[DPO] Direct Preference Optimization: Your Language Model is Secretly a Reward Mode
Paper Review
Direct Preference Optimization: Your Language Model is Secretly a Reward Mode 논문 리뷰
RL Background
- Policy Gradient Methods
- 직접적인 정책 최적화
- Likelihood Ratio Trick (로그 미분 트릭): Objective function 의 그래디언트를 계산할 때, 미분 불가능한 기댓값 내부의 확률 분포를 형태로 바꾸기
- Advantage Function (): 보상()을 사용하는 대신, '평균보다 얼마나 더 좋은가'를 뜻하는 Advantage를 곱함 — 분산(Variance)을 줄이기 위해 도입됨
- 단점 (High Variance & Step Size): 한 번의 업데이트가 정책을 너무 크게 바꿔버리면(Bad update), 모델이 아예 망가져 버림
- 데이터 효율성 ↓ (On-policy의 한계)
- Importance Sampling
- Sample from different distribution
- 과거의 정책 로 수집한 데이터를 현재 정책 의 업데이트에 재사용할 수 있게 됨
- Sample from different distribution
- TRPO (Trust Region Policy Optimization)
- PG의 '불안정한 업데이트' 문제를 수학적인 제약 조건(constraint)으로 해결하려 함
- Surrogate Objective: 현재 정책과 이전 정책의 확률 비율 을 사용하여 목적 함수를 정의함
- Trust Region (신뢰 영역): 업데이트 전후의 정책 차이가 너무 크지 않도록 KL-Divergence를 사용하여 제약 조건을 걺
- 단점 (Second-order Optimization): 이 제약 조건을 풀기 위해 Fisher Information Matrix(Hessian)를 계산하고 인버전(Inverse)해야 함 — 계산 복잡도가 너무 높고 구현이 매우 어려움
- PPO (Proximal Policy Optimization)
- Clipped Surrogate Objective
- 비율 ()가 일정 범위를 벗어나지 못하도록( 구간 안에 속하도록) clipping
- i.e., 확률 비율 가 이라는 기존 상태에서 와 라는 범위를 벗어나 너무 커지거나 작아지는 것을 방지!
- Adaptive KL Penalty Coefficient
- KL-Divergence를 제약 조건이 아닌 페널티 항으로 목적 함수에 직접 포함
- PPO의 핵심 아이디어:
- 환경과 상호작용하여 데이터를 샘플링하고, 이 데이터를 여러 번 반복하여(multiple epochs) "surrogate objective function"을 업데이트하는 것
- PG보다 더 효율적이고 안정적인 학습을 가능하게 함
- Clipped Surrogate Objective
⁕ TRPO / PPO: Importance Sampling을 쓰긴 하지만, 방금 얻은 데이터()와 현재 업데이트 중인 정책()이 거의 비슷할 때만 그 데이터가 유효하므로 on-policy
| 특징 | TRPO (Trust Region) | PPO (Proximal Policy) |
|---|---|---|
| 도구 | Importance Sampling | Importance Sampling |
| 안전장치 | KLD Constraint (Hard Constraint) | Objective Clipping (Soft Constraint) |
| 수학적 난이도 | 높음 (2차 미분, Hessian 사용) | 낮음 (1차 미분, Clip 함수 사용) |
| 학습 안정성을 위해 | "내 보폭이 를 넘지 않게 계산해!" | "보폭이 너무 크면 그냥 잘라버려!" |
0. Abstract
RLHF에서 reward model의 새로운 parameterization을 도입하여 대응하는 최적 정책(optimal policy)을 closed form으로 추출할 수 있게 함으로써, 단순한 classification loss만으로 표준 RLHF 문제를 해결할 수 있도록 함
1. Introduction
- 기존 방법들이 사용하는 RL 기반 목적 함수를 단순한 Binary Cross-Entropy objective function으로 정확하게 최적화할 수 있음 — 선호도(preference) 학습 파이프라인 단순화
- 명시적인 보상 모델링이나 강화학습 없이 인간의 선호도를 따르도록 언어 모델을 직접 최적화
- DPO 알고리즘은 기존 RLHF와 동일한 목표(=KL-divergence 제약 하에서 보상을 최대화하는 것)를 달성하면서도 구현이 훨씬 간단하고 학습이 용이함
- DPO의 핵심 아이디어: 선호되는 응답(preferred response)의 확률을 높이고 선호되지 않는 응답(dispreferred response)의 확률을 낮추는 것 (i.e., 선호되는 응답과 선호되지 않는 응답 간의 로그 확률 비율(relative log probability)을 조절하여 학습을 진행함)
- 각 학습 쌍(preference pair)에 대해 동적으로 계산되는 importance weight을 도입 — 모델 퇴화(model degeneration) 현상 방지 (*모델 퇴화: 모델이 특정 높은 보상을 얻기 위한 행동만 반복하거나 의미 없는 응답을 생성하는 등 바람직하지 않은 행동을 보이는 것)
- 기존 방법론들과 마찬가지로 인간의 선호도 데이터를 수학적으로 모델링하는 이론적 프레임워크(Bradley-Terry 모델)에 기반 but 보상 모델 학습 대신 정책 최적화에 직접 적용
- Change of variables: 보상 모델을 명시적으로 학습하는 대신, preference loss 자체를 LM의 정책 함수로 정의
2. Related Work
- 기존 연구들의 단점
- Online으로 preference 데이터를 수집
- 별도의 reward model을 학습시킨 뒤 RL을 적용하는 복잡하고 비효율적인 과정
- PbRL (기존 RLHF) : "선호도 데이터 → 보상 모델 → 정책 최적화"
Single stage policy learning (DPO) : "선호도 데이터 → (이론적 변환) → 정책 직접 최적화”
3. Preliminaries
RLHF 파이프라인 개요 (Ziegler et al. https://arxiv.org/pdf/1909.08593 기반)
- SFT (Supervised Fine-Tuning): Pre-trained LM을 특정 작업(downstream task)에 맞는 고품질 데이터로 추가 학습(fine-tuning)시켜 기본 성능을 향상시킴
- Reward Modelling Phase
- Preference Sampling and Reward Learning : SFT 모델이 생성한 여러 응답에 대해 인간이 선호하는 응답을 선택하는 데이터를 수집하고, 이를 기반으로 human preference를 나타내는 reward model 학습
- : Bradley-Terry model (인간의 선호도 분포를 수학적으로 나타냄)
- 프롬프트 에 대해 생성된 응답 쌍
- : Reward model을 학습시키기 위한 loss function
-
Framing the problem as a binary classification → Negative Log-likelihood Loss
-
: 로부터 샘플링된 데이터셋
-
: Logistic function (=sigmoid)
보상 모델 가 인간의 선호도 데이터셋 에 있는 각 쌍 에 대해, 선호하는 응답 의 보상 점수가 비선호하는 응답 의 보상 점수보다 높을 확률(= )을 최대화하도록
i.e., 인간이 실제로 선호하는 응답에 더 높은 점수를 부여하도록 보상 모델을 학습시키는 것
-
- RL Fine-Tuning Phase
- 정책 최적화 : 학습된 보상 모델()을 사용하여 언어 모델(LM)의 정책(policy, )을 RL(PPO)으로 최적화
- KL-divergence와 같은 제약 조건(constraint)을 통해 모델이 원본 모델에서 크게 벗어나지 않도록 함
- Reward model이 정확한 분포에서 너무 멀리 벗어나는 것 방지
- 생성의 다양성 유지
- 단일한 높은 보상의 답변으로 mode-collapse 방지
- 정책 최적화 : 학습된 보상 모델()을 사용하여 언어 모델(LM)의 정책(policy, )을 RL(PPO)으로 최적화
4. Direct Preference Optimization
- 기존의 RLHF 방법들 : 보상을 학습한 후 RL을 통해 이를 최적화
↔ DPO : RL 훈련 루프 없이 closed form으로 최적 정책을 추출할 수 있게 하는 특정 보상 모델 파라미터화(parameterization) 선택을 활용 - Analytical mapping : 보상 함수로부터 최적 정책을 도출할 수 있는 직접적인 수학적 관계
- Change-of-Variables : Analytical mapping을 활용하여, 학습 목표를 '보상 함수 최적화'에서 '정책 자체의 직접 최적화'로 변경 (보상 함수에 대한 손실 함수를 정책에 대한 손실 함수로 변환) → Policy network는 단순히 LM만을 나타내는 것을 넘어 인간의 선호도를 반영한 (implicit) reward 역할까지 수행할 수 있게 됨
Deriving the DPO objective
The optimal solution to the KL-constrained reward maximization objective
-
유도 과정


- : 주어진 입력 에 대해 출력 를 생성할 확률
- : Reference LM의 정책 확률 (일반적으로 Pre-trained LM이나 SFT 모델 사용)
- : Reward function
- : KL-divergence constraint 강도 조절 스케일링 파라미터
- : 정규화 항(partition function), 모든 가능한 출력 에 대한 확률의 합이 1이 되도록. ()
→ 추정하는 것 expensive 🙁
⇒ 위 식의 양 변에 log 취하고 재배열 : Reparameterization
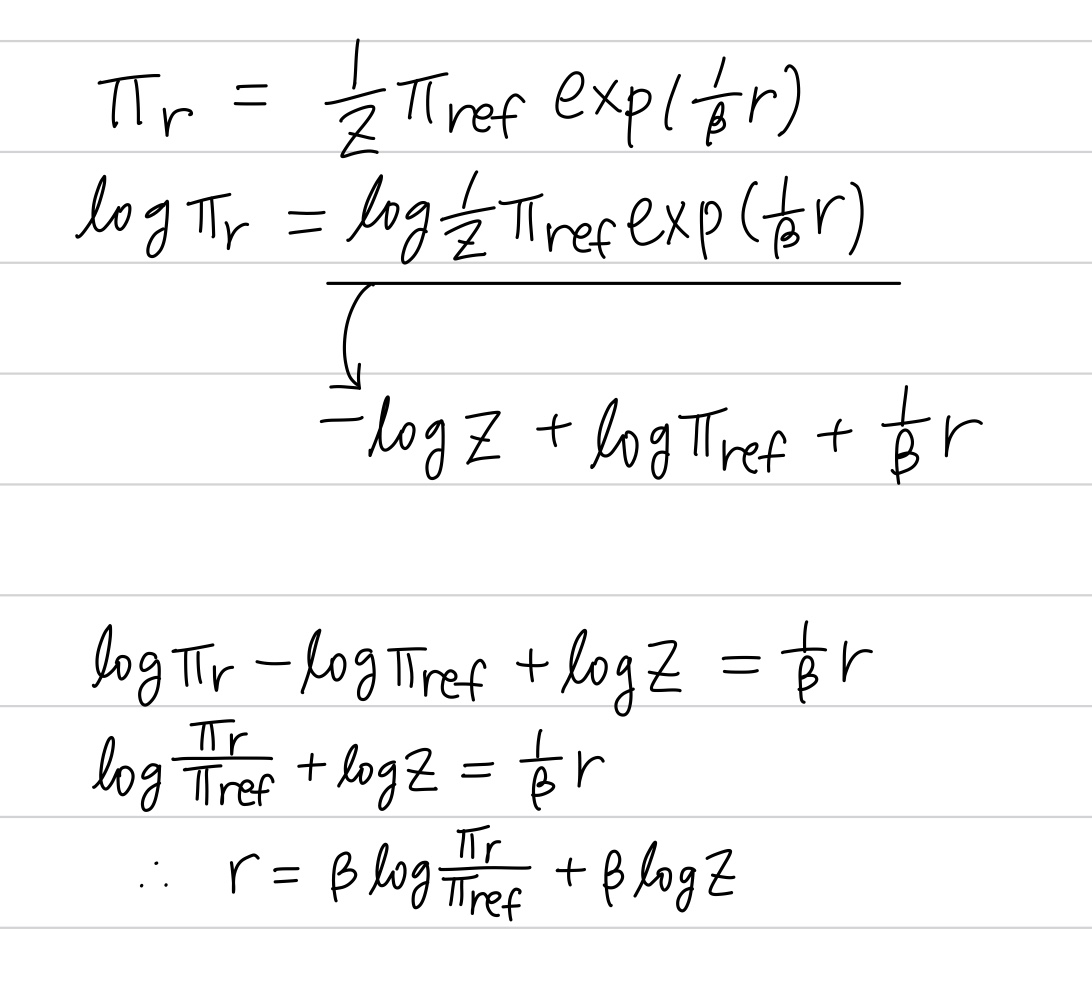
- Bradley-Terry model은 두 응답에 대한 절대적인 보상 값이 아니라, 두 보상 값의 차이만을 사용하여 선호도 확률을 계산 = 보상 함수에 어떤 임의의 상수값 를 더해도(즉, 와 같이 변환해도) 두 응답 간의 선호도 확률 는 변하지 않음을 의미 = 모델이 절대적인 보상 스케일에 얽매이지 않고 상대적인 선호도를 학습할 수 있음
- 선호도 확률을 보상 함수 대신, 학습하고자 하는 최적 정책 와 레퍼런스 정책 사이의 관계로 표현
- 는 상쇄됨 ()
Policy Objective
- 보상 모델을 명시적으로 학습하는 대신, 위 수식에서처럼 인간의 선호도 데이터()를 직접 사용하여 LM policy()를 간단한 classification loss(binary cross-entropy)로 업데이트
- 암묵적 보상 함수 학습 + 최적 정책 도출
- RL 트레이닝 루프 제거 → 학습을 단순화하고 안정성 높임
DPO update
- 선호되는 응답 의 likelihood(생성 확률)를 ⬆️
비선호 응답 의 likelihood는 ⬇️
방향으로 업데이트 - : 암묵적 보상 모델이 두 응답의 순서를 얼마나 잘못 판단했는지(i.e., 이 보다 얼마나 더 좋은지를 잘못 판단한 정도)를 나타내는 가중치
- : 위 가중치의 강도를 조절; KL constraint 강도를 고려함
- 가 클수록 KL constraint 강하게 작용 → 참조 정책의 분포에서 크게 벗어나지 않도록 보수적 업데이트
DPO outline
- 프롬프트 에 대한 응답 샘플링
→ 인간 선호도로 레이블링하여 오프라인 데이터셋 구성 - LM 최적화 : 주어진 , , 원하는 에 대해 를 최소화하도록
- (SFT is available)
- (SFT is not available)
5. Theoretical Analysis of DPO
Your Language Model Is Secretly a Reward Model
-
4절의 ‘Deriving the DPO objective’ 섹션에서 도출된 objective function 은 Bradley-Terry 모델 과 equivalent
- 증명

- Lemma 1. 하나의 인간 선호도 데이터를 설명하는 보상 함수는 여러 개 존재할 수 있음!
- 만약 이라는 보상 함수가 어떤 선호도 데이터를 잘 설명함
- 그러면 (여기에서 는 에만 의존하는 임의의 값) 도 똑같은 선호도 데이터를 설명할 수 있음 ∵ 두 보상 값의 “차이”는 항이 사라져서 똑같기 때문
- Lemma 2. 같은 equivalence class에 속하는 두 보상 함수는 동일한 최적 정책을 유도함!
- KL-divergence 제약 조건이 동일하고, 최적화하려는 보상 함수의 차이만 동일하게 유지되기 때문에
- ⇒ 이상적인 보상 함수를 직접 찾는 대신, 그 보상 함수가 유도하는 “이상적인 최적 정책(= LM)”을 직접 학습할 수 있게 만드는 것이 DPO
: Bradley-Terry 모델에서 얻어지는 선호도 데이터에 대한 MLE와 동일한 형태!
- 증명
-
Bradley-Terry 모델: 인간 선호도에 내재된 보상 체계를 수학적으로 표현한 것 (두 보상 함수의 “차이”)
DPO objective: 보상 함수와 정책 사이의 수학적 관계 (reward reparameterization)
⇒ “Your Language Model Is Secretly a Reward Model” : "보상 함수 모델링 없이 최적 정책을 학습하는 것(= LM(정책)에 보상 모델의 기능이 내재되어 있음)으로 인간 선호도를 학습할 수 있다”
Instability of Actor-Critic Algorithms
- 기존 RLHF의 문제점: PPO와 같은 알고리즘은 objective function에 normalization term()이 포함됨 (실제로는 최적해에 영향을 주지 않지만, 이 term이 없으면 정책의 그래디언트 값에 큰 분산을 유발할 수 있음)
- 높은 분산(= 학습 불안정성)을 해결하기 위해 PPO에서는 별도의 value function을 학습하거나, human completion baseline을 활용해야 함
- But 이러한 추가적인 학습이나 추정 과정은 복잡성을 증가시키고 구현을 어렵게 만듦
- DPO의 장점:
Reward reparameterization ⇒ 명시적인 보상 모델 학습이나 RL 훈련 루프 없어도 최적 정책 직접 학습 가능
- 학습 과정에 추가적인 베이스라인이나 가치 함수 추정 없이도 안정적인 학습이 가능
: 구현의 간결성과 효율성을 크게 높임!
6. Experiments
- 하이퍼파라미터 튜닝을 거의 하지 않고도, DPO가 PPO를 이용한 RLHF와 같은 강력한 베이스라인과 비슷하거나 더 나은 성능을 보이는 경향 有
- DPO는 참조 정책 분포를 크게 벗어나지 않으면서 보상을 최대화하는 능력이 PPO 등의 기존 RLHF 알고리즘보다 뛰어남
(Reward/KL tradeoff 👍) - “Best of N” 방식 베이스라인과 비교했을 때도 경쟁력 있는 성능을 보임
- DPO는 샘플링 temperature 변화에 대해 PPO보다 훨씬 robust한 성능을 보임
7. Conclusion
- 인간의 선호도 학습: 강력하고 확장 가능한 접근 방식, capable and aligned LM 트레이닝에 중요
- DPO: 강화학습(RL) 없이 선호도 데이터를 통해 언어 모델을 훈련하는 간단한 방법을 제안함!
- 기존 RLHF 방식은 복잡한 RL 설정을 사용하는 반면, DPO는 LM 정책과 보상 함수 간의 매핑을 활용하여 직접적으로 인간의 선호도를 만족하는 모델을 트레이닝
- 단순한 cross-entropy loss 사용
- DPO의 장점:
- 단순함: RL 학습 루프를 제거. 구현과 훈련이 훨씬 간편함
- 안정성: 샘플링 과정이나 복잡한 하이퍼파라미터 튜닝 없이도 안정적인 성능
- 효율성: 실험 결과, PPO 기반 RLHF와 동등하거나 더 나은 성능을 달성하면서도 계산 가벼움
- 향후 연구 방향:
- 분포 외 일반화: DPO 정책이 명시적인 보상 함수를 학습한 모델과 비교하여 분포 외 데이터에 얼마나 잘 일반화되는지 추가 연구 必
- 보상 과적합: DPO 설정에서 보상 과적합이 어떻게 나타나는지, 그리고 Figure 3-right의 성능 감소가 이에 해당하는지 탐색 必
- 확장성: 현재 6B 매개변수 모델까지 평가되었으나, 훨씬 더 큰 최신 모델로 DPO를 확장하는 연구 必
- 자동 평가: GPT-4와 같은 자동 평가 도구의 프롬프트가 결과에 영향을 미치므로, 고품질 평가를 위한 최적의 프롬프트 설계 연구 必
- 다중 모달리티 적용: DPO는 언어 모델 외에 다른 모달리티(이미지, 오디오 등)의 생성 모델 훈련에도 적용될 수 있음
