
이벤트 처리
# 1. Lambda, SNS & SQS
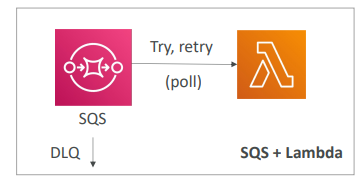
- SQS와 람다 함수를 사용해 이벤트가 SQS 대기열에 삽입되고 람다가 SQS 대기열을 풀링
- 문제가 발생하면 해당 메시지를 다시 SQS 대기열에 입력하고 폴링을 재시도
- 이 작업을 무한히 반복되다가 한 메시지에 중대한 문제가 발생시
5번의 재시도 후에 데드 레터 대기열(DLQ)로 보내도록 SQS 설정을 한다.
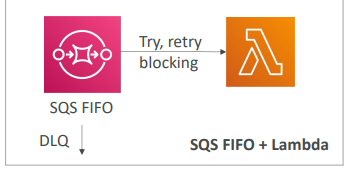
- SQS FIFO와 Lambda를 사용
- FIFO로 선입선출해 Lambda 함수가 대기열 메시지를 순서대로 처리를 시도
- 순서대로 처리하기 때문에 한 메시지를 처리하지 못 하면 차단이 발생해 처리가 끝나지 않고 전체 대기열 처리가 차단된다.
- 이 경우에도 마찬가지로 데드 레터 대기열(DLQ)을 구성해 SQS 대기열에서 해당 메시지를 빼내고 함수가 계속 동작하도록 할 수 있다.
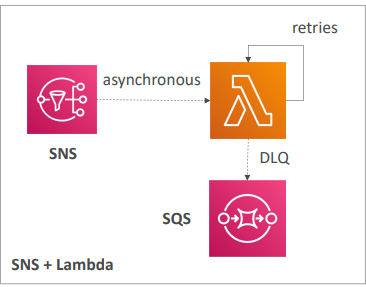
- SNS와 람다를 사용
- 메시지가 통과하고 메시지는 비동기식으로 Lambda에 전송된다.
- 이때 람다는 재시도 행동을 달리해 처리하지 못하는 메시지가 발생하더라도 내부적으로만 재시도한다.
- 재시도는 총 3번까지 하고 처리되지 않으면 해당 메시지를 제거하거나 DLQ로 보내도록 구성할 수 있다.
- 그러나 여기서는 람다 서비스 수준에서 해당 메시지를 SQS 대기열로 보내 나중에 다시 처리하게할 수도 있다.
# 2. 팬 아웃 패턴
- 팬아웃 패턴은 다중 SQS 대기열에 데이터를 전송하는 방식
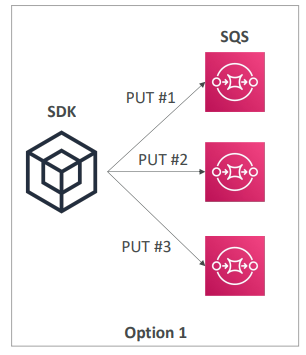
- 이 패턴에서는 애플리케이션과 AWS SDK가 설치되어 있고 3개의 SQS 대기열에 메시지를 전송하고자 한다.
- 이 경우 애플리케이션을 구성할 때 먼저 메시지를 첫 번째 대기열에 보내고, 동일한 메시지를 2번째, 3번째 대기열에도 보낸다.
- 이 방식은 작동은 하지만 안정성이 높지는 않다.
만약 두 번째 대기열에 메시지를 전송한 다음 애플리케이션이 오류로 종료되면 세 번째 대기열은 메시지를 전달받지 못하기 때문에 각 대기열의 콘텐츠가 달라질 수 있다.
- 이를 보완하기 위해 팬아웃 패턴을 사용
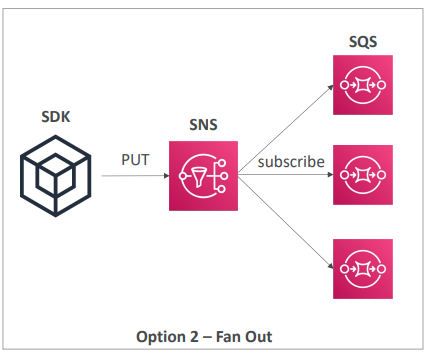
- SQS 대기열과 애플리케이션 사이에 SNS 주제를 둔다
- 이러면 SQS 대기열은 SNS 주제의 구독자가 되고, SNS 주제에 메시지를 전송할 때마다 메시지가 모든 SQS 대기열에 전달되므로 안정성이 높아진다.
- 애플리케이션의 입장에선 SNS 주제에 PUT 요청을 전송하면 자동으로 SNS 서비스가 해당 메시지를 SQS 대기열에 팬아웃한다.
- AWS에서 자주 보이는 설계 패턴이니 잘 알아두자.
# 3. S3 이벤트 알림
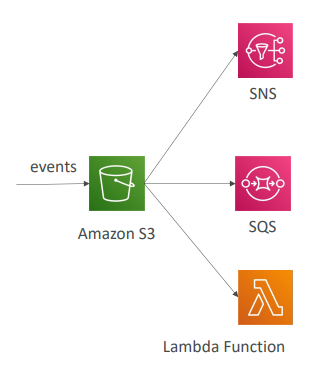
- S3 버킷이 특정 이벤트에만 반응하도록 설정해 객체 생성/삭제/복원/복제본 생성 시 알림을 보내도록 할 수 있다.
- 그리고 객체 이름별로 필터링도 가능하다.
- 사용사례
S3에 업로드된 이미지의 섬네일을 생성하는 경우
- S3 이벤트를 SNS,SQS또는 Lambda로 보내는데 이때 S3 이벤트는 원하는 만큼 생성할 수 있다.
- 이벤트 알림은 보통 수초 내로 전송되고 가끔 몇 분 이상 소요됨.
# 4. EventBridge를 사용해 S3 이벤트 알림 보내기
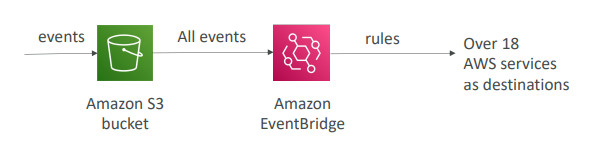
- S3 버킷에서 일어난 모든 이벤트를 EventBridge로 전송하는 방식
- 규칙을 설정해 18개 이상의 AWs 서비스로 전달할 수 있다.
- EventBridge를 사용하는 이유
1. JSON 규칙에 고급 필터링 옵션을 사용해 메타데이터, 객체 크기, 이름 등으로 필터링할 수 있기 때문이다.
2. 여러 대상에 이벤트를 한 번에 보낼 수 있다.
예를들어 Kinesis Data Stream/Firehose .. 등등.
3. EventBridge 기능 중 아카이빙, 이벤트 재생, 안전한 이벤트 전송 등을 사용할 수 있다.
- EventBridge 에서 API 호출 차단
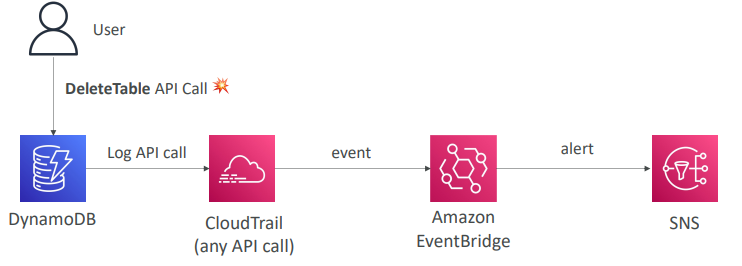
- EventBridge 에서 모든 API 호출 차단 하려면 CloudTrail을 통합해 사용하면 된다.
- 사용자가 DynamoDB의 테이블을 삭제하고자 DeleteTable API를 호출하는 이벤트가 발생한다면 이 API 호출은 CludTrail에 로그되고 그 외 모든 호출이 CloudTrail에 로그된다.
- 이 로그는 EventBridge의 이벤트를 트리거하므로 이를 이용해 경보를 생성해 SNS에 전송할 수 있다.
# 5. API Gateway를 이용하는 AWS의 외부 이벤트

- API Gateway에 클라이언트가 요청을 보내면 API Gateway가 Kinesis Data Stream에 메시지를 전송한다.
- 해당 레코드는 Kinesis Data Firehose로 이동하고 최종적으로 S3에 저장된다.
- 이후 AWS에서 이벤트를 통합하는 방법을 사용해 자동화를 구축한다.
캐싱 전략
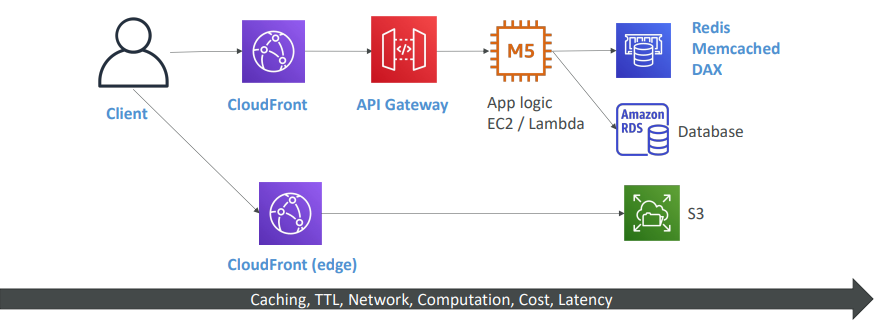
- API Gateway 앞에 CloudFront가 있다.
- 애플리케이션 로직에는 EC2나 Lambda가 될 수 있다.
- 애플리케이션은 DB에서 데이터를 저장하고 쓰고, Redis, Memcached, DAX등의 내부 캐시를 사용할 수도 있다.
- 그럼 바로 동적 콘텐츠와 동적 라우팅이 실행된다.
- 정적 콘텐츠 라우팅도 가능하다.
- CloudFront로 가는 클라이언트나 CloudFront가 S3에서 데이터를 소싱하는 경우이다.
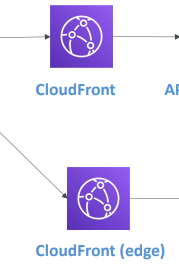
- CloudFront가 두 개가 있다.
- 이는 엣지에서 캐싱을 한다.
즉, 사용자와 최대한 가까이에서 캐싱한다는 뜻이다.
- CloudFront에서 캐싱을 허용하면 캐시를 히트하는 모든 사용자들이 즉시 응답을 빠르게 얻게 된다.
- 하지만 엣지에 있기 때문에 백엔드에서 변화가 일어났을 수 있고 오래된 데이터일 수 있다.
- 그래서 TTL을 사용해 최신화를 한다.
- 그리고 엣지에 캐시를 얼마나 더 할 것인가와 앱 논리에 얼마나 할지 균형을 재게 된다.
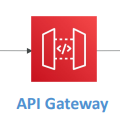
- API Gateway도 캐싱이 가능해 CloudFront와 함께 사용할 필요가 없다.
- API Gateway는 리전 서비스이기 때문에 API Gateway에서 캐시를 사용할 경우 캐시도 리전에 묶이게 된다.
- 클라이언트와 API Gateway 사이에 네트워크 라인이 형성되어 캐시가 여기서 히트된다.
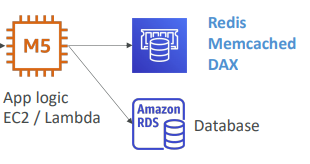
- 앱 로직은 보통 캐싱을 하지 않는데, DynamoDB가 있을 경우 Redis, Memcached, DAX등을 사용해 캐시를 한다.
- DB를 반복적으로 히트하길 원치 않을 때 사용.
- DB는 캐싱하지 못함.
- 자주 발생하는 쿼리나 복잡한 쿼리가 공유 캐시에 결과가 저장되어 앱 논리에 의해 쉽게 액세스할 수 있게 한다.
- 그리고 DB에서는 캐싱을 통해 비용을 절약한다.
DB의 압력을 줄이고 읽기 용량은 늘린다.

- S3의 DB에는 캐싱 기능이 없다........
- 캐싱의 경로를 따라 뒤로 갈수록 비용과 지연 시간이 늘어난다.
- 어떤 작업을 하느냐, 작업을 위해 애플리케이션을 어떻게 설정하느냐에 따라 아키텍처를 구성.
IP 주소 차단
# 1. 간단한 아키텍처
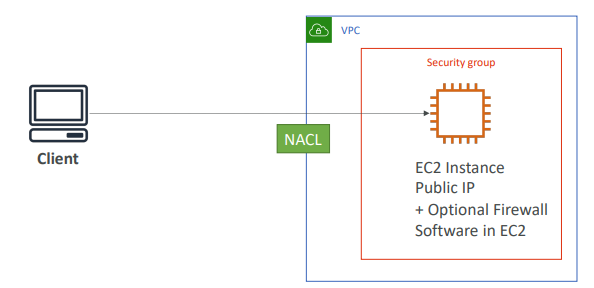
- 첫 번째 방어선: VPC 수준에서 설정된 NACL
이 NACL에서 클라이언트 IP 주소에 대한 거부 규칙을 설정
- 두 번째 방어선: EC2 인스턴스의 보안 그룹에서 거부 규칙 설정
승인된 클라이언트의 하위 집합만이 EC2에 액세스할 수 있다면 보안 그룹에서 EC2로 접근을 허용할 IP 주소의 하위 집합만 정의하는 것이 좋다.
- 그러나 애플리케이션이 글로벌인 경우 애플리케이션에 액세스할 모든 IP 주소를 알 수 없다.
-> 이 경우 EC2의 보안 그룹은 큰 도움이 되지 않을 것이다.
- 세 번째 방어선: EC2 내에서 선택적으로 방화벽 소프트웨어 실행
S/W 내에서 클라이언트의 요청을 차단할 수 있다.
- 요청이 이미 EC2에 도달한 경우 해당 요청은 처리되어야 하고 이로 인해 CPU 비용이 발생할 것이다.
# 2. ALB가 있는 아키텍처
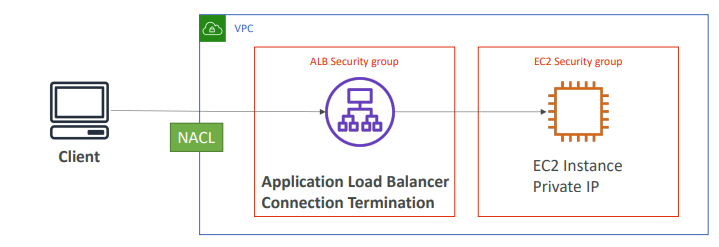
- ALB는 VPC 내에 정의된다.
- 위 그림에서 두 개의 SG가 있다.(ALB, EC2 보안그룹)
- 이 경우 로드 밸런서가 클라이언트와 ec2 사이에 있고 이를 통해 연결/종료를 수행
즉, 클라이언트는 ALB에 연결되고 종료된다.
그리고 ALB에서 EC2로 새로운 연결이 시작된다.
- (ec2) 이 경우 EC2 SG는 ALB의 SG을 허용하도록 구성해야 한다.
EC2가 사설 서브넷에 배포되어 사설 IP를 가지면 인스턴스가 보는 트래픽이 소스는 클라이언트가 아니라 ALB이기 때문
- 따라서 SG 관점에서는 ALB의 보안그룹만 허용해 안전을 확보한다.
- (alb) ALB의 보안그룹은 클라이언트를 허용해야 한다.
즉, IP 범위를 알고 있다면 보안 그룹을 구성할 수 있다.
그러나 글로벌 애플리케이션이라면 모두 허용해야 한다.
- 그리고 방어선은 NACL 수준이 될 것이다.
# 3. NLB가 있는 아키텍처
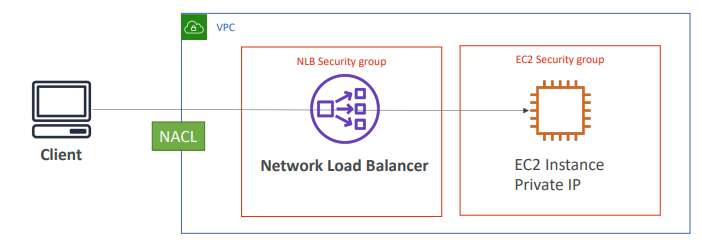
- NLB도 비슷하게 보안그룹이 2개 있다.(NLB, EC2)
- NLB에서 EC2 보안 그룹으로의 트래픽과 클라이언트에서 NLB 보안 그룹으로의 트래픽이 허용되도록 규칙을 설정하고 그 과정에서 트래픽을 제어하도록 한다.
# 4. ALB + WAF로 트래픽 필터링
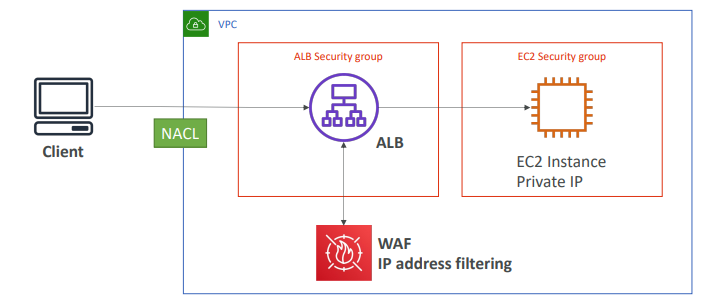
- IP를 거부하기 위해 WAF, 웹 애플리케이션 방화벽을 설치한다.
- WAF는 부가 서비스+방화벽 서비스이기 떄문에 좀 더 비싸다.
그럼에도 IP주소에 대한 복잡한 필터링을 수행하고 클라이언트로부터 동시에 많은 요청이 들어오지 않도록 규칙을 설정할 수 있다.
- WAF는 클라이언트와 ALB 사이에 있는 서비스가 아닌 ALB에 설치하는 서비스이다.
# 5. ALB와 CloudFront WAF 사용
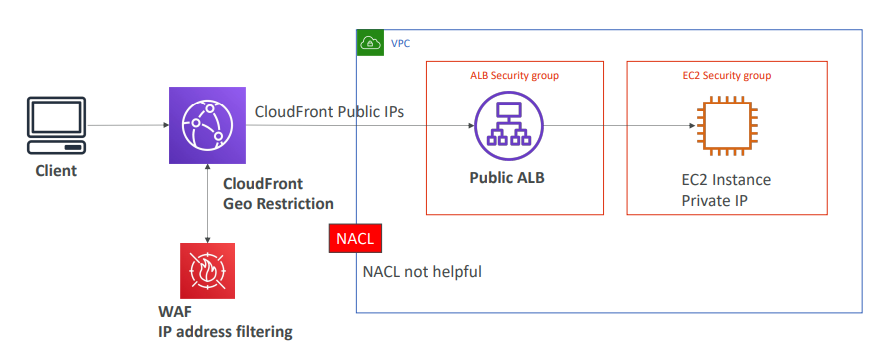
- ALB 앞에 CloudFront를 사용하는 경우 VPC 외부에 외치한다.
- ALB는 엣지 위치에서 오는 CloudFront의 모든 공용 IPS를 허용해야 한다.
따라서 ALB에서는 클라이언트 IP를 볼 수 없다.
표시되는 것은 클라우드 프론트의 공용 IP이다.
- 따라서 VPC 경계에 위치한 NACL은 클라이언트 IP 주소를 차단하는데 도움이 되지않는다.
- 이 경우 CloudFront에서 클라이언트를 차단하려면 두 가지 방법이 있다.
1. CloudFront의 지리적 제한 기능 사용
어떤 나라의 공격을 받으면 CloudFront의 지리적 제한 기능을 사용해 특정 국가에서의 접근을 차단하거나
2. WAF 사용
특정 IP가 문제를 일으키는 경우 WAF를 사용해 IP 주소 필터링을 수행
- IP 주소 필터링을 어디에 설정해야 하는지 정확하게 파악하는것이 중요하다.
고성능 컴퓨팅(HPC)
- 클라우드는 고성능 컴퓨팅을 실행하기에 최적이다.
- 많은 리소스를 즉각적으로 생성할 수 있기 때문
- 리소스를 추가해 결과 추출 시간을 단축할 수 있다.
- 사용량만큼만 비용을 지불하면 된다.
- 즉, 필요에 따라 컴퓨팅을 수행하는 수많은 인스턴스를 가질 수 있고, 작업이 완료되면 사용량만큼만 비용을 지불한다.
- HPC가 필요한 경우
- 유전체학
- 컴퓨터화학
- 금융 위험 모델링
- 기상 예측
- 머신러닝/딥러닝
- 자율 주행
- 등등...
HPC 작업을 돕는 AWS 서비스
# 1. 데이터 관리 방식과 AWS로 데이터를 전송하는 방법
- AWS Direct Connect
- 초당 GB의 속도로 프라이빗 보안 네트워크를 통해 클라우드로 데이터를 전송
- Snowball & Snowmobile
- 물리적 라우팅을 통해 클라우드로 PB 단위 데이터를 옮길 때 사용
- DataSync
- DataSync 에이전트를 설치해 대용량의 데이터를 전송
- 온프레미스, NFS, SMB 시스템에서 S3, EFS, FSx(윈도우용)으로 전송
HPC의 컴퓨팅과 네트워킹
- EC2 인스턴스
- 실행하려는 작업에 따라 CPU나 GPU에 최적화된 인스턴스가 있다.
- Spot 인스턴스나 스팟 플릿을 사용해 비용을 절약하고 계산량을 기반으로 플릿을 오토스케일링
- EC2 배치 그룹
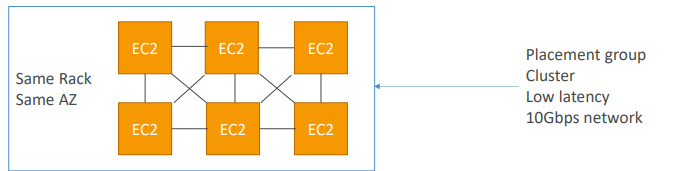
- EC2가 서로 통신해야 하거나 분배된 형태로 동작할 경우
클러스터 유형의 EC2 배치 그룹을 사용하면 최고의 네트워크 성능을 낸다.
- 클러스터 배치 그룹의 경우 랙이 전부이다.
모두 같은 AZ에 위치
EC2 인스턴스 성능 향상 방법
- EC2 Enhanced Networking(SR-IOV)
- 더 넓은 대역폭이 제공되고 더 높은 PPS(Packet per Second), 지연시간이 짧아진다.
- 구성 방법
- 옵션 1: Elastic Network Adapter(ENA) 사용
- 네트워크 속도를 100Gbps까지 올릴 수 있다.
- 대역폭과 초당 패킷을 증가시키고 지연 시간을 줄임. - 옵션 2: Intel의 82599VF 사용
- 최대 10Gbps까지 빨라진다.
- 오래된 ENA
- 옵션 1: Elastic Network Adapter(ENA) 사용
- ENA와 Intel 모두 EC2 Enhanced Networking을 이용할 수 있게 한다.
- Elastic Fabric Adapter(EFA)
- HPC를 위해 개선된 ENA
Linux에서만 사용 가능하다. - 노드 간 소통이나 밀집된 워크 로드 처리에 좋다.
분산 계산같은거 - ENA가 사용하는 게 Message Passing Interface(MPI) 표준인데 이 표준은 Linux를 우회해 안정적이고 지연시간이 더 짧은 송신을 보장한다.
그래서 Linux 인스턴스가 있고 많은 워크로드를 처리해야 할 경우 EFA를 사용해 OS를 우회해 높은 네트워크 성능을 제공할 수 있다.
- HPC를 위해 개선된 ENA
HPC 데이터 저장 - 스토리지
- 인스턴스가 연결된 스토리지 사용
- EBS: io2 Block Express로 256,000IOPS까지 확장 가능.
- 인스턴스 스토어: 수백만의 IOPS로 확장 가능
EC2와 연결되어 하드웨어에 있고, 지연 시간이 짧지만 인스턴스가 망가지면 손상될 위험이 있다.
- 네트워크 스토리지
- S3: 대용량 블롭 데이터를 저장할 때 사용
파일 시스템이 아니라 큰 객체 저장을 위해 사용한다. - EFS: IOPS가 파일 시스템의 전체 크기에 따라 확장된다.
프로비저닝된 IOPS 모드를 사용해 EFS에서 높은 IOPS를 얻기도 한다. - FSx for Lustre: HPC 전용 파일 시스템
Lustre는 Linux와 Cluster용이고, HPC에 최적화되어 수백만의 IOPS를 제공
백엔드에서 S3로 제공된다.
- S3: 대용량 블롭 데이터를 저장할 때 사용
HPC 자동화 및 오케스트레이션
- AWS Batch
- 다중 노드 병렬 작업을 수행
- 여러 EC2에 결쳐 작업
- 작업 예약과 AWS Batch 서비스로 관리되어 EC2 실행이 쉬워진다.
- HPC에서 많이 선택하는 방법이다.
- AWS ParallelCluster
- 오픈 소스 클러스터 관리 도구
- HPC를 AWS에 배포한다.
- 텍스트 파일로 구성해서 AWS로 배포하는 것
- VPC와 서브넷 및 클러스터 타입과 인스턴스 타입 생성을 자동화한다.
- AWS ParallelCluster는 EFA와 함께 사용한다.
클러스터 상에서 EFA를 활성화하는 매개변수가 텍스트 파일에 있기 때문이다.
따라서 네트워크 성능이 향상되고 HPC 클러스터를 구현할 수 있다.
- HPC는 단일 서비스가 아닌 여러 옵션과 서비스의 결합이다.
EC2 고가용성
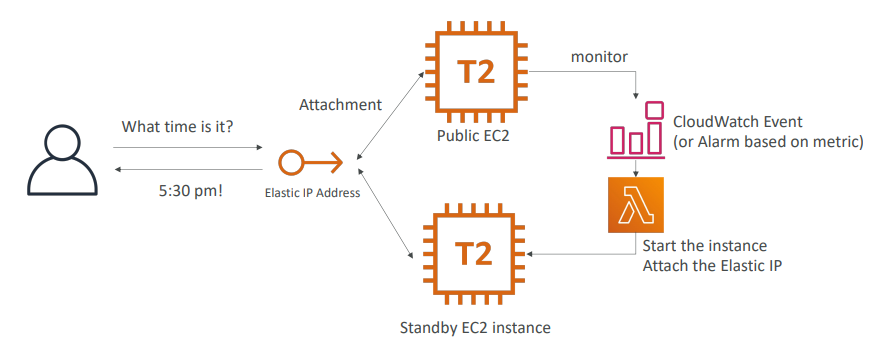
- 공용 EC2가 있고 웹서버에 액세스 한다.
- 그러려면 EC2에 탄력적 IP를 연결하고 사용자가 이 IP를 통해 웹사이트에 액세스한다.
- 그러나 일이 잘못 될 경우르 대비해 대기 인스턴스를 만들어 가용성을 높이고 싶다.
- 무엇이 잘못되었는지 모니터링을 설정한다.
- CloudWatch나 경보를 만든다
경보나 CloudWatch에서 람다를 수행하도록해 원하는 작업을 수행한다.
예를 들어 람다가 API를 호출해 인스턴스를 실행
- 그 후 대기 인스턴스에 탄력적 IP를 연결하는 API를 호출할 수도 있다.
- 탄력적 IP가 연결되면 이 IP는 다른 인스턴스에서는 분리되는데
한 탄력적 IP는 한 인스턴스에만 연결될 수 있다.
즉 다른 EC2는 종료되거나 사라질 것이다.
- 사용자는 탄력적 IP를 통해 아키텍처와 소통하기 떄문에 무슨일이 일어나는지 모른다.
ASG로 고가용성 구성
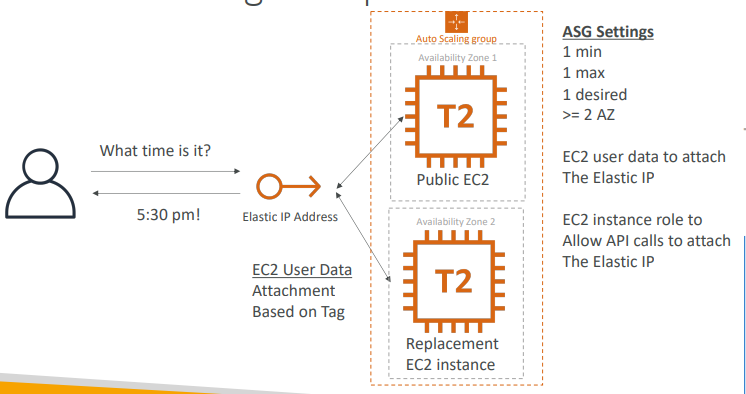
- 두 가용 영역에 ASG가 있다.
- 사용자가 탄력적 IP를 통해 애플리케이션과 소통하게 한다.
- 이제 ASG구성하는데 인스턴스의 최솟값과 최댓값을 1로 설정해 두 가용 영역에 지정한다.
- 그럼 첫 번째 AZ에 인스턴스가 생성되는데
EC2의 사용자 데이터가 나타나게 되면 이 탄력적 IP를 태그에 기반해 연결할 것이다.
- 이 사용자 데이터가 API 호출을 발행하고 탄력적 IP가 공용 EC2에 연결되는 것
- 첫 번째 인스턴스를 종료할 경우 ASG는 다른 AZ에 대체 EC2를 생성한다.
- 이후 첫 번째 인스턴스가 종료되고 두 번째 인스턴스가 EC2 사용자 데이터 스크립트를 실행하고 탄력적 IP를 연결할 것이다.
- 이 경우 CloudWatch 경보나 Events가 필요없다.
- EC2가 탄력적 IP에 연결하기 위해 API 호출하는 역할을 부여해야 한다.
- 사용자 데이터를 이용해 탄력적 IP를 연결하고 API 호출이 성공하도록 EC2역할 설정을 한꺼번에 함
ASG + EBS를 사용한 EC2 고가용성
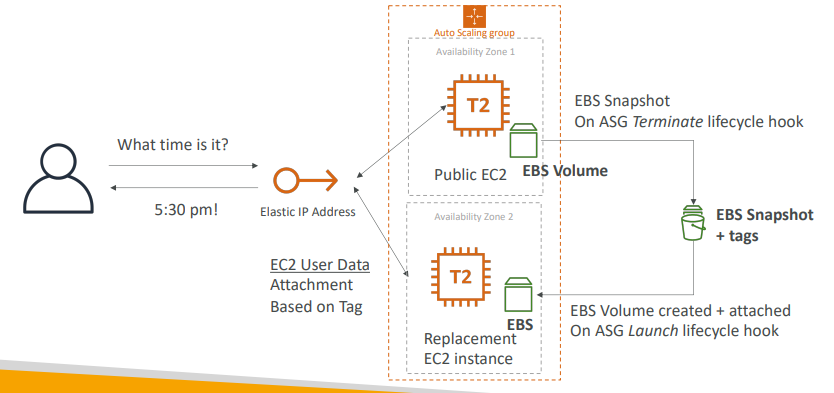
- EC2를 상태 유지하게 하고 EBS 볼륨을 줄 수 있다.
- ASG와 두 AZ 공용 EC2 인스턴스와 탄력적 IP가 있다.
- 여기에 EC2에 EBS 볼륨을 연결할 것이다.
EC2가 DB라 해보자
- 모든 데이터가 EBS 볼륨에 있고 EBS 볼륨은 특정 AZ에만 고정되어 있다.
이제 EC2가 종료된다 가정하면
- 인스턴스가 종료될 경우 ASG는 수명 주기 후크를 사용한다.
이 수명 주기 후크 덕분에 EBS 볼륨에서 스냅샷을 얻을 수 있는 스크립트를 생성할 수 있다.
EC2 인스턴스가 종료되자마자 스냅샷이 발동되기 때문에 EBS 볼룸에 문제가 생겼다는 것을 알 수 있다.
- EBS 스냅샷을 올바르게 태그하면 ASG는 대체 EC2 인스턴스를 실행할 것이다.
- 이제 실행 이벤트에 수명 주기 후크를 생성하도록 ASG를 올바르게 구성함으로써 이 EBS 스냅샷에 기반해 올바른 가용 영역에 EBS 볼륨을 생성할 수 있다.
- 그리고 대체 EC2에 연결하면 EC2 사용자는 이것만 확인하고 탄력적 IP를 직접적으로 연결하면 된다.
- 그러려면 API 호출이 제대로 됐는지 확인하기 위해 EC2 역할이 있어야 한다.
- EBS 볼륨이 스냅샷을 만들고 그 스냅샷에서 다른 AZ로 복구되는지 확인하기 위해 EC2 사용자 데이터 및 수명 주기 후크를 이용한다.
이것이 EBS 볼륨으로 고가용성 EC2 인스턴스를 만드는 방법이다.
