
방문자수가 드럽게 안늘어난다..
출처
https://backendcode.tistory.com/198
https://velog.io/@mertyn88/Elasticsearch-Vector-search-예제
📌elastic search 서버 실행
필자는 로컬 환경에 elastic search를 다운받아 실행했다.
1. Elastic search 설치
https://www.elastic.co/kr/downloads/past-releases#elasticsearch
위의 링크로 들어가 원하는 버전을 설치하면 된다.
나는 참고한 글을 바탕으로 7.16.2 버전을 설치했다.
Download 버튼을 눌러 설치해준다.
2. Elastic search 실행
다운로드 받은 파일을 열면 바로 압축이 풀릴 것이다.
원하는 폴더로 이동해준 후, 터미널을 열고 elastic search가 있는 폴더로 접근한다.

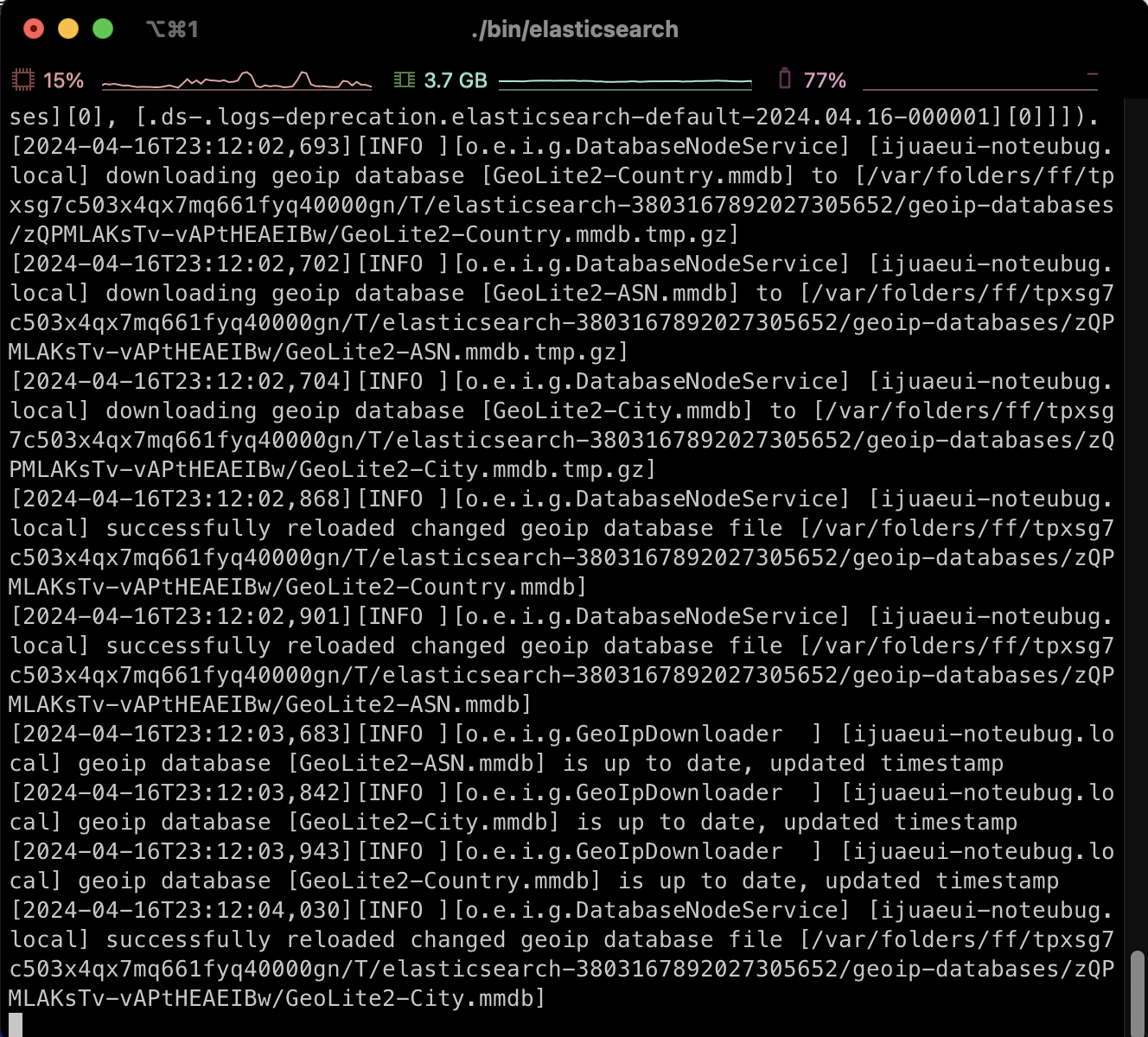
elasticsearch-X.X.X 폴더로 이동을 했다면 아래의 명령어를 실행해 elasticsearch 서버를 실행해준다.
./bin/elasticsearch그럼 정말 엄청나게 많은 글씨들이 나온다.
⚠️ 참고로 mmdb확장자로 끝나는 파일까지 로딩되면 끝난거다!! 난 모르고 기다리다가 피봤다..
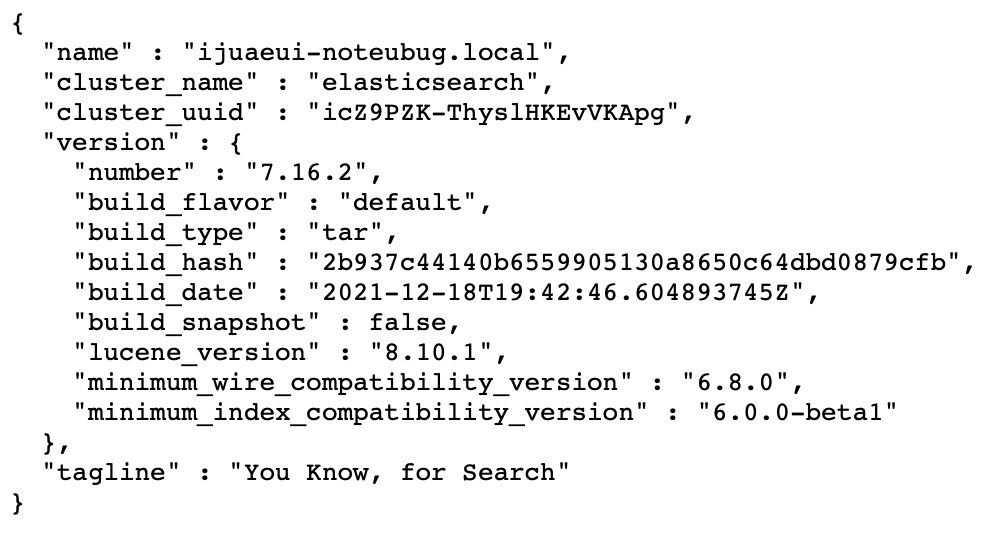
3. Elastic search 서버 접속
http://localhost:9200로 접속했을 때, 아래의 화면이 뜬다면 성공!
📌 코드 구현
꼭!!! 파일 이름은 elasticsearch가 아닌 sth_else.py같은걸로 해야한다... elasticsearch가 라이브러리 이름이라 충돌난다.
내가 Input으로 넣은 csv파일은 멤버의 아이디, 해시태그 라는 두개의 column만 존재한다.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from elasticsearch import Elasticsearch, helpers
# Load the dataset
data_path = 'final_dataset.csv'
data = pd.read_csv(data_path)
# Compute TF-IDF
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(data['content'])
# Initialize Elasticsearch client
client = Elasticsearch('http://127.0.0.1:9200')
# Define the index configuration with dense_vector type
index_config = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"member_id": {
"type": "keyword"
},
"content": {
"type": "text" # Changed from 'keyword' to 'text' for full-text search capabilities
},
"content_vector": {
"type": "dense_vector",
"dims": tfidf_matrix.shape[1] # Set dimensions to the number of features in TF-IDF
}
}
}
}
# Create the index
client.indices.create(index='tfidf_vector_index', body=index_config, ignore=400)
# Prepare documents for indexing
docs = [{
"_index": "tfidf_vector_index",
"_source": {
"member_id": row['member_id'],
"content": row['content'],
"content_vector": tfidf_matrix[index].toarray().flatten().tolist() # Convert CSR row to dense format and flatten to a list
}
} for index, row in data.iterrows()]
# Bulk indexing the documents
helpers.bulk(client, docs)
# Example vector inference (here we just use the vectorizer to transform the query)
query_vector = vectorizer.transform(['여행 자연 사진']).toarray()[0].tolist()
# Define the vector similarity query
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, doc['content_vector'])",
"params": {"query_vector": query_vector}
}
}
}
# Perform the search
response = client.search(
index="tfidf_vector_index",
query=script_query,
size=10,
_source_includes=["member_id", "content"]
)
# Display results
for hit in response['hits']['hits']:
print(f'Member ID: {hit["_source"]["member_id"]}, Content: {hit["_source"]["content"]}, Score: {hit["_score"]}')아무튼 여자저차 성공!! 이제 코드에 적용해보러 가야겠다.
.jpeg)
헬로 아이엠군자. 굿투씨유