Kinesis로 데이터 정렬
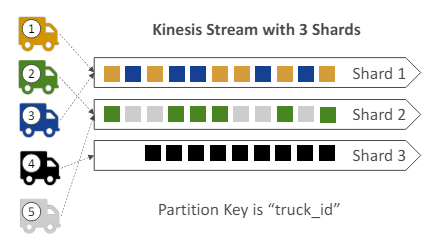
- 도로에 트럭 100대가 있고 각각 트럭 ID가 있다
그리고 GPS 위치를 주기적으로 AWS에 보낼 것이다. - 각 트럭의 순서대로 데이터를 소비해서 트럭의 이동을 정확하게 추적하고, 그 경로를 순서대로 확인하려 한다.
- 어떻게 Kinesis로 데이터를 전달할까?
- 파티션 키를 사용하면 된다.
파티션 키 값은 트런 ID이다.
-> 트럭1은 트럭1의 파티션키를 전송, 트럭2는 트럭2의 파티션키 전송....
--> 같은 파티션 키를 지정하면 해당 키가 언제나 동일한 샤드로 전달되기 때문이다.
위 그림처럼 재분할하는것을 파티션이라 하기에 파티션 키라고 부르는 것
각 트럭의 파티션 키는 거기에 따른 샤드에 속한다.
kinesis가 파티션 키를 해시해서 어느 샤드로 보낼지 결정
한번 결정된 샤드는 이후에도 같은 샤드로 보낸다.
- 파티션 키를 사용하면 된다.
SQS로 데이터 정렬
- SQS 표준 방식에는 순서가 없다.
그래서 SQS FIFO 사용 - SQS FIFO의 그룹 ID를 사용하지 않으면 모든 메시지가 소비되는 방식은 보내진 순서에 따르고 소비자는 하나만 존재한다.

(설명)
(ㄱ) 위 그림은 SQS FIFO 대기열에 전송되는 중이다.
(ㄴ) 전송되는 순서대로 소비자가 수신 받을 것이다.
소비자는 하나이기 때문에 두 배치의 메시지를 소비한다
EX) 트럭이 있다면
모든 트럭이 FIFO 대기열로 데이터를 보내더라도 소비자는 하나뿐이다. - 만약 소비자 숫자를 스케일링하고 서로 연관된 메시지를 그룹화하려는 경우 '그룹ID'를 사용할 수 있다.-> kinesis의 파티션 키와 개념이 비슷하다.
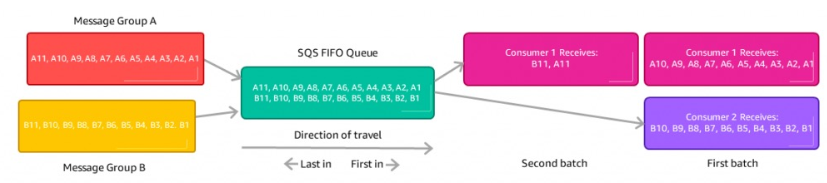
(설명)
(ㄱ) 그룹 ID를 사용하면 FIFO 대기열은 FIFO 내부에 두 개의 그룹이 생긴다.
(ㄴ) 정의한 그룹마다 각각 소비자를 가질 수 있게 된다.
-> 그룹A,B가 있고 각각 소비자1,2가 있다.
-> 소비자 1,2는 독자적으로 그룹A,B를 읽을 수 있다.
-> 그룹이 많아질수록 소비자도 많아진다.
Kinesis 데이터 정렬 vs SQS 데이터 정렬
- 트럭은 100대이고 kinesis 샤드가 5개, 1개의 SQS FIFO 대기열이라면
- Kinesis 데이터 스트림에서 평균적으로 가지는 값
샤드당 20대가 될것이다.
-> 해시 기능으로 각 트럭은 하나의 샤드에 지정되고 해당 샤드에 머물 것이다.
트럭 데이터는 각 샤드에 순서대로 정렬된다.
단, 동시에 가질수 있는 최대 소비자 개수는 5개이다.
-> 샤드가 5개이고 샤드마다 하나의 소비자가 필요하기 때문
-> 샤드가 5개이기 때문에 초당 5MB의 데이터 수신 - SQS FIFO
SQS FIFO 대기열은 하나뿐이다.
-> 샤드 및 파티션을 정의할 필요없이 하나의 대기열만 있다.
100개의 트럭이 있으므로 각 트럭 ID에 상응하느 그룹 ID를 100개 생성한다.
-> 그룹 ID가 100개가 되고 소비자도 최대 100개가 될 수 있다.
--> 각 소비자가 특정한 그룹 ID와 연결 되기 때문
SQS FIFO에서 최대 초당 300 or 3000개(배치 사용시)의 메시지를 가진다
- Kinesis 데이터 스트림에서 평균적으로 가지는 값
서로 다른 소비, 생산, 정렬 모델에서 경우에 따라 적절한 모델은 달라진다.
- SQS FIFO는 그룹 ID 숫자에 따른 동적 소비자 수를 원할때
- Kinesis데이터 스트림은 대규모 데이터를 전송하고, 데이터 스트림에 샤드당 데이터를 정렬할 때
SQS vs SNS vs Kinesis
SQS
- 소비자가 SQS 대기열에서 메시지를 요청해서 데이터를 가져오는(pull) 모델
- 데이터를 처리한 후 소비자가 대기열에서 삭제해서 다른 소비자가 읽을 수 없도록 해야 한다.
- 작업자나 소비자 수에 제한이 없다.
작업자와 소비자가 함께 소비하고 대기열에서 삭제하기 때문 - 관리된 서비스이므로 처리량을 프로비저닝할 필요가 없다
아주 빠르게 수백 수천 개의 메시지로 확장 가능 - 순서를 보장하고 싶다면 FIFO 대기열을 활성화해야 한다.
- 각 메시지에 지연 기능이 있다.
30초등 일정 시간뒤에 대기열에 나타나도록 할 수 있다.
SNS
- 게시/구독 모델
다수의 구독자에게 데이터를 푸시하면 메시지의 복사본을 받는 것 - SNS 주제별로 1250만명의 구독자까지 가능
- 데이터가 한 번 SNS에 전송되면 지속되지 않는다.
즉, 데이터가 잘 전달되지 않으면 데이터를 잃을 가능성이 있다. - 게시/구독 모델은 최대 10만개의 주제로 확장 가능하다.
- 처리량을 프로비저닝하지 않아도 된다.
- SQS와 결합할 수 있다.
팬아웃 아키텍처 패턴을 이용하면 SNS와 SQS를 결합 - 또는 SNS FIFO 주제를 SQS FIFO 대기열과 결합 할 수 있다.
Kinesis
- 두 가지 소비 모드
- 표준 모드
소비자가 Kinesis로부터 데이터를 가져옴(pull)
샤드당 2MB/s 지원 - 향상된 팬아웃 모드
Kinesis가 소비자에게 데이터를 보냄(push)
샤드하나에 소비자당 2MB/s 지원
처리량이 훨씬 높아 Kinesis 스트림에서 더 많은 애플리케이션 읽기가 가능
- 표준 모드
- 데이터가 지속되기 때문에 데이터를 다시 재생할 수 있다.
실시간 빅 데이터 분석, ETL등에 활용 - 샤드 레벨에서 정할 수 있어 Kinesis Data Stream마다 원하는 샤드 양을 지정해야 한다.
- 샤드를 직접 확장해 데이터가 언제 만료될지 정한다.
1 ~ 365일까지 데이터 보존 가능 - 용량 모드
- 프로비저닝 용량 모드
Kinesis Data Stream으로부터 원하는 샤드 양을 미리 지정 - 온디맨드 용량 모드
샤드 수가 Kinesis Data Stream에 따라 자동으로 조정
- 프로비저닝 용량 모드
Amazon MQ
- SQS와 SNS는 AWS의 독점 기술(클라우드 기본 서비스)
각자 사용하는 API 세트가 따로 있다. - 온프레미스에서 기존 애플리케이션을 실행하는 경우
개방형 프로토콜인 MQTT,AMQP,STOMP,WSS,Openwire등을 사용하면 된다. - 애플리케이션을 클라우드에 마이그레이션하는 경우
SQS,SNS 프로토콜 대신 MQTT,AMQP등과 같은 기존에 쓰던 프로토콜을 사용하고 싶을 수 있는데
그럴때 Amazon MQ 사용!
Amazon MQ
- Amazon MQ는 관리형 메시지 브로커 서비스(RabbitMQ와 ActiveMQ)
- RabbitMQ와 ActiveMQ는 온프레미스 기술
개방형 프로토콜 액세스를 제공한다.(MQTT,AMQP,STOMP,WSS,Openwire등) - Amazon MQ를 이용하면 해당 브로커의 관리형 버전을 클라우드에서 사용할 수 있다.
- 특징
- Amazon MQ는 확장성이 작다.
Amazon MQ는 서버에서 실행되기 때문에 서버 문제가 있을 수 있기 때문이다. - 고가용성을 위해 장애 조치와 함께 다중 AZ 설정을 할 수 있다.
- Amazon MQ는 SQS처럼 보이는 대기열 기능과 SNS처럼 보이는 주제 기능이 있다.
- Amazon MQ는 확장성이 작다.
Amazon MQ - 고가용성 (시험)
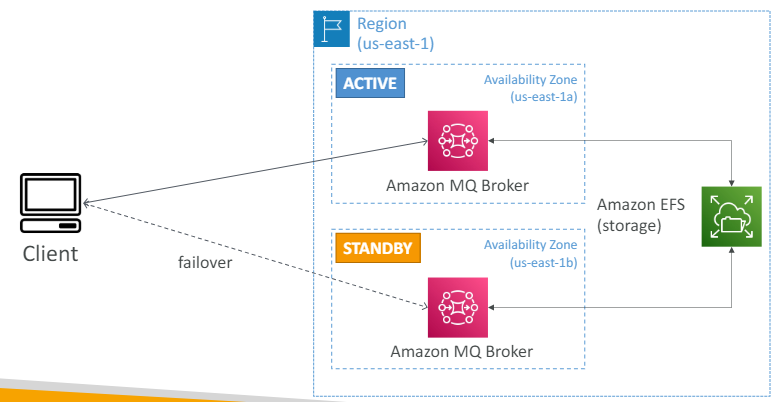
(설명)
(ㄱ) us-east-1 리전에 us-east-1a와 us-east-1b의 가용 영역이 있다.
(ㄴ) 영역 하나는 활성 상태이고 다른 하나는 대기 상태이다.
(ㄷ) 두 영역에 각각 활성, 대기 상태인 Amazon MQ 브로커를 추가한다.
(ㄹ) 장애 조치 실행을 위해 백엔드 스토리지에 EFS를 정의한다.
EFS는 네트워크 파일 시스템으로 다중 AZ에 마운트 할 수 있다.
(ㅁ) 이렇게 설정하면 장애 조치가 일어날 때마다 대기 상태 영역도 EFS에 마운트된다.
(ㅂ) 그래서 첫 번째 활성 대기열과 동일한 데이터를 가질 수 있다.
따라서 장애 조치도 올바르게 실행될 것이다.
(ㅅ) 클라이언트가 Amazon MQ 브로커와 통신해서 장애 조치가 실행되는 경우에도 EFS로 인해 데이터가 저장된다.
