S3 객체 암호화
- 객체 암호화 방법
- 서버 측 암호화(SSE)
- (1) SSE-S3
S3 에서 관리하는 키를 이용한 서버측 암호화 - 기본으로 활성화
(ㄱ) AWS에서 처리하고 관리, 소유한 키를 이용해 암호화
사용자는 그 키에 절대로 액세스할 수 없다.
(ㄴ) 객체는 AWS에 의해 서버측에서 암호화가 된다.
암호화 유형은 AES-256이다.
(ㄷ) S3가 SSE-S3메커니즘을 이용해 객체를 암호화하도록 요청하기 위해 헤더를 "x-amz-server-side-encryption":"AES256"로 설정해야한다.
(ㄹ) SSE-S3는 새로운 버킷과 새롱룬 객체에 대해 기본값으로 활성화 되어있다.
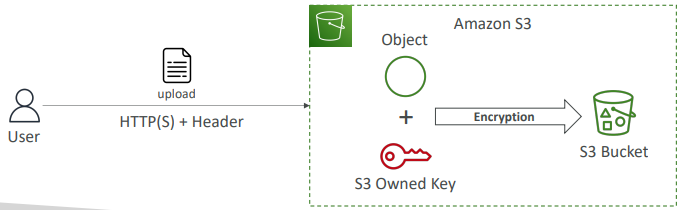
- (2) SSE-KMS
KMS(키 관리 서비스) 키를 이용해 암호화 키를 관리
(ㄱ) KMS를 사용하면 사용자가 키를 통제할 수 있는 장점이 있다.
사용자가 KMS에서 직접 키를 생성할 수 있다.
(ㄴ) CloudTrail을 이용해 키 사용을 검사할 수 있다.
로깅 서비스인 CloudTrail로 로깅
(ㄷ) 객체는 서버측에서 암호화된다.
(ㄹ) "x-amz-server-side-encryption":"aws:kms"헤더가 있어야 한다.
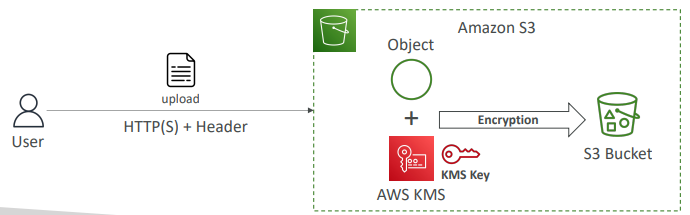
=> S3 버킷에서 파일을 읽기 위해서는 객체 자체에 액세스할 수 있어야 하고 + KMS키에도 액세스할 수 있어야 파일을 읽을 수 있다.- SSE-KMS 제한 사항
S3로 업로드하고 거기서 다운로드 하기 때문에 KMS키를 사용해야 한다.
예를들어 KMS키에는 GenerateDataKey같은 자체 API가 있고,
Decrypt API를 사용해 복호화를 한다.
그래서 사용자는 KMS 서비스에 API호출을 하게 될 것이다.
그 API호출은 모두 KMS의 초당 API 호출 쿼터에 합산된다.
그럼 서비스 쿼터 콘솔을 이용해 쿼터를 늘릴 수 있지만 리전에 따라 초당 5,000내지 30,000건의 요청이 가능하다
그렇다면 만약 사용자의 S3 버킷의 처리량이 아주 많고 모든게 KMS 키로 암호화 되어 있다면 스로틀링 활용 사례가 될 수 있다. - + DSSE-KMS
KMS를 기반으로 한 이중 암호화
- SSE-KMS 제한 사항
- (3) SSE-C
고객이 제공한 키를 사용한다. > 사용자가 가진 키를 제공
(ㄱ) 키가 AWS 외부에서 관리되지만 서버측 암호화이다.
왜냐하면 사용자가 그 키를 AWS로 전송하기 떄문이다.
하지만 S3는 그 암호화 키를 저장하지 않는다.(사용 후 폐기)
(ㄴ) 사용자는 키를 S3로 전송하기 떄문에 반드시 HTTPS를 사용해야한다.
모든 요청에 HTTP 헤더의 일부로서 키를 전달해야 한다.
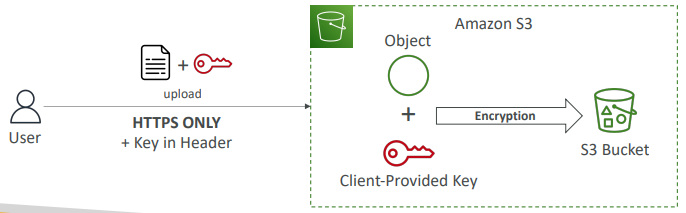
=> 사용자가 파일을 읽으려면 파일을 암호화 하기 위해 사용한 키를 제공해야 한다.
- (1) SSE-S3
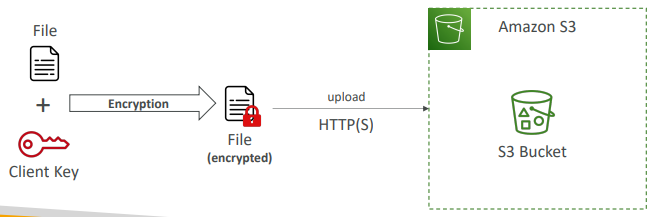
- 클라이언트 측 암호화(어떤 상황에서 사용하는지)
클라이언트 측 암호화 라이브러리 같은 클라이언트 라이브러리를 활용하면 더 쉽게 구현할 수 있다.
(ㄱ) 클라이언트 측에서 직접 데이터를 암호화한 다음 S3에 업로드
(ㄴ) 데이터의 복호화는 S3 외부의 클라이언트 측에서 이루어진다.
즉, 클라이언트가 키와 암호화 사이클을 완전하게 관리
- 서버 측 암호화(SSE)
전송 중 암호화(SSL/TLS)
- S3버킷에는 기본적으로 2개의 엔드포인트가 있다.
- HTTP 엔드포인트
- HTTPS 엔드포인트
- S3를 사용할때는 데이터 송신 보안을 위해 HTTPS를 사용하도록 권장한다.
- SSE-C 타입의 메커니즘을 이용한다면 반드시 HTTPS 프로토콜을 사용해야 한다.
전송 중 암호화 강제하기
- 버킷 정책을 활용하자.
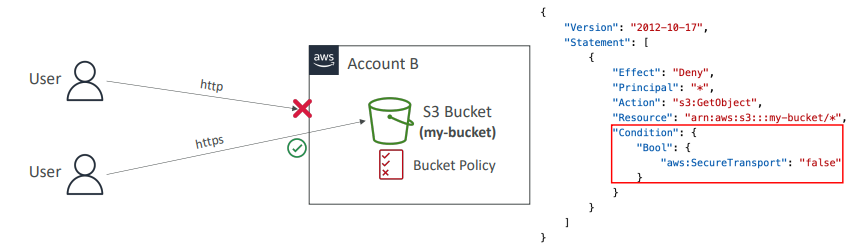
- 버킷 정책을 첨부
"aws:SecureTransport": "false" 상태이면(암호화 연결을 사용하고 있지않다면)
GetObject 작업을 거부해라.
- 버킷 정책을 첨부
암호화 실습
버킷 만들기 -> 버킷 버저닝 활성화 -> 기본값 암호화 -> SSE-S3/SSE-KMS/DSSE-KMS중 선택
만든 버킷에 파일 업로드 -> 파일에 들어간 후 -> 서버 측 암호화 설정
* 파일에 대한 암호화 메커니즘을 편집할 수도 있다.
서버 측 암호화를 편집하면 업데이트된 세팅으로 새로운 버전의 객체가 생성된다.
* 암호화 변경
편집 -> 기본 암호화에 관련된 버킷 설정 무시 -> SSE-KMS/DSSE-KMS중 선택
SSE-KMS는 KMS키를 지정해줘야 한다.
KMS key ARN을 입력하거나 사용자의 KMS 키들 중 선택
(기본 KMS키 = aws/s3)
* SSE-C는 콘솔이 아닌 CLI에서 다뤄야 한다.
* 클라이언트 측 암호화는 암호화 되었다고 알릴 필요가 없기 때문에 콘솔로 다루지 않아도 된다.
* 콘솔로 다룰 수 있는 옵션은 SSE-S3/SSE-KMS/DSSE-KMS뿐이다.
기본값 암호화 vs 버킷 정책
- SSE-S3 암호화(default)
다른 암호화 방식으로 변경할 수 있다.(위에 참고)
버킷 정책을 이용해 암호화를 강제하고, 올바른 암호화 헤더가 없는 경우 S3 객체를 PUT하는 API 호출을 거절할 수 있다.
(예시)
SSE-KMS나 SSE-C에 대해 적용할 수 있다.

=> 버킷 정책으로도 버킷안의 암호화를 강제할 수 있다.
=> 버킷 정책은 기본값 암호화 설정 이전에 평가된다.
=> 버킷 정책을 이용해 선제적으로 적용해 원하는 암호화를 강제할 수 있다.
CORS(Cross-Origin Resource Sharing,교차 오리진 리소스 공유)
- 작동 원리(시험)
- 오리진 = 체계(프로토콜) + 호스트(도메인) + 포트
(예시)
https://www.example.com(HTTPS: 443)
프로토콜: HTTPS, 포트: 443, 도메인: www.example.com - CORS는 웹 브라우저 기반 보안 메커니즘이다.
메인 오리진을 방문하는 동안 다른 오리진에 대한 요청을 허용하거나 거부한다.
웹 브라우저가 한 웹사이트를 방문하는 동안 다른 웹사이트에 요청을 보내야 하는 경우 다른 오리진이 CORS 헤더를 사용해 요청을 허용하지 않는 한 해당 요청은 이행하지 않는다. => '액세스 제어 허용 오리진' 헤더라 한다.

- 오리진이 같다는 의미란?
프로토콜, 도메인, 포트가 동일하면 오리진이 같다고 말한다.
http://example.com/app1 = http://example.com/app2
- 오리진이 같다는 의미란?
- S3에서의 CORS
클라이언트가 S3 버킷에서 교차 오리진 요청을 하면 정확한 CORS 헤더를 활성화해야 한다.
-> 빠르게 수행하려면 특정 오리진을 허용하거나
-> * 를 붙여 모든 오리진을 허용한다.
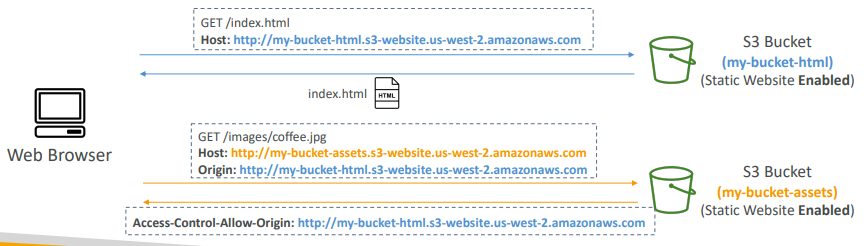
=> 웹 브라우저와 정적 웹사이트가 활성화된 S3 버킷이 있고, 자산과 이미지는 다른 버킷에 있다.
=> 웹 브라우저는 첫 번째 버킷으로 가서 해당 웹사이트 URL에 대한 index.html을 요청하고 그 html의 이미지는 다른 웹사이트에 있다.
=> images/coffee.jpg를 요청한다.
=> 올바른 CORS 헤더를 갖도록 구성되지 않으면 거부되고, 올바른 CORS를 갖고 있다면 요청을 혀옹한다. - 즉, CORS는 웹 브라우저 보안 메커니즘으로 다른 오리진에서 한 S3 버킷에 들어있는 이미지,자산,파일을 요청할 수 있게 해준다.
- 오리진 = 체계(프로토콜) + 호스트(도메인) + 포트
CORS 실습
- CORS를 사용하기전에 html파일에 CORS코드를 작성해야 한다.
(CORS 활성화 코드 - EX)
@index.html
<html>
<head>
<title>My First Webpage</title>
</head>
<body>
<h1>I love coffee</h1>
<p>Hello world!</p>
<body>
<img src="coffee.jpg" width=500/>
<!-- CORS demo -->
<div id="tofetch"/>
<script>
var tofetch = document.getElementById("tofetch");
fetch('extra-page.html')
.then((response) => {
return response.text();
})
.then((html) => {
tofetch.innerHTML = html
});
</script>
</html>@extra-page.html
<p>This <strong>extra page</strong> has been successfully loaded!</P>=>
My First Webpage에 I love coffee와 Hello worle!가 본문에 표시되고 coffee.jpg 이미지가 표시
extra-page.html 페이지를 가져와(fetch) 이미지 아래에 표시한다.
- 이제 위 코드를 이용해 실습해보자
(ㄱ) 버킷을 생성하고 파일 두개를 업로드한다.(extra-page.html, index.html파일)
(ㄴ) 속성 탭으로 가서 아래에 있는 엔드포인트를 찾아 링크를 클릭하면 새 탭에서 열린다.
(ㄷ) 그럼 웹페이지에 I love coffee, hello world!와 커피 이미지가 있고 아래에 'This extra page has been successfully loaded!' 메세지가 보일 것이다.
-> 이는 같은 오리진 안에서 fetch 요청이 작동했다는 것
--> extra-page.html, index.html파일이 같은 버킷에 있기 때문에 잘 작동된다. - CORS를 사용해보자
(ㄱ) 다른 S3 버킷을 생성하고 웹사이트로 활성화 하자(다른 오리진으로 설정)
-> 퍼블릭 액세스 차단 해제 후 생성
(ㄴ) 생성한 버킷으로 이동한 후 속성 탭으로 들어간다.
(ㄷ) 아래로 내려서 '수동 웹사이트 호스팅' 편집 -> 활성화 -> 호스팅 타입 설정 -> index문서 'index.html' -> 저장
(ㄹ) 버킷을 퍼블릭으로 설정
권한 탭 -> 버킷 정책 설정 편집 -> 버킷 정책 추가 후 저장
(ㅁ) 객체 탭에 가서 다른 오리진에 파일을 업로드(extra-page.html파일 업로드)
(ㅂ) 업로드한 객체 URL을 클릭하면 'This extra page has been successfully loaded!' 메세지가 보인다. - 이제 오리진 버킷에 가서 extra-page.html파일을 삭제한다.
그리고 index.html파일이 다른 오리진에 있는 추가 페이지를 가리키도록 변경해야 한다.
(ㄱ) 두 번쨰 오리진으로 들어가서 속성 탭으로들어가 퍼블릭 URL을 누른다.
(ㄴ) 에러페이지가 뜬다면 뒤에 /extra-page.html을 입력하자. 그럼 웹페이지가 나온다.
(ㄷ) 그 웹페이지 URL을 사용해 index.html 파일을 변경한다.
@index.html
<html>
<head>
<title>My First Webpage</title>
</head>
<body>
<h1>I love coffee</h1>
<p>Hello world!</p>
<body>
<img src="coffee.jpg" width=500/>
<!-- CORS demo -->
<div id="tofetch"/>
<script>
var tofetch = document.getElementById("tofetch");
fetch('http://demo-....amazonaws.com/extra-page.html')
.then((response) => {
return response.text();
})
.then((html) => {
tofetch.innerHTML = html
});
</script>
</html>=> fetch에 기존 extra-page.html대신 다른 버킷에 있는 extra-page.html의 전체 경로를 가져온다.
이렇게 하면 교차 오리진 리소스 공유 요청이 트리거된다.
- 다시 메인 버킷에 index.html파일을 다시 업로드하자.(덮어쓰기 된다.)
다시 메인 버킷의 index.html URL로 접속하면 이미지 아래에 오류 메시지가 없어져있다.
그러나 도구 더보기 - 웹 개발자 도구를 열면 에러 메시지가 표시된다.(콘솔 로그 디버거 탭)
내용으로는 '정책에서 허용하지 않아 교차 오리진 요청이 차단되었고, CORS 헤더인 액세스 제어 허용 오리진이 누락되었음'이라는 에러가 표시된다.
=> 즉, 요청은 다른 버킷으로 가지만 다른 버킷에는 CORS가 설정되어 있지않다. - 다른 오리진에 CORS 설정을 해보자
다른 오리진으로 들어가 권한 탭으로 가 아래로 내리면 CORS 설정 옵션이 있다.
-> JSON 형식으로 정의해야 한다.
편집을 누르고 맞는 CORS 설정을 추가한다.
@CORS_CONFIG.json
[
{
"AllowedHeaders": [
"Authorization"
],
"AllowedMethods": [
"GET"
],
"AllowedOrigins": [
"<메인 오리진의 index.html 전체URL을 여기에 넣는다.>" // 끝에 슬래시가 있다면 지워준다.
],
"ExposeHeaders": [],
"MaxAgeSeconds": 3000
}
]위 코드를 넣고 저장한다.
=> 이제 다른 오리진이 첫 번째 오리진의 요청을 허용하도록 설정했다.
다시 페이지를 새로고침하면 'This extra page has been successfully loaded!' 메세지가 보인다.
S3 MFA Delete
- S3 MFA Delete 보안 기능
- MFA(Multi-Factor Authentication)
사용자가 장치에서 코드를 생성하도록 강제
(예시)
google Authenticator 애플리케이션이 설치된 휴대폰
MFA 하드웨어 장치 - MFA는 코드를 생성하는데 중요한 작업을 수행하기 전에 S3에 해당 코드를 삽입해야한다.
- MFA(Multi-Factor Authentication)
- MFA는 언제 필요할까?
- 객체 버전을 영구적으로 삭제할 때 필요하다.
영구 삭제에 대한 보호 설정. - 버킷에서 버저닝을 중단할 때
- 객체 버전을 영구적으로 삭제할 때 필요하다.
- MFA가 필요하지 않을 때
버저닝을 활성화
삭제된 버전을 나열하는 작업
위 작업은 위험한 작업이 아니기 때문에 MFA가 굳이 필요없다. - MFA Delete를 사용하려면 버킷에서 버저닝을 활성화 해야한다.
- 버킷 소유자(루트 계정)만이 MFA Delete를 활성화하거나 비활성화할 수 있다.
- 즉, MFA Delete는 추가 보호 기능이다.
특정 객체 버전의 영구 삭제를 방지하는 역할
MFA Delete 실습
MFA Delete는 콘솔로 활성화 할 수 없어 CLI로 설정해야한다.
S3 버킷에 MFA삭제를 활성화할 때 제외하고는 루트 계정의 AWS CLI로 구성하는 것은 권장하지 않는다.
(전제 조건)
IAM 루트 계정에 대한 MFA장치가 설정 되어있어야한다.
* 루트 계정 -> 내 보안 자격증명 -> MFA 설정
MFA에 대해 가상 장치를 설정하고 '새로운 액세스키 생성'을 누르고 키 파일을 다운로드한다.
@AWS CLI
// 프로필 생성
~ > aws configure --profile root-mfa-delete-demo
AWS Access Key ID [None]: [Access Key ID]
AWS Secret Access Key [None]: [Secret Access Key]
Default rehion name [None]: [내 리전]
Default output format [None]: [enter]
~ > aws s3 ls -profile root-mfa-delete-demo
-> 버킷 확인
// MFA 삭제 활성화
aws s3api put-bucket-versioning --bucket [버킷 이름] --versioning-configuration Status=Enabled,MFADelete=Enabled --mfa"[MFA 가상장치 ARN] [MFA 코드]" --profile root-mfa-delete-demo위 설정 후 버킷 버저닝으로 이동해 새로고침하면 버킷 버저닝과 MFA Delete가 활성화 되어 있다.
이제 버킷에서 업로드한 객체를 지우면
버저닝이 활성화 되어있기 때문에 삭제마커가 추가되고, 버킷 버전 목록으로 들어가 버전 ID을 삭제(영구 삭제)하려고 하면 MFA 삭제가 활성화되어 CLI로만 삭제할 수 있다.
// MFA 삭제 비활성화
aws s3api put-bucket-versioning --bucket [버킷 이름] --versioning-configuration Status=Enabled,MFADelete=Disabled --mfa"[MFA 가상장치 ARN] [MFA 코드]" --profile root-mfa-delete-demoMFA 삭제 비활성화 했기 때문에 이제 콘솔로 영구 삭제 가능
이후 MFA로 가서 아까 생성한 액세스키는 꼭 삭제 권장.
S3 액세스 로그
- 감사 목적으로 S3 버킷에 대한 모든 액세스를 기록할 수 있다.
- 어떤 계정에서든 S3로 보낸 모든 요청은 승인 도는 거부 여부와 상관없이 다른 s3 버킷에 파일로 기록된다.
- 해당 데이터는 Amazon Athena같은 데이터 분석 도구로 분석 가능
- 대상 로깅 버킷은 같은 AWS 리전에 있어야 한다.
- 작동 방법
(ㄱ) S3 버킷에 요청할 경우 액세스 로그를 활성화 해서
(ㄴ) 모든 요청이 로깅 버킷에 기록되도록 설정 - 특정 로그 형식
https://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html
위 에서 확인
액세스 로그 주의사항
(ㄱ) 로깅 버킷을 모니터링하는 버킷과 동일하게 설정하지 말아야 한다.
-> 동일하게 설정 시 로깅 루프가 생성되어 버킷 크기가 매우 커짐.
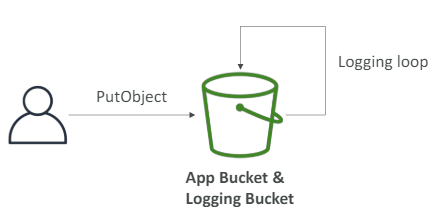
액세스 로깅 실습
로깅 버킷으로 사용할 버킷 생성 -> 다른 버킷을 열어 로깅 활성화(속성 탭 -> 서버 액세서 로깅 편집 -> 활성화, 타겟 버킷을 처음 생성한 버킷으로 설정)
이제 모든 활동이 로깅 버킷에 로깅될 것이다.
S3 - Pre-Signed URL(미리 서명된 URL)
- S3 콘솔, CLI, SDK를 사용해 생성할 수 있는 URL
- URL 만료 기한
S3 콘솔: 최대 12시간
CLI: 168시간 - 미리 서명된 URL을 생성할 때
URL을 받는 사용자는 URL을 생성한 사용자의 GET/PUT에 대한 권한을 상속한다. - 사용 사례
프라이빗 버킷이 있다.
AWS 외부의 사용자에게 한 파일에 대한 액세스 권한을 부여해야 할 때 퍼블릭 파일로 설정하면 안된다.
이때 버킷 소유자또는 사용자로서 해당 파일을 가지고 미리 서명된 URL을 생성하는 것.
그러면 버킷이 URL을 제공하고 해당 URL은 미리 서명된다.
URL이 자격 증명을 이어받아 해당 파일에 액세스할 수 있는 권한을 부여한다.
그 다음 이 URL을 제한된 시간 내에 사용자에게 파일을 보내면 사용자는 URL을 사용해 버킷의 파일에 접근할 수 있게 된다.
만료 기간 이후에는 버킷에서 파일을 다시 가져온다.
사용자는 그동안 파일을 다운로드할 수 있다. - 정리
미리 서명된 URL은 다운로드 또는 업로드를 위해 특정 파일에 임시로 액세스할 때 사용되는 방법 - 예시
(ㄱ) 로그인한 사용자만 S3 버킷에서 프리미엄 비디오를 다운로드할 수 있도록 허용
(ㄴ) 사용자 목록이 계속 변하는 경우 URL을 동적으로 생성해 파일을 다운로드할 수 있게 함.
(ㄷ) 일시적으로 사용자가 버킷을 비공개로 유지한 채 특정한 위치에 파일을 업로드하도록 허용
미리 서명된 URL 실습
프라이빗 버킷에 있는 파일을 가지고 실습을 할거다.
공용이 아니기때문에 공용 URL로 접속하면 거부된다.
그러나 소유자 상단에 있는 open을 누르면 허용된다. -> presigned URL이기 때문
그렇다면 모두를 위한 presigned URL은 어떻게 생성할까?
- CLI 이용하기
- S3 콘솔에서 생성하기
프라이빗 버킷 -> 파일 -> 객체 작업 -> presigned URL로 공유 클릭 -> 허용할 분/시간 설정
이제 생성된 URL을 공유하면 프라이빗 파일이더라도 접근할 권한을 가지게 된다.
S3 Glacier Vault Lock
- WORM(Write Once Read Many)모델을 채용하기 위해 Glacier 볼트를 잠근다.
객체를 가져와 S3 Glacier 볼트에 넣고 수정하거나 삭제할 수 없도록 잠그는 것. - Glacier 위에 볼트 잠금 정책을 생성
- 향후 편집을 위해 정책을 잠근다.
볼트 잠금 정책을 설정하고 잠근 후에는 누구도 변경하거나 삭제할 수 없게 된다. - 규정 준수와 데이터 보존에 아주 유용하다
객체가 Glacier 볼트에 삽입되면 볼트에 볼트 잠금 정책이 적용되어 있으므로 객체를 삭제할 수 없다.
-> 관리자, AWS 서비스를 사용해도 삭제 불가
S3 객체 잠금(버저닝 기능 활성화)
- WORM 모델 채택
- 객체 잠금은 전체 버킷의 잠금 정책이 아닌 객체 각각 적용할 수 있는 잠금이다.
- 객체 잠금을 통해 특정 객체 버전이 특정 시간동안 삭제되는 것을 방지한다.
- 보존 모드
- 규정 준수 모드
S3 Glacier 볼트 잠금과 유사하다.
(ㄱ) 사용자를 포함한 그 누구도 객체 버전을 수정하거나 삭제할 수 없다.
(ㄴ) 보존 모드 자체도 변경할 수 없다.
보존 기간도 단축할 수 없다. - 거버넌스 보존 모드
좀 더 유연한 보존 모드
(ㄱ) 대부분의 사용자는 객체 버전을 덮어쓰기/삭제/로그 설정을 변경할 수 없다.
(ㄴ) 관리자 같은 이부 사용자는 IAM을 통한 권한으로 보존 기간을 변경하거나 객체를 바로 삭제할 수 있다.
- 규정 준수 모드
- 보존 모드 모두 보존 기간을 설정해 줘야 한다.
원하는 만큼 기간 연장 가능. - 객체에 법적 보존 상태 설정하기
(ㄱ)법적 보존을 설정하면 버킷 내 모든 객체를 무기한으로 보호한다.
(ㄴ) 보존 기간과 무관하기 때문에 아주 중요한 객체에 법적 보존을 설정한다.
ex) 재판에서 사용할 중요한 객체 - 하지만 s3:PutObjectLegalHold IAM 권한을 가진 사용자는 어떤 객체에든 법적 보존을 설정하거나 제거할 수 있다.
S3 액세스 포인트
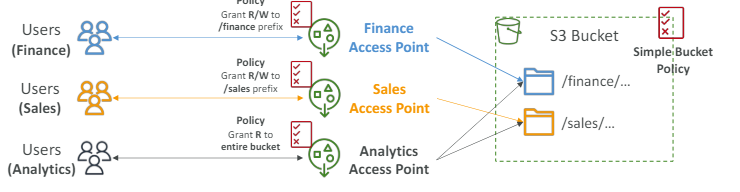
많은 데이터가 담긴 버킷이 있다.
다양한 사용자나 그룹들이 데이터에 액세스 하려고 한다.
복잡한 S3 버킷 정책을 생성하고 시간이 지남에 따라 커지도록 할 수 있다.
사용자와 데이터가 많아질수록 관리하기 어려워 진다.
- 어떻게 해결 할까?
액세스 포인트를 만들면된다.
(ㄱ) 재무 액세스 포인트를 만들고 이는 재무 데이터와 연결될 것이다.
재무 데이터에 연결하기 위해 서 액세스 포인트에 정책을 정의하고 /finance 접두어에 읽기와 쓰기 액세스 권한을 부여한다
(ㄴ) 영업 액세스 포인트를 만들고 영업 데이터와 연결된다.
영업 액세스 포인트에 /sales접두어에 읽기와 쓰기 액세스 권한을 부여
(ㄷ) 분석 액세스 포인트도 만들고 재무와 영업 데이터를 지시하도록 하고 읽기만 가능하게 권한을 부여할 수 있다.
이 처럼 보안 관리를 S3 버킷 정책에서 꺼내 액세스 포인트에 넣을 수 있다.
액세스 포인트는 각각의 보안 정책을 가지고 있다.
사용자는 IAM권한을 통해 각자의 액세스 포인트에 접근할 수 있게 된다. - 정리
(ㄱ)버킷에 대한 액세스를 스케일링하기 편리해 진다.
(ㄴ) 액세스 포인트는 S3 버킷의 보안 관리를 간소화
(ㄷ) 각각의 액세스 포인트는 각자의 DNS 이름을 갖게 된다.
그걸로 액세스 포인트에 접속한다.
+ 액세스 포인트가 인터넷 오리진에 연결되거나 프라이빗 트래픽의 경우 VPC 오리진에 연결되도록 할 수 있다.
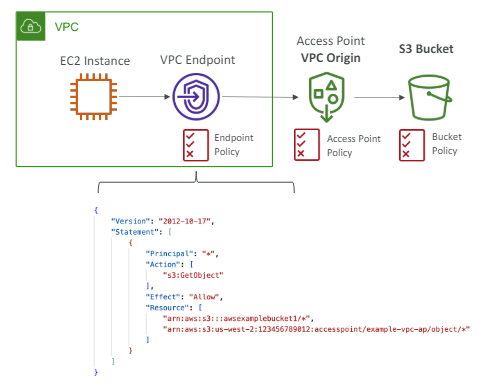
액세스 포인트 - VPC 오리진
VPC 오리진을 프라이빗 액세스 가능하도록 정의할 수 있다.
- 예시(나중에 다시보기)
VPC의 EC2 인스턴스는 인터넷을 통하지 않고 VPC 액세스 포인트와 VPC 오리진을 통해 S3 버킷에 액세스할 수 있다.
그럼 이 VPC 오리진에 액세스하기 위해 액세스 포인트에 접근하기 위한 VPC 엔드포인트를 만들어야 한다.
그것은 VPC 안에 있고 VPC 오리진을 통해 액세스 포인트에 사적으로 접속할 수 있게 해준다.
그리고 이 VPC 엔드포인트에는 정책이 있고, 글 정책은 타깃 버킷과 액세스 포인트에 대한 접근을 허용해줘야 한다.
그럼 VPC 엔드포인트 정책은 우리의 EC2 인스턴스가 S3의 액세스 포인트와 S3 버킷 모두 접속하게 허용해 줄 것이다.
이 경우엔 VPC 엔드포인트 보안이 있고, 액세스 포인트 정책에도 보안이 있고, S3 버킷 수준에도 보안이 있다.
액세스 포인트 - 객체 람다
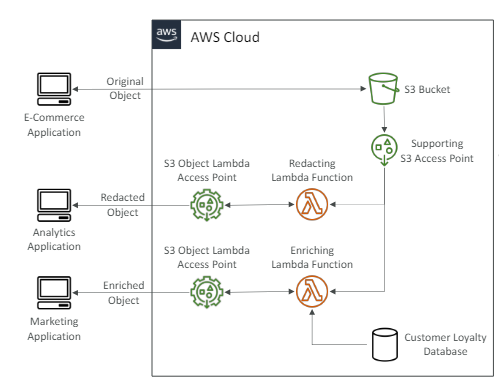
- 버킷이 있는데 호출자 애플리케이션이 객체를 받기 직전에 그 객체를 수정하려는 경우 사용
- 예시
버킷을 복제해서 버킷에 각 객체의 다른 버전을 갖는 대신에 S3 객체 람다를 사용- 분석기 애플리케이션
삭제된 객체에 액세스
(ㄱ) 분석기 애플리케이션은 S3 객체 람다 액세스 포인트에 액세스하고, 람다 함수를 호출한다.
(ㄴ) 람다 함수는 S3 버킷에서 데이터를 받고, 어떤 코드를 실행해 데이터를 삭제한다.
(ㄷ) 그래서 분석기 애플리케이션은 전자상거래 애플리케이션과 동일한 S3 버킷으로부터 데이터가 삭제된 객체를 받게 되는 것이다.
- 분석기 애플리케이션
- 마케팅 애플리케이션
데이터가 보강된 객체에 액세스
데이터를 보강하는 고객 충성도 DB를 갖고 있다.
(ㄱ) 새 버킷을 생성하는 대신 람다 함수 사용
(ㄴ) 도 다른 코드가 있을 것이고, 이 코드는 고객 충성도 DB에서 데이터를 검색해 데이터를 보강할 것이다.
(ㄷ) 그러면 별도의 객체 람다 액세스 포인트를 만들 수 있다.
(ㄹ) 그러면 마케팅 애플리케이션은 S3 객체 람다 액세스 포인트에 접근해 보강된 객체를 받을 수 있다.
이 처럼 하나의 버킷으로 액세스 포인트와 객체 람다로 원하는 대로 데이터를 수정할 수 있다. - 활용 사례
(ㄱ) 분석기나 비프로덕션 환경을 위해 PII데이터(개인식별정보)를 삭제하는 경우
(ㄴ) 데이터 형식을 XML에서 JSON으로 변환하는 경우
(ㄷ) 즉석에서 이미지 크기를 조정
(ㄹ) 워터마크를 추가 -> 객체를 요청하는 사용자에게만 적용
등등
원하는 변환을 수행하는 경우.
