
출처
https://aws.amazon.com/ko/what-is/vector-databases/
https://www.elastic.co/kr/what-is/vector-database
📌 벡터 데이터베이스란?
필수 배경지식
- 임베딩 모델: 임베딩은 모든 유형의 데이터를 객체의 의미와 컨텍스트를 포괄하는 벡터로 인코딩함.
임베딩을 통해 인접한 데이터 포인트를 검색할 수 있고, 이를 통해 유사한 객체를 찾을 수 있음.
🔍 벡터 데이터베이스의 기능
- 벡터 데이터베이스는 벡터를 고차원 포인트로 저장하고 검색하는 기능을 제공
- N차원 공간에서 가장 가까운 이웃을 효율적이고 빠르게 조회할 수 있는 추가적인 기능을 추가함.
- 일반적으로 k-NN(k-Nearest Neighbor) 인덱스로 구동되며 계층적 탐색 가능한 소규모 세계(HNSW) 및 반전된 파일 인덱스(IVF) 알고리즘과 같은 알고리즘으로 구축됩니다.
- 벡터 데이터베이스는 데이터 관리, 내결함성, 인증 및 액세스 제어, 쿼리 엔진과 같은 추가 기능을 제공합니다
- 벡터 데이터베이스는 벡터 임베딩을 관리하기 위해 구축되었으므로 비정형 및 반정형 데이터 관리를 위한 완벽한 솔루션을 제공
⚠️ 벡터 데이터베이스는 벡터 검색 라이브러리 또는 벡터 인덱스와 다릅니다.
이는 메타데이터 저장 및 필터링을 가능하게 하고, 확장 가능하며, 동적 데이터 변경을 허용하고, 백업을 수행하고, 보안 기능을 제공하는 데이터 관리 솔루션입니다.
- 벡터 데이터베이스는 고차원 벡터를 통해 데이터를 구성
- 고차원 벡터에는 수백 개의 차원이 포함되어 있으며 각 차원은 그것이 나타내는 데이터 객체의 특정 기능이나 속성에 해당
🔍 벡터 데이터베이스의 사용방법
- 벡터 데이터베이스는 일반적으로 시각적, 의미 체계, 다중 모달 검색과 같은 벡터 검색 사용 사례를 강화하는 데 사용
(그래서 난 TF-IDF 벡터를 저장하는데 사용할 예정이다.) - 개발 프로세스는 제품 이미지와 같은 코퍼스를 벡터로 인코딩하도록 설계된 임베딩 모델을 구축하는 것에서 시작
(데이터 가져오기 프로세스를 데이터 하이드레이션이라고도 한다.) - 모델 내에서 k-NN(k-Nearest Neighbor) 인덱스는 벡터를 효율적으로 검색하고 코사인과 같은 거리 함수를 적용하여 유사성을 기준으로 결과의 순위를 매긴다.
벡터 데이터베이스의 파이프라인
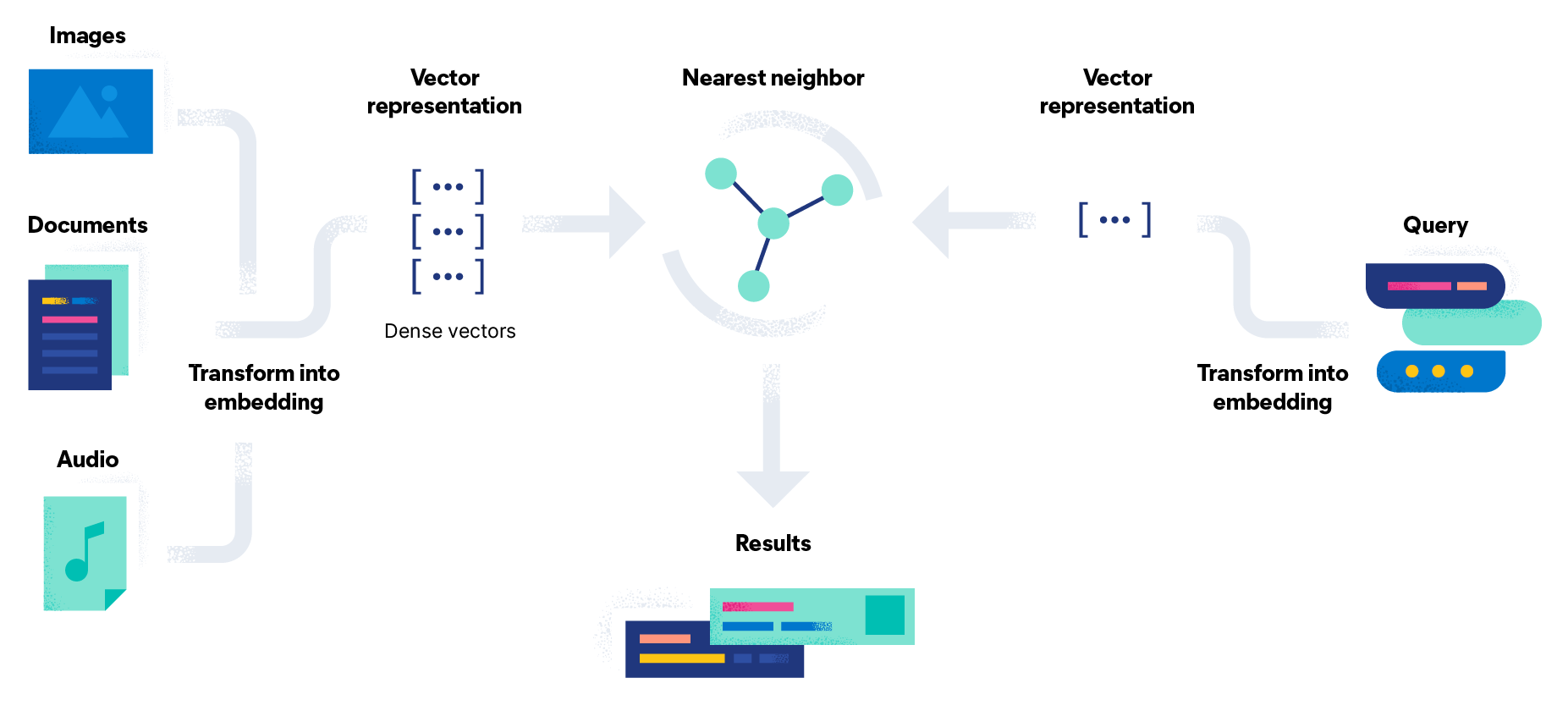
1️⃣ 색인
해싱, 양자화 또는 그래프 기반 기술을 사용하는 벡터 데이터베이스는 벡터를 주어진 데이터 구조에 매핑하여 벡터를 색인합니다. 이를 통해 더 빠른 검색이 가능합니다.
-
해싱
- 지역성 기반 해싱(Locality-Sensitive Hashing, LSH) 알고리즘과 같은 해싱 알고리즘은 빠른 결과를 제공하고 대략적인 결과를 생성하므로 근사 최근접 유사 항목 검색에 가장 적합합니다.
- LSH는 스도쿠 퍼즐과 같은 해시 테이블을 사용하여 최근접 유사 항목을 매핑합니다. 쿼리는 테이블로 해시된 다음 동일한 테이블의 벡터 집합과 비교되어 유사성을 결정합니다.
-
양자화
- 곱 양자화(Product Quantization, PQ)와 같은 양자화 기술은 벡터를 더 작은 부분으로 나누고 해당 부분을 코드로 표현한 다음 해당 부분을 다시 합칩니다.
- 결과는 벡터와 해당 구성 요소의 코드 표현입니다.
- 이러한 코드의 앙상블을 코드북이라고 합니다. 쿼리가 수행되면 양자화를 사용하는 벡터 데이터베이스는 쿼리를 코드로 나눈 다음 코드북과 일치시켜 가장 유사한 코드를 찾아 결과를 생성합니다.
-
그래프 기반
- 계층적으로 탐색 가능한 작은 세계(Hierarchical Navigable Small World, HNSW) 알고리즘과 같은 그래프 알고리즘은 노드를 사용하여 벡터를 나타냅니다. 노드를 클러스터링하고 유사한 노드 사이에 선이나 가장자리를 그려 계층적 그래프를 만듭니다.
- 쿼리가 시작되면 알고리즘은
그래프 계층 구조를 탐색하여 쿼리 벡터와 가장 유사한 벡터가 포함된 노드를 찾습니다. - 벡터 데이터베이스는 데이터 객체의 메타데이터도 색인합니다. 이러한 이유로 벡터 데이터베이스에는 벡터 인덱스와 메타데이터 인덱스라는 두 개의 인덱스가 포함됩니다.
2️⃣ 쿼리
벡터 데이터베이스는 쿼리를 받으면 인덱스 벡터를 쿼리 벡터와 비교하여 최근접 벡터 항목을 결정합니다. 최근접 항목을 설정하기 위해 벡터 데이터베이스는 유사성 측정이라는 수학적 방법을 사용합니다. 다음과 같이 다양한 유형의 유사성 측정이 존재합니다.
- 코사인 유사성(Cosine similarity)은 -1에서 1 범위의 유사성을 설정합니다. 벡터 공간에서 두 벡터 사이의 각도의 코사인을 측정하여 정반대(-1로 표시), 직교(0으로 표시) 또는 동일한(1로 표시) 벡터를 결정합니다.
- 유클리드 거리(Euclidean distance)는 벡터 사이의 직선 거리를 측정하여 0부터 무한대까지의 범위에서 유사성을 결정합니다. 동일한 벡터는 0으로 표시되고, 값이 클수록 벡터 간의 차이가 커집니다.
- 점 곱(Dot product) 유사성 측정은 마이너스 무한대에서 무한대까지의 범위에서 벡터 유사성을 결정합니다. 점 곱은 두 벡터의 크기와 그 사이의 각도의 코사인의 곱을 측정하여 서로 떨어진 벡터에는 음의 값을, 직교하는 벡터에 0을, 같은 방향을 가리키는 벡터에 양의 값을 할당합니다.
3️⃣ 후처리
벡터 데이터베이스 파이프라인의 마지막 단계는 때때로 후처리 또는 사후 필터링이며, 이 과정에서 벡터 데이터베이스는 다른 유사성 척도를 사용하여 최근접 항목의 순위를 다시 매깁니다. 이 단계에서 데이터베이스는 메타데이터를 기반으로 검색에서 식별된 쿼리의 최근접 항목을 필터링합니다.
일부 벡터 데이터베이스는 벡터 검색을 실행하기 전에 필터를 적용할 수 있습니다. 이런 경우, 이를 전처리(preprocessing) 또는 프리필터링(pre-filtering)이라고 합니다.
.jpeg)
헬로 아이엠군자. 굿투씨유