
학습목표
- 주식, 언어와 같은
Sequential data와 이를 이용한Sequential model의정의와종류- 딥러닝에서 sequential data를 다루는
Recurrent Neural Networks에 대한정의와종류
1. Sequntial Model (순차 모형)
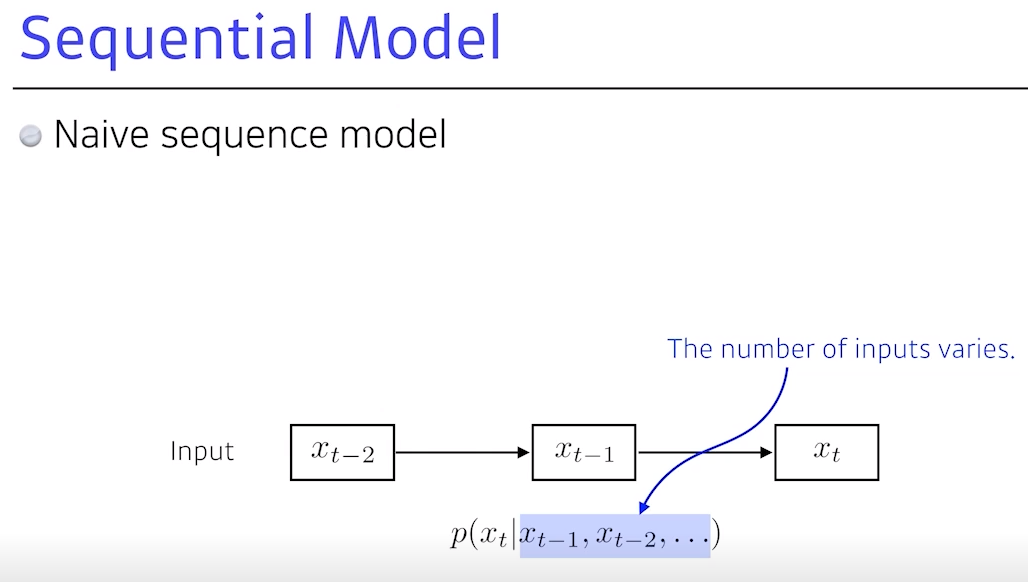
- RNN은 주어지는 입력 자체가 Seqential 입력
Seqential Data: 일상생활에서 접하는 대부분의 데이터 (음성, 비디오, 손동작 등)
💡 Seqential 모델과 데이터를 다루는데 어려움은?
- 얻고싶은 것은 어떤 하나의
라벨일 때가 많음 (혹은 정보)
- 가장 간단한 분류라고 볼 때 원하는 것은 내가 하는 말이무엇이다인데,
Seqential Data는길이가 언제 끝날지 모름
- 그래서, 기본적으로 받아드려야하는입력의 차원을 알 수가 없음
- 그렇기 때문에 앞에서 배운 것들을 사용할 수 없음- 즉, 몇 개의
입력이 들어오든상관없이이 모델은동작할 수 있어야 함
Seqential 모델: 입력이 여러 개 들어왔을 때 다음 입력에 대한예측하는 것
- 랭귀지 모델이 있다면, 이전 말이 나올 때 다음 단어가 뭐가 나올지 예측하는 것으로, 예를 들면 10개의 입력이 있는데 첫 번째 입력은 아무 것에도 컨비젼 돼 있지 않고 두 번째는 처음만 고려하고 세 번째는 1~2번째를와 같이,
고려해야하는 컨비션 이펙터의 숫자가 늘어가게 됨
The number of inputs varies: 과거에 고려해야하는 정보량이 점점 늘어난다는 것으로, 이것이 어려운 문제
2. Autoregressive Model
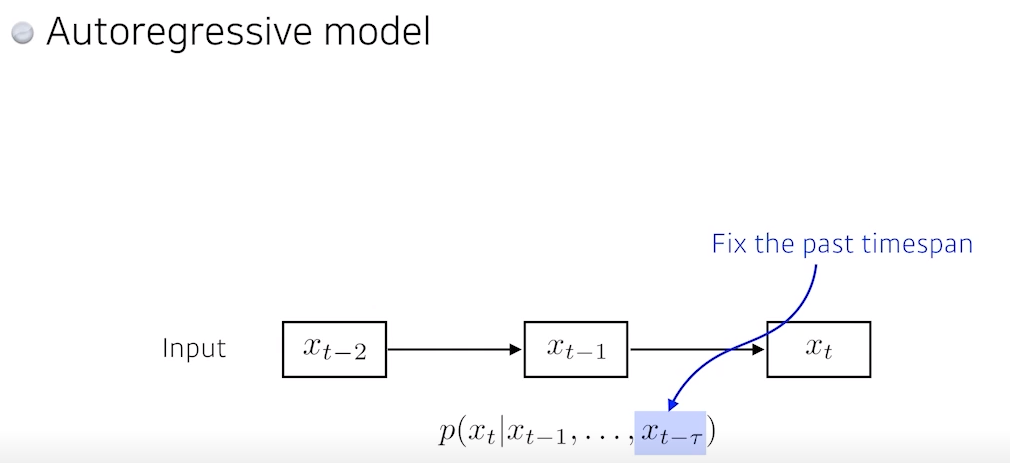
- 제일 쉽게 할 수 있는 것은
과거의 몇 개만보는 것- 과거의 5개만 본다면 항상 5개를 보기 때문에 훨씬 계산이 쉬워짐
3. Markov Model
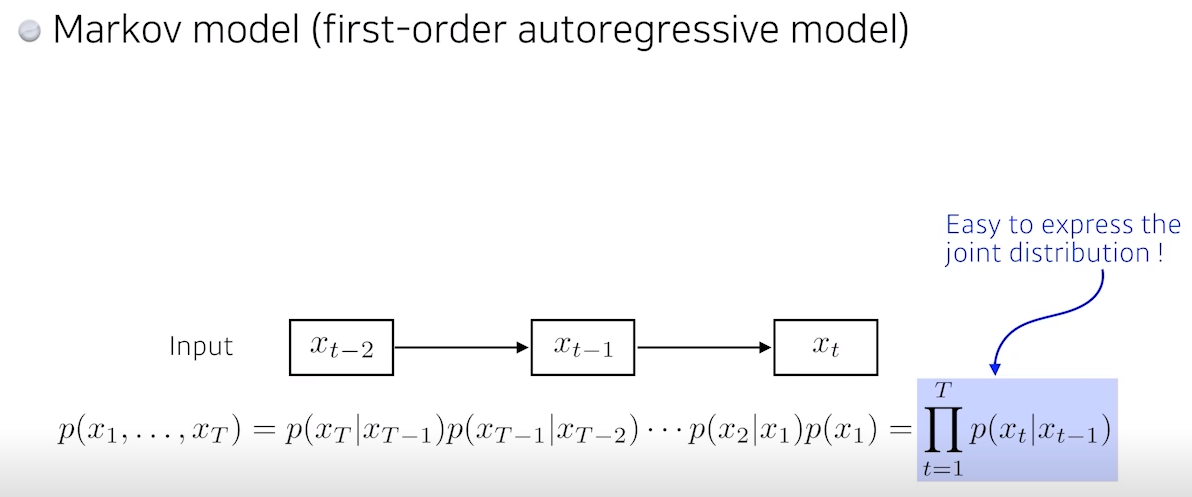
- 제일 쉬운 것 중 하나로 가장 큰 특징은 내가 가정하기에 나의 현재는 과거에만 dependent한다는 것 (
과거는 바로 전 과거)
- 하지만, 이 모델이 현실에서 말이 안 됨.
예를 들어, 내일 수능점수는 과거 몇 년간 공부했던 것이 누적 돼서 점수가 나와야 하는데, 이는 전날 공부한다는 것에 dependent한다는 것으로 설명됨- 그래서 markov model 많은 정보를 버릴 수 밖에 없음
- 반면 markov model의 가장 큰 장점은
joint distribution을 표현하기 쉬워짐
4. Latent autoregressive model
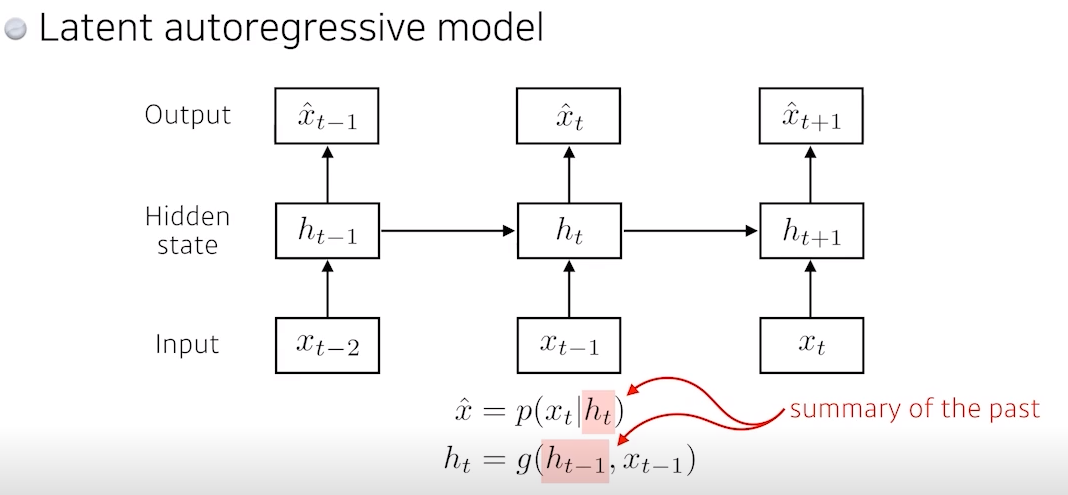
- markov의 단점은 과거에 많은 정보를 고려해야하는데, 고려 할 수 없는 것
- 그래서 이 모델은 중간에
Hidden state가 하나 있는데, 이 Hidden state가 과거의 정보를요약하고 있고, 다음 time step은 Hidden state 하나에만 dependent- 여기서 하나의 과거가 나의 과거 이전의 state가 아니라 이전의 정보를 요약한 어떤 Hidden state라고 봄
- 물론 어떻게 만드느냐에 따라 차이가 있겠지만, 중간의 Hidden state이 추가함으로써 과거 정보를 요약 (summary)
5. Recurrent Neural Network
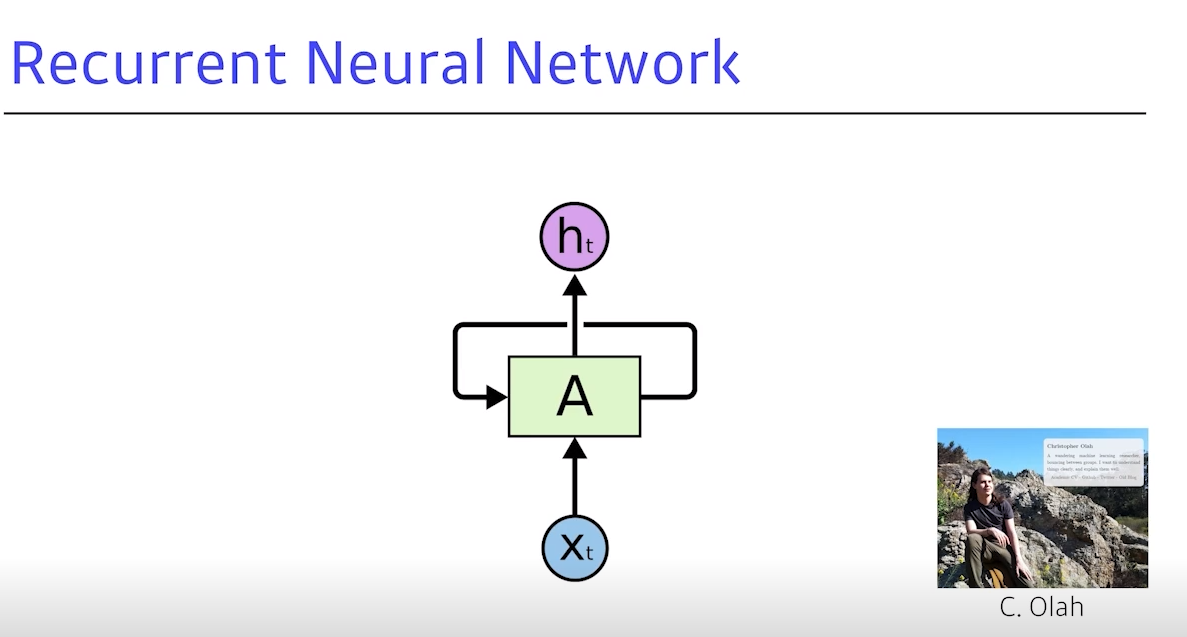
- 이 컨셉들을 가장 쉽게 설명하고 구현하는 방법
- 자기자신을 돌아오는 구조가 하나 있는데, 는 에만 dependent 하는 것이 아니라, 이전의 cell state에 dependent하는 것
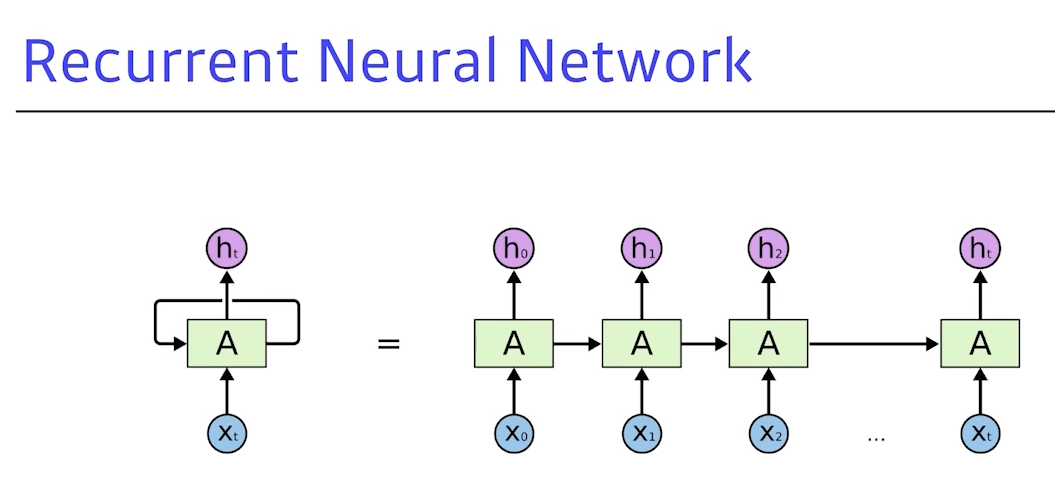
- RNN은
시간 순으로 푼다고 이야기를 함- x가 A로 들어가고 그 정보가 x1과 합쳐저 h1이 나오고 (…) 반복
- 중요한 사실은 RNN으로 불리는 구조를 시간 순으로 풀면, RNN 학습과 동일
- recurancy가 있어 그 자체로 복잡하고, 만약 timestep을 픽스 후 시간 순으로 풀게되면, 결국 각각 네트워크 파라미터를 쉐어하는 굉장히 인풋의 위치가 큰 네트워크가 됨
6. Short-term dependencies
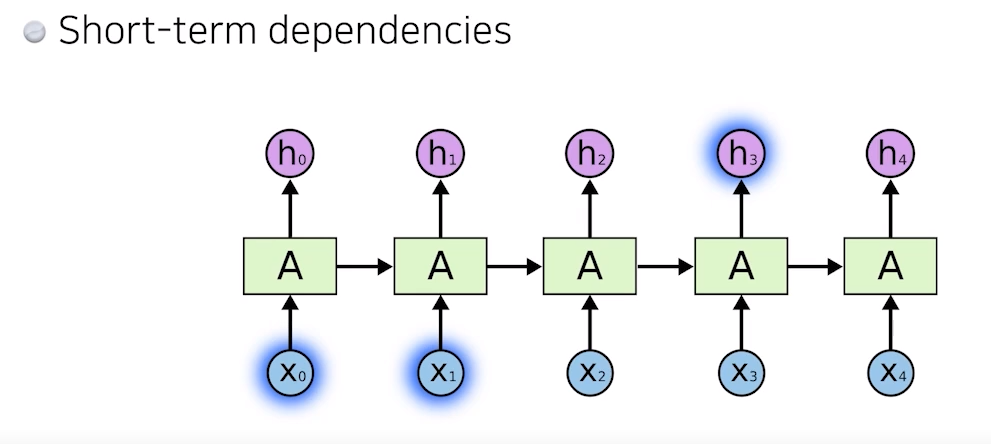
- 과거에 얻어진 정보들을 취합해서 미래에서 고려해야 하는데,
RNN 자체는 하나의 픽스로 이 정보를 계속 취합하기 때문에과거에 있던 정보가 미래까지 살아남기가 힘듦
- 그래서 몇 스텝 전 정보는 고려가 잘 되지만, 멀리있는 정보는 고려하기 힘듦
- 예를 들어, 음성인식 서비스가 있다고 보면 문장이 길어져도 이전에 중요하다고 생각한 정보를 다 가지고 있다가, 요약을 계속하고 표현할 때 써야 하는데 5초 전에 들은 말을 하나도 기억 못하는 것
7. Long-term dependencies
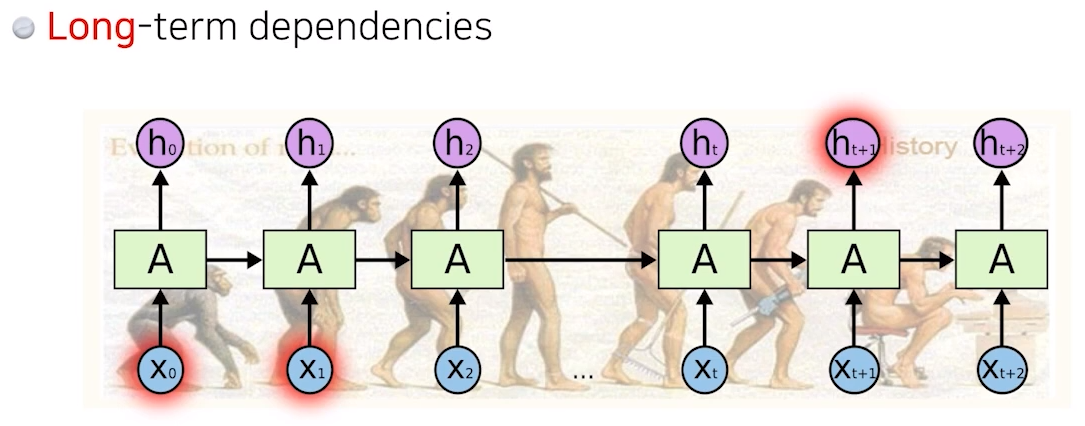
- 이것이 일반적으로 알려진 RNN의 가장 큰 단점
- 이를 해결하는 것이 어려움
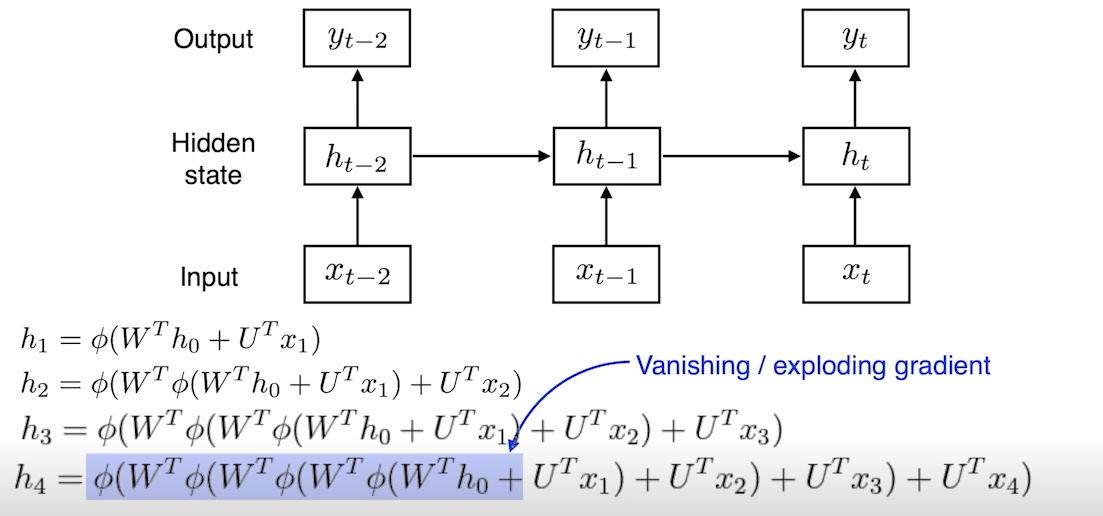
💡 RNN은 어떤 식으로 학습되며 왜 어려울까?
- 네트워크을 풀어보면 굉장히 큰 네트워크, 위치가 커진 것이 됨
- 이라고 불리우는것은 에서 나오는 값과 과 합쳐짐
- = + 동일 (….)
- 이처럼 중첩되는 구조가 들어가기 때문에 가 4까지 가기 위해, 똑같은 weight를 곱하고 통과시킴
- 어떤 정보가 네트워크 weight를 곱하고 반복하면, 그 값이 의미가 없어져 줄어듦
ReLU를 쓴다고 가정해보면, w는 양수이고 이 w를 n번 곱하면, 의 값이 4로 갈 때 엄청 크게 반영될 것
- activation function이
sigmoid일 경우vanishing돼서 학습 안 됨- activation function이
ReLU일 경우 학습할 때 네트워크가폭발해 학습 안 됨
- 따라서 RNN에서는 ReLU를 많이 쓰지 않으며, 학습이 어려운 것도 있음
- 그래서
LSTM이라는 모델이 나오게 됨!
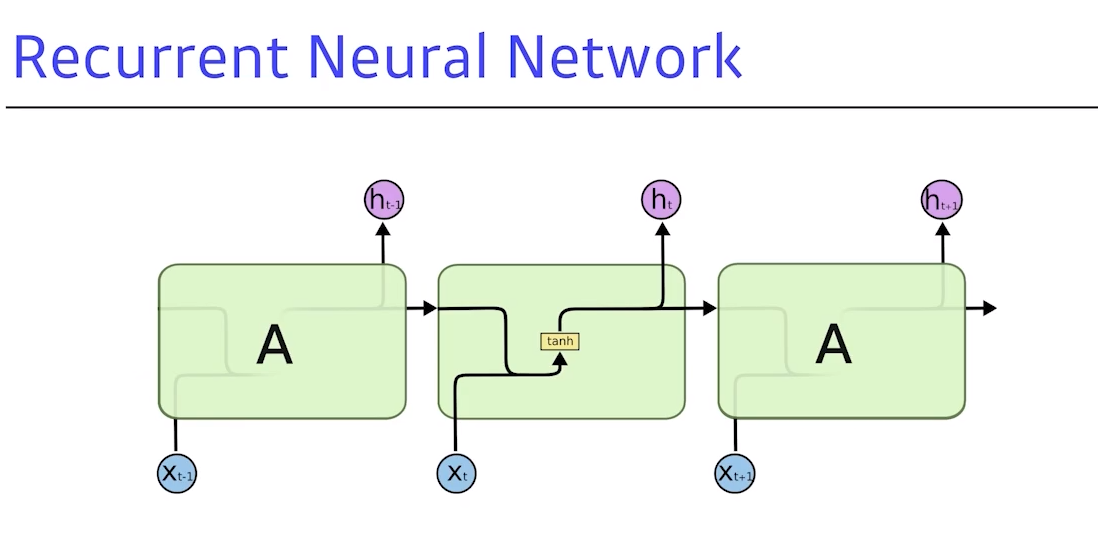
- RNN 의 기본구조 (위의 과정들)
8. LSTM Model
LSTM이 각각 컴포넌트가 어떻게 동작을 하고 어떻게 긴 dependencies를 잡는지 아는 것이 목표
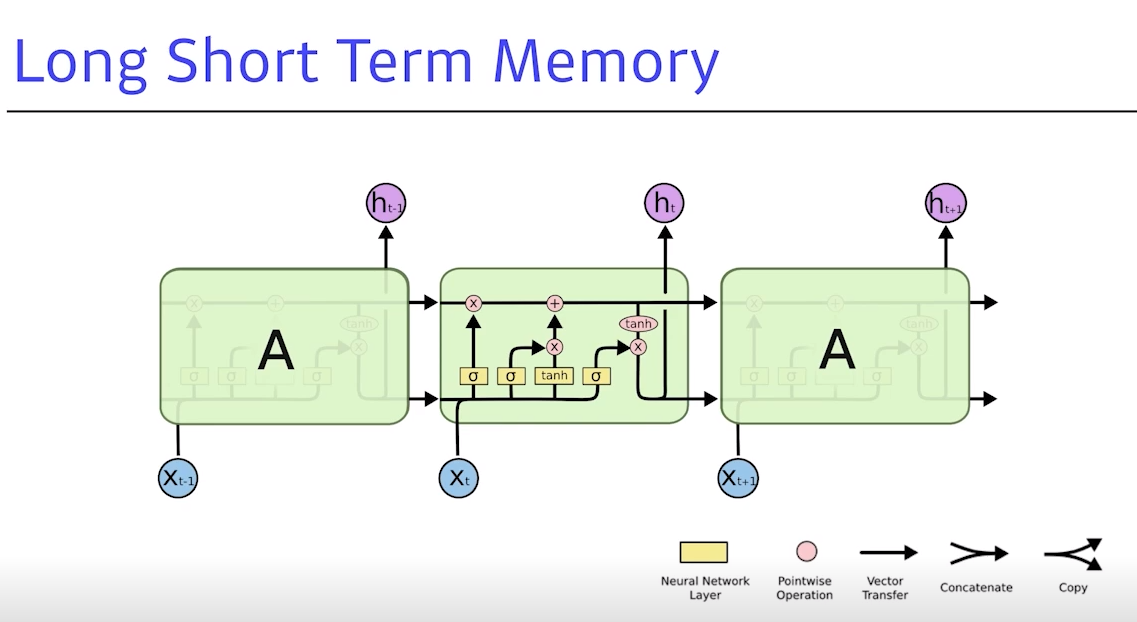
- : Input (랭귀지 모델이면 단어)
- : Output → 최종적으로 t번째 step의 아웃풋이 출력
Previous cell state: 밖으로 나가지 않고 내부에서만 흐르며,
지금까지time step t까지들어왔던 것을모두 취합한 정보
Previous hidden state: 아웃풋이 위로도 가지만 아래도 흐름
- 입력으로 들어가는 건
이전의 출력 값혹은 Previous hidden state와 밖으로 나가지 않는Previous cell state그리고 현재의time step t번째의 t가 됨- 네트워크만 보면 입력 3개와 출력 3개이지만, 실제로 나가는 것은 아웃풋
- 안에서 각각 구조를 잘 보면 로우라고 돼 있는 것이 3개 있음
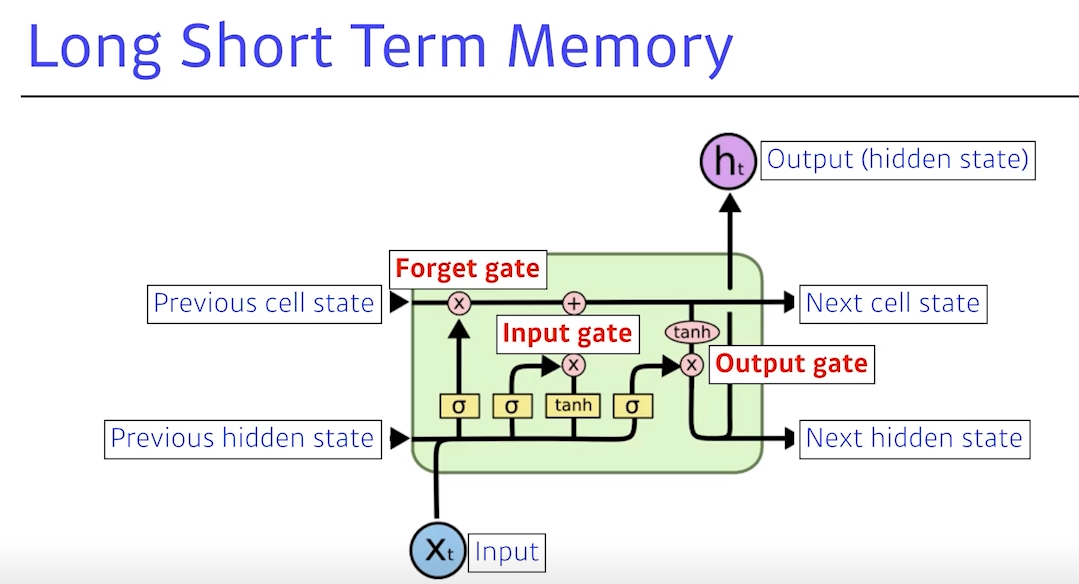
💡 LSTM은gate를 위주로 이해하면 좋음 (Forget gate, Input gate, Output gate)
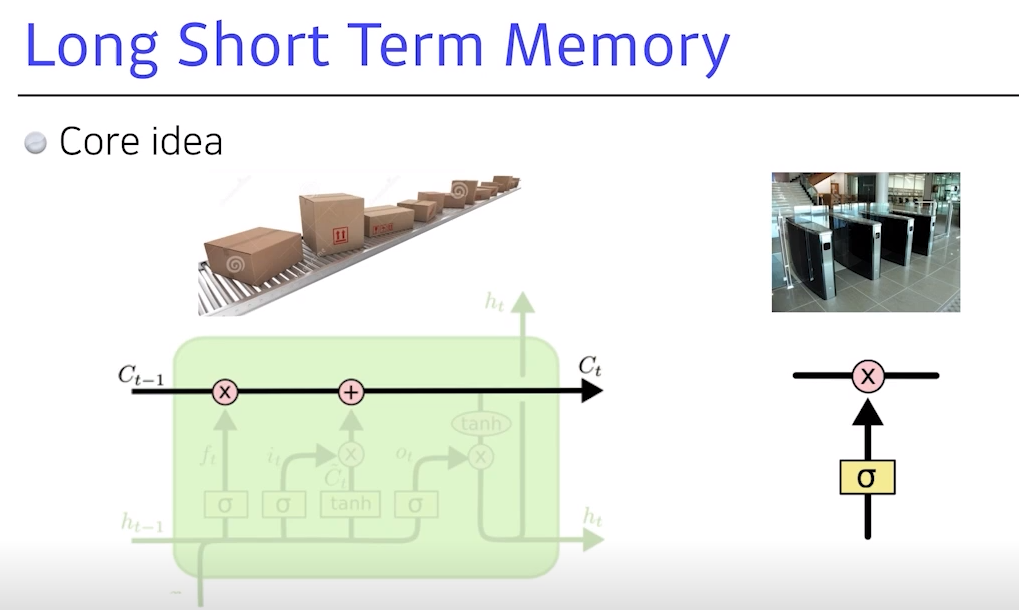
- 가장 큰 아이디어는 중간에 흐르는
cell state- time step t까지 들어오는 정보를 요약하는 것으로
컨베이너 벨트로 빗대어 보면,
- 어떤 물건이 올라올 때 조작공들이 어떤 정보가 유용하고 유용하지 않은지를 조작한 후 다음으로 넘김
- 이 역할을 컨베이너 벨트 위에서 어떻게
올리고 빼고 조작할지에 대한 정보가gate에 해당 (원 안의 기호들이 모두gate)
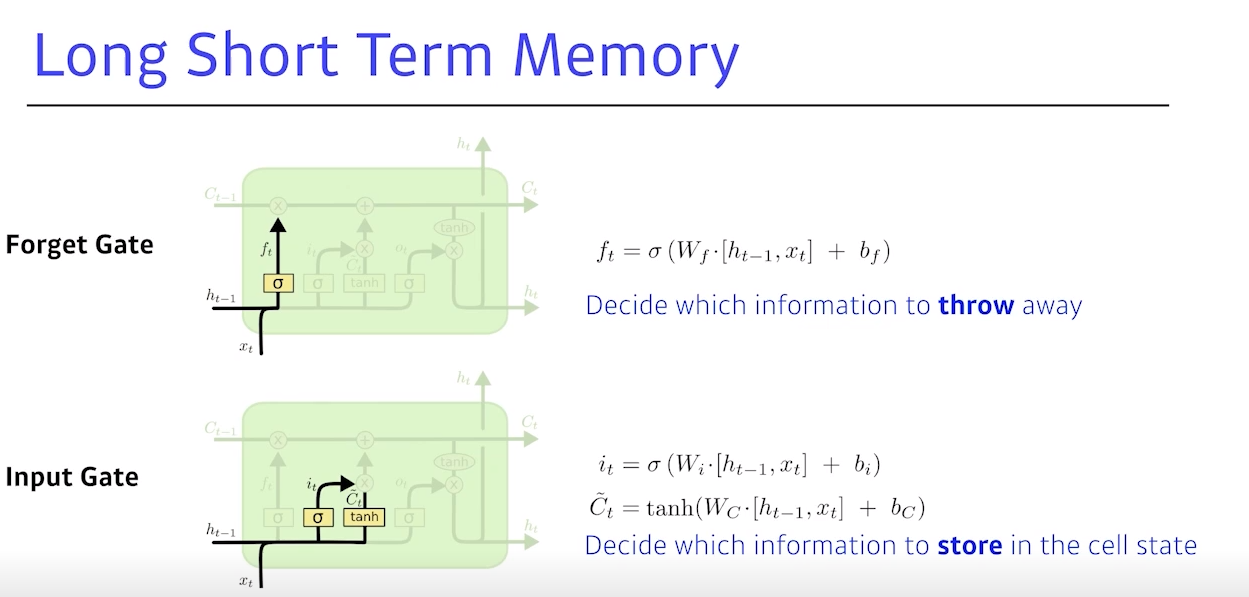
Forget gate: 어떤 정보를 버릴지 정함, 입력으로 들어가는 건 현재 입력과 이전 입력이 들어가서 라는 숫자를 얻음 (sigmoid를 통과하기 때문에 항상 0~1값을 가짐)
- 뒤에서는 를 이전 cell state에서 나온 정보 중 어떤 걸 버리고 살릴지를 정함
Input gate: 입력이 들어오면, 이를 무조건 cell state에 올리는 것이 아니라,
이 정보 중어떤 것을 올릴지 말지를 정함
- hidden state와 현재 입력을 가지고 라는 정보를 만들고, 는 어떤 정보를 올리고 말지를 정함
C 틸다: 현재 정보와 이전 출력값을 가지고 만든 cell state 예비군,
이전에 나온 cell state와 현재의 정보와 아웃풋을 잘 섞어 업데이트
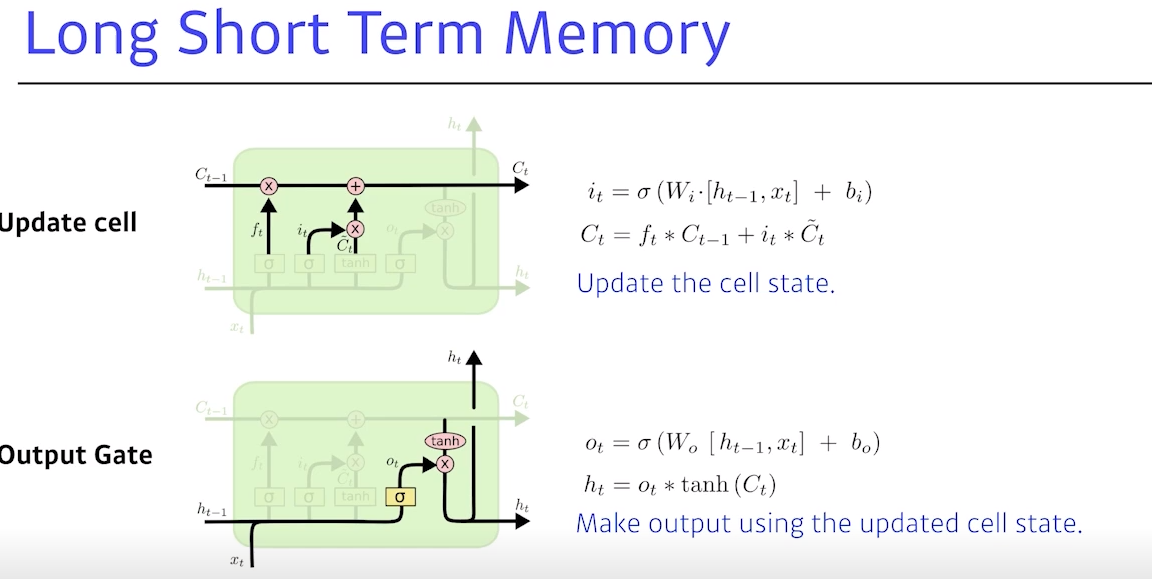
Update cell: 에 이전 C 탈다를 곱해서 버릴 건 버린 후, C 틸다에 만큼 곱해서 어느 값을 올릴지를 정한 후, 이 두 값을 합해서 새 cell state로 업데이트
(인풋과 아웃풋의 취합)
Output gate: 어떤 값을 내보낼지 해당하는 output gate를 만들고,
이를 곱해서 가 현재 아웃풋이 된 뒤, 다음으로 넘어감
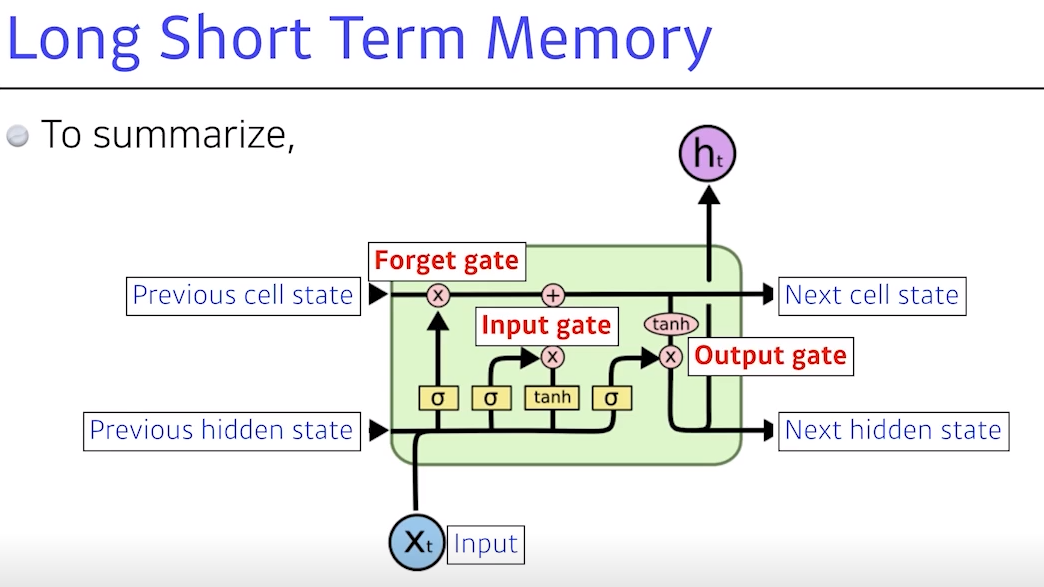
- NN 네트워크 안에서 어떤 정보와 이전 cell state를 얼마만큼 지울지 정함
- 어떤 값을 올릴지 C 틸다를 정하고, 업데이트된 cell state와 현재 올릴 데이터를 조합해 새로운 cell state를 정하고 얼마만큼 뺄지를 정해서, 최종적인 출력 값이 나옴
9. GRU
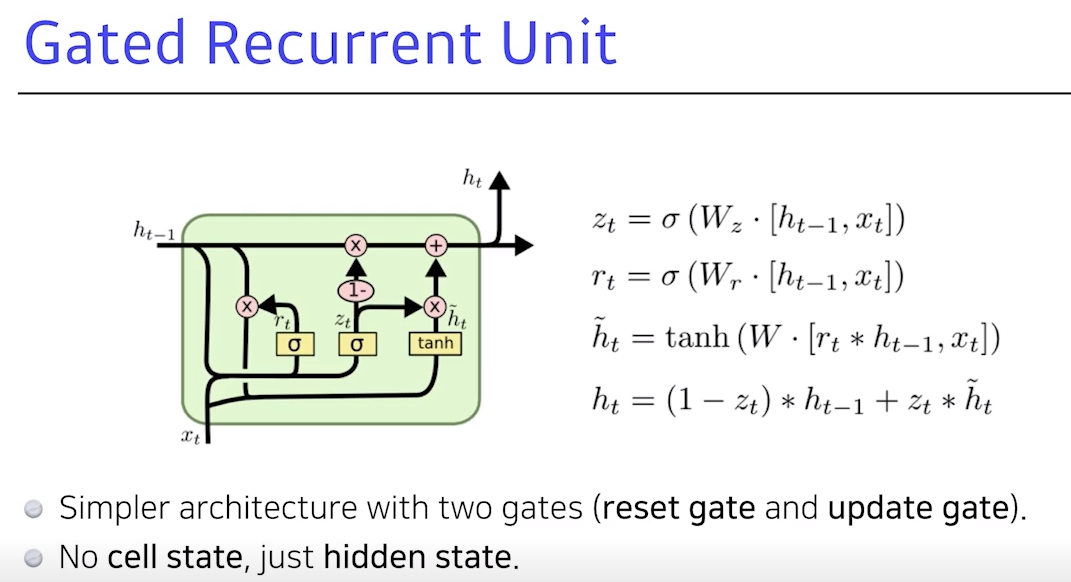
GRU: 게이트가 2개 밖에 없음 (reset gate,update gate)hidden state가 곧 output
- cell state가 없고 hidden state가 바로 있음으로써 output gate가 필요 없음
- 대신, reset gate와 update gate가 있음
- 2개의 게이트만 가지고도 LSTM과 비슷한 성능
- 똑같은 task에 대해서 GRU가 성능이 더 높기도 함 (네트워크 파라미터가 적기 때문)
- 그런 관점에서 GRU를 많이 활용하기도 함
- 사실
Transformer가 나오면서 이 둘도 많이 활용 안 됨

세상을 이롭게하는 AI Engineer