Deep Reinforcement Learning from Human Preferences 논문 리뷰입니다.
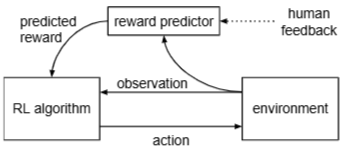
- env를 관찰(observation)하고 정책(RL algorithm)에 따라 행동(action)
- 이 때 정책(RL algorithm)은 reward predictor에 의해 예측된 보상(predicted reward)에 의해 최적화됨
- Human feedback을 받아서 reward predictor를 업데이트
에이전트-환경 상호작용:
- 환경(Environment)은 현재 상태에 대한 관찰(observation)을 RL 알고리즘(RL algorithm)에게 제공함
- RL 알고리즘은 이 관찰을 바탕으로 최적의 행동(action)을 결정하고 환경에 전달함
- 이 행동은 환경에 영향을 미쳐 다음 관찰을 이끌어냄
보상 예측기를 통한 학습:
- RL 알고리즘은 보상 예측기(Reward predictor)로부터 예측된 보상(predicted reward)을 받음
- RL 알고리즘은 이 예측된 보상을 최대화하는 방향으로 **자신의 정책(policy)을 업데이트**하며 학습함
i.e., 보상 예측기가 '좋다'고 판단하는 행동을 더 자주 하도록 학습
인간 피드백을 통한 보상 예측기 훈련:
- RL 알고리즘이 생성한 여러 행동 trajectory 또는 그 일부 세그먼트(segment)들이 보상 예측기의 훈련 데이터로 사용됨
- 인간(Human)은 이 trajectory segment들을 비교하고 어느 쪽이 더 나은지에 대한 피드백(human feedback)을 제공
- 보상 예측기는 이러한 인간의 피드백을 학습하여, 앞으로 에이전트의 행동에 대해 더 정확하게 보상을 예측할 수 있도록 업데이트됨
이 메커니즘은 순환적으로 작동함!
에이전트가 행동하고, 그 결과에 대해 인간이 피드백을 주고, 그 피드백으로 보상 예측기가 정교해지며, 정교해진 보상 예측기가 에이전트의 학습을 더 효과적으로 이끄는 것
이를 통해 명시적인 보상 함수 없이도 인간의 의도를 반영한 복잡한 행동을 학습할 수 있게 됨!
(Prior work와 비교했을 때) Key contribution:
Human feedback을 deep RL로 확장(scaling)하고, 훨씬 더 복잡한 행동을 학습하는 것
전통적인 RL ()처럼 env가 reward signal을 생성한다고 가정하는 대신,
Trajectory segments 간의 선호도(preference)를 표현할 수 있는 인간 감독자(human overseer)가 있다고 가정함
- Trajectory segment: 관찰과 행동의 시퀀스
(에이전트의 목표는 인간이 선호하는 trajectory를 생성하는 동시에 인간에게 가능한 한 적은 쿼리를 하는 것)
- 정량적 평가: : 이 더 선호된다는 뜻 (= 시퀀스에서의 총 보상의 합이 더 큼 — 인간의 선호도가 어떤 (알려지지 않은) reward function 을 따르고 있다고 가정한 상태)
- 정성적 평가: 명확한 보상 함수(reward function)가 존재하지 않아 에이전트의 성능을 수치적으로 평가하기 어려운 상황에서 사용
- 자연어로 된 목표를 설정
- 인간 평가자에게 에이전트의 행동을 보여줌 → 해당 행동이 자연어로 정의된 목표를 얼마나 잘 충족하는지 평가하도록
- 에이전트가 목표를 달성하기 위해 시도하는 과정을 담은 비디오를 제시 → 인간 평가자가 이를 보고 판단
- 명확한 보상 함수가 없는 복잡한 작업에서 강화 학습(RL) 에이전트를 훈련하는 것을 목표로
- 핵심 아이디어: 에이전트의 행동에 대한 인간의 선호도를 사용하여 보상 함수를 학습하고, 학습된 보상 함수를 통해 에이전트를 훈련하는 것
- 주요 구성 요소:
- 정책 (): 에이전트가 관찰(observation, )을 기반으로 어떤 행동(action, )을 취할지 결정하는 함수. (DNN으로 매개변수화됨)
- 보상 함수 추정치 (): 인간의 선호도를 기반으로 학습된, 각 관찰-행동 쌍에 대한 보상 값을 예측하는 함수. (DNN으로 매개변수화됨)
- 정책 (): 에이전트가 관찰(observation, )을 기반으로 어떤 행동(action, )을 취할지 결정하는 함수. (DNN으로 매개변수화됨)
- 업데이트 프로세스:
-
정책 상호작용:
에이전트()는 환경과 상호작용하여 일련의 trajectory()를 생성생성된 는 보상 함수 추정치()를 사용하여 얻은 예측 보상을 최대화하도록 정책()을 업데이트하는 데 사용됨
-
선호도 수집:
1단계에서 생성된 들로부터 짧은 trajectory segment 쌍()을 선택 (i.e., 여러 번의 시뮬레이션 중에 짧은 클립 2개 선택)인간이 이 둘 중에 어느 것을 더 선호하는지에 대한 피드백 수집
-
보상 함수 학습:
인간으로부터 수집된 모든 비교 데이터를 사용하여 보상 함수 추정치()를 지도 학습(supervised learning) 방식으로 최적화인간이 특정 trajectory segment 쌍을 선호할 확률을 예측하는 모델을 학습
비동기적(asynchronously) 작동:
위 세 프로세스는 서로 연결되어 있지만 독립적으로 실행됨
-
1단계에서 생성된 trajectory는 2단계로 흘러감
-
2단계에서 수집된 human feedback은 3단계로 흘러감
-
3단계에서 업데이트된 보상 함수 추정치의 매개변수는 1단계에서 정책 업데이트에 사용됨
인간의 선호도를 모방하는 보상 함수를 학습하면서 동시에 그 보상 함수를 최대화하는 정책을 발전시키는 것
-
보상 함수()가 human feedback에 따라 계속 학습되면서 비정상적(non-stationary)일 수 있음
- Policy gradient methods와 같은 방법론에 집중
- Atari 게임 : A2C
- 로보틱스 : TRPO
- Reward normalization
(⬆️ 두 trajectory segment 에 대해 인간이 을 선호할 확률)
분자 값이 큼 = 에서의 보상 추정치 총합이 큼 = 를 더 선호할 확률이 높음
Luce-Shephard choice rule: 두 trajectory segment 보상 총합 간 차이가 클수록 해당 trajectory 선호할 확률이 높아짐
Cross Entropy Loss
모델이 인간이 선호한 trajectory segment에 대해 높은 선호 확률을 예측하도록 학습, 잘못된 예측에 대해 높은 페널티를 부과
Bradley-Terry model:
- 여러 항목(trajectory segment) 중에서 pairwise(쌍으로) 주어지는 선호도 데이터를 사용하여 각 항목의 '점수'()를 추정하는 데 사용됨
- 보상 함수를 직접 설계하는 대신 인간의 선호도를 학습하여 RL 에이전트를 훈련시킬 수 있음
인간의 피드백을 실시간으로 반영하여 보상 예측기를 지속적으로 업데이트하는 온라인 방식이나, 인간의 선호도 데이터를 직접 사용하여 보상 함수를 학습하는 방식을 더 선호
(↔ 이전 훈련 단계에서 수집된 고정된 데이터셋만을 사용하여 보상 예측기를 학습시키는 오프라인 방식)
