S3 스토리지
- 수 많은 웹사이트에서 S3를 활용하고, 많은 AWS 서비스는 S3로 통합을 위해 사용하고 있다.
사용 사례
- 백업
- 스토리지
- 재해 복구 용도
- 아카이브용
- 하이브리드 클라우드 스토리지
- 애플리케이션 호스팅
- 미디어 호스팅
- 데이터 레이크 & 빅데이터 분석
- S/W 딜리버리
- 정적 웹 사이트 호스팅
EX
Nasdaq는 7년간의 데이터를 S3 Glacier에 저장해둠
Sysco는 자체 데이터에 관한 분석을 실행해 S3로부터 비즈니스 인사이트를 얻음.
S3 버킷
- S3는 파일을 버킷에 저장하는데 버킷은 상위 레벨 디렉토리로 표시
- S3 버킷의 파이릉ㄴ 객체라고 한다.
- 버킷은 계정 안에 생성
버킷에는 전역적으로 고유한 이름으로 지어야 한다.
-> 이름은 계정에 있는 모든 리전과 AWS에 존재하는 모든 계정에서 고유해야 한다. - 버킷은 리전 수준에서 정의
버킷 이름이 모든 리전과 모든 계정에 고유해도 버킷은 반드시 특정 AWS 리전에 정의되어야 함.
S3는 전역 서비스처럼 보이지만 리전에 생성됨. - 이름 규칙
- 대문자, 밑줄이 없어야 함.
- 3~63자
- IP 불가
- 소문자나 숫자로 시작
- 몇몇 접두사 제한
문자, 숫자, 하이픈만 사용
S3 객체
- 키
키 = 파일의 전체 경로
ex)
s3://my-bucket/my_file.txt ->
s3://my-bucket/my_folder1/another_folder/my_file.txt- 키는 접두사와 객체 이름으로 구성(prefix + object name)
prefix: 경로
object name: 파일이름 - s3 자체로는 디렉토리 개념이 아니다.
s3의 핵심은 키 - 키는 길이가 길고 슬래시를 포함해 접두사와 객체 이름으로 만들어진다.
- 키는 접두사와 객체 이름으로 구성(prefix + object name)
- 객체란?
값은 본문의 내용
-> 파일등 원하는 데이터를 s3로 업로드- 최대 크기: 5TB
5GB보다 큰 파일은 멀티파트 업로드를 사용해 파일을 여러개로 나눠 업로드 - 메타데이터(객체의 키-값 쌍 리스트)
시스템이나 사용자에 의해 설정
파일에 관한 요소, 메타데이터를 나타냄 - 태그
유니코드 키-값 쌍은 최대 10개까지 가능
태그는 보안고 수명 주기에 유용 - 버전 ID
사용하려면 버전 관리를 활성화 해야한다.
- 최대 크기: 5TB
- S3에 파일을 업로드하고 객체에 접근할때
상단의 open과 object URL이 다르다.
상단의 open으로 접근하면 긴 URL이 나오는데 이는 자격증명을 담고 있다.
-> 본인만 접근 가능하다.
폴더를 만들 수도 있다.
S3 보안 및 버킷 정책
S3 보안
- 사용자 기반
사용자에게 IAM정책으로 어떤 API호출이 특정 IAM 사용자를 위해 허용되어야 하는지를 승인 - 리소스 기반 보안
- S3 버킷 정책을 사용
S3 콘솔에서 직접 할당할 수 있는 전체 버킷 규칙
-> 특정 사용자가 들어올 수 있게 하거나 다른 계정의 사용자를 허용
--> S3 버킷에 액세스할 수 있는 교차 계정이라 한다.
--> 버킷을 공개로 만드는 방법이기도 하다. - 객체 액세스 제어 목록(ACL)
세밀한 보안 (비활성화-활성화) - 버킷 ACL
덜 일반적(비활성화-활성화)
- S3 버킷 정책을 사용
- 어떤 상황에서 IAM 원칙이 S3 객체에 액세스할 수 있을까?
- IAM 권한이 이를 허용하거나 리소스 정책이 이를 허용하는 경우
IAM 권한이 특정 API 호출 시 S3 객체에 액세스할 수 있다. - 명백한 거부는 없다.
- IAM 권한이 이를 허용하거나 리소스 정책이 이를 허용하는 경우
- 암호화
암호 키를 사용해 S3 보안 관리
S3 버킷 정책
- JSON 기반 정책

- 리소스 블록
정책이 적용되는 버킷과 객체를 정책에 알려준다. - Effect(허용/거부)
작업을 허용/거부하는 API 집합 -> Action - Action
API 집합(ex:GetObjcet) - Peincipal
정책을 적용할 사용자/계정 - 위 예시 버킷 JSON
버킷 내 모든 객체에 대해 공개 읽기로 설정
- 리소스 블록
- 버킷 정책
- 버킷에 대한 공개 액세스를 허용
- 업로드 시 객체를 강제로 암호화
- 다른 계정으로의 액세스 허용
예시
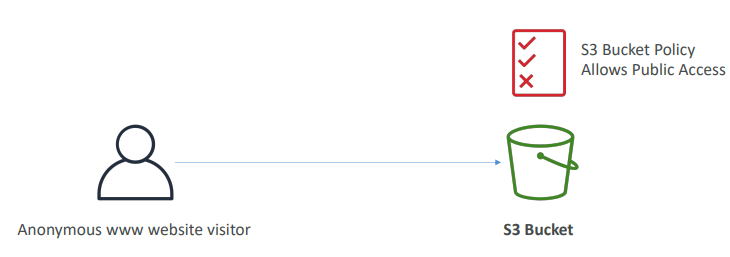
공개 액세스를 위한 버킷 정책
웹 사이트 방문자는 S3 버킷안에 있는 파일에 접속
필요한 버킷 정책을 첨부해 공개 액세스 허용 가능
버킷 정책이 S3에 첨부되면 그 안에 있는 모든 객체에 액세스 가능

IAM 사용자가 있는 경우
정책을 통해 이 사용자에게 IAM 권한을 할당할 수 있다.
이 정책이 S3 버킷으로 액세스 허용하므로 해당 사용자는 버킷에 접근 가능.
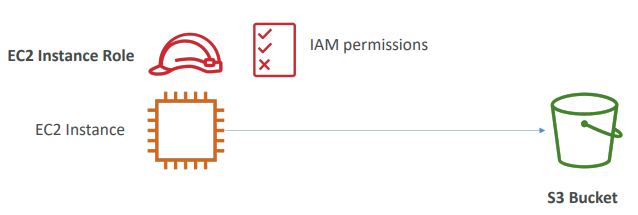
인스턴스가 있는 경우
인스턴스에서 S3 버킷으로 액세스
IAM 사용자는 적절하지 않음.
그렇기 떄문에 IAM 역할을 사용해야한다.
올바른 IAM 권한을 통해 인스턴스 역할을 생성
-> S3 버킷에 접근할 수 있게됨.

교차 계정 액세스를 혀용하려는 경우
버킷 정책을 사용
다른 계정에 IAM 사용자가 있다.
추가 버킷 정책을 생성해 이 특정 IAM 사용자에게 교차 계정 액세스를 허용하면
IAM 사용자는 S3 버킷으로 API호출을 할 수 있게 된다.
블록 공개 액세스를 위한 버킷 세팅

이 설정은 기업 데이터 유출을 방지하기 위한 추가 보안 계층이다.
AWS가 개발
S3 버킷 정책을 설정해 공개로 만들덛라도 이 설정이 활성화 되있으면
버킷은 공개되지 않는다.
-> 데이터 유출을 방지
버킷을 공개하면 안되는 경우, 이 설정으로인해 잘못된 S3 버킷 정책을 설정한 사람들에 대해 이러한 수준의 보안을 가질 수 있다.
+ 버킷중 어느 것도 공개되서는 안된다면 계정 수준에서 이를 설정하면 된다.
공개 액세스 실습
- 버킷 -> 권한 탭 -> 버킷 설정에서 공개 액세스 허용
-> 공개 버킷 정책을 사용하려는 경우메나 비활성화 할 것 - 버킷 정책 생성
AWS 정책 생성기를 사용해 S3 버킷 정책을 만들어 적용
< 정책 생성기 >
Select Type of Pollcy: S3 bucket Policy
Effect: Allow
Principal:
AWS Service: Amazon S3
Action: GetObject
Amazon Resource Name(ARN): Bucket ARN를 복사해 붙여넣고 '/ '추가
'Add Statement' 클릭
'정책 생성' 클릭 후 JSON 복사한 후 Edit bucket policy에 붙여 넣기
저장
-> 이제 공개 URL로도 접근 가능해진다.
S3 정적 웹 사이트
-
웹 사이트 URL
AWS 리전에 따라 달라진다. -
S3 버킷을 통해 웹 사이트 호스팅하기
위 URL을 통해 사용자가 S3 버킷에 액세스할 수 있다.
그러나 버킷에서 공개 읽기를 활성화 하지 않는다면 작동하지 않는다.
(주의) 활성화 했음에도 403 오류가 발생했다면 공개를 허용하는 S3 버킷 정책을 첨부해야 한다.
정적 웹 사이트 호스팅 실습
- S3 버킷 -> 파일 업로드 -> 속성 탭 -> 정적 웹사이트 호스팅 -> 편집
- <정적 웹 사이트 호스팅> 활성화 -> <호스팅 타입> 정적 웹사이트 호스팅 -> <인덱스 문서> index.html -> 저장
- 객체 탭 -> index.html 업로드 -> 속성 탭 -> 웹 사이트 호스팅에서 엔드포인스 접속
S3 버전 관리
- 버전관리를 해야하는 이유
의도치 않게 삭제되는 것을 보호
이전 버전으로 롤백 가능 - 유의사항
버전 관리가 적용되지 않는 파일은 널 버전을 갖는다.
버전 관리를 중단해도 이전 버전이 사라지지 않는다.
버전 관리 실슴
- 속성 탭 -> 버킷 버전 관리 편집 -> 활성화
index.html파일을 덮어쓴 후 객체 탭에서 버전 보기 누르면 버전 ID가 있다. - 롤백 하기
특정 버전 ID를 지우면 이전 버전으로 실행됨. - 버전 관리를 활성화 후 객체를 삭제한다면?
객체가 삭제가 되더라도 삭제된 상태를 버전ID로 남겨지고 이전 파일은 버전ID가 널인 상태로 버킷에 남아있다.
되돌리고 싶다면 삭제 마커를 삭제하면 이전 객체를 되돌릴 수 있다.
S3 복제
특정 리전에 S3 버킷이 있고, 이를 다른 리전에 복제할 때
버킷간 비동기 복제가 필요하다면
- 먼저 소스 버킷과 복제 대상 버킷 둘 모두 버전 관리 기능이 활성화되있어야 한다.
- CRR, 교차 리전 복제
두 리전이 달라야 한다. - SRR, 같은 리전 복제
두 리전이 같아야 한다. - 서로 다른 AWS 계정간에도 사용할 수 있다.
- 복제는 비동기식으로 이루어짐.
- 복제 과정은 백그라운드에서 이루어진다.
- 복제 기능이 정상적으로 실행되려면, S3에 올바른 IAM권한이 있어야 한다.(읽기/쓰기 권한)
- 유스케이스
- CRR
컴플라이언스(법규, 내부 체제 관리), 데이터가 다른 리전에 있어 지연시간을 줄기기 용도
계정간 복제 - SRR
다수의 S3 버킷간의 로그를 통합, 개발 환경이 별도로 있어 운영 환경과 개발 환경간 실시간 복제
- CRR
알아 두어야 할 점
- 새로운 객체만 복제 대상이 된다.
- 기존 객체를 복제하려면 S3 배치 복제 기능을 사용해야 한다.
기존 객체부터 복제에 실패한 객체까지 복제할 수 있는 기능. - 작업을 삭제하려면 소스 버킷에서 대상 버킷으로 삭제 마커를 복제하면 된다.
버전 ID로 삭제하는 경우 버전ID는 복제되지 않는다.(영구 삭제) - 체이닝 복제는 불가능 하다
1번 버킷이 2번 버킷에 복제되어 있고, 2번 버킷이 3번 버킷에 복제되어 있다해서 1번 버킷의 객체가 3번 버킷으로 복제되지 않는다.
복제 설정 실습
소스 버킷에서 관리 탭 -> 복제 규칙 생성(이름, 규칙 범위 선택, 대상 버킷 선택,IAM 역할 등)
복제 설정 이후에 새로 업로드 되는 객체만 복제 NO
기존 객체를 복제하고 싶다면 YES
+ 추가 기능
관리 탭에서 복제 규칙을 선택하고 규칙 편집 -> 하단에 '삭제 마커 복제'옵션 선택
기본적으로 삭제 마커는 복제되지 않지만 이를 설정하면 삭제마커 복제
S3 스토리지 클래스
S3에서 객체를 생성할 때 클래스를 선택할 수 있고, 스토리지 클래스를 수동으로 수정할 수 있다.
수명 주기 구성을 사용해 스토리지 클래스 간 객체를 자동으로 이동할 수 있다.
-
스토리지 클래스 종류
- Amazon S3 Standard - 일반 목적
가용성 99.99%
자주 액세스하는 데이터에 사용
지연 시간이 짧고 처리량이 높다
AWS에서 두 개의 기능장애를 동시에 버틸 수 있다.- 사용 사례
빅 데이터 분석
모바일, 게임 애플리케이션, 컨텐츠 배포
- 사용 사례
- 스토리지 클래스 - Infrequent Access
자주 액세스하지 않지만 필요한 경우 빠르게 액세스해야 하는 데이터
S3 Standard보다 비용이 적지만 검색 비용이 발생한다.- Amazon S3 Standard - Infrequent Access(IA)
가용성 99.9%- 사용 사례
재해 복구, 백업
접근 횟수는 적지만, 접근시 지연시간을 낮게 유지하고자 할 때 사용
- 사용 사례
- Amazon S3 One Zone - Infrequent Access
단일 AZ 내에서는 높은 내구성을 갖지만 AZ가 파괴된 경우 데이터를 잃는다.(객체 손실의 위험)
가용성 99.5%- 사용 사례
온프레미스 데이터를 2차 백업
재생성 가능한 데이터를 저장
즉, 재생성 가능하지만 하나의 존에만 생성되는 객체
- 사용 사례
- Amazon S3 Standard - Infrequent Access(IA)
- 스토리지 클래스 - Glacier Storage Class
아카이빙과 백업을 위한 저비용 객체 스토리지
스토리지 비용과 검색 비용이 발생- Amazon S3 Glacier Instant Retrieval
밀리초 단위로 검색 가능
최소 보관 기간: 90일- 사용 사례
분기에 한 번 액세스하는 데이터에 적합
백업이지만 밀리초 이내에 액세스해야 하는 경우 적합
- 사용 사례
- Amazon S3 Glacier Flexible Retrieval
최소 보관 기간: 90일- 옵션
- Expedited
데이터를 1~5분 이내에 받을 수 있다. - Standard
데이터를 3~5시간 이내에 받을 수 있다. - Bulk
무료이지만 데이터를 돌려받는데 5 ~12시간이 걸린다.
- Expedited
- 옵션
- Amazon S3 Glacier Deep Archive
장기 보관을 위한 것
가장 저렴하다.
최소 보관 기간: 180일- 검색 티어
- Standard: 12시간
- Bulk: 48시간
- 검색 티어
- Amazon S3 Glacier Instant Retrieval
- Amazon S3 Intelligent Tiering
사용 패턴에 따라 액세스된 티어 간에 객체를 이동할 수 있게 한다.
소액의 월별 모니터링 비용과 티어링 비용이 발생
그러나 검색 비용이 없다.
알아서 객체를 이동시켜 주기 때문에 편하게 스토리지를 관리
데이터에 대한 접근 패턴을 알 수 없을때 사용- 티어
FrequentAccess tier(자동): default 티어
Infrequent Access tier(자동): 30일 동안 액세스하지 않는 객체 전용 티어
Archive Instant Access tier(자동): 90일 동안 액세스하지 않는 객체 전용 티어
Archive Access tier(선택사항): 90~700일이상 까지 구성할 수 있다.
Deep Archive Access tier(선택사항): 180~700일 이상 액세스하지 않는 객체
- 티어
- Amazon S3 Standard - 일반 목적
-
내구성과 가용성
- 내구성
S3로 인해 객체가 손실되는 횟수
S3는 99.999999999%의 내구성 보장
S3에서 모든 스토리지 클래스의 내구성을 동일하다. - 가용성
서비스가 얼마나 용이하게 제공되는가
스토리지 클래스마다 다르다.
- 내구성
스토리지 클래스 실습
파일 업로드 시 업로드 옵션에서 특성 목록 -> 스토리지 클래스 메뉴에서 원하는 스토리지 클래스 선택
이후 파일에서 속성 메뉴로 스토리지 클래스를 다른 것으로 바꿀수 있다.
- 객체 스토리지 클래스 변경 자동화
버킷 화면에서 관리 목록 -> 생명주기 규칙 생성 -> 몇일 뒤에 변경할 스토리지 클래스 넣기
