Playing Atari with Deep Reinforcement Learning 논문의 내용을 한국어로 요약 정리한 글입니다.
0. Abstract
-
강화학습을 사용하여 vision, speech와 같은 high-dimensional sensory input으로부터 control policy를 직접 학습하는 데에 성공한 딥러닝 모델 소개
-
Q-learning의 변형으로 학습된 CNN
- Input : Raw pixels
- Output : A value function estimating future rewards
-
7개의 Atari 2600 게임에 DQN 적용 → 6개의 게임에서 이전의 모든 접근 방식보다 성능이 뛰어났고 3개의 게임에서는 human expert를 능가
1. Introduction
강화학습과 딥러닝
-
High-dimensional sensory inputs으로부터 에이전트를 직접 제어하는 방법을 학습하는 것은 RL의 오랜 과제였음
-
기존의 RL 어플리케이션들 : 선형적인 가치함수/정책 표현과 hand-crafted features에 의존 → feature representation의 quality에 따라 좌우됨
-
최근 딥러닝의 발전 → raw sensory data로부터 high-level features 추출 가능해짐 ⇒ 비슷한 기술이 sensory data를 갖는 RL에도 도움이 될까?
강화학습에 딥러닝을 적용할 때 생각해 볼 문제점
-
성공적인 딥러닝 적용 사례들에는 대부분 대량의 수작업 라벨링된 데이터가 필요했음 BUT 강화학습 알고리즘은 희박하고 노이즈가 많으며 지연되는 경우가 많은 스칼라 리워드로부터 학습해야 함.
-
보상은 행동 이후 수천 타임스텝만에 받게 될 수도 있고, 그럼 이것을 지도 학습의 input과 target처럼 직접적으로 연관짓기 어려움
-
대부분의 딥러닝 알고리즘은 데이터 샘플들이 독립적이라고 가정함 BUT 강화학습에서는 일반적으로 상관관계가 높은 상태들의 시퀀스를 다루는 문제가 많음
-
강화학습에서는 새로운 행동을 학습함에 따라 데이터 분포가 변화함 → 고정된 기본 분포를 가정하는 딥러닝 방법에서는 문제가 될 수 있음
그럼 이러한 문제점들을 어떻게 극복할 것인가?
본 논문에서는 복잡한 RL 환경의 데이터로부터 어떻게 성공적으로 학습할 것인가를 보일 것임
→ 가중치를 업데이트하기 위해 SGD(stochastic gradient descent)를 사용하는 큐러닝 알고리즘의 변형을 이용, 상호연관된 데이터와 비고정 분포의 문제를 완화하기 위해 experience replay mechanism 이용 (이전의 transition들을 무작위로 샘플링 → 과거의 여러 행동에 대한 training distribution을 smoothing)
2. Background
-
에이전트가 일련의 행동, 관찰, 보상을 통해 환경 (Atari emulator)와 상호작용
-
매 타임스텝마다 가능한 행동 중에서 행동 선택 → 행동이 emulator(환경)에 전달되고 internal state와 game score 수정 (확률적인 환경)
-
Model-free : 에이전트는 환경의 내부 상태 관측 불가
환경으로부터 얻은 샘플을 이용해 학습.
-
Off-policy, 입실론 탐욕 정책 선택
-
에이전트는 (게임 스코어의 변화)를 받음
-
일반적으로 게임 스코어는 과거의 행동, 관찰 시퀀스 전체를 반영. 행동에 대한 피드백은 수천 타임스텝이 경과한 후 받을 수 있음
-
에이전트는 현재 화면 상의 이미지만 관찰. 이것만으로는 환경의 현재 상황을 완전히 이해하는 것이 불가능함
→ 시퀀스를 고려해서 학습 (유한한 타임스텝)
💡 시퀀스 Sequence
Atari는 비디오 게임이므로 단일 이미지만 가지고는 환경을 이해할 수 없음
이 논문에서는 한 상태(시퀀스)마다 4개의 연속된 프레임을 쌓아서 에이전트가 움직임이나 동작의 연속성을 잘 이해할 수 있도록 함
- 각 시퀀스가 distinct state인 유한한 Markov decision process (MDP)
💡 Markov property
"미래는 오로지 현재에 의해 결정된다.”
Markovian state
: 현재 상태만으로 미래 상태를 예측할 수 있는 상태
e.g.) 체스 게임
- 한 수 이전 혹은 그 전의 상황의 영향 X
- 어느 시점 t의 사진 한 장으로 체스의 다음 수 결정 가능
Non-Markovian state
: 과거 상태가 필요하여 현재 상태만으로는 미래 상태를 예측할 수 없는 상태
e.g.) 운전하고 있는 운전자의 상태
- 어느 시점 t의 사진 한 장으로 의사 결정 불가능
- 앞으로 가고 있는지, 뒤로 가는지 확인 불가
- 10초 동안의 사진 10장을 묶어서 상태로 제공하면 좀 더 마르코프한 상태에 가까움
- 진행 방향, 속도, 가속도 등의 정보를 함께 제공하여 마르코프한 상태 만족
-
에이전트의 목표 : 미래의 보상을 최대화하는 행동을 선택함으로써 환경과 상호작용
-
Standard assumption - 미래의 보상은 타임스텝마다 만큼 할인됨
→ 시간 에서의 반환값 : (Markov property에 따라)
-
( : 행동(또는 행동의 분포)에 시퀀스를 맵핑하는 정책)
: 어떤 전략을 따르고 어떤 시퀀스 를 본 후 어떤 행동 를 취함으로써 얻을 수 있는 최대 기대 반환값
-
최적 큐함수 - 벨만 방정식; 다음 타임스텝의 시퀀스 의 최적값 이 가능한 모든 행동 에 대해 알려진 경우에, 최적의 전략은 의 기댓값을 최대화하는 행동 을 선택하는 것
-
(큐함수에 대한 벨만 최적 방정식) -
큐함수 근사
-
Q-network : a neural network function approximator with weights
→ minimizing a sequence of loss functions that changes at each iteration .
- The target for iteration :
- The behavior distribution, 시퀀스 와 행동 에 대한 확률 분포 :
- 손실 함수를 최적화할 때 이전 반복의 파라미터 은 고정됨
- The targets depend on the network weights; this is in contrast with the targets used for supervised learning, which are fixed before learning begins.
-
(DQN에서의 loss function : 현재 Q-value와 목표 Q-value의 차이를 줄이는 것이 목표. 목표 Q-value를 근사하기 위해 사용되는 파라미터(가중치)는 계속 업데이트되며 변화. 이에 따라 타깃이 고정되어 있지 않음)
-
(+ Human-level control through deep reinforcement learning (2015)에 타깃 네트워크 내용 추가됨)
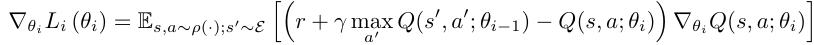
neural network 학습을 통해 최적의 를 찾게 되는데, 이 과정을 위와 같은 수식으로 표현 (SGD를 사용)
3. Related Work
TD-Gammon
- A backgammon-playing program
💡 Backgammon
15개의 말을 주사위로 진행시켜서, 먼저 전부 자기 쪽 진지에 모으는 쪽이 이기는 2인용 전략 보드게임
-
큐러닝과 비슷한 model-free 알고리즘 이용
-
하나의 hidden layer를 갖는 MLP을 이용해 가치 함수 근사
-
On-policy : self-play 게임들로부터 행동하는 대로 학습
-
여기에 적용된 방법들을 체스, 바둑, 체커에도 적용해보았지만 성공적이지 않았음
→ ‘아마도 주사위 던지기의 확률성이 state space를 탐색하는 데 도움이 되고 가치 함수를 특히 부드럽게 만들기 때문에 이 TD-gammon 접근 방식은 backgammon에서만 작동하는구나’라는 믿음이 널리 퍼짐.
-
큐러닝과 같은 model-free 강화학습 알고리즘을 non-linear function approximator나 off-policy learning과 함께 사용할 때 Q-network가 발산할 수 있음이 밝혀짐 → 그래서 다수의 강화학습 연구들이 좋은 수렴이 보장된 linear function approximator에 초점을 맞추게 됨
최근 연구
-
딥러닝과 강화학습의 결합
- 환경 를 추정하기 위한 DNN
- 가치함수나 정책을 추정하기 위한 제한된 볼츠만 머신
-
큐러닝의 발산 문제
- Gradient temporal-difference 방법을 통해 부분적으로 해결 → Non-linear function approximator를 사용해 고정된 정책을 평가할 때 / 큐러닝의 제한된 변형을 사용한 linear function approximation을 가지고 control policy를 학습할 때 수렴하는 것으로 입증됨 BUT 아직 nonlinear control로 확장되지는 않았음
- Gradient temporal-difference 방법을 통해 부분적으로 해결 → Non-linear function approximator를 사용해 고정된 정책을 평가할 때 / 큐러닝의 제한된 변형을 사용한 linear function approximation을 가지고 control policy를 학습할 때 수렴하는 것으로 입증됨 BUT 아직 nonlinear control로 확장되지는 않았음
NFQ
: Neural Fitted Q-learning
DQN의 접근 방식과 가장 유사한 선행 연구
- NFQ는 위의 loss functions 시퀀스를 최적화. Q-network의 파라미터를 업데이트하는 데에 RProp 알고리즘을 사용
💡 RProp
Resilient backpropagation is a popular gradient descent algorithm that only uses the signs of gradients to compute updates.
- 모든 데이터셋을 한번에 학습하는 batch update를 이용하기 때문에 연산량이 매우 큼
(↔️ DQN에서는 대량의 데이터에 대해서도 cost를 낮출 수 있도록 SGD를 고려함)
- Deep autoencoder를 사용해 task의 저차원 표현을 학습한 다음 이 표현에 NFQ를 적용함
(↔️ DQN에서는 end-to-end 적용 (visual input으로부터 바로 결과 보여줌) → action-value를 판별하는 데에 직접적으로 관련된 features 학습 가능)
💡 End-to-end deep learning
입력(input)에서 출력(output)까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리한다는 의미
4. Deep Reinforcement Learning
-
매우 큰 training sets에서 deep neural network를 효율적으로 훈련 : SGD에 기반한 lightweight updates를 사용해 raw input에서 직접 학습하는 방식
-
DNN에 충분한 데이터를 공급하면 수작업으로 만든 feature보다 더 나은 표현을 학습할 수 있는 경우가 많음
⇒ 목표 : 강화학습 알고리즘을 RGB 이미지에서 직접 작동하는 DNN에 연결하고 SGD를 사용해 training data를 효율적으로 처리하는 것!
-
TD-Gammon architecture :
- 가치 함수를 추정하는 신경망의 파라미터를 업데이트
- On-policy 경험을 통해 얻은 샘플을 이용함
-
Deep Q-learning with Experience replay
-
매 타임스텝마다의 에이전트의 경험
-
Replay memory — 여러 에피소드에 걸쳐서 샘플들을 저장함
-
저장된 경험 샘플 중에 무작위로 뽑아서 큐러닝 업데이트나 minibatch 업데이트를 적용
-
Experience replay 이후 에이전트는 -탐욕 정책을 이용해 행동 선택
-
함수 이용 — 고정된 길이의 history 표현 (큐함수 input 통일하기 위해?)

- 개의 샘플을 저장 가능한 리플레이 메모리 초기화
- 랜덤한 가중치를 가지는 큐함수 초기화
- 개의 에피소드 동안:
1) 시퀀스(상태) 초기화 및 전처리
2) 한 에피소드 내의 타임스텝 1 ~ 까지 반복:
i) - 탐욕 정책에 의한 행동 선택
ii) 행동 수행 후 보상 와 다음 이미지 받음
iii) 설정 후 전처리
iv) 리플레이 메모리에 저장 (s,a,r,s’)
v) 리플레이 메모리에서 랜덤하게 미니배치 샘플 추출
vi) 한 미니배치의 정답 value →
vii) Gradient descent 이용해 (정답 - 타깃 신경망을 이용한 예측값)—Loss— 최소화
-
-
Standard online Q-learning과 비교했을 때의 장점
- Data efficiency : 리플레이 메모리의 한정된 용량에 담긴 샘플들만 가지고 가중치 업데이트 (메모리에는 오래된 경험 샘플을 버리는 대신 새로운 경험 샘플을 넣을 수 있음)
- 시간적으로 연속된 샘플을 가지고 바로 학습하는 것은 비효율적임 → 샘플 간의 강한 상관관계
⇒ 무작위로 추출한 샘플을 이용해 학습 → 업데이트의 분산 감소
- On-policy 학습 시 현재 파라미터는 파라미터가 학습될 다음 데이터 샘플을 결정 (local minima, 발산 문제 야기 가능)
⇒ Experience replay 사용 : 행동 분포가 많은 이전의 상태들로부터 평균화됨 → 수렴 안정성 강화
(Experience replay를 학습에 이용하기 위해서는 off-policy 필수적 : 학습 중인 모델의 현재 파라미터가 과거에 데이터를 생성할 때 사용한 파라미터와 다르기 때문에)
- Data efficiency : 리플레이 메모리의 한정된 용량에 담긴 샘플들만 가지고 가중치 업데이트 (메모리에는 오래된 경험 샘플을 버리는 대신 새로운 경험 샘플을 넣을 수 있음)
-
본 논문의 DQN 알고리즘
- 마지막 개의 experience tuple만 리플레이 메모리에 저장
- 업데이트 시 리플레이 메모리에서 균일하게 무작위로 샘플링
- 균일한(uniform) 샘플링 : 리플레이 메모리의 모든 transition(샘플)에 동일한 중요성을 부여함
- (더 정교한 샘플링을 위해서는 prioritized sweeping과 유사한 전략 사용 가능)
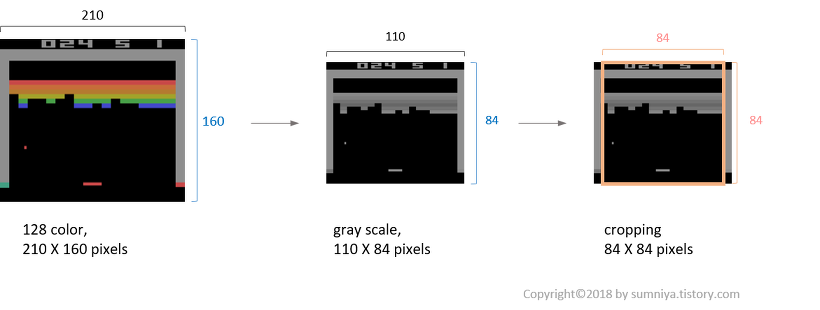
Preprocessing
Input 이미지의 차원 축소를 위한 전처리
큐함수의 input으로 넣기 위한
- RGB → grayscale (3채널 → 1채널)
- 210X160 pixel → 110X84 pixel (downsampling)
- cropping 84X84 region
Model Architecture
가 history-action 쌍을 추정한 Q-value 스칼라 값에 맵핑 → 이전의 일부 접근 방식에서는 history와 action을 신경망의 input으로 사용했음 BUT 이러한 구조의 단점 : action이 input으로 들어가기 때문에 각 action에 대한 Q-value를 계산하기 위한 별도의 forward pass (연산 과정)이 필요함 — 액션의 수에 비례해 cost 증가
⇒ DQN : 각 action에 대해 별도의 output unit 존재, state에 대한 표현만 신경망의 input으로 하는 구조 사용. Output = input state에 대한 개별 action들의 예측된 Q-value
(장점) 한 번의 forward pass만으로 주어진 state에 대해 가능한 모든 action에 대한 Q-value 계산 가능
The exact architecture for all seven Atari games
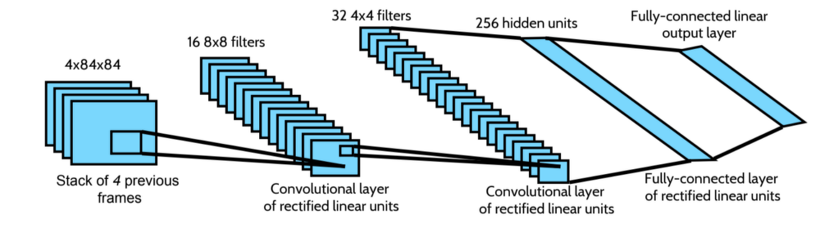
- Input : 84x84x4 image
- 1st hidden layer : 8x8 filter 16개 (stride=4, activation function=ReLU)
- 2nd hidden layer : 4x4 filter 32개 (stride=2, activation function=ReLU)
- 3rd hidden layer : fully-connected layer with ReLU
- Output : fully-connected linear layer (모든 가능한 action들에 대한 single output)
: Deep Q-Networks (DQN)
5. Experiments
-Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders-
-
7개의 게임 전부 동일한 network architecture, learning algorithm, hyperparameters settings 사용 → 게임별 정보를 통합하지 않고도 다양한 게임에서 robust하게 작동함을 보임
-
게임마다 스코어의 스케일 다른 것 보상 구조 고정
→ positive reward : +1 / negative reward : -1 / unchanged : 0⇒ Reward clipping의 효과 : error 도함수의 scale를 제한함으로써 다양한 게임에서 동일한 learning rate 더 쉽게 사용할 수 있게 해줌
-
Minibatch : batch size 32
-
Optimizer : RMSProp
-
행동 선택 : -탐욕 정책 (첫 백만 프레임 동안 = 1 ~ 0.1로 decay / 이후 = 0.1 고정)
-
총 천만 프레임에 대해 훈련, 최근 백만 개 프레임을 저장하는 리플레이 메모리 사용 (시퀀스 하나 당 연속된 4프레임으로 구성됨 → 리플레이 메모리에 저장되는 샘플은 25만 개?)
-
Frame-skipping technique
: 에이전트가 매 프레임을 보고 행동을 선택함
여기서는
(한 시퀀스를 구성하는 세 프레임 동안 가장 최근의 행동(이전 시퀀스의 마지막 행동)을 수행하다가 마지막 4번째 프레임에서 새로운 행동을 선택)
⇒ 이렇게 하면 매 프레임마다 행동을 선택하는 것보다 훨씬 계산량 감소함 → 동일한 런타임에 대략 배 많은 게임 플레이 가능
(⁕ Space Invaders라는 게임에서는 4의 배수 프레임에서는 레이저 깜박이는 타이밍이라 레이저가 보이지 않았으므로 이 게임에서만 을 사용함)
Training and Stability
강화학습에서는 훈련 도중에 에이전트의 진행 상황을 evaulation하는 것이 어려울 수 있음
→ 평가 지표(evaluation metric) :
-
에이전트가 여러 게임에서 평균적으로 수집한 총 보상을 훈련 중에 주기적으로 계산
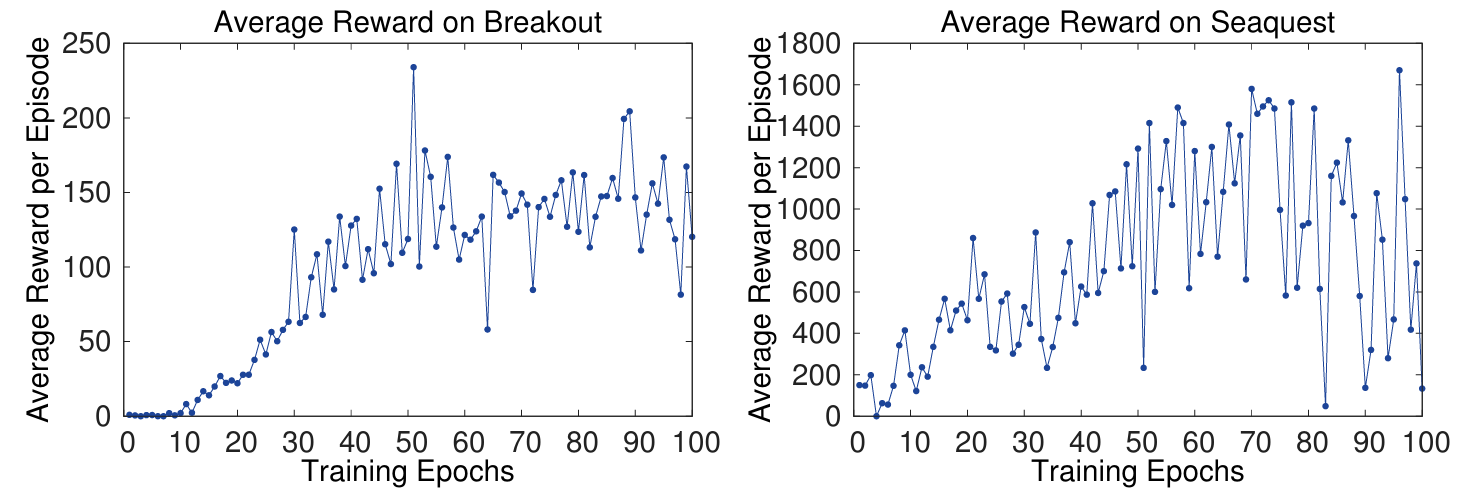
= 0.05, time step = 10000
⬆️ 평균 보상 지표에 노이즈 많은 이유 : 정책의 가중치가 조금만 바뀌어도 정책이 방문하는 상태의 분포에 큰 변화가 생길 수 있기 때문에
-
정책의 예상 큐함수(Q) : 에이전트가 주어진 상태에서 정책을 따를 때 얻을 수 있는 할인된 보상의 추정치 제공
(훈련 시작 전에 랜덤 정책 실행 → 고정된 상태 집합 수집 → 이 상태에 대해 최대로 예측된 큐함수의 평균 추적)
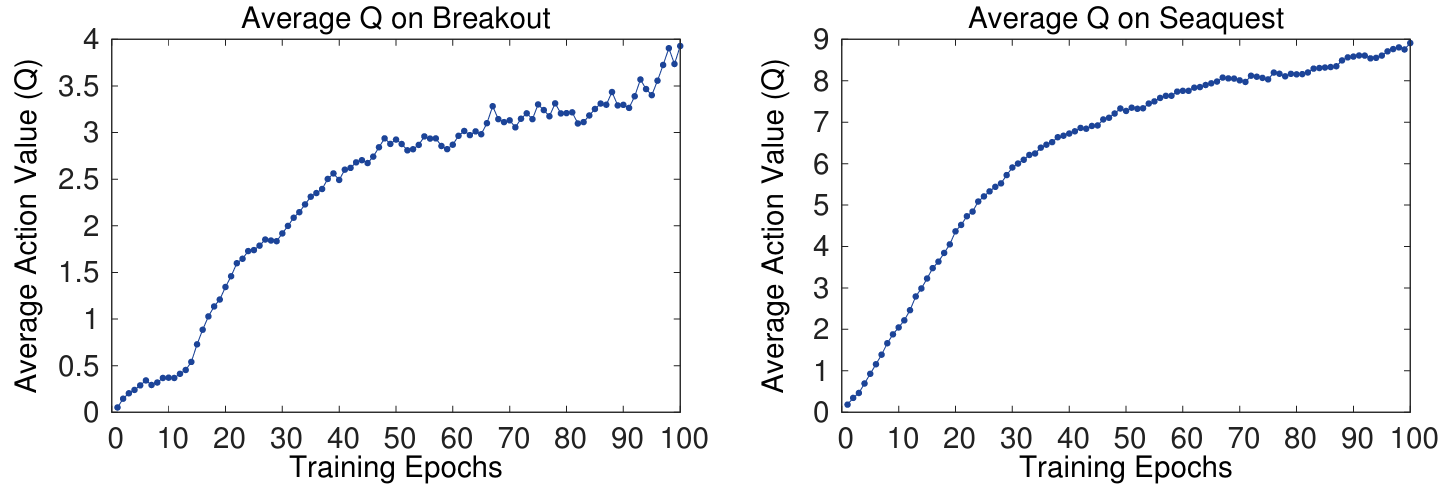
⬆️ 1 epoch = 50000 minibatch weight updates (roughly 30 minutes of training time)
Visualizing the Value Function

⬆️ Seaquest 게임의 value function 시각화 그래프 (스크린샷 좌 : A, 중앙 : B, 우 : C)
- (적을 처치하면 보상 증가)
- A : 적(연두색)이 화면 상 왼쪽에서 나타난 이후 예측 value 상승
- B : 에이전트(노란색)가 적을 향해 어뢰(회색 직사각형) 발사 후 적중하려고 할 때 예측 value 최고점
- C : 적이 사라지면 다시 original value로 감소
Main Evaluation
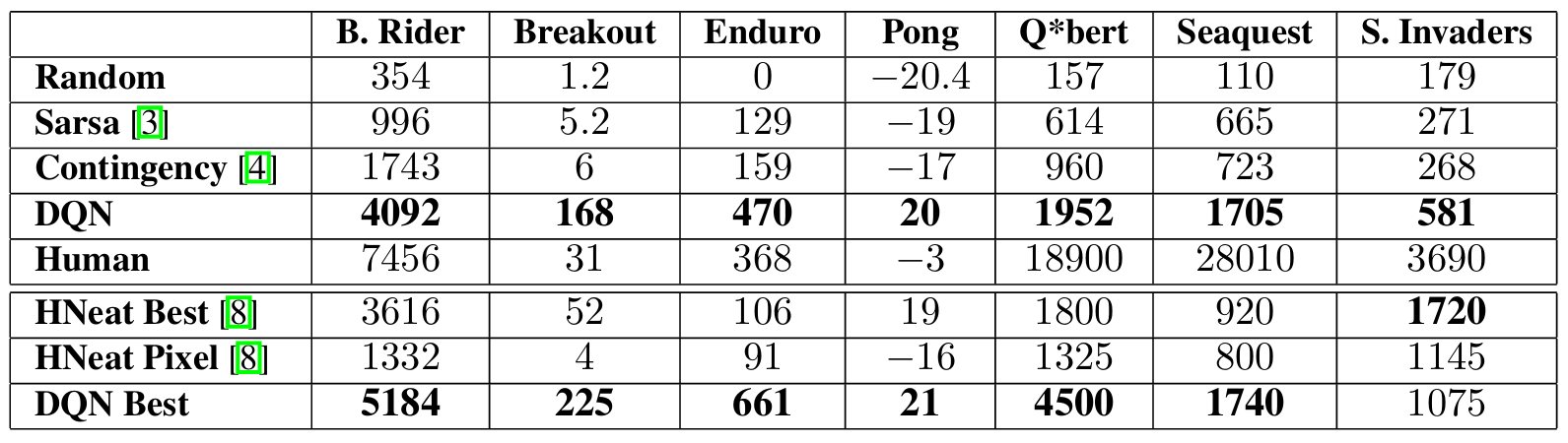
⬆️ 다양한 강화학습 방법들 및 사람이 직접 플레이했을 때 성능 비교
- Sarsa, Contingency
- 시각적 문제에 대한 사전 지식이 포함된 알고리즘
- 색상을 독립적인 채널로 분리하여 학습
- DQN
- Raw RGB screenshots만 입력 받아 스스로 객체를 감지
- Human
- 인간 플레이어
- 게임 당 약 2시간 플레이한 보상의 중간값
- Evolutionary policy search approach와의 비교 (HNeat)
- 8 color channel을 활용해 객체의 레이블을 학습 → 결정론적 상태의 시퀀스를 찾는 데 중점을 두고 일반화하기 어려움
- DQN을 이용했을 때 - 탐욕 제어 시퀀스에 대해 평가되므로 가능한 다양한 상황들에 대해 더 잘 일반화
6. Conclusion
DQN : 강화학습을 위한 새로운 딥러닝 모델
- Input으로 raw pixels만을 사용하여 Atari 2600 게임에 대한 좋은 성능을 보임
- Online Q-learning의 변형 with SGD + experience replay memory
[참고 문헌]
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (n.d.). Playing Atari with Deep Reinforcement Learning. https://arxiv.org/pdf/1312.5602
https://velog.io/@kimjunsu97/바닥부터-배우는-강화학습-마르코프-결정-프로세스Markov-Decision-Process
https://languages.oup.com/google-dictionary-ko/
