Kinesis
- Kinesis
- 실시간 스트리밍 데이터를 손쉽게 수집
- 실시간 스트리밍 데이터를 처리,분석
- 실시간 데이터
- 애플리케이션 로그
- 애플리케이션 계측
- 웹 사이트 클릭 스트림
- IoT 원격 측정 데이터
- 등등...
- Kinesis 서비스 종류
- 1) Kinesis Data Stream
데이터스트림을 수집해 처리하고 저장 - 2) Kinesis Data Firehose
데이터스트림을 AWS 내부나 외부의 데이터 저장소로 로드 - 3) Kinesis Data Analytics
SQL이나 Apache Flink를 활용해 데이터 스트림 분석 - 4) Kinesis Video Stream
비디오 스트림을 수집하고 처리해 저장
- 1) Kinesis Data Stream
Kinesis Data Stream
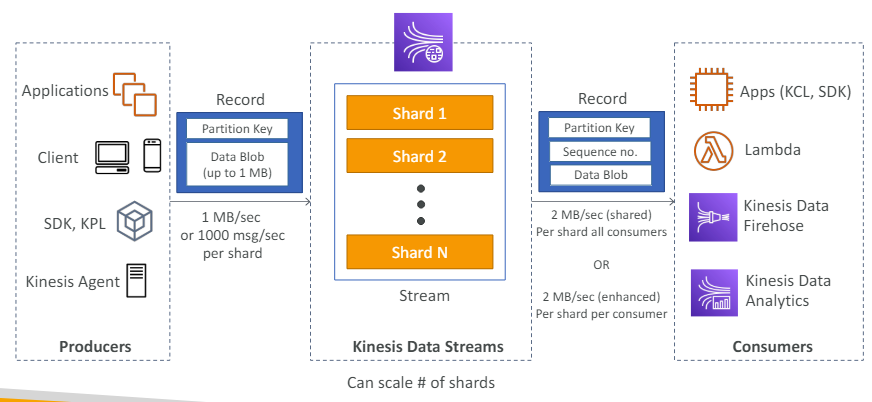
- 시스템에서 규모가 큰 데이터 흐름을 다루는 서비스
- Kinesis Data Stream는 여러개의 샤드로 구성
사전에 프로비저닝해 샤드 번호를 매긴다.
-> Kinesis Data Stream을 시작할때 몇개의 샤드로 구성할지 결정
--> 그럼 데이터는 모든 샤드에 분배 될 것이다. - 샤드는 데이터 수집률이나 소비율 측면에서 스트림 용량을 결정.
(생산자)
- 생산자는 데이터를 Kinesis Data Stream으로 보낸다.
생산자: 애플리케이션, 클라이언트, SDK, KPL, kinesis Agent - 생산자는 모두 동일한 작업을 한다.
매우 낮은 수준에서 SDK에 의존하며 Kinesis Data Stream에 레코드를 전달- 레코드 요소
(1) 파티션 키: 레코드가 이용할 샤드 결정
(2) 최대 1MB 크기의 데이터 블롭: 값 자체를 의미
- 레코드 요소
- 생산자는 데이터를 스트림으로 보낼 때
- 초당 1MB를 전송하거나
- 샤드당 1초에 천 개의 메시지 전송
만약 6개의 샤드가 있으면 초당 6MB를 얻거나 6천개의 메시지를 얻을 수 있다.
(소비자)
- 데이터가 스트림에 들어가면 많은 소비자가 이 데이터를 사용하게 된다.
소비자: 애플리케이션(SDK, KCL), 람다 함수, Kinesis Data Firehose, Kinesis data Analytics - 소비자가 레코드를 받으면
- 파티션 키
- 시퀀스 번호
샤드에서 레코드의 위치를 나타냄 - 데이터 블롭
데이터 자체를 의미
- Kinesis Data Stream에는 여러 소비 유형이 있다.
- 샤드마다 초당 2MB의 처리량을 모든 소비자가 공유
- 소비자마다 샤드당 1초에 2MB씩 받기
효율성을 높인 팬아웃 방식의 경우
스트림으로부터 병렬로 데이터를 검색하는 다수의 소비자가 있다면 향상된 팬아웃 기능을 사용해야 한다.
정리
- 생산자가 Kinesis Data Stream에 데이터를 전송하고
- 데이터는 잠시 스트림에 머물면서 여러 소비자에게 읽힌다.
Kinesis Data Stream 특징
- 보존 기간
1 ~ 365일 사이로 설정 가능
-> 데이터를 다시 처리하거나 확인할 수 있다. - 데이터가 Kinesis로 들어오면 삭제할 수 없다.(불변성)
- 데이터 스트림으로 메시지를 전송하면 파티션 키가 추가된다.(오더링)
파티션 키가 같은 메시지들은 같은 샤드로 들어가게 된다.
-> 키 기반으로 데이터를 정렬 가능. - 생산자
SDK, KPL(Kinesis Producer Library), Kinesis Agent를 사용해 데이터를 전송 - 소비자
- KCL(Kinesis Client Library), SDK를 사용해 직접 데이터 작성 가능
- AWS 람다, Kinesis Data Firehose, Kinesis Data Analytics를 활용 가능.
Kinesis Data Stream 용량 유형
- 프로비저닝 모드(전통적인 용량 유형)
- 프로비저닝할 샤드 수를 정하고
- API 활용
or - 수동을 조정
- API 활용
- Kinesis Data Stream에 있는 각 샤드는
초당 1MB나 1,000개의 레코드를 받아들인다. - Kinesis Data Stream에 있는 각 샤드는
초당 2MB를 받아들임. -> 일반적인 소비 유형이나 효율성을 높인 팬아웃 방식에 적용 - 샤드를 프로비저닝할 때마다 시간당 비용이 부과됨.
- 사전에 사용량을 계획할 수 있다면 프로비저닝 모드 선택해라
- 프로비저닝할 샤드 수를 정하고
- 온디맨드 모드
- 프로비저닝 하거나 용량을 관리할 필요 없음.
시간에 따라 언제든 용량이 조정됨. - 초당 4MB 또는 초당 4,000개의 레코드 처리
- 지난 30일 동안 관측한 최대 처리량에 기반해 자동으로 용량을 조정
- 시간에 대한 스트림당 송수신한 GB에 따라 비용 부과
- 사전에 사용량을 예측할 수 없을때 온디맨드 모드 선택해라
- 프로비저닝 하거나 용량을 관리할 필요 없음.
Kinesis Data Stream - 보안
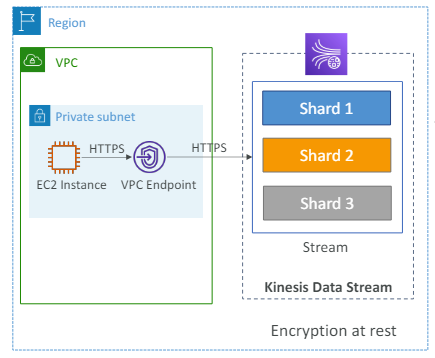
- IAM 정책
- 샤드를 생성하거나
- 샤드에서 읽어 들이는 접근 권한을 제어
- 암호화
- HTTPS로 전송 중 데이터 암호화
- CMS로 미사용 데이터 암호화
- 클라이언트 측 암호화
클라이언트 측에서 데이터를 암호화하거나 해독 가능
-> 직접 데이터를 암호화하고 해독해야 한다. - VPC 엔드포인트
Kinesis에 VPC 엔드포인트를 사용할 수 있다.- 프라이빗 서브넷의 인스턴스에서 kinesis에 직접 접근 가능
인터넷을 거치지 않음.
- 프라이빗 서브넷의 인스턴스에서 kinesis에 직접 접근 가능
- 모든 API 요청은 CloudTrail로 감시할 수 있다.
Kinesis Data Stream 실습
- Kinesis Data Stream 생성
- 이름, 데이터 스트림 용량 설정
- 모드 설정
- 프로비저닝 모드
용량을 미리 알 때
샤드 설정을 해주야 함(레코드속도,레코드 크기, 소비자 수 설정)
쓰기: 초당 1MB
읽기: 초당 2MB - 온디맨드 모드
용량을 모를 때
최대 처리량: 초당 200MB, 20만 레코드
최대 읽기 용량: 초당 400MB(소비자 한 명에 한해 향상된 팬아웃 옵션 사용할 경우)
- 프로비저닝 모드
- 생성하면 애플리케이션 탭에 생산자 메뉴에 옵션이 3가지 있다.
- 생산자
- Kinesis Agent
애플리케이션 서버에서 Kinesis Data Stream으로 데이터를 스트리밍하는 방법 - AWS SDK
낮은 수준부터 생산자를 개발할 때 사용 - Kinesis Producer Library(KPL)
더 나은 API를 가지고 높은 수준부터 생산자를 개발할때 사용
- Kinesis Agent
- 소비자 탭
- kinesis Data Analytics
- Kinesis Data Firehose
- Kinesis Client Library(KCL)
- 람다 함수
- 생산자
- 모니터링 탭
- 레코드를 전송량
- 구성 탭
- 스트림 조정(샤드 조정)
- 태그 추가
- 향상된 팬아웃
향상된 팬아웃 기능을 활용하는 소비자 애플리케이션이 필요한 경우 구성
CLI 이용하기(AWS SDK)
공유 소비 모델
# kinesis-data-streams.sh
// CLI 버전확인
aws --version
(생산자)
// CLI v1인 경우 - Kinesis Data Stream으로 레코드 전송
aws kinesis put-record --stream-name test \
--partition-key user1 --data "user signup"
// CLI v2인 경우 - Kinesis Data Stream으로 레코드 전송
aws kinesis put-record --stream-name 'Kinesis Data Stream 이름' \ --> put-record API 사용해 스트림 이름을 기재
--partition-key user1 --data "메세지"\ --> 전송하는 데이터에 맞는 파티션 키를 명시(같은 파티션 키를 공유하는 데이터는 같은 샤드로 가야한다.)
--cli-binary-format raw-in-base64-out --> 텍스트 데이터를 쓰고 있으므로 raw-in-base64-out 옵션 사용
# 위 명령어를 치면 메시지가 나옴
{
"ShardId": "~~~" // 샤드 ID
"SequenceNumber": "~~~" // 메세지 시퀀스 번호
}
생성한 Kinesis Data Stream로 돌아가 모니터링 탭의 스트림 지표를 보면 보낸 레코드를 확인할 수 있다.(CloudWatch가 지표를 업데이트)
(소비자)
# 스트림 구성에 대한 정보 얻기
// 스트림 설명
aws kinesis describe-stream --stream-name "Kinesis Data Stream 이름"
-> 스트림 정보가 나옴
# 데이터 소비
aws kinesis get-shard-iterator --stream-name "Kinesis Data Stream 이름" \
--shard-id "샤드 ID" \
--shard-iterator-type TRIM_HORIZON --> TRIM_HORIZON: 처음 레코드부터 전부 읽겠다.
-> 샤드 반복자가 출력된다. // 샤드 반복자는 레코드를 소비하는데 다시 사용된다.
aws kinesis get-records --shard-iterator "출력된 샤드 반복자 값"
-> 여러 레코드가 출력된다. // 데이터는 base64로 인코딩되어 있다.
base64로 디코딩하면 데이터를 볼 수 있다.
+ 추가로 맨 아래에 샤드 반복자 인자가 있다.
이는 다음에 소비할 두 번째 샤드 반복자를 명시해 중단한 지점부터 소비할 수 있도록 해줘야 한다. ..?위 경우 KCL을 사용해야 적절한 API를 활용할 수 있다.......?
Kinesis Data Firehose
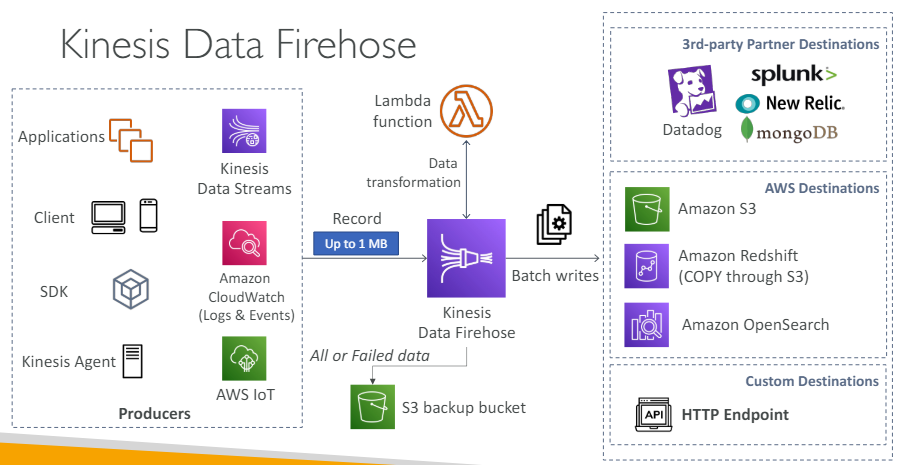
- 생산자로부터 데이터를 가져올 수 있는 유용한 서비스
- 모든 생산자 애플리케이션들은 Kinesis Data Firehose로 기록을 전송
- Kinesis Data Firehose는 데이터를 람다를 사용해 변환할지 말지 선택
- 데이터는 대상에 일괄 처리되어 쓰이게 된다.
- Kinesis Data Firehose는 소스로부터 데이터를 가져온다
- 가장 흔한 경우는 Kinesis Data Stream에서 가져오는 것이다.
- 이후 데이터를 여러 대상에 쓴다
Kinesis Data Firehose는 데이터를 쓰는 방법을 알기 때문에 코딩할 필요가 없다. - Kinesis Data Firehose의 대상(3종류)
- AWS 대상
- S3: S3로 모든 데이터를 쓸 수 있다.
- Amazon Redshift: 웨어하우징 DB
S3로 데이터를 쓴 후에 Kinesis Data Firehose가 복사 명령을 내리면 데이터를 S3에서 Redshift로 복사 - Amazon Opensearch
- 서드파티 대상
- Datadog
- Splunk
- New Relic
- MongoDB
- 등등..
- 커스텀 대상
- HTTP 엔드포인트를 갖는 자신의 API
- AWS 대상
- 대상에게 데이터가 보내진 후 옵션
- 1) 백업으로 모든 데이터를 S3 버킷으로 보내기
- 2) 대상들로 쓰는 데 실패한 데이터를 실패 S3 버킷으로 보내기
요약
- Kinesis Data Firehose는 완전관리형 서비스
- 관리할 필요 없음
- 자동확장 기능
- 서버리스 기능
- AWS 대상으로 데이터 보내기
- S3
- OpenSearch
- Redshift
- 서드 파티로 데이터 보내기
- Splunk
- MongoDB
- Datadog
- New Relic 등등..
- 커스텀 대상에게 데이터 보내기
- HTTP 엔드포인트
- Firehose를 통과하는 데이터만 비용 지불
- 근 실시간(완전한 실시간 서비스는 아님)
Firehose로부터 대상으로 데이터를 묶어 쓰기 때문이다.- 묶음이 아닌경우 60초의 지연 발생
- 아니면 대상으로 데이터를 보내려면 1MB의 데이터가 쌓일 때까지 기다려야 한다.
- Firehose 지원
- 데이터 포맷
- 변환
- 압축
- 람다를 이용해 데이터 변환 가능.
- 실패한 데이터 또는 모든 데이터를 백업 S3버킷으로 보낼 수 있다.
시험에는 Kinesis Data Stream이랑 Kinesis Data Firehose가 각각 어떤 상황에서 써야하는가에 대해 물어봄.
# Kinesis Data Stream vs Kinesis Data Firehose
Kinesis Data Stream Kinesis Data Firehose
* 대규모 데이터 수집을 위한 스트리밍 * 데이터 수집 서비스
-> S3, Redshift, OpenSearch, 서드파티, 커스텀 HTTP
* 생산자와 소비자를 위해 커스텀 코드를 써야한다. * 완전 관리형이기 때문에 관리할 서버가 없다.
* 실시간(~ 200ms) * 실시간에 가깝다(버퍼 시간 최소 60초)
* 직접 스케일을 관리해야 한다.(규모, 처리량) * 자동 스케일링 기능
-> shard splitting / shard merging -> Firehose를 지나가는 데이터만 비용지불
-> 프로비저닝한 용량만큼 비용 지불
* 데이터 저장은 1 ~ 365일 까지 가능하다. * 데이터 저장이 없다.
-> 다양한 고객들이 같은 스트림으로부터 읽을 수 있게함 -> Firehose로부터 데이터를 replay할 수 없다.
* 재생 기능 지원(replay capability) * 재생 기능 지원하지 않음(Replay capability X)Kinesis Data Firehose 실습
-
왼쪽 메뉴 Kinesis Data Firehose 생성
- 소스: Kinesis Data Stream
- 대상: S3
-> 다른 AWS서비스, 서드파티 등 다른것도 많다. - 소스 설정
탐색 -> 스트림 선택 - 전송 스트림 이름은 자동 입력된다.
- 레코드 변환 및 형식 섹션(선택)
람다를 이용해 레코드를 변환할때 사용
-> 레코드 변환, 필터, 압축해제, 형식 변환 가능 - 레코드 형식 변환 옵션
데이터를 어디로 보내느냐에 따라 이 옵션을 이용해 데이터 형식을 변환
-> 파켓 / ORC로 변환 - 목적지 설정
생성해 둔 S3 설정하거나 새로 만들어 설정한다.- 동적 파티셔닝(선택)
- S3 버킷 접두사(선택)
- 버킷 에러 출력 접두사(선택)
- S3 버퍼 힌트, 간격, 압축, 암호화 섹션 설정
- 고급 설정
- 권한 설정
IAM 역할을 자동을 생성(S3에 쓰기 권한 전부를 가짐)
- 권한 설정
-
모니터링으로 지표 확인 가능
-
설정 메뉴
-
목적지 에러 로그
CloudWatch에서 업데이트 -
이제 전에 만든 데이터 스트림으로 데이터를 더 보내보자
CLI로 위 코드를 다시 수행 -
이후 S3로 들어가 레코드가 보이는지 확인(Firehose 검색)
