다른 스토리지 클래스 간 객체를 옮기는 방법
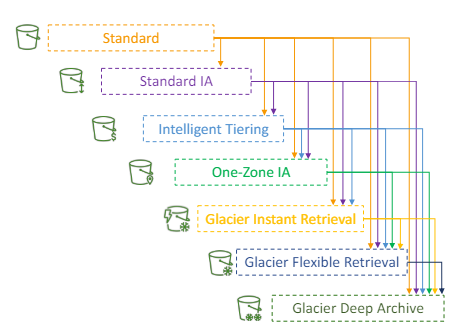
- Standard에서
실제로 객체에 자주 액세스하지 않을걸 알고 있다면 Standard IA로 옮기거나
객체를 아카이브화 하려는 걸 알고 있다면 Glacier 티어나 Deep Archive 티어로 이전 - 이 과정을 수작업으로 옮길 수도 있겠지만 라이프사이클 규칙으로 자동화 해보자
생명주기 규칙
- Transition Actions
객체를 다른 스토리지 클래스로 이전하기 위해 설정- 예시
생성 후 60일 뒤에 Standard 클래스로 이전하기
6개월 뒤 Glacier로 이전해 아카이브화 하기
- 예시
- Expiration actions
일정한 시간 뒤에 만료되어 객체를 삭제하도록 설정- 예시
버저닝을 활성화 했다면 Expiration actions를 사용해 모든 파일 버전 삭제하기
불완전한 멀티파트 업로드를 삭제
-> 멀티파트 업로드가 2주 이상 된 경우에도 완전히 완료 되지 않은 경우에 그걸 삭제
- 예시
- 규칙은 특정한 접두어에 대해 지정할 수 도 있다.
그것을 버킷 전체에 적용하거나 버킷 안의 특정한 경로에 적용할 수 있다.
또는 특정한 객체 태그에 대해 규칙을 지정할 수도 있다.
시나리오
- 1 문제
EC2 애플리케이션이 있고, 그 앱은 프로필 사진이 S3에 업로드된 후에 이미지 섬네일을 생성한다.
그러나 섬네일들은 원본 사진으로부터 쉽게 재생성할 수 있다. 그리고 60일 동안만 보관해야 한다.
원본 이미지는 60일 동안은 곧바로 받을 수 있어야 하고, 그 후에 사용자는 최대 6시간동안 기다릴 수 있다.- 1 해결
S3 원본 이미지는 Standard 클래스에 있을 수 있고, 60일후에 Glacier로 이전하기 위한 라이프 사이클 설정
그리고 섬네일 이미지는 접두어를 써서 소스와 섬네일을 구분하고, 섬네일은 One-Zone IA에 있을 수 있다.
왜냐하면 빈번히 액세스하는게 아니고 쉽게 재생성할 수 있기 때문.
그리고 60일 후에 그것들을 만료하거나 삭제하는 라이프사이클설정이 있을 수 있다.
- 1 해결
- 2 문제
회사 규칙에 따라 30일 동안은 삭제된 S3 객체를 즉각적으로 복구할 수 있어야한다.
그 기간이 지나면 최장 365일 동안은 삭제된 객체를 48시간 이내에 복구할 수 있어야 한다.- 2 해결
S3 버저닝을 활성화해 객체 버전을 보관할 수 있고, 삭제된 객체들은 실제로 "삭제 마커"에 감춰져 있다.
그런 다음 복구할 수 있을 것이다.
다음으로 현재 버전이 아닌 객체들을 Standard IA로 이전하기 위한 규칙을 만들 것이다.
즉, 현재 버전이 아닌 버전들을 아카이브화를 목적으로 Giacier Deep Archive로 이전할 수 있다.
- 2 해결
스토리지 클래스 분석
- Amazon S3 Analytics
객체를 다른 클래스로 이전할 최적의 일 수를 결정하도록 도와준다.
Standard나 Standard IA에 관한 추천사항을 제시해 준다.
One-Zone IA나 Glacier는 호환되지 않는다.- S3 버킷에 S3 Analytics가 실행되고 있다면
.csv보고서를 생성하고 추천사항과 통계를 제공해준다.
보고서는 매일 업데이트되고, 데이터 분석 결과는 24~48시간정도 걸린다.
이 보고서를 보고 합리적인 라이프사이클 규칙을 조합하거나 개선하기 좋은 자료이다.
- S3 버킷에 S3 Analytics가 실행되고 있다면
버킷 수명 주기 규칙 생성하기 실습
S3 -> 버킷 -> 관리 탭 -> 수명 주기 생성 -> 이름, 규칙 범위 선택, 규칙 작업 선택
- 규칙 작업(5개)
- 스토리지 클래스간 최신 버전의 객체 이동
버저닝된 버킷이 있어야한다. - 스토리지 클래스간 이전 버전으로 객체 이동
새 객체에 의해 코드가 덮어쓰기된 이전 버전을 이동시키는 것 - 객체의 최신 버전 만료
- 최신 버전이 아닌 객체 영구 삭제
- 만료된 객체 삭제 마커 또는 완료되지 않은 멀티파트 업로드 삭제
- 스토리지 클래스간 최신 버전의 객체 이동
S3 요청자 지불
버킷 소유자가 버킷과 관련된 모든 S3 스토리지 및 데이터 전송 비용을 지불한다.
- 요청자 지불 버킷 활성화
버킷 소유자가아니라 요청자가 비용을 지불한다.
대량의 데이터 셋을 다른 계정과 공유하려 할때 매우 유용
단, 요청자가 익명이면 안된다.(요청자가 AWS에서 인증을 받아야 한다.)
S3 이벤트 알림
- S3 이벤트란?
객체가 생성/삭제/복구/복제 되는것.
이러한 이벤트들을 필터링 할 수 있다.- 사용 사례
S3 에서 일어나는 특정한 이벤트에 자동으로 반응하려는 경우
-> S3에 업로드된 모든 이미지의 섬네일을 생성하려 하는 경우
--> 이벤트 알림을 만들고 몇몇 대상에 전송할 수 있다.
--> (대상) SNS 토픽, SQS Queue, 람다 함수 - 원하는 만큼 S3 이벤트를 만들 수 있고, 원하는 타깃에도 전송할 수 있다.
- 이벤트들은 보통 몇 초 안에 대상으로 전달되지만 몇 분정도 걸릴 수 있다.
- 이벤트 알림이 작동하려면 IAM권한을 가지고 있어야 한다.
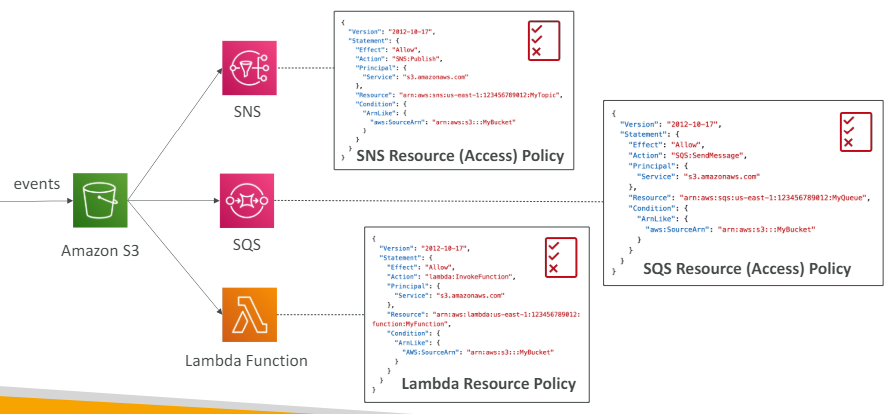
- 즉, SNS,SQS,람다 함수가 이벤트 알림 타킷이라는 것을 기억하자.
- 사용 사례
- 통합(EventBridge)
이벤트는 S3 버킷으로 갈것이고 모든 이벤트는 결국 Amazon EventBridge로 가게 된다.
EventBridge에서 규칙을 설정할 수 있고, 그 규칙으로 이벤트들을 18가지 AWS 서비스에 전송할 수 있게 된다.
-> EventBridge를 사용하면 더 많은 고급 필터링 옵션을 사용 가능해 진다.(메타데이터, 객체 사이즈, 이름)
-> 다수의 대상에게 한번에 전송할 수도 있다.(Step Functions, Kinesis Streams, Firehose)
-> 아카이빙, 이벤트 중계, 안정적인 전달 기능을 사용가능. - 정리
S3의 이벤트는 SNS,SQS,람다,EventBridgedp 전송해서 이벤트에 반응할 수 있다.
실습
버킷 -> 속성 메뉴 -> 이벤트 알림 or EventBridge
- 이벤트 알림
이름 설정 -> 이벤트 유형 선택 -> 게시할 대상 선택(람다, SNS, SQS)
(주의) 람다,SNS,SQS사용시 액세스 정책 변경해야 이벤트 생성됨.- 자동화 섬네일 만들기
버킷에 파일 업로드하고 SQS에서 send and recive messages -> Poll fot messages 클릭
- 자동화 섬네일 만들기
- EventBridge
편집 -> 활성화
S3 퍼포먼스
기본적으로 S3는 요청이 많을때 자동으로 확장
prefix당 초당 3500개의 PUT/COPY/POST/DELETE, 초당 5500개의 GET/HEAD요청을 지원한다.
버킷 내에 접두사의 제한은 없다
- 예
file이라는 이름을 가진 4개의 객체가 있다 가정해보자- 첫 번째 객체의 위치는 bucket/folder1/sub1/file이다.
이 경우 bucket과 file 사이에 있는 folder1/sub1이 접두사가 된다.
folder1/sub1접두사를 가진 file은 초당 3500개의 PUT 요청과
초당 5500개의 GET 요청을 처리한다. - bucket/folder1/sub2/file 폴더가 있는경우
접두사는 folder1/sub2가 되고
이 접두사에 대해서도 초당 3500개의 PUT 요청과
초당 5500개의 GET 요청을 처리한다. - bucket/1/file => /1/ 접두사
- bucket/2/file => /2/ 접두사
- 첫 번째 객체의 위치는 bucket/folder1/sub1/file이다.
- 위 예시와 같이 4개의 접두사에 읽기 요청을 균등하게 분산하면?
초당 22,000개의 GET/HEAD 요청을 처리한다.
S3 성능/최적화
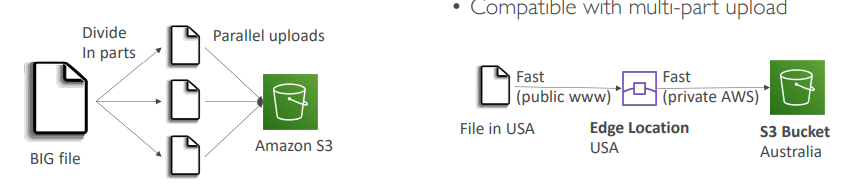
- 멀티파트 업로드
(ㄱ) 100MB가 넘는 파일은 멀티파트 업로드를 사용하는 것이 좋다.
(ㄴ) 5GB가 넘는 파일이라면 반드시 사용해야한다.
(ㄷ) 멀티파트 업로드는 업로드를 병렬화하므로 접송 속도를 높여 대역폭을 최대화 할 수 있다. - S3 전송 가속화
(ㄱ) 파일을 AWS 엣지 로케이션으로 전송해서 전송 속도를 높이고 데이터를 대상 리전에 있는 S3 버킷으로 전달한다.
엑지 로케이션은 리전보다 수가 많고 현재 엣지 로케이션은 200개가 넘고 계속 증가중이다.
(ㄴ) 전송 가속화는 멀티파트 업로드와 같이 사용할 수 있다.
=> 퍼블릭 인터넷의 사용량을 최소화하고 프라이빗 AWS 네트워크의 사용량을 최대화
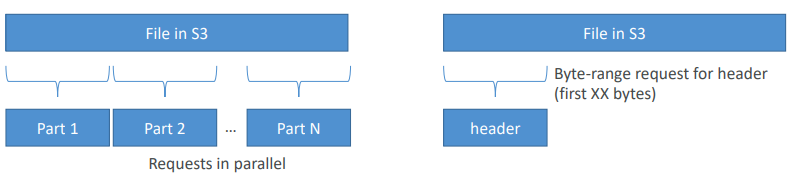
S3 바이트 범위 가져오기
파일을 수신하고 파일을 읽는 가장 효율적인 방법
- 파일에서 특정 바이트 범위를 가져와서 GET 요청을 병렬화한다.
- 특정 바이트 범위를 가져오는데 실패한 경우에도 더 작은 바이트 범위에서 재시도해 실패의 경우에도 복원력이 높다.
- 사용 사례
(ㄱ) 다운로드 속도 높일 때
(ㄴ) 파일의 일부만 검색할 때
-> 만약 S3 파일의 첫 50바이트가 헤더이고, 파일에 대한 정보를 안다면
첫 헤더 50바이트에서 헤더에 대한 바이트 범위 요청을 보내면 된다.
그럼 해당 정보를 빠르게 수신할 수 있게 된다.
- 사용 사례
S3 Select & Glacier Select
- S3에서 파일을 검색할 때 검색한 후 필터링하면 너무 많은 데이터를 검색하게 된다.
- 대신 서버 측 필터링을 수행한다면 어떨까?
필터링하는 위치를 클라이언트쪽에서 말고 서버쪽에서 수행하도록 함.- SQL 문에서 간단히 행과 열을 사용해 필터링할 수 있다.
- 네트워크 전송이 줄어들기 때문에 데이터 검색과 필터링에 드는 클라이언트 측의 CPU 비용도 줄어든다.
- 정리하자면..
Select 사용 전에는 모든 데이터를 검색한 다음 애플리케이션 측에서 필터링을 통해 찾는다면
S3 Select 사용하면 S3가 대신 파일을 필터링하고 필요한 데이터만 검색할 수 있게 된다. -> 속도 +400%, 비용 -80% - 필터링 종류
S3 Select
Glacier Select
S3 Batch Operations(일괄 작업)
- 단일 요청으로 기존 S3 객체에서 대량 작업을 수행하는 서비스
- 사용 사례
(ㄱ) 한 번에 많은 S3 객체의 메타데이터와 프로퍼티를 수정
(ㄴ) 배치 작업으로 S3 버킷 간에 객체를 복사할 수 있음.
(ㄷ) S3 버킷 내 암호화되지 않은 모든 객체를 암호화할 수 있다.
(ㄹ) ACL이나 태그를 수정
(ㅁ) S3 Glacier에서 한 번에 많은 객체를 복원할 수 있다.
(ㅂ) 람다 함수를 호출해 S3 Batch Operations의 모든 객체에서 사용자 지정 작업을 수행
등등. 객체 목록에서 원하는 작업은 무엇이든지 수행할 수 있다.
작업은 객체의 목록, 수행할 작업 옵션 매게 변수로 구성 - 왜 스크립팅하지 않고 Batch Operations를 사용할까?
Batch Operations를 사용하면..
(ㄱ) 재시도를 관리할 수 있다.
(ㄴ) 진행 상황을 추적
(ㄷ) 작업 완료 알림
(ㄹ) 보고서 생성등의 기능을 사용 할 수 있다. - S3 배치에 전달할 객체 목록 생성방법
S3 Inventory 기능을 사용해 객체 목록을 가져오고 S3 Select를 사용해 객체를 필터링한다.
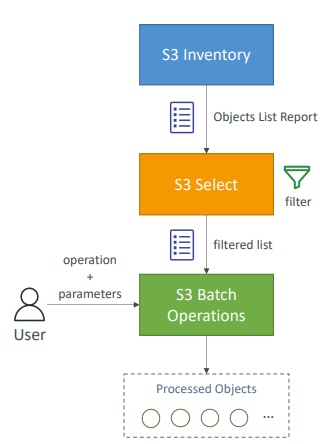
=> S3 Inventory와 S3 Select를 사용해서 배치 작업에 포함하려는 필터링된 객체 목록을 얻은 다음
S3 Batch Operations에 수행할 작업, 매개 변수와 함께 객체 목록을 전달
S3 배치가 작업을 수행하고 객체를 처리
(사용 사례)
Inventory를 사용해 암호화되지 않은 모든 객체를 찾은 다음 Batch Operations를 사용해 한번에 모두 암호화
- 사용 사례
S3 Storage Lens
- 스토리지 분석 최적화 서비스
- S3 스토리지 렌드를 통해 이상 징후를 발견 및 비용 효율성 파악해 전체 AWS 조직에 보호 모범 사례를 적용한다.
-> 30일 사용량/활동 메트릭 제공
- 특정 계정, 지역, 버킷, 접두사별로도 데이터를 집계
- 나만의 대시보드/기본 대시보드 사용 가능.
- 모든 메트릭과 모든 리포트를 CSV 또는 parquet 형식으로 버킷으로 내보낼 수 있다.
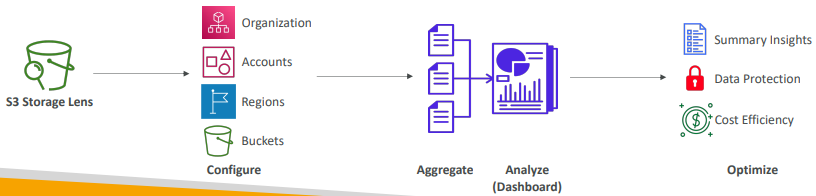
기본 대시보드
- 요약된 인사이트와 트렌드 확인
- 여러 지역과 여러 계정의 데이터를 표시 [v]
- S3에 의해 사전에 구성된다.
- 삭제는 불가능하지만 비활성화할 수 있다.
메트릭
- 요약 메트릭
- 일반적인 인사이트를 제공
- 스토리지 바이트: 스토리지 및 객체의 크기를 파악
-> 스토리지에 얼마나 많은 객체가 있는지 파악 - 사용 사례
가장 빠르게 성장하거나 사용하지 않는 버킷과 접두사를 식별
- 스토리지 바이트: 스토리지 및 객체의 크기를 파악
- 비용 최적와 지표
스토리지 비용을 관리/최적화 인사이트 제공- 현재 버전이 아닌 버전에 대한 정보를 제공
- 스토리지 바이트
최신이 아닌 버전 객체의 수, 실제로 차지하는 공간,
불완전한 멀티파트 업로드 스토리지 바이트 수를 의미 - 사용 사례
불완전한 업로드가 있는 경우 버킷에서 얼마나 많은 공간을 차지하는지 확인
어떤 버킷이 다중 파트 업로드에 실패했는가
어떤 객체를 더 저렴한 스토리지 클래스로 전환할 수 있는가
- 데이터 보호 메트릭 [v]
데이터 보호 기능에 대한 인사이트 제공(객체 암호화)- VersioningEnableBucketCount를 통해 모든 버킷이 버전 관리를 통해 활성화되었는지 확인
- MFADeleteEnabledBucketCount, SSCKMSEnabledBucketCount, CrossRegionReplicationRuleCount등
- 사용 사례
데이터 보호 모범 사례를 따르지 않는 버킷을 식별
- 액세스 관리 메트릭
S3 벜시 소유권에 대한 인사이트 제공- 메트릭 이름
ObjectOwnershipBucketOwnerEnforcedBucketCount - 사용 사례
버킷이 현재 어떤 객체 소유권 설정을 사용중인지 식별
- 메트릭 이름
- 이벤트 메트릭
S3 이벤트 알림에 대한 인사이트를 얻고 S3 이벤트 알림이 구성된 버킷의 수를 파악 - 퍼포먼스 메트릭
S3 전송 가속에 대한 인사이트 제공
S3 전송 가속이 활성화된 버킷의 수를 확인 - 활성화 매트릭
- AllRequests, GetRequests, PutRequests, ListRequests, BytesDownloaded
- 상세 상태 코드 메트릭
HTTP 상태 코드에 대한 인사이트 제공- 200OKStatus Count, 403ForbiddenErrorCount등으로 버킷의 사용 유형 파악
- 일반적인 인사이트를 제공
Storage Lens - 무료 메트릭 vs 유료 메트릭 [v]
- 무료 메트릭
- 모든 고객에게 자동으로 제공
- 약 28개의 지표
- 쿼리에 대해 14일간 데이터 조회 가능
- 유료 메트릭
고급 지표 및 권장 사항- 추가 유료 지표 및 기능 제공
활동, 고급 비용 최적화, 고급 데이터 보호 및 상태 코드 - CloudWatch에 퍼블리쉬(출판)
추가 비용 없이 액세스 가능 - 접두사 수준에서 메트릭을 수집
S3 내의 접두사로 메트릭 수집 - 15개월동안 데이터 사용 가능.
- 추가 유료 지표 및 기능 제공
