AlphaZero
Mastering the game of Go without human knowledge 논문의 개념과 알파제로 구현 방식 정도를 간단하게 정리한 글입니다.
AlphaGo
- 정책 네트워크 - DNN. 처음에는 human expert의 수를 정확하게 예측하기 위해 supervised learning, 이후 MCTS로 policy gradient 이용해 개선됨
- 가치 네트워크 - DNN. 정책 네트워크가 자신과 대결하는 게임의 승자를 예측하도록 훈련됨
- 학습이 완료된 네트워크들 + MCTS ⇒ lookahead search → 정책 네트워크 : search 범위를 높은 확률의 moves로 좁힘
가치 네트워크 with 몬테 카를로 롤아웃 : MCTS가 탐색 중인 게임 트리 내의 상태를 가치 네트워크를 통해 평가하고, 이 평가를 바탕으로 해당 위치가 얼마나 유리한지를 판단함
💡 Lookahead search
특정 상태에서 미래의 여러 수를 미리 탐색하여 결과를 예측하는 검색 방법
e.g.) Mini-max algorithm, Alpha-beta pruning, MCTS
AlphaGo Zero
- Self-play RL, starting from random play
- 바둑판 위의 흑,백 바둑돌이 유일한 input
- 단일 신경망 사용
- 더 단순한 tree search (몬테 카를로 롤아웃 수행 X)
⇒ Lookahead search를 training loop 내부에 도입
→ Rapid improvement & precise and stable learning
Reinforcement learning in AlphaGo Zero
Deep neural network with parameters
- Input : The raw board representation of the position and its history
- Output :
: move 확률 벡터
- 각 move (pass 포함)를 선택할 확률을 나타냄
: scalar evaluation
- 현재 플레이어가 위치 에서 승리할 확률을 추정함
: 정책 네트워크 + 가치 네트워크
- 많은 residual blocks로 구성됨 (conv layers with BN, ReLU)
- 각 move (pass 포함)를 선택할 확률을 나타냄
AlphaGo Zero의 신경망은 독특한 강화학습 알고리즘을 통해 self-play 게임으로부터 학습됨
- 각 상태 에서 (신경망 에 의해 안내되는) MCTS 실행
- MCTS는 각 수를 둘 확률 를 출력 이러한 탐색 확률은 보통 신경망 의 raw move probabilities 보다 훨씬 강력한 수를 선택하게 하므로, MCTS는 강력한 policy improvement operator로 볼 수 있음 (MCTS는 트리 구조를 통해 가능한 모든 수를 시뮬레이션하여 탐색하는 알고리즘. 즉, 단순히 하나의 수를 평가하는 것이 아니라, 미래의 여러 수를 고려하며 그 결과를 바탕으로 최적의 선택하므로)
- 개선된 MCTS를 이용한 탐색 기반의 정책을 사용하여 셀프 플레이를 진행하고, 게임의 승자 를 가치의 샘플로 사용하면 이를 강력한 policy evaluation operator로 볼 수 있음
⇒ MCTS를 실행해 얻은 (를 신경망 의 학습 목표(정답)로 활용
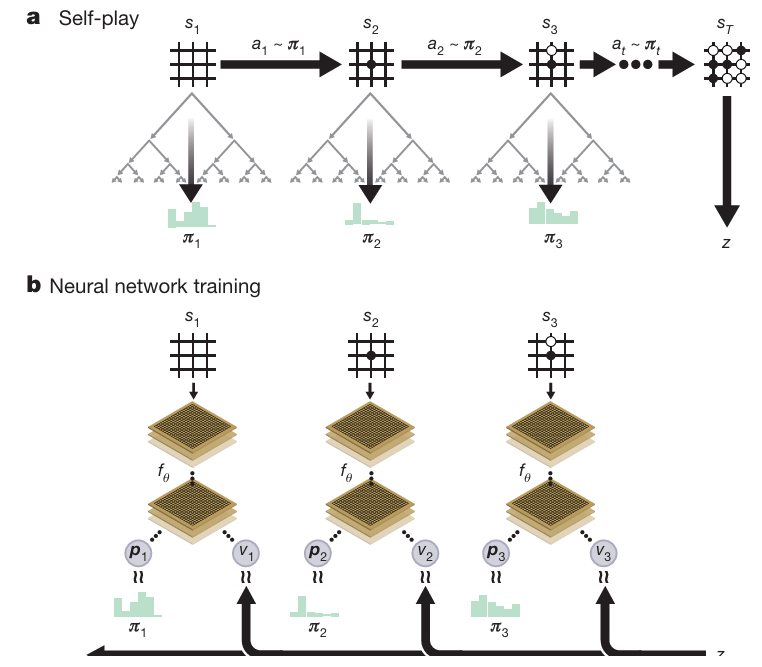
- Self-play
- 의 self-play 게임 진행
- 매 상태 마다 MCTS가 실행되어 정책 를 통해 행동 선택
- The terminal position 는 게임 규칙에 따라 scoring되어 승자 가 결정됨
- Neural network training
- Input : The raw board position
- CNN 통과
- Output : (move의 확률 분포 벡터, 에서 현재 플레이어의 승리 확률 스칼라 값)
- 는 정책 벡터 와 탐색 확률 사이의 similarity를 maximize, 예측된 승리 확률 와 실제 게임 승자 사이의 error를 minimize하는 방향으로 업데이트!
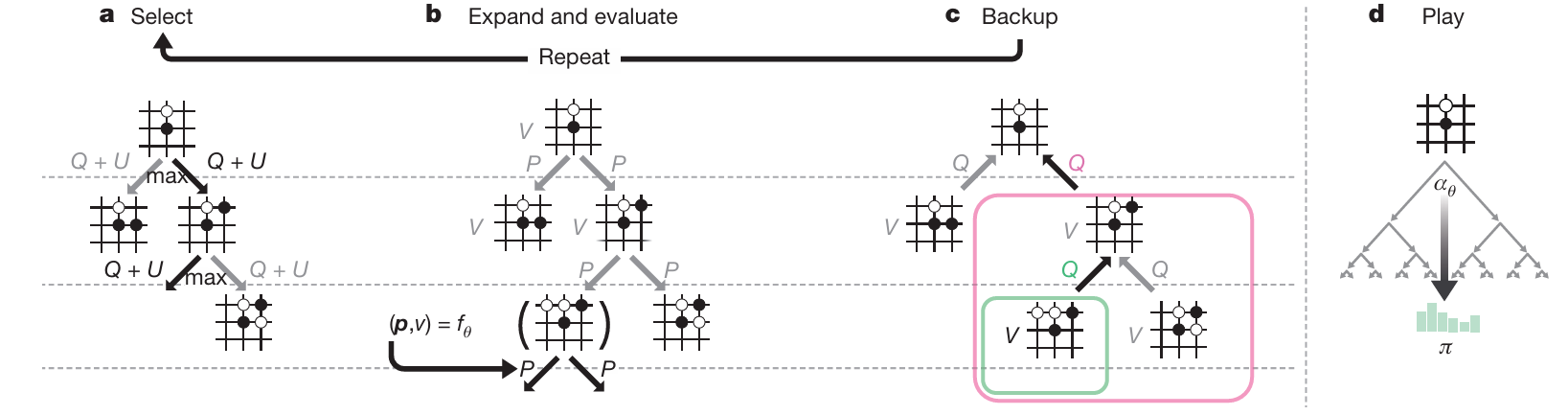
MCTS의 시뮬레이션 방법
- 를 이용해 시뮬레이션을 guide함 (MCTS는 임의로 수를 탐색하는 대신, 신경망의 출력을 참고하여 더 가능성 높은 수에 집중적으로 방문)
- 탐색 트리의 엣지마다 사전 확률 , 방문 횟수 , 행동 가치 를 저장
- 각 시뮬레이션은 root state에서부터 시작 → 상위 신뢰 구간(upper confidence bound)을 최대화하는 수(move)를 반복적으로 선택 → 리프 노드 에 다다를 때까지
Upper confidence bound
: , where
- Leaf position은 신경망에 의해 한 번만 확장되고 평가되어, 사전 확률과 평가값을 생성
- 시뮬레이션에서 지나온 각 엣지 는 방문 횟수 를 증가시키고, 이 시뮬레이션들에 대한 평균 평가값을 기반으로 행동 가치를 업데이트
MCTS는 신경망 파라미터 와 root position 가 주어졌을 때, 두어야 할 수를 추천하는 탐색 확률 벡터 를 계산하는 self-play 알고리즘으로 볼 수 있음
여기서 각 수에 대한 탐색 확률 는 각 수의 방문 횟수에 비례한 지수 함수로 정의됨
, where is a temperature parameter.
💡 : 탐색 확률의 분포를 조절하는 하이퍼파라미터
- 가 작을수록 - 가 큰 수에 높은 확률이 집중됨 → 판단된 수에만 거의 모든 확률이 쏠리게 됨
- 가 클수록 - 확률 분포가 고르게 퍼지면서 다양한 수에 비슷한 확률이 부여됨
신경망 학습
: 신경망은 MCTS를 이용하여 각 수를 두는 self-play 강화학습 알고리즘에 의해 학습됨
-
먼저 신경망 무작위 가중치 로 초기화
-
이후 반복 i ≥ 1 마다 self-play 게임 생성
-
각 타임스텝 에서, 이전 반복에서의 신경망 을 사용하여 MCTS 탐색 가 실행되며, 탐색 확률 에 따라 수를 선택
-
게임은 양 플레이어가 모두 패스하거나(더 이상 득점할 수 있는 유효한 수가 없을 때), 탐색 값이 resignation threshold 아래로 떨어지거나, 게임이 최대 길이를 초과할 때 종료
-
이후 게임 scoring → 최종 보상 주어짐
-
각 타임스텝 에 대한 데이터 : 로 저장되며, 여기서 는 현재 플레이어의 관점에서 본 게임의 승자
-
동시에, 새로운 신경망 파라미터 는 self-play의 마지막 반복에서 모든 타임스텝의 데이터 를 균등하게 샘플링하여 학습
-
신경망 는 예측 값 와 승자 사이의 오차를 최소화하고, 예측 확률 와 탐색 확률 의 similarity을 최대화하는 방향으로 학습
- 파라미터 는 MSE와 cross-entropy 손실을 합한 loss function 에 대한 경사 하강법을 통해 조정됨:
( : L2 regularization을 조절하기 위한 파라미터)
- 파라미터 는 MSE와 cross-entropy 손실을 합한 loss function 에 대한 경사 하강법을 통해 조정됨:
