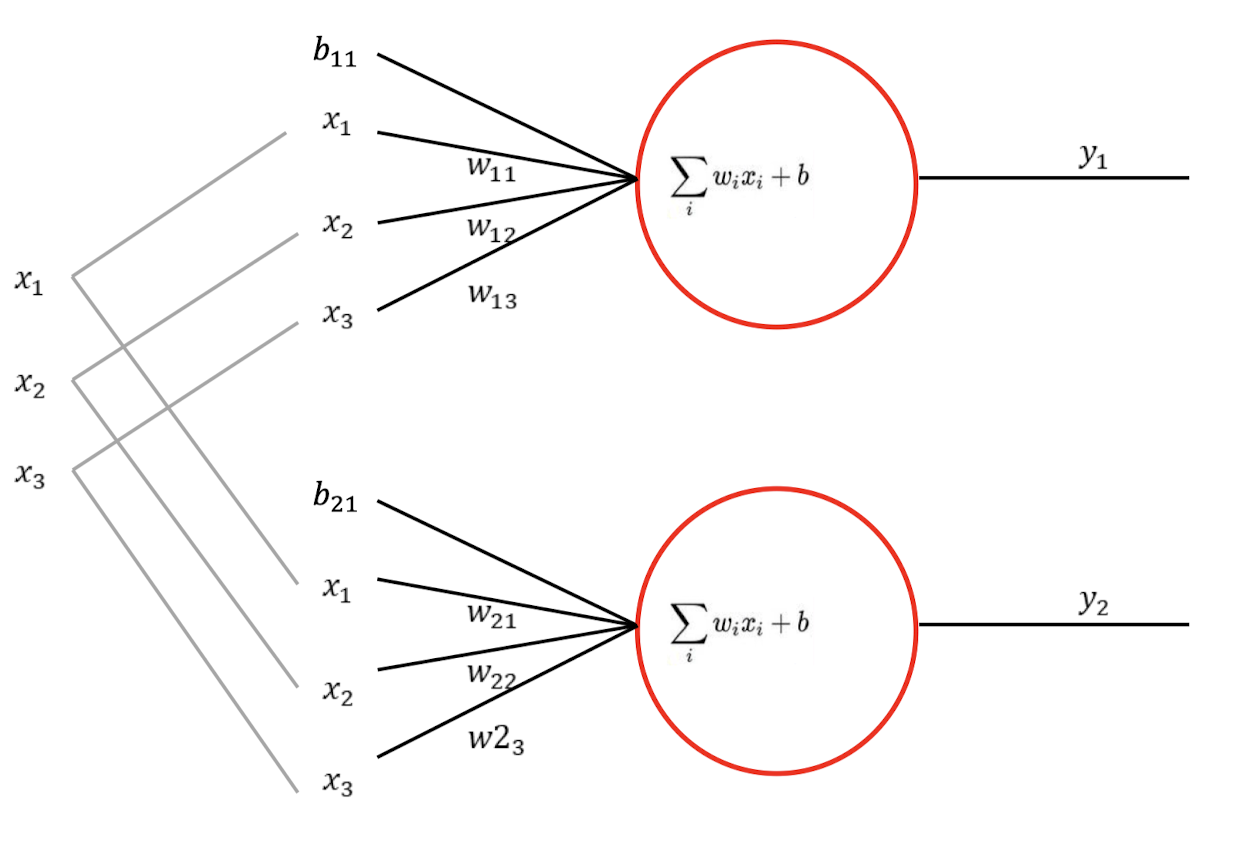
그렇다면 위의 ANN은?? 어떻게 나타내야 할까?
.
.
.
.
.
.
.
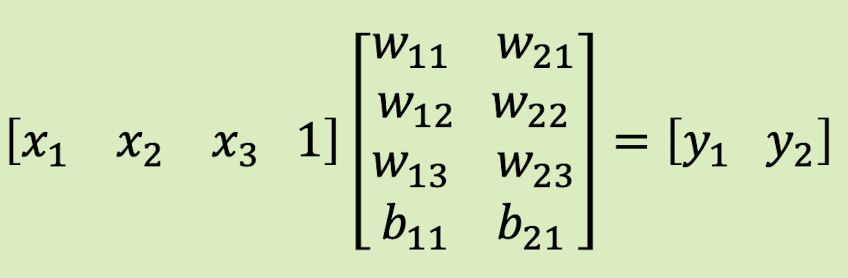
만약 input을 공유하지 않고 퍼셉트론별로 여러개라면 아래와 같은 식도 나올 수 있다.
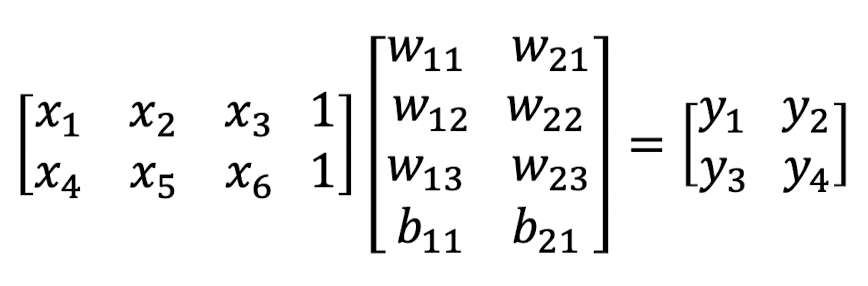
ANN layers
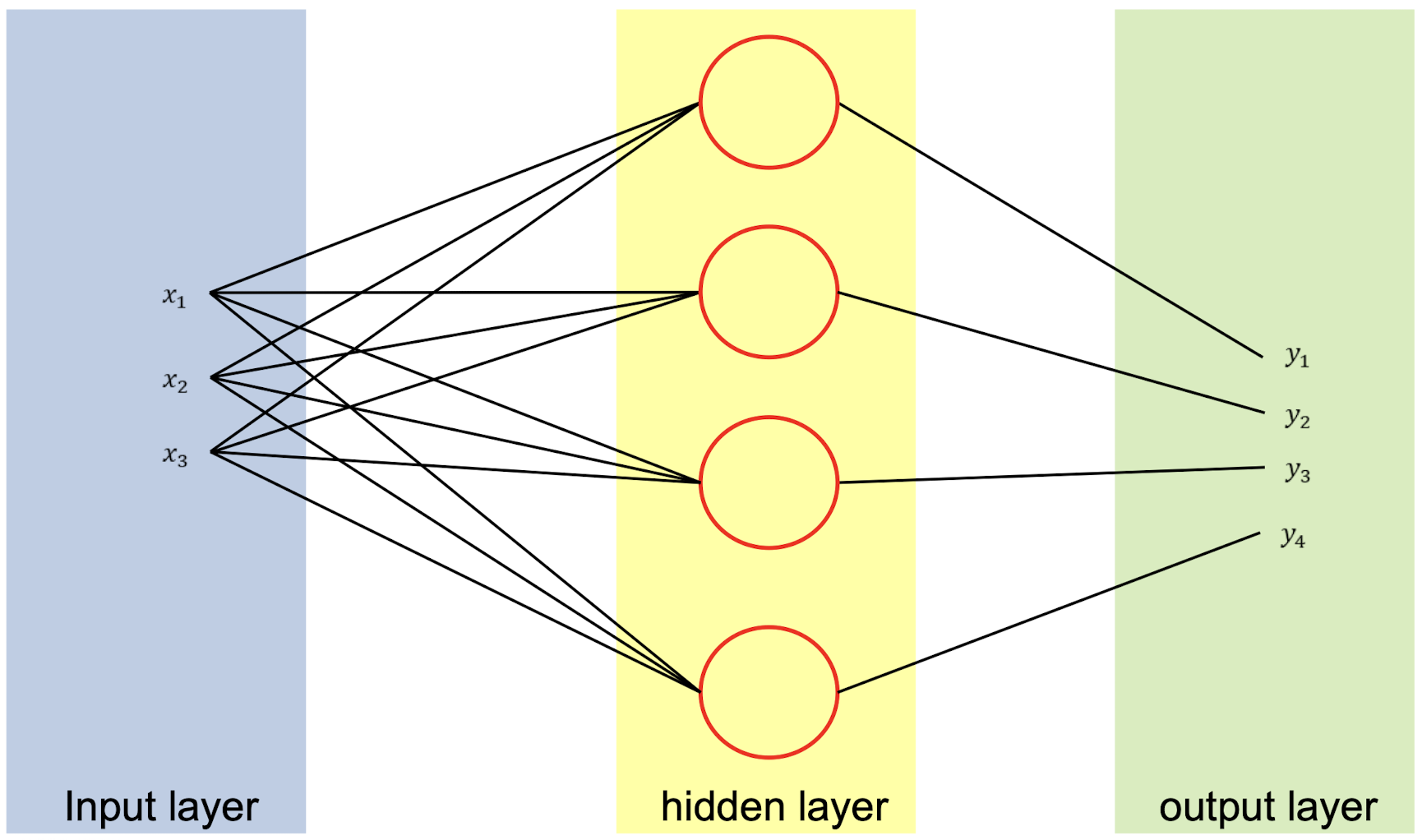
퍼셉트론을 보면 크게 3가지 파트로 나눌 수 있다.
x값이 입력된는 input layer
y값이 계산되는 hidden layer
y값이 결과로 나오는 output layer
ANN process
- Set initial value of parameters(e.g. randomly)
- Check cost(GT와 결과값 비교); GT(ground truth)
- Parameter modification by Back Propagation
- Go to stage 1 until the error is less than the threshold.
deep learning(multi-layered neural network)
근데 그럼 NN, ANN에 추가된 deep learning만의 차이점이 뭔데?
-> one-hot encoding, softmax, activation function
one-hot encoding
- softmax 함수를 이용해 network에서 나온 값을 0과 1 중 하나의 정수로 바꿔주는 것.
Softmax
- the Ground truth: GT의 각 값은 one-hot-encoding으로 나타내어짐.
- 따라서 우리는! 각 네트워크의 결과를 확률값으로 나타내야 함.
- 결과값을 확률로 바꾸기 위해서 우린 softmax함수를 사용함!
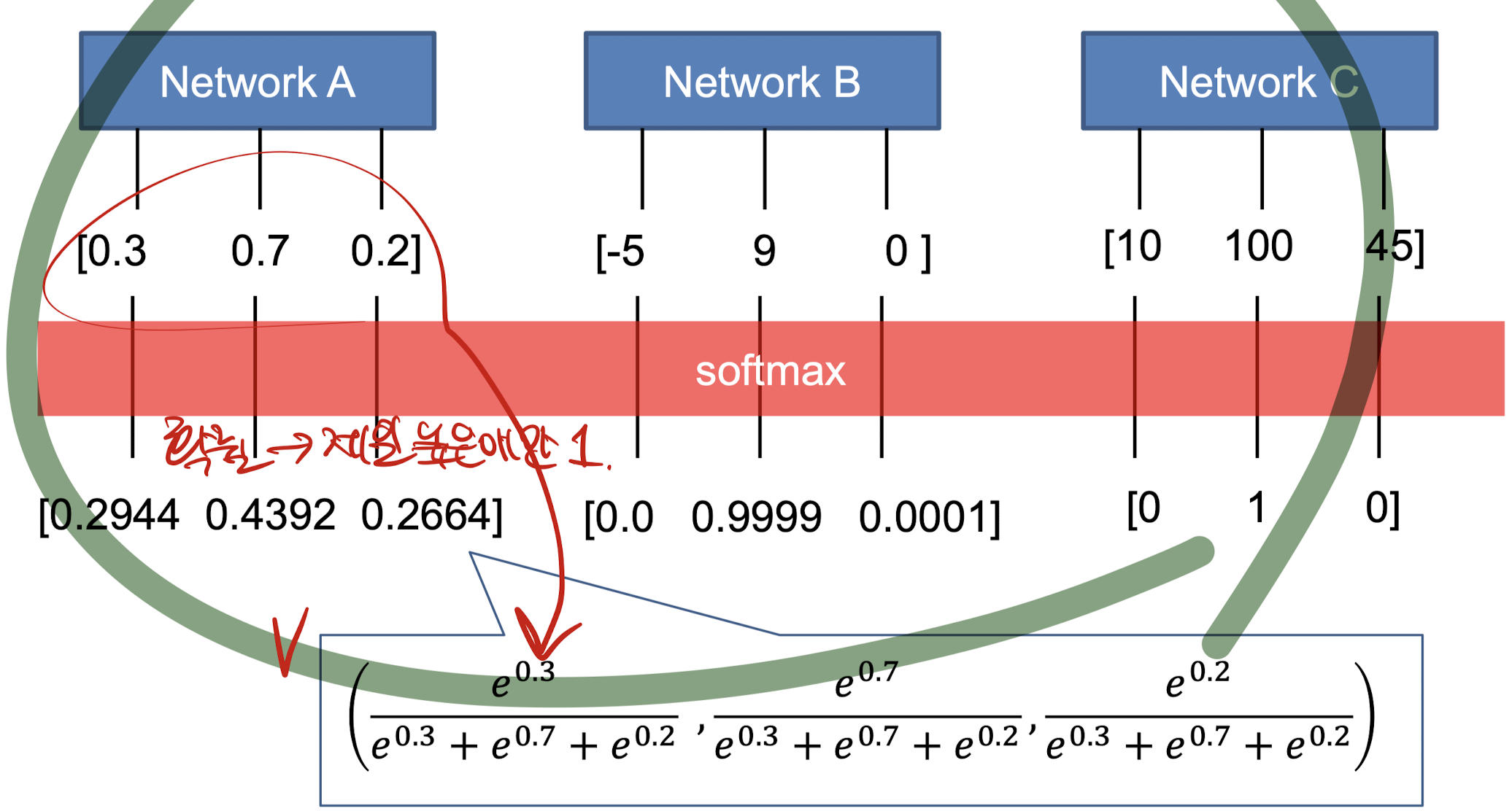
softmax를 그럼 어떻게 계산함?
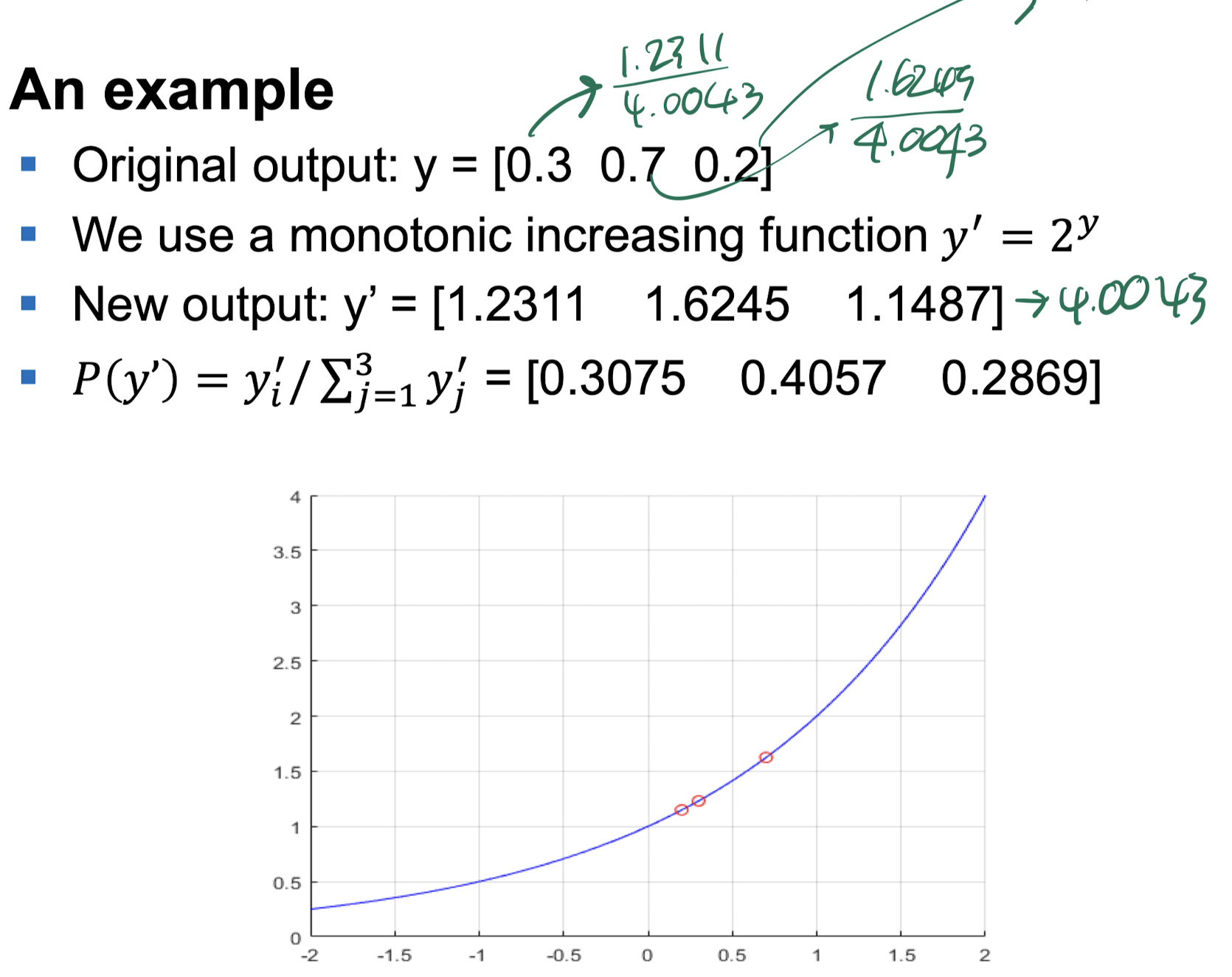
전체 Output의 값을 더하고, 거기서 특정 output의 비율을 계산함.
위의 softmax 계산 식은 단순히 예제일 뿐이다. 그렇다면 실제 softmax 함수의 생김새는 어떨까?
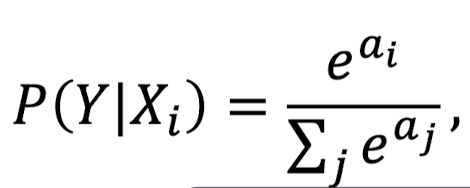
softmax 함수를 보면 exp값이 존재한다.
그럼 왜 ? 어쩌다가 자연상수를 쓰게 된걸까
Bayes theorem을 따르기 때문에
위에서 알 수 있지만 우리는 확률값을 계산하게 된다. 따라서 베이즈 정리를 이용했고, 그 결과를 ln에 넣었기에 해당 식이 나오게 되었다.
위의 식을 적용해 나온 예시는 다음과 같다.
Cost function
Cross Entropy
- 분류에 많이 쓰이는 개념이다.
- 구하는 방법은 다음과 같다.
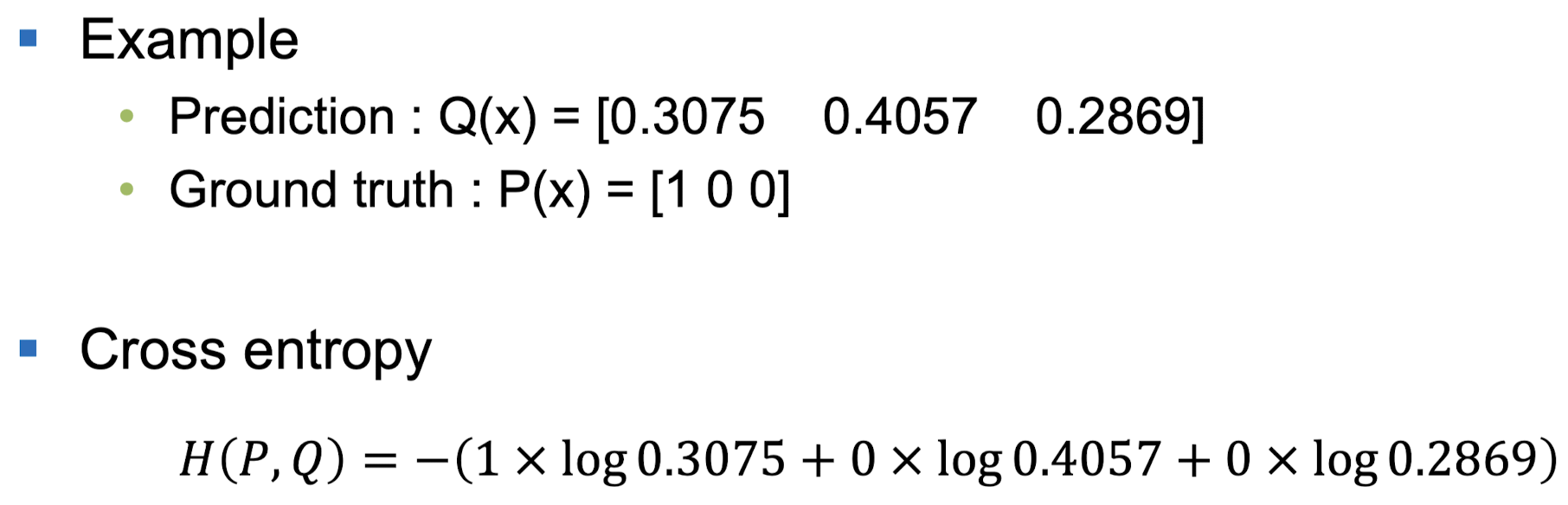
딥러닝에서는 실제 데이터의 확률 분포와, 학습된 모델이 계산한 확률 분포의 차이를 구하는데 사용된다.
q와 p가 모두 들어가서 크로스 엔트로피라고 한다.
Activation function
NN에서 많이 쓰이는 activation function
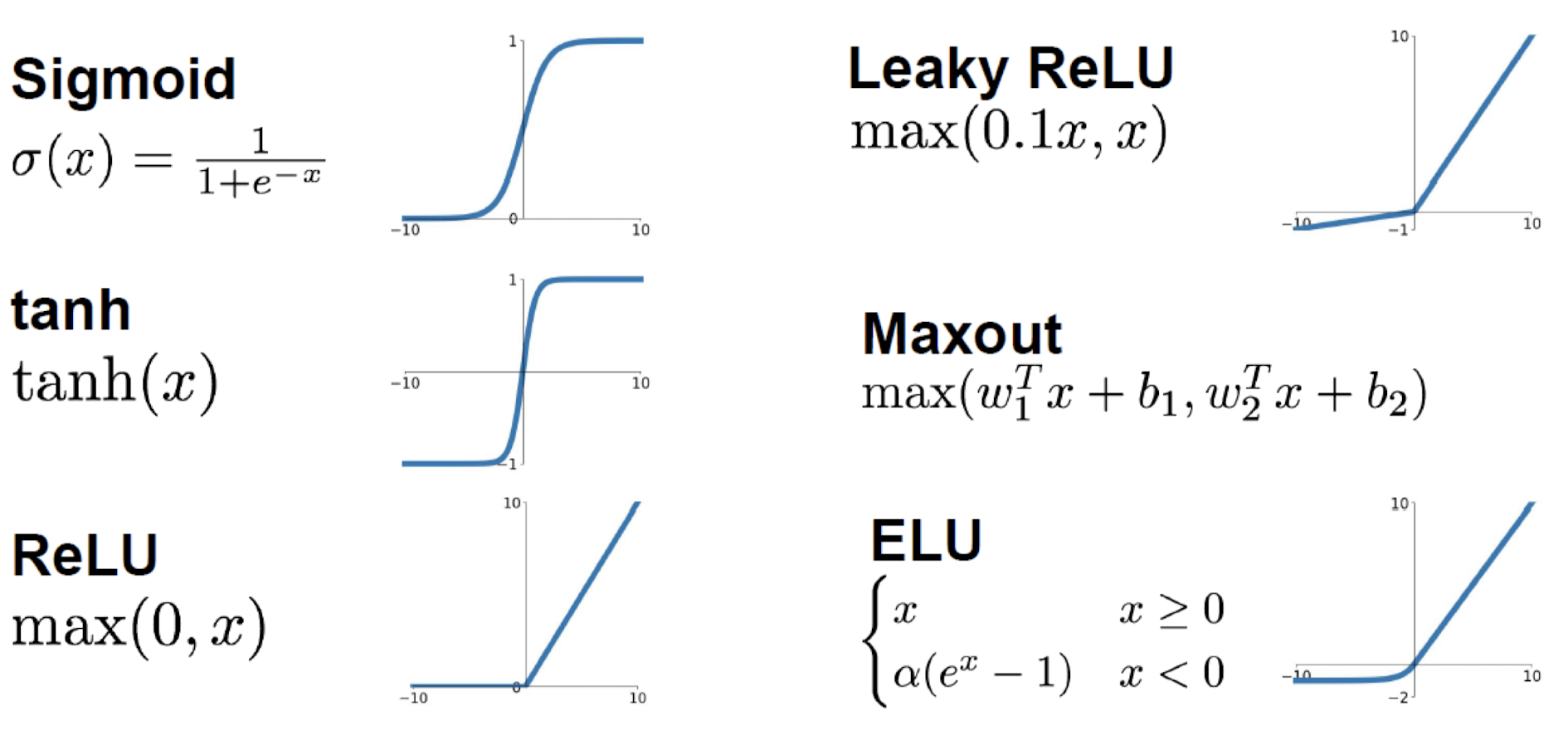
- Sigmoid
- 숫자를 [0,1] 사이의 범위로 만든다.
- 뉴런의 firing rate(역치)를 잘 설명해서 역사적으로 유명
- 문제점:
- 뉴런이 가득해지면(saturated) gradient를 kill
- zero centered하지 않다.
- exp는 계산 cost가 high하다.
- tanh
- 숫자를 [-1,1] 사이의 범위로 만든다.
- 중심이 0이다.
- 문제점:
- 뉴런이 가득해지면(saturated) gradient를 kill
- ReLU
- f(x) = max(0,x)
- 양의 방향으로는 saturate하지 않는다.
- 계산 측면에서 굉장히 효과적이다.
- Converges가 시그모이드, 탄젠트의 학습속도보다 훨씬 빠르다.
- 문제점:
- 죽는다.
- Leaky ReLU
- f(x) = max(0.01x,x)
- 얘는 그냥 saturate하지 않는다(Does not saturate).
- 계산 측면에서 굉장히 효과적이다.
- Converges가 시그모이드, 탄젠트의 학습속도보다 훨씬 빠르다.
- 죽지도 않는다.
그렇다면 우리가 activation function을 쓰는 이유는??
Non-linearities 를 보장해주기 때문
.jpeg)