https://arxiv.org/abs/1706.03762
Architecture : Transformer
Abstract
- Transformer는 recurrence(RNN)나 convolutions(CNN)을 사용하지 않고 attention 메커니즘만을 사용한 sequence transduction model이다.
- Transduction : reasoning from observed specific (training) cases to specific (test) cases (위키피디아)
(참고) https://dos-tacos.github.io/translation/transductive-learning/
- Transduction : reasoning from observed specific (training) cases to specific (test) cases (위키피디아)
- 장점: Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
1. Introduction
-
사용 분야와 SOTA 모델 역사…
-
Recurrent neural networks
- Long short-term memory (LSTM)
- Gated recurrent neural networks (GRN) → sequence modeling and transduction problems such as language modeling and machine translation
- Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures.
-
기존의 recurrent models : 입출력 시퀀스를 symbol positions (기호의 위치 = 단어의 순서)에 따라 순차적으로 처리. 위치(position)을 time step에 맞춰 정렬 - 이것이 이전 hidden state 과 input for position 의 function으로 hidden states 의 시퀀스를 생성함.
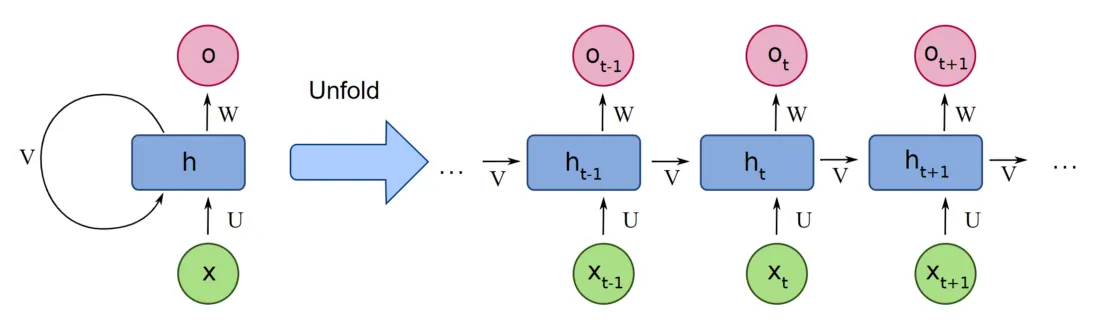
(이미지 출처: https://www.analyticsvidhya.com/blog/2022/03/a-brief-overview-of-recurrent-neural-networks-rnn/)
-
기존의 recurrent models 단점 : 병렬화 못함 → 시퀀스 길이가 길어질수록 메모리 제약으로 인해 examples 간의 배치 처리 제한됨
-
최근(논문 기준)의 연구들 - factorization tricks, conditional computation을 통해 계산 효율성 향상 / conditional computation은 모델 성능도 개선함
-
그럼에도 순차적 계산(sequential computation)의 근본적인 제약은 여전히 남아 있음 : 입력 시퀀스가 길어질수록 단어 사이 거리가 멀수록 관계를 잘 포착하지 못함
-
Attention 메커니즘은 다양한 작업에서 강력한 sequence modeling과 transductive model의 필수적인 부분이 되었으며, 시퀀스 내 토큰 간의 거리에 관계 없이 의존성(dependencies)을 모델링할 수 있게 해줌
-
하지만 몇몇 케이스를 제외하고 전부 다 attention 메커니즘을 RNN과 함께 사용함
-
Transformer
- 기존의 순환 구조(recurrence)를 피하고, attention 메커니즘만으로 시퀀스를 처리
- 입력과 출력 사이의 전역적인 의존성(global dependencies)을 파악하는 데 있어서, 멀리 떨어진 단어들 사이의 관계까지도 효과적으로 파악할 수 있도록 설계됨
- 순차적으로 처리하는 방식이 아니기 때문에, 병렬화(parallelization)가 훨씬 더 잘됨 → 훈련 속도 증가, 연산 자원 활용 효율 향상
2. Background
-
(Transformer가 등장하기 전까지의 주요 시퀀스 모델링 패러다임의 진화)
-
기존 모델들(Extended Neural GPU, ByteNet, ConvS2S)도 Transformer와 마찬가지로 sequential computation을 줄이기 위해, 입력과 출력 포지션들의 hidden representations를 병렬적으로 연산 가능한 CNN 구조 사용함
But 이 모델들에서는 두 위치(position)에서 신호를 연관시키는 데 필요한 연산 횟수가 위치(position) 사이 거리에 따라 ConvS2S는 linearly, ByteNet은 logarithmically 증가함 → 거리가 멀수록 둘 사이 의존성 학습하기 어려워짐 (Long-term dependency 학습 어려움)
-
→ Transformer는 위치(position) 사이 거리에 상관없이 일정한 연산 횟수로 관계를 포착한다는 장점 by self-attention 메커니즘
- Attention weight을 통한 평균이라는 방식으로 인한 reduced effective resolution 문제(정확한 위치 정보나 세밀한 구별 능력(resolution)이 줄어드는 부작용)가 있기는 하나 (i.e. 한 토큰이 여러 위치(position)의 정보를 ‘평균적으로’ 받다 보니 디테일한 구분이 어려울 수 있다는 것),
- 이것은 Multi-Head Attention 기법을 사용해 보완됨
-
두 포지션 간 관계를 학습할 때 필요한 연산 횟수의 비교
모델 연산 횟수
(d: 두 위치(position) 간 거리)설명 ConvS2S O(d) 인접한 위치만 한 번에 처리함
멀리 있는 위치까지 도달하려면 여러 층이 필요함ByteNet O(log d) Dilated Convolution으로 범위를 빠르게 확장 가능함 Transformer O(1) 모든 위치들이 self-attention을 통해 동시에 접근 가능함 -
Self-attention
- 시퀀스의 표현(representation)을 계산하기 위해서 한 시퀀스 내의 서로 다른 위치(position)들을 연관시키는 attention 메커니즘
-
End-to-End Memory Networks
- 2015년 Facebook AI Research에서 제안한 모델
- 기계가 기억을 갖고 있는 것처럼 여러 개의 정보를 저장하고 이를 참조하면서 질의에 답할 수 있는 구조
- 일반적인 RNN처럼 토큰 순서에 맞춰 순차적으로 처리하는 것이 아니라, ‘메모리에’ attention을 반복적으로 적용함
- 비교적 단순한 질의응답(QA)이나 언어 모델링에서는 효과적인 성능을 보임
-
Transformer : sequence-aligned RNNs나 convolution을 사용하지 않고 입력과 출력의 표현(representation)을 계산하기 위해 self-attention에만 전적으로 의존한 최초의 transduction model임
3. Model Architecture
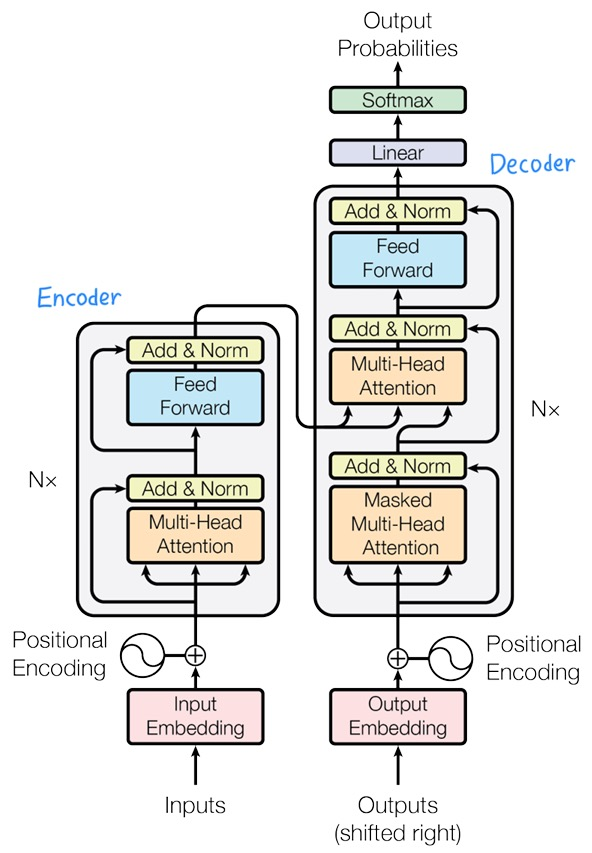
<Transformer 구조 간단 정리>
-
Encoder layers의 맨 처음 input sequence : symbol representations (, ..., )
↓ input embedding
continuous representations (, ..., )
-
N개의 encoder blocks를 거쳐 정제된 를 decoder의 입력으로 이용해 N개의 decoder blocks를 거쳐 출력 시퀀스를 생성
- 한 time 당 요소(element) 하나씩 생성함 = auto-regressive: 이전에 생성된 symbol을 다음 생성 시의 추가 입력으로 사용
-
(참고) Symbol이란?
- 자연어의 물리적인 표현 단위
- 문자 단위 (예: ‘a’, ‘b’, ‘가’)
- 단어 단위 (예: ‘apple’, ‘사과’)
- subword / token 단위 (예: ‘app’, ‘##le’, ‘사’, ‘과’) 등
3.1 Encoder and Decoder Stacks
Encoder
- N = 6개의 동일한 레이어(블럭) 스택으로 구성됨
- 한 레이어(블럭)의 구조
-
Multi-head self-attention mechanism
-
Add (residual connection) & Layer normalization
-
Position-wise fully connected feed-forward network
-
Add (residual connection) & Layer normalization
-
- Residual connection을 위해 임베딩 레이어와 모든 하위 레이어들의 출력 차원 통일:
(출력 차원 통일의 이유가 오직 residual connection 하나뿐인 것은 아님. Multi-head attention 구현 시 쿼리, 키, 밸류를 여러 헤드로 분할하고 최종적으로 다시 합칠 때 각 프로젝션 행렬의 크기를 일정하게 유지하기 위해서, 파라미터 절감 및 학습 안정성을 위해서, 고정된 크기의 배치 연산을 통한 훈련 속도 증가를 위해서 등의 이유가 있음!)
Decoder
- N = 6개의 동일한 레이어(블럭) 스택으로 구성됨
- 한 레이어(블럭)의 구조
- Masked multi-head self-attention mechanism
→ 병렬적으로 연산하되 후속 위치에는 attend하지 않도록 해야 하므로 (auto-regressive decoding) - Add (residual connection) & Layer normalization
- Multi-head attention mechanism
→ Encoder 스택의 출력에 대해 multi-head attention 연산 (decoder sequence 내의 attention이 아닌, 현재 생성할 decoder output token 하나와 encoder output sequence와의 attention이므로 self 아님!) - Add (residual connection) & Layer normalization
- Position-wise fully connected feed-forward network
- Add (residual connection) & Layer normalization
- Masked multi-head self-attention mechanism
3.2 Attention
⭐ Model architecture의 주황색 attention 블럭들
📌 Attention mechanism에 대한 기본적인 선수 지식 필요
- Attention function : 쿼리(a query) & 키-값 쌍들(a set of key-value pairs)을 출력에 맵핑하는 것
- Query, key, value는 모두 벡터
- Attention function의 출력 : 주어진 query에 대해, 각 key와의 유사도(compatibility function)를 기준으로 계산된 가중치를 이용해 value들을 가중합한 결과
(1) Scaled Dot-Product Attention
- : Query와 key 벡터의 차원
- : Value 벡터의 차원
- 이론적으로는 query 하나하나마다 모든 key-value쌍 개수만큼의 가중치를 구해 최종 가중합 스칼라값 하나를 구하는 것이 attention 메커니즘이지만,
실제로는 빠른 연산을 위해 모든 query들에 대해 동시에 행렬로 연산함 ( : query matrix)
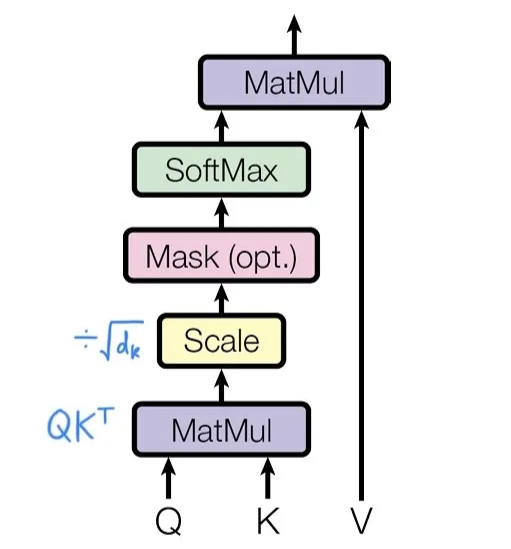
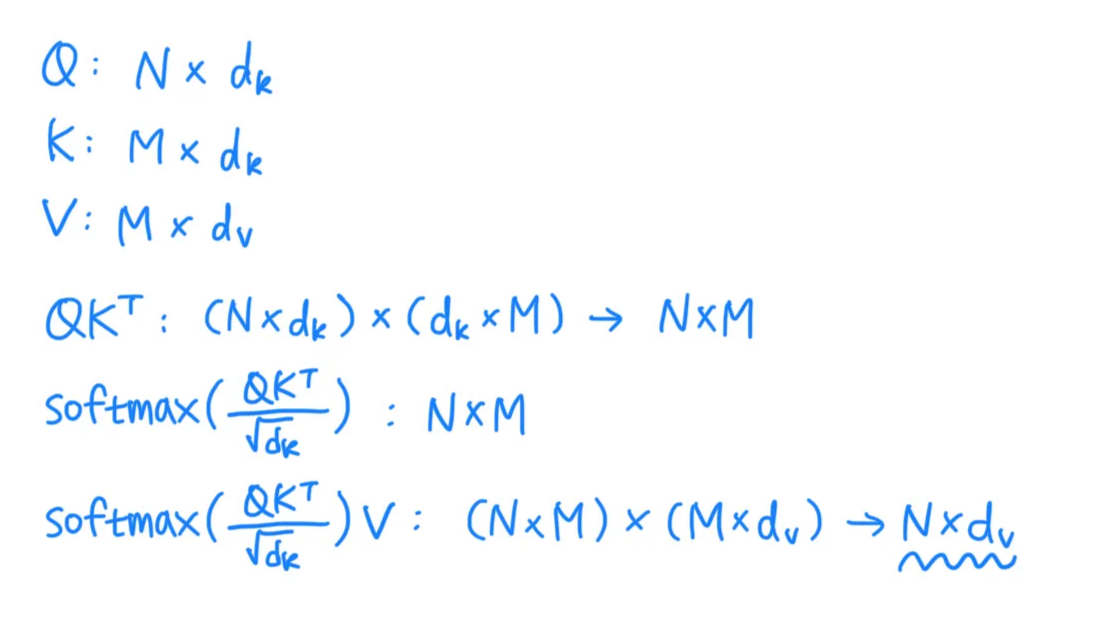
- 가장 흔히 사용되는 attention function 2가지
-
Additive attention (Bahdanau Attention)
:
-
Dot-product (multiplicative) attention
:
-
- Dot-product attention이 더 빠르고 공간 효율적임
- But 가 큰 값일 때에는 additive attention이 더 성능이 뛰어남
- Why? Query와 key의 요소들이 정규분포(평균 0, 분산 1)를 따른다고 가정할 때, 그들의 dot product는 평균이 0이고 분산이 가 됨
→ 가 커질수록 dot product의 분산이 커짐
→ 큰 값에 softmax 함수를 적용하면 0 혹은 1에 치우치게 되고, 기울기는 0에 수렴함 (Gradient Descent problem) : dot-product attention without scaling의 단점
⇒ Dot-production의 효율적인 장점을 이용하면서도 단점을 보완하기 위한 해결책 : scaled dot-product attention !!
(2) Multi-Head Attention
- 차원의 queries, keys, values에 대해 attention을 한 번만(single) 수행하는 것보다 서로 다르게 학습시킨 linear projection을 이용해 를 만들어 번의 attention을 수행하는 것이 더 좋음
- 각 attention head마다의 queries, keys, values는 여러 버전으로 project됨
- 개의 attention heads의 연산은 병렬로 한꺼번에 수행되고, 모든 heads에서 출력값의 차원은
→ 모든 heads의 출력값을 concat해서 한 번 더 project
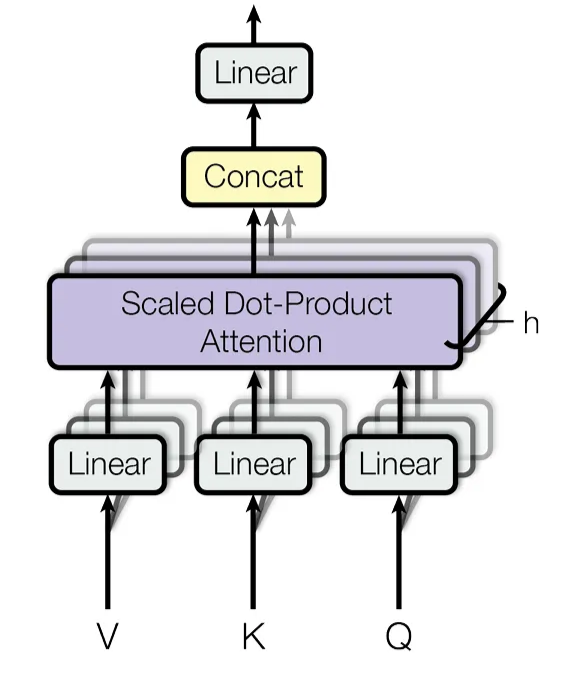
- 본 논문에서는 의 병렬 attention layers(heads)를 적용함
(➕ 3.1에서 로 구현했다고 나와 있음)
→ 각 query, key, value의 차원은
- 각 헤드마다 차원이 감소되었으므로(), 8개의 attention heads에서 수행하는 연산과 에서의 single-head attention 연산의 computational cost는 비슷함
- Multi-head attention을 하는 이유
⇒ 모델은 서로 다른 representation subspace에서 동시에 정보를 추출하고, 위치별로 다양한 특징(구문, 의미, 형태 등)에 주목할 수 있게 됨
(3) Applications of Attention in our Model
: Transformer가 multi-head attention을 사용하는 3가지 방법
-
“Encoder-decoder attention” layers
- Query : 이전 decoder 레이어의 출력
- Keys and values : encoder의 (최종) 출력값
→ Decoder가 문장을 생성할 때마다 encoder가 처리한 전체 입력(memory) 중
어느 위치(position)에 주목(attend)할지 동적으로 계산함 -
Encoder의 self-attention layers
- Query, keys and values : 한 시퀀스(이전 encoder 레이어의 출력)로부터 생성됨
→ 인코딩 과정에서 각 위치(position)들은 한 문장 내 모든 위치들과의 관계에 전부 주목(attend)할 수 있게 됨
-
Decoder의 self-attention layers
→ Decoder의 각 위치가 해당 위치를 포함한 모든 위치에 주목할 수 있도록 함
- Encoder의 self-attention과 다른 점 : “auto-regressive” ⇒ 아직 생성되지 않은, 미래의 timestep의 위치에 대해서는 로 마스킹 처리
- Encoder의 self-attention과 다른 점 : “auto-regressive” ⇒ 아직 생성되지 않은, 미래의 timestep의 위치에 대해서는 로 마스킹 처리
3.3 Position-wise Feed-Forward Networks
⭐ Model architecture의 파란색 feed-forward 블럭들
- 각 위치(position) 별로 독립적으로 적용되는 fully connected feed-forward network
- 선형 변환 1 → ReLU → 선형 변환 2
- 레이어(블럭)마다 다른 파라미터를 사용함 i.e. 같은 레이어 안의 모든 위치에 대해 동일한 파라미터를 사용하지만, feed-forwarding은 위치 별로 각각 적용됨
- 입출력 차원
- 내부 레이어 차원
3.4 Embeddings and Softmax
- 입력 토큰 & 출력 토큰 → 차원 벡터로 임베딩
: 학습된 임베딩 이용 - Decoder 출력 → 예측된 다음 토큰 확률
: 일반적인 학습된 선형 변환 및 softmax 함수 이용 - 입력 임베딩 레이어, 출력 임베딩 레이어, softmax 직전의 선형 변환에서 동일한 가중치 행렬 사용
- 임베딩 레이어에서는 가중치를 로 나누어 스케일링
- 왜 동일한 가중치를 공유하는가?
- 파라미터 절감
서로 다른 세 개의 가중치 행렬 대신 하나만 학습하므로 전체 파라미터 수 감소 - 학습 안정성
임베딩과 출력 projection이 같은 공간을 쓰면서, 역전파 신호가 공유된 의미 표현을 더욱 견고하게 만듦
입력과 출력 공간이 동일하게 맞춰져, 토큰 간 의미론적 대응이 자연스럽게 학습됨 - 성능 향상
번역 품질과 수렴 속도를 개선하는 것이 실험적으로 알려짐
- 파라미터 절감
3.5 Positional Encoding
Attention 메커니즘에는 recurrence 없음 (순차적 처리 X, 병렬 처리 O), convolution 없음 (공간적 정보 활용 X)
⇒ 시퀀스의 순서를 활용하기 위해서는 시퀀스 내 토큰의 상대적/절대적 위치에 대한 정보를 추가적으로 주입해야 함: positional encoding
- 임베딩 차원()과 동일한 차원을 갖는 positional encoding 벡터 : 임베딩 벡터와 더해주기 위함
( : 위치(position), : 차원(dimension))
- 위 정현파 함수의 주기가 등비수열로 부터 까지 커짐
<장점>
✔️ 규칙 기반이므로 시퀀스 길이에 제한이 없음
- 사인/코사인은 수학적인 함수이므로, 시퀀스 길이가 훈련 시보다 길어져도 계산해서 그대로 위치 인코딩 값을 생성할 수 있음
✔️ 상대적 거리 정보를 잘 보존
- 사인/코사인 기반 인코딩은 가 의 선형함수로 표현될 수 있기 때문에, 상대 위치 정보를 자연스럽게 반영할 수 있음
- https://velog.io/@gibonki77/DLmathPE (참고하면 좋음)
✔️ 학습하지 않는 고정된 인코딩 → 일반화에 유리
- 학습 기반 위치 임베딩은 훈련된 범위를 벗어나면 위치 정보를 일반화하기 어려움
- 반면, 사인/코사인 방식은 훈련 당시 본 적 없는 더 긴 문장이나 시퀀스에 대해서도 자연스럽게 위치 표현 가능
4. Why Self-Attention
 $n$ : 입력 시퀀스 길이, $d$ : 표현(representation) 차원, $k$ : 합성곱 커널 크기
👍 모든 위치에서의 self-attention을 전부 **병렬화** 가능
$n$ : 입력 시퀀스 길이, $d$ : 표현(representation) 차원, $k$ : 합성곱 커널 크기
👍 모든 위치에서의 self-attention을 전부 **병렬화** 가능

-
인 경우 - 기계 번역의 SOTA 모델들의 문장 표현에서 가장 흔함

-
Self-attention : 매우 긴 시퀀스 ( >> ) 에서는 계산 복잡도가 엄청나게 커지는 단점
→ Restricted self-attention을 도입

: restricted self-attention의 이웃 크기
(* 위치 의 query는 범위의 key-value 쌍만 참조함)
-
A single convolutional layer

-
: 출력 위치 하나가 볼 수 있는 입력의 범위(수용 영역, receptive field)가 제한됨
→ 시퀀스 길이 안에서 모든 임의의 두 위치 간 정보를 한 계층만으로 직접 주고받을 수 없음 -
모든 입력-출력 쌍을 연결하기 위한 필요 계층 수
-
연속 커널:
-
확장(dilated) 커널
→ 두 위치 사이 최대 경로 길이 증가 ⇒ long-term dependency 학습 어려움
-
-
-
Separable convolutions는 로 복잡도를 상당히 낮출 수 있음
but 일 때(합성곱 층을 하나만 이용할 때)조차 이것은 Transformer 모델이 채택한 self-attention layer() + point-wise feed-forward layer() 방식과 동일한 복잡도를 가짐
👍 Long-range dependency의 문제점 해결: Transformer 모델은 대응관계가 있는 토큰들 간의 물리적인 거리값들 중 최댓값이 다른 모델에 비해 매우 짧아 장거리 의존성(long-range dependency)을 잘 학습할 수 있고 시퀀스 변환 문제도 잘 해결할 수 있음
- Long-range dependency 학습 문제
- 그래디언트 소실(vanishing)∙폭발(exploding)
많은 층(layer) 또는 시퀀스 스텝(step)을 거치며 기울기가 점점 작아지거나 커져, 멀리 떨어진 입력–출력 간의 관계를 안정적으로 학습하기 어려워집니다. - 정보 희석
긴 경로를 지나는 동안 정보가 왜곡∙소실되어 실제로 필요한 신호가 약해집니다.
- 그래디언트 소실(vanishing)∙폭발(exploding)
👍 해석 가능한 모델: 'Attention' 이라는 가중치를 시각화하여 토큰들 간의 대응관계를 눈으로 직접 확인 가능
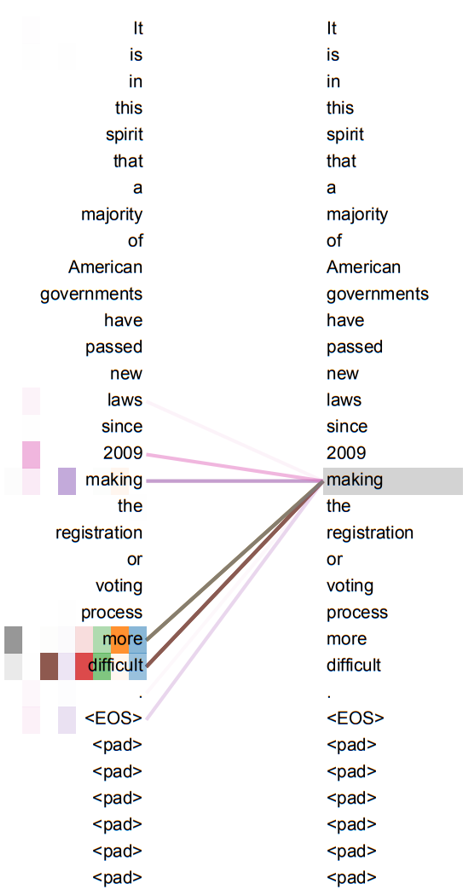 encoder self-attention
encoder self-attention

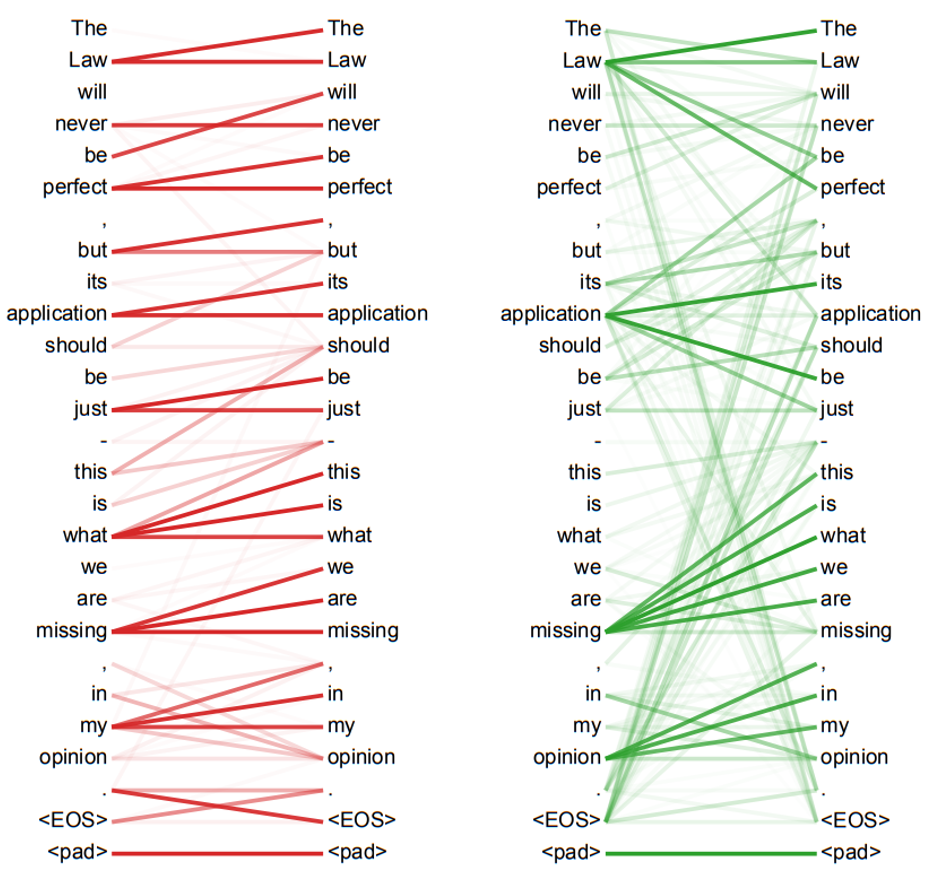 encoder self-attention heads
encoder self-attention heads
7. Conclusion
- Transformer : the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention
- 영어-독일어, 영어-프랑스어 번역 과제에서 SOTA 달성
- 향후 연구 계획
- 번역뿐만 아니라 다른 과제들에도 적용해보는 것
- 입출력 형식이 텍스트 이외에도 다른 모달리티도 포함할 수 있도록 하는 것
- Making generation less sequential
