
의욕이 없다. 왜?
📌 Data Augmentation
-
데이터 부족과 과적합:
- 데이터셋이 부족하면 모델이 훈련 데이터에 과적합(overfitting)되는 문제가 발생합니다.
-
데이터 증강의 조건:
- 증강된 데이터는 현실적이어야 합니다. 즉, 원래 데이터의 특성을 유지하면서도 변형된 데이터여야 합니다. 그렇지 않으면, 모델이 잘못된 패턴을 학습할 수 있습니다.
-
데이터 증강의 효과:
- 실제로 데이터 증강은 네트워크 성능을 크게 향상시키는 데 기여합니다. 이는 더 많은 데이터와 다양한 데이터를 통해 모델이 더 일반화된 성능을 보일 수 있게 하기 때문입니다.
-
데이터 증강 기법의 예:
- shift and crop
- flip(vertically, horizontally)
- rotation
- resize(upsampling, downsampling)
- color jitter(luminance, contrast)
- adding noise
📌 Vanishing Gradient
알제?..
📌 Weight (parameter) initialization
🔍 LeCun Initialization
-
LeCun Normal Initialization:
- 가중치는 평균이 0이고 분산이 (\frac{1}{n_{in}})인 정규 분포에서 샘플링합니다.
- 수식:
- : 이전 층의 노드 수
-
LeCun Uniform Initialization:
- 가중치는 에서 사이의 균등 분포에서 샘플링합니다.
- 수식:
🔍 Xavier (Glorot) Initialization
-
Xavier Normal Initialization:
- 가중치는 평균이 0이고 분산이 인 정규 분포에서 샘플링합니다.
- 수식:
- : 이전 층의 노드 수
- : 다음 층의 노드 수
-
Xavier Uniform Initialization:
- 가중치는 에서 사이의 균등 분포에서 샘플링합니다.
- 수식:
🔍 He Initialization
-
He Normal Initialization:
- ReLU 활성화 함수를 사용할 때 효과적입니다.
- 가중치는 평균이 0이고 분산이 인 정규 분포에서 샘플링합니다.
- 수식:
-
He Uniform Initialization:
- 가중치는 에서 사이의 균등 분포에서 샘플링합니다.
- 수식:
🔍 Summary
- Sigmoid와 tanh 활성화 함수를 사용할 때는 Xavier Initialization이 효율적입니다.
- ReLU 활성화 함수를 사용할 때는 He Initialization이 효율적입니다.
- 대부분의 최신 모델에서는 He 초기화를 주로 사용합니다.
- PyTorch를 사용하면 초기화 방법을 쉽게 적용할 수 있습니다.
코드 예시 (PyTorch에서 초기화 방법 사용):
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)📌 Transfer learning
전이 학습은 사전 훈련된 모델을 새로운 데이터셋에 맞추어 재훈련(fine-tuning)하는 방식으로, 특히 작은 데이터셋에서 효과적입니다. 다음은 전이 학습의 개념과 효과에 대한 설명입니다.
전이 학습의 전략
-
Quadrant 1:
- Large dataset, different from the pre-trained model's dataset
- 전략: 전체 모델을 훈련시킵니다.
- 데이터셋 크기가 크고, 사전 훈련된 모델의 데이터셋과 다르기 때문에 모든 레이어를 새로 학습시켜야 합니다.
-
Quadrant 2:
- Large dataset, similar to the pre-trained model's dataset
- 전략: 일부 레이어를 훈련시키고, 나머지는 동결합니다.
- 데이터셋 크기가 크고, 사전 훈련된 모델의 데이터셋과 유사하기 때문에 일부 레이어만 새로 학습시켜도 충분합니다.
-
Quadrant 3:
- Small dataset, different from the pre-trained model's dataset
- 전략: 일부 레이어를 훈련시키고, 나머지는 동결합니다.
- 데이터셋 크기가 작고, 사전 훈련된 모델의 데이터셋과 다르기 때문에 일부 레이어만 새로 학습시킵니다.
-
Quadrant 4:
- Small dataset, similar to the pre-trained model's dataset
- 전략: 기본 Convolutional 베이스를 동결합니다.
- 데이터셋 크기가 작고, 사전 훈련된 모델의 데이터셋과 유사하기 때문에, 대부분의 레이어를 동결하고 일부 레이어만 새로 학습시킵니다.
전이 학습의 효과성
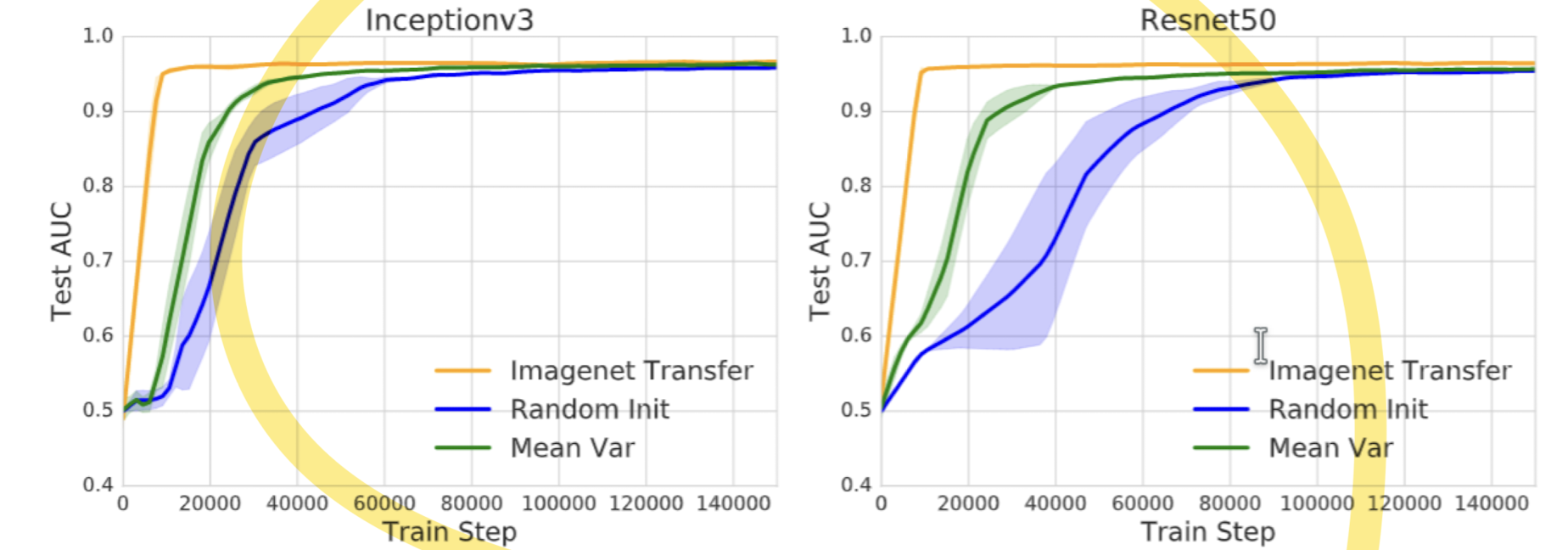
Inceptionv3와 ResNet50 모델의 비교:
- 세 가지 초기화 방법:
- Imagenet Transfer (오렌지 색): ImageNet에서 사전 훈련된 가중치를 사용한 경우
- Random Init (파란색): 가중치를 무작위로 초기화한 경우
- Mean Var (초록색): 평균과 분산을 이용해 가중치를 초기화한 경우
- 결과:
- Imagenet Transfer가 가장 빠르게 높은 성능을 달성합니다. 이는 사전 훈련된 가중치가 새로운 작업에서도 유용하게 작용함을 보여줍니다.
- Random Init과 Mean Var는 성능이 천천히 상승하며, 최종 성능도 낮습니다.
추가 설명
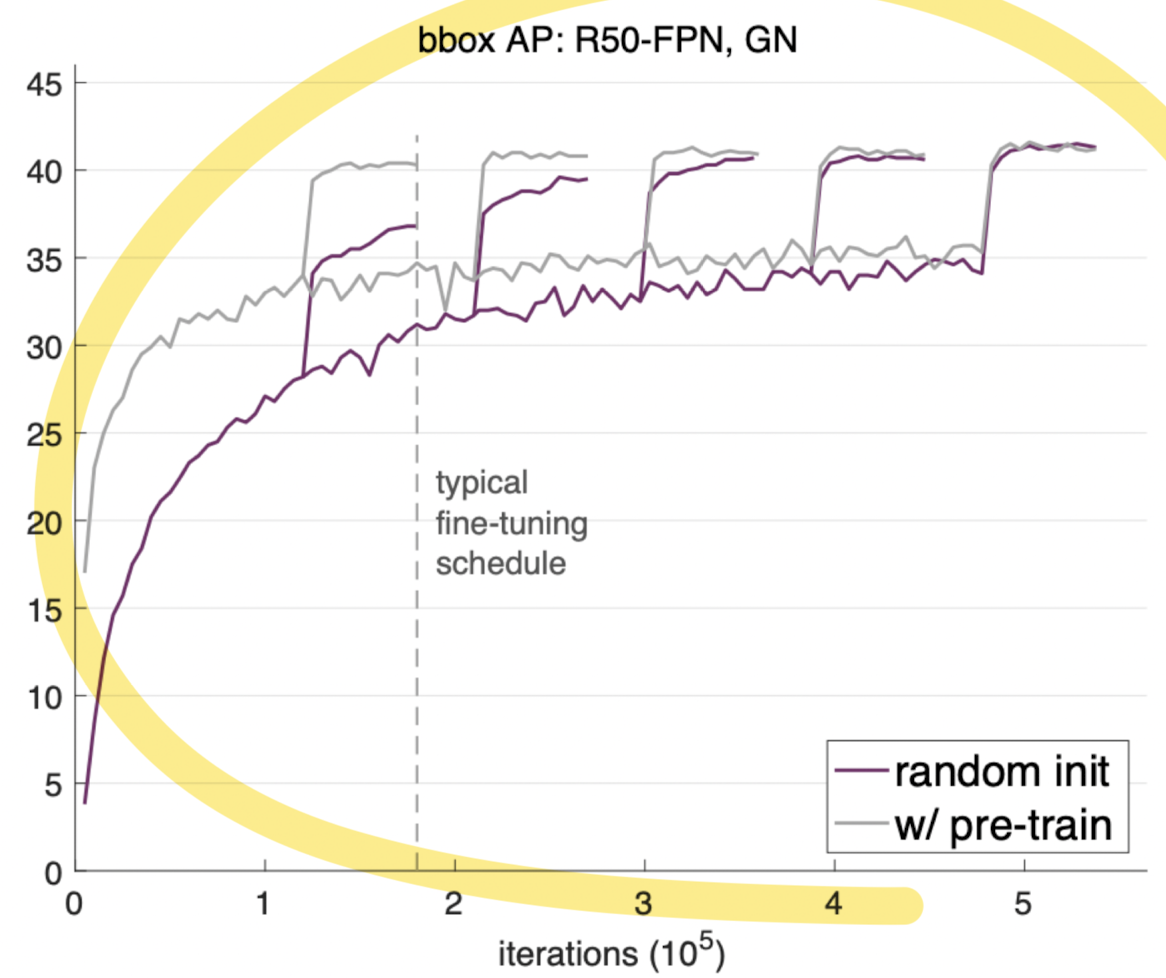
1. 전이 학습의 효과성 (bbox AP: R50-FPN, GN):
- 그래프는 랜덤 초기화와 사전 훈련된 모델의 성능을 비교합니다.
- random init (보라색)과 w/ pre-train (회색) 곡선으로, 사전 훈련된 모델이 더 빠르게 더 높은 성능에 도달함을 보여줍니다.
- 사전 훈련된 모델은 초기 학습 속도가 빠르고, 최종 성능도 더 높습니다.
- 전이 학습의 요점 (Takeaway for your projects and beyond):
- 작은 데이터셋 (< 100만 이미지)를 가진 경우:
- 유사한 데이터를 가진 매우 큰 데이터셋을 찾아, 큰 ConvNet을 훈련시킵니다.
- 전이 학습을 통해 자신의 데이터셋에 적용합니다.
- 딥러닝 프레임워크는 사전 훈련된 모델의 "모델 저장소(Model Zoo)"를 제공하여, 직접 모델을 훈련할 필요가 없습니다.
- 작은 데이터셋 (< 100만 이미지)를 가진 경우:
요약
전이 학습은 데이터셋의 크기와 유사성에 따라 다양한 전략을 사용할 수 있습니다. 사전 훈련된 모델을 사용하는 것이 무작위 초기화보다 빠르고 효율적으로 높은 성능을 달성할 수 있습니다. 작은 데이터셋을 가진 경우, 전이 학습은 특히 유용하며, 딥러닝 프레임워크의 모델 저장소를 활용하면 더욱 쉽게 적용할 수 있습니다.
.jpeg)
헬로 아이엠군자. 굿투씨유