
📌 RNN
RNN(순환 신경망)은 시퀀스(순차적) 데이터를 처리하는 데 사용되는 신경망의 한 종류입니다. RNN은 이전 상태를 기억하여 현재의 입력과 결합하여 출력을 생성하므로 순차적인 데이터에 적합합니다.
🔍 주요 특징:
- Recurrent:
- "Recurrent"는 "반복적인"이라는 의미로, 입력 데이터가 순차적이라는 것을 의미합니다.
- 매개변수는 여러 시점에서 재사용됩니다.
- 용도:
- 가변 길이 입력 또는 출력을 처리할 수 있는 신경망 패밀리입니다.
- 주로 사용되는 분야: 자연어 처리(NLP), 비디오 처리, 이미지 캡셔닝
🔍 Sequential Data
특징
-
각 데이터 포인트:
- 벡터의 시퀀스 , for
-
배치 데이터:
- 서로 다른 길이의 시퀀스
- 일정한 양의 데이터가 들어오는 것이 아니라는 점에서 그걸 맞추는 것이 어려움
-
라벨:
- 스칼라, 벡터 또는 시퀀스일 수 있습니다.
- 예:
- 감정 분석
- 기계 번역
-
다양한 타입의 시퀀스 라벨:
- 이미지 캡셔닝:
- 입력 데이터: 이미지(예: CNN을 통해 이미지 특징 추출)
- 출력 데이터: 설명
- 이미지 캡셔닝:
요약
- RNN의 특징:
- 순차 데이터를 처리하며, 매개변수를 공유하여 입력 데이터가 순차적으로 처리됨.
- 1986년에 도입된 이후 자연어 처리, 비디오 처리, 이미지 캡셔닝 등 다양한 분야에 사용됨.
- 시퀀스 데이터의 특징:
- 데이터 포인트는 벡터의 시퀀스로 구성.
- 배치 데이터는 여러 시퀀스를 포함하며, 각 시퀀스는 길이가 다를 수 있음.
- 라벨은 스칼라, 벡터 또는 시퀀스 형태로 존재하며, 감정 분석, 기계 번역 등 다양한 응용이 가능.
📌 Structures of Recurrent Neural Networks
순환 신경망(RNN) 구조
RNN 구조의 유형
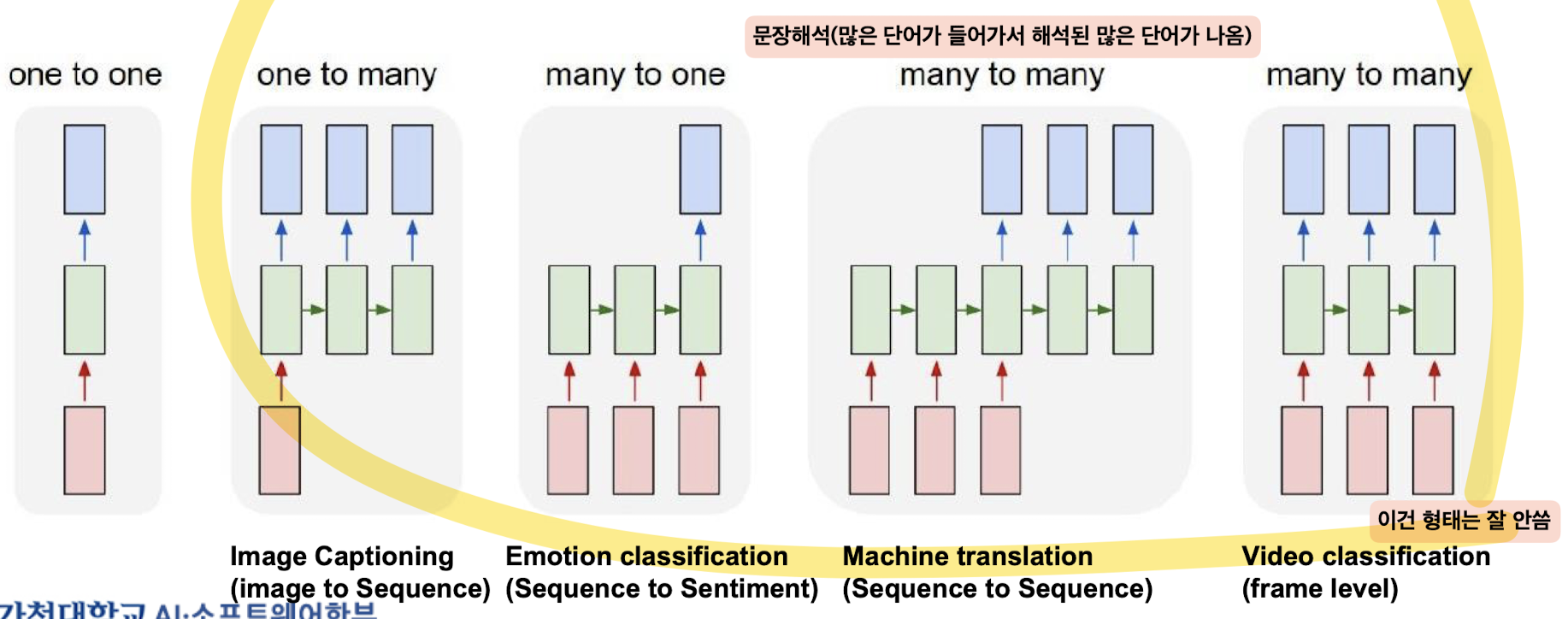
1. 일대일(One to One)
- 단일 입력에서 단일 출력.
- 예: 기본 이미지 분류.
-
일대다(One to Many)
- 단일 입력에서 여러 출력.
- 예: 이미지 캡셔닝(이미지에서 시퀀스로).
-
다대일(Many to One)
- 여러 입력에서 단일 출력.
- 예: 감정 분석(시퀀스에서 감정으로).
-
다대다(Many to Many)
- 여러 입력에서 여러 출력.
- 예: 기계 번역(시퀀스에서 시퀀스로).
- 예: 비디오 분류(프레임 수준 분류).
도전 과제 및 해결책
- 문제: 입력 시퀀스가 길어질수록 더 많은 매개변수가 필요하며, 이는 계산 복잡성과 메모리 사용량을 증가시킵니다.
- 해결책: seq2seq(시퀀스 투 시퀀스)와 같은 기술을 사용하여 many-to-one과 one-to-many 구조를 결합합니다.
시퀀스 투 시퀀스(Seq2Seq)
- 구조: many-to-one과 one-to-many 구조를 결합합니다.
- 인코더(Encoder): 입력 시퀀스를 고정 크기의 벡터로 변환합니다.
- 디코더(Decoder): 고정 크기의 벡터를 다시 출력 시퀀스로 변환합니다.
RNN의 작동
-
기능:
- RNN은 시퀀스의 다른 시간 단계에서 동일한 계산 함수와 매개변수를 사용합니다.
- 각 시간 단계에서 RNN은 입력 항목과 이전 숨겨진 상태를 가져와 출력 항목을 계산합니다.
-
표현:
- RNN은 일반적으로 단일 레이어(Fig.A)로 표현되지만, 실제로는 각 시간 단계에서 작동합니다(Fig.B).
기본 RNN(Vanilla RNN)
-
처리 과정:
- RNN은 시퀀스의 벡터 ( \mathbf{x} )를 각 시간 단계에서 재귀 공식으로 처리합니다.
- 메모리 셀: RNN의 단일 레이어.
-
공식:
- : 이전 상태.
- : 시간 단계 에서의 입력 벡터.
- : 매개변수 를 포함한 함수.
-
예시:
- : 활성화 함수(예: tanh).
- : 활성화 함수(예: 소프트맥스).
- : 매개변수인 텐서들.
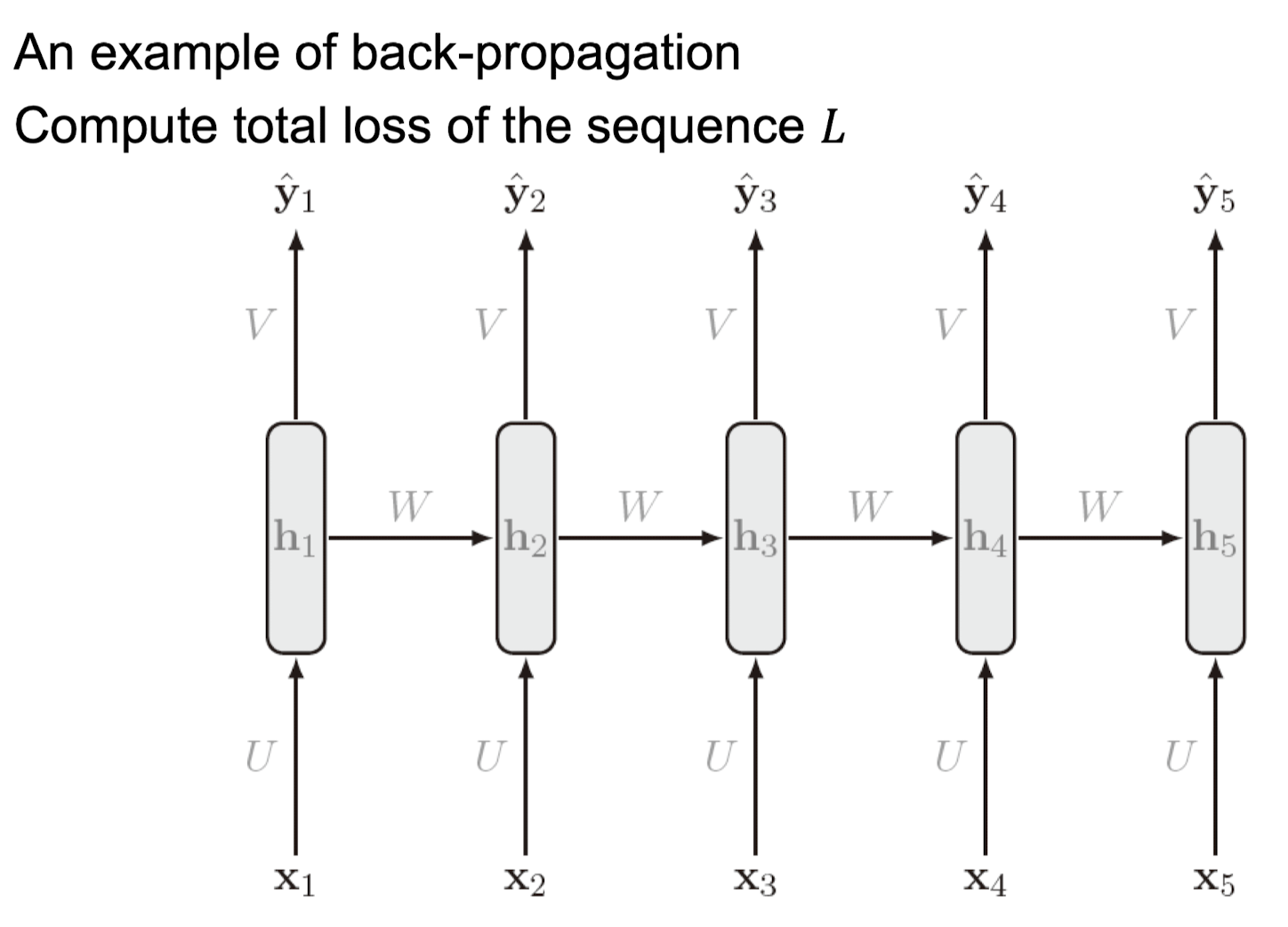
📌 RNN: Feed forward Propagation
- Feed Forward Propagation: 입력과 출력 시퀀스의 길이가 같은 RNN의 예입니다. 피드 포워드 연산은 왼쪽에서 오른쪽으로 진행됩니다.
- 손실 계산: 손실은 시간 단계별로 계산된 손실의 합입니다.
손실 함수 은 다음과 같이 정의됩니다:
여기서 는 다음과 같이 정의됩니다:
Note: 피드 포워드 전파는 병렬화(parallelized)될 수 없습니다.
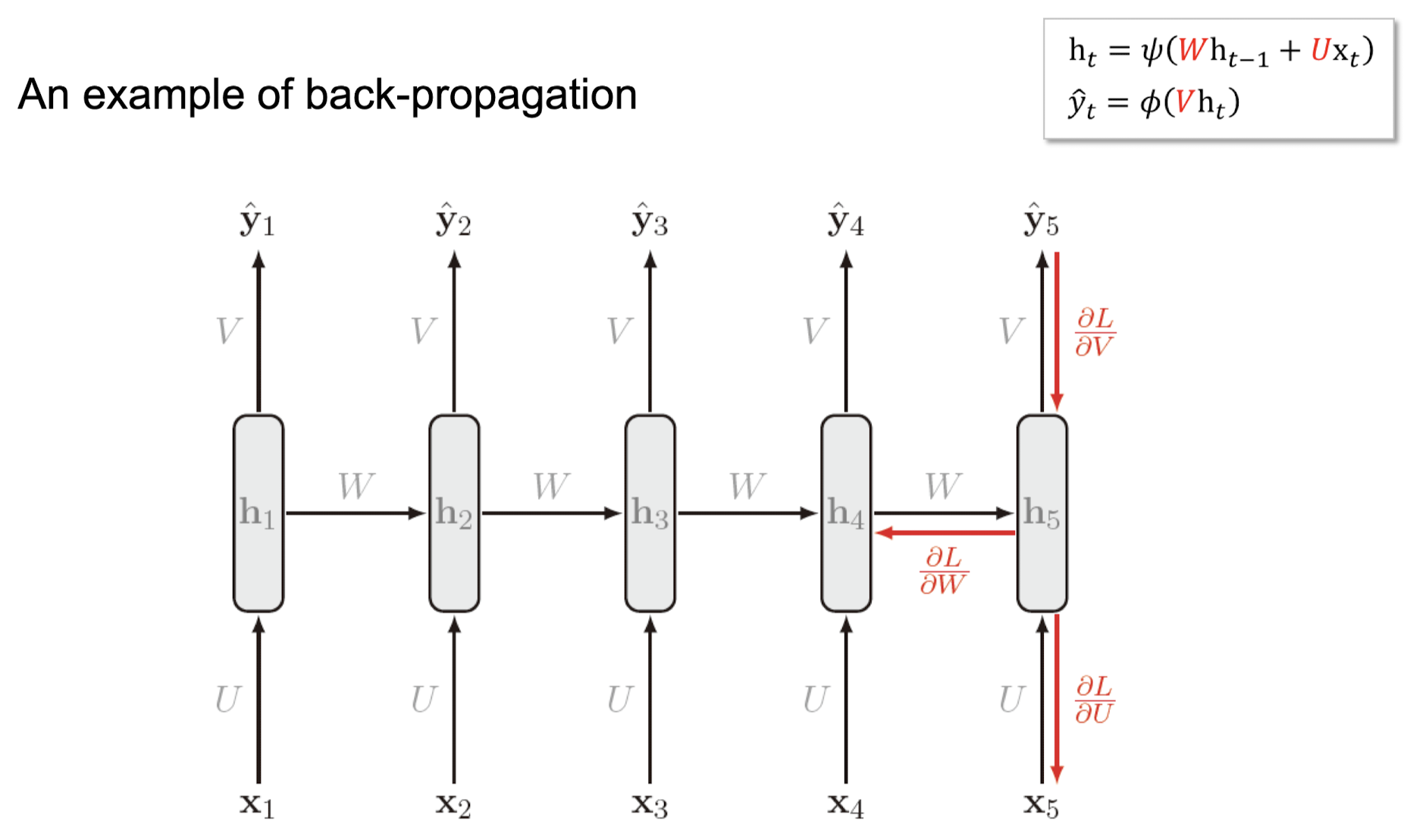
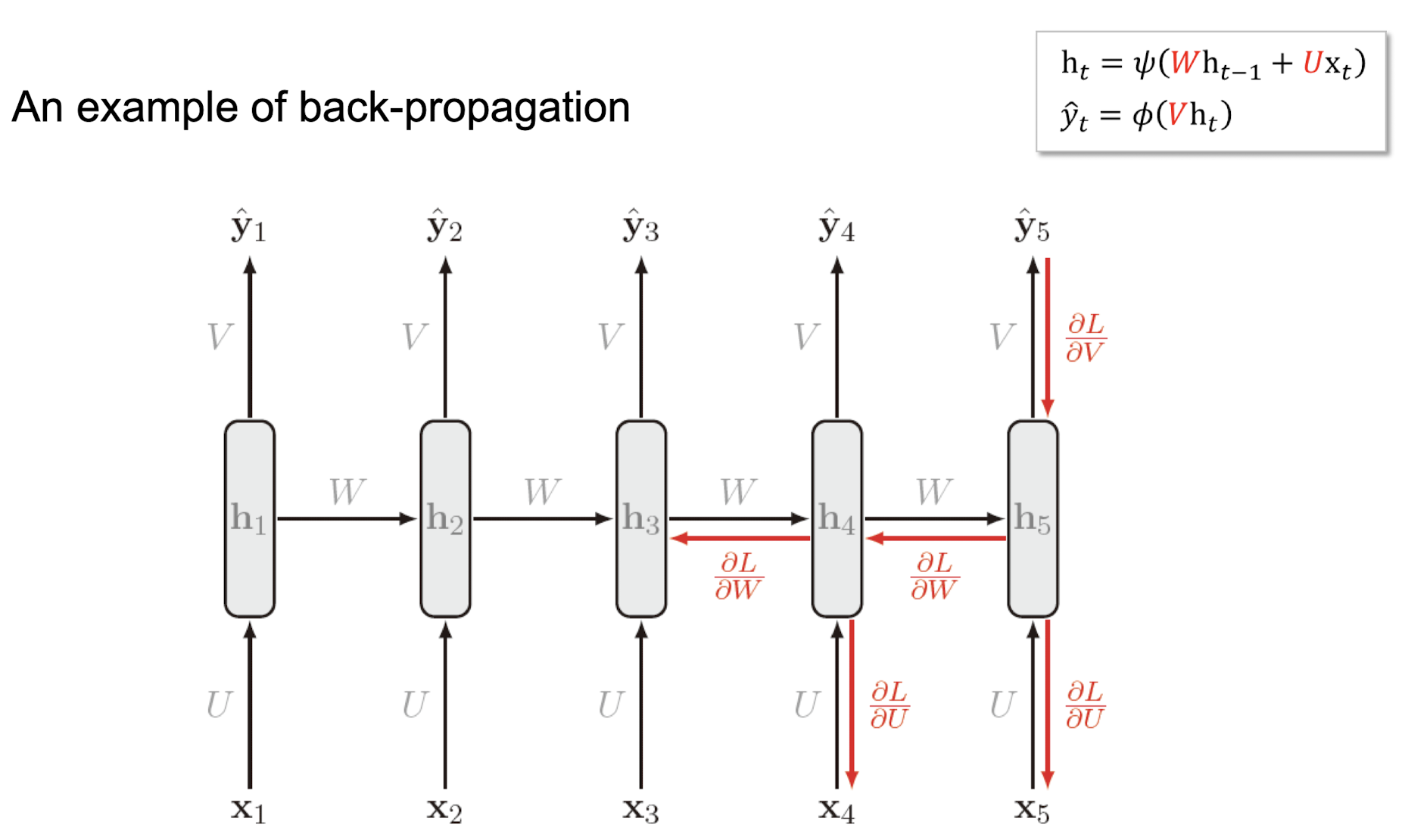
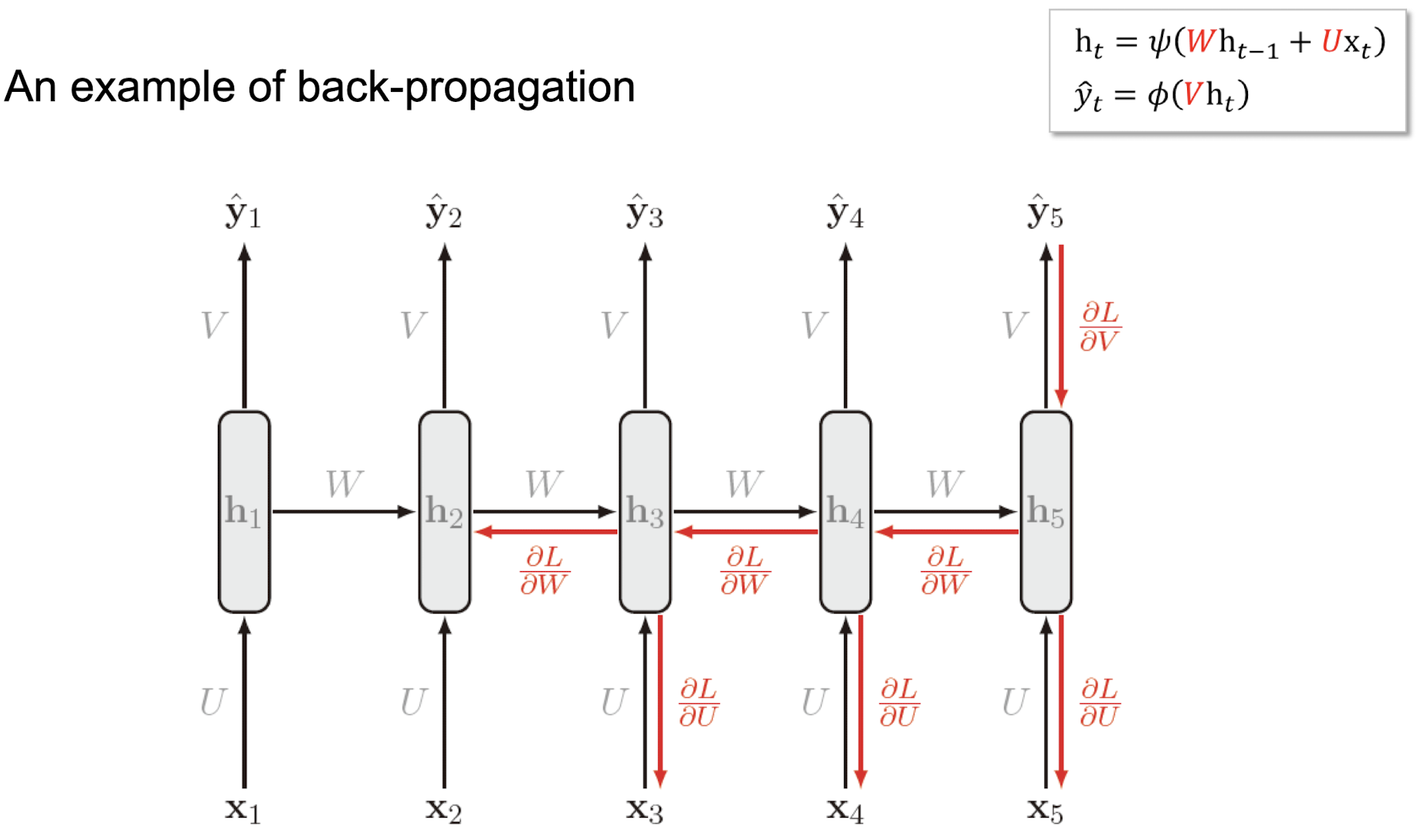
📌Backward Propagation (Back-propagation through time -> BPTT)
- Backward Propagation: 역전파를 위해 우리는 , , 을 찾아야 합니다.
- 역전파 과정: RNN을 다층 네트워크로 간주하고, 펼쳐진 네트워크에 역전파를 적용합니다.
Unrolled Network: 시퀀스를 위한 전체 계산 그래프입니다.
역전파는 오른쪽에서 왼쪽으로 이동합니다. 이것을 시간에 따른 역전파라고 합니다.
식:
여기서 는 매개변수인 텐서입니다.는 tanh, 는 softmax가 될 수 있습니다.
전체 요약:
1. Feed Forward Propagation:
- RNN에서 입력 시퀀스와 출력 시퀀스의 길이가 같은 경우 왼쪽에서 오른쪽으로 진행.
- 손실은 시간 단계별로 계산된 손실의 합.
- Backward Propagation:
- RNN을 다층 네트워크로 간주하고 펼쳐진 네트워크에 역전파를 적용.
- 시간에 따른 역전파로 오른쪽에서 왼쪽으로 이동.
Backward Propagation 예시
📌 Bi-directional RNN (양방향 RNN)
-
양방향 순환 신경망 (BRNN): 양방향 순환 신경망은 두 개의 은닉층을 반대 방향으로 연결하여 동일한 출력으로 연결합니다. 이는 두 개의 독립된 RNN을 함께 연결하는 것입니다.
-
입력 시퀀스: 하나는 정상적인 시간 순서로, 다른 하나는 역방향 시간 순서로 입력됩니다. 이는 문맥을 더 잘 이해할 수 있도록 돕습니다.
동작 방식
-
정방향 RNN:
- 입력 에서 시작하여, 순차적으로 로 진행합니다.
- 각 단계에서 은닉 상태 는 이전 은닉 상태와 현재 입력을 사용하여 계산됩니다.
-
역방향 RNN:
- 입력 시퀀스를 반대로 로 입력받아 진행합니다.
- 각 단계에서 은닉 상태 는 이전 은닉 상태와 현재 입력을 사용하여 계산됩니다.
-
출력 계산:
- 정방향과 역방향의 은닉 상태를 결합하여 최종 출력을 계산합니다.
예시
- 문장 예시에서, BRNN은 문장의 앞뒤 문맥을 모두 고려하여 더 정확한 출력을 제공합니다.
- 예: "I am ____ hungry" 문장에서 빈칸을 채우기 위해 앞뒤 문맥을 모두 고려합니다.
📌 Problems of RNN (순환 신경망의 문제점)
-
순환 신경망(RNN) 한계:
- 기울기 소실(Gradient Vanishing): 기울기 값이 점점 작아져서 거의 0에 가까워지며 학습이 멈추는 현상.
- 기울기 폭발(Gradient Exploding): 기울기 값이 너무 커져서 무한대(inf) 또는 NaN 값이 되어 학습이 불가능해지는 현상.
-
파라미터 재사용:
- RNN은 시간 단계마다 동일한 파라미터를 재사용합니다.
- 파라미터가 1보다 큰 경우: 기울기 폭발 발생 가능성이 큽니다.
- 파라미터가 1보다 작은 경우: 기울기 소실 발생 가능성이 큽니다.
해결 방법:
-
게이트 순환 신경망(Gated RNN): RNN의 기울기 문제를 해결하기 위해 고안된 구조로, 대표적인 예로 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)가 있습니다.
- LSTM: 셀 상태(cell state)를 유지하여 장기 의존성을 학습할 수 있도록 함.
- GRU: LSTM의 변형으로, 비교적 간단한 구조로 이루어져 있으며 비슷한 성능을 보임.
.jpeg)