- AWS나 일반적인 재해복구 유형
- 온프레미스 간 DR
데이터 센터를 캘리포니아 시애틀등 여러 군데로 나눔 (비용이 많이든다.) - 클라우드 사용(하이브리드 복구)
온프레미스를 기본 데이터 센터로 두고 재해 발생 시 클라우드를 사용 - 모두 클라우드에 있는 경우(완전 클라우드 유형)
리전 A에서 B로 재해 복구를 수행
- 온프레미스 간 DR
- 재해 복구
- RPO(복구 시점 목표)
- RTP(복구 시간 목표)
RPO & RTO
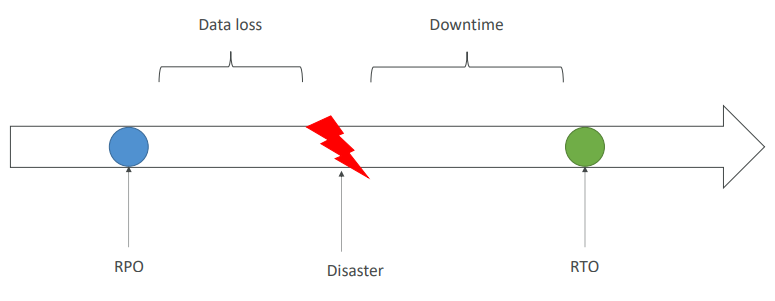
- RPO(복구 시점 목표): 복구를 진행할 때 어떤 시점으로 되돌릴지 결정
- 재해가 발생하면 RPO와 재해 발생 시점 사이의 데이터는 날아간다.
- RPO는 1시간이나 1분 등 원하는 대로 설정할 수 있다.
- RTP(복구 시간 목표): 재해 발생 후 복구할 때 까지의 시간
- 재해 발생 시점과 RTP 시간 차는 애플리케이션 다운타임이다.
- 다운타임을 24시간으로 두기도 하지만 1분으로 설정하는 경우도 있다.
재해 복구 전략
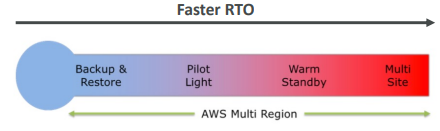
- 백업 및 복구
- 파일럿 라이트
- 웜 대기
- 핫 사이트/다중 사이트 접근
- 백업 및 복구 - 파일럿 라이트 - 웜 대기 - 멀티사이트 순으로 비용이 더 들지만 RTO가 빠르다.
백업 및 복구 전략
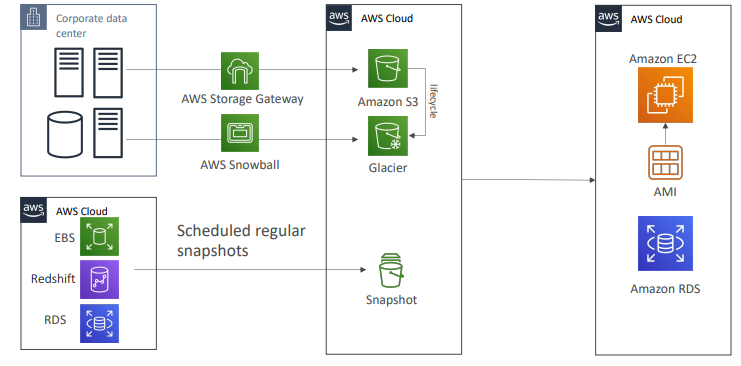
- 백업 및 복구는 RPO,RTO가 크다.
[온프레미스 데이터 센터]
- AWS Cloud 및 S3 버킷이 있다.
- 시간에 따라 데이터를 백업하고 싶다면 AWS Storage Gateway를 사용할 수 있다.
- 수명 주기 정책을 만들어 비용 최적화 목적으로 Glacier에 데이터를 입력하거나
- AWS Snowball을 사용해 일주일에 한 번씩 많은 양의 데이터를 Glacier로 전송할 수도 있다.
Snowball을 사용히 RPO는 대략 일주일이 된다.
[AWS Cloud]
- EBS 볼륨과 Redshift, RDS가 해당된다.
- 정기적으로 스냅샷을 예약하고 백업해 두면 24시간이든 한 시간이든 스냅샷의 간격에 따라 RPO가 달라진다.
- 재해가 발생하면 모든 데이터를 복구해야 하므로 AMI를 사용해 ec2 인스턴스를 다시 만들고 애플리케이션을 스핀 업하거나 스냅샷에서 RDS 데이터베이스, EBS, 볼륨, Reshift등을 바로 복원 및 재생산할 수 있다.
[백업 및 복구 전략]
- 데이터 복구는 시간이 오래 걸리므로 RTO가 커지지만 값이 저렴하다.
- 중간에서 인프라 관리가 필요없어 재해 발생 시 인프라를 재생샌할 수 있어 백업 저장 비용 외에는 비용이 들지 않는다.
파일럿 라이트 전략

- 애플리케이션 축소 버전이 클라우드에서 항상 실행된다.
- 보통 이는 크리티컬 코어이다.
- 백업 및 복구와 비슷하지만 크리티컬 시스템이 항상 작동하고 있어 복구 시 다른 시스템을 더해 주면 되기 때문에 더 빠른 복구가 가능하다.
- 그림에서 데이터 센터의 DB에서 RDS로 데이터를 계속 복제하면 언제든 실행할 수 있는 RDS DB를 확보하게 된다.
- 그러나 EC2는 크리티컬 시스템이 아니기 때문에 작동하지 않고 있다가 재해가 발생할 때
- Route 53이 데이터 센터 서버에 장애 조치를 허용해 클라우드 EC2를 재생산하고 실행하도록 처리
- 이때 RDS는 이미 준비된 상태이기 때문에 빠른 조치가 가능
웜 대기 전략
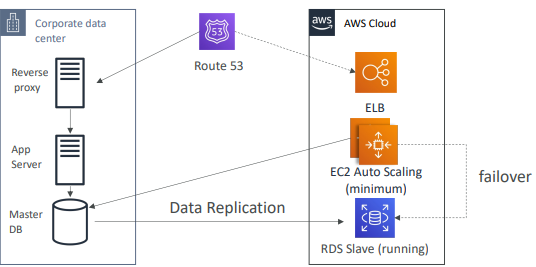
- 시스템 전체를 실행하되 최소한의 규모로 가동해 대기하는 방법
- 재해가 발생하면 프로덕션 로드로 확장할 수 있다.
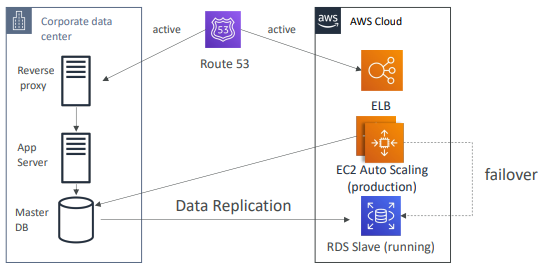
- 그림에서 데이터 센터가 있고, Route 53가 DNS를 기업의 데이터 센터를 가리킨다.
- 클라우드에서는 실행 중인 RDS Slave DB로 데이터 복제가 이뤄지고 있다.
- EC2 ASG가 최소 용량을 가동하고 기업 데이터 센터 DB와 소통한다.
- 재해가 발생하면 웜 대기 전략으로 Route 53을 사용해 ELB로 장애 조치해 애플리케이션이 데이터를 가져오는 곳을 변경
EX: RDS Slave에서 데이터를 취하도록 변경한 뒤 효과적으로 대기했다가 오토 스케일링을 사용하면 애플리케이션이 빠르게 확장한다.
- 파일럿 라이트보다 RPO,RTO는 줄어들지만 비용이 더 든다.
멀티 사이트/핫 사이트 접근 전략
- 매우 비싸지만 RTO가 매우 낮다
- 온프레미스와 AWS에서 완전 프로덕션 스케일을 얻는다.
- 온프레미스 데이터 센터의 완전 프로덕션 스케일과 데이터 복제를 진행하는 동시에 AWS 데이터 센터 완전 프로덕션 스케일이 가능하다.
- 이미 실행 중인 핫 사이트가 있기 때문에 Route 53가 기업 데이터 센터와 AWS에 요청을 라우팅할 수 있는데, 이를 액티브-액티브 유형 설정이라 한다.
- 필요하다면 EC2가 RDS Slave DB에 장애 조치를 할 수 있지만
- AWS와 온프레미스에서 완전 프로덕션 스케일이 실행돼 많은 비용이 발생하지만 동시에 장애 조치 할 준비가 되어 있기 때문에 다중 DB 유형 인프라를 실행할 수 있어 좋다.
모두 클라우드로 실행하는 경우
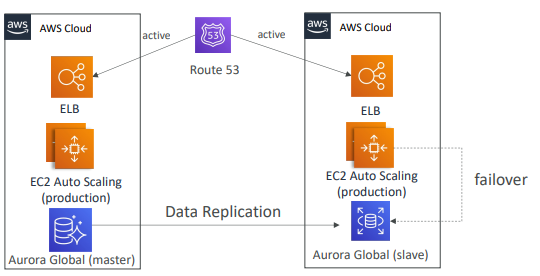
- 다중 리전이고 모두 클라우드 내에 있어 Aurora를 사용할 수 있다.
- 한 리전에 마스터 DB가 있고, 다른 리전에 Slave로 복제된 DB가 있다.
- 두 리전 모두 잘 작동하는데 장애 조치를 할 때 필요에 따라 완전 프로덕션 스케일이 다른 리전에서 가능하다.
재해 복구 팁
- 백업
- EBS 스냅샷과 RDS로 자동화된 스냅샷과 백업을 사용한다.
- S3, S3 IA, Glacier등에 스냅샷을 규칙적으로 푸시할 수 있다.
- 수명 주기 정책 실행 가능
- 다른 리전에 백업을 두고 싶다면 리전 간 복제 가능
- 온프레미스에서 클라우드로 데이터 공유 시 Snowball과 Storage Gateway가 유용하다.
- 고가용성
- Route 53을 사용해 DNS를 다른 리전으로 옮기면 된다.
- 다중 AZ를 실행하는 기술 이용 가능
RDS 다중 AZ, ElastiCache 다중 AZ, EFS, S3등 - 웹사이트를 활성화하면 기본적으로 가용성이 높다.
- 기업 데이터 센터에서 AWS로 연결할 때 Direct Connect를 실행했을 수도 있다.
만약 연결이 끊기면 Site-to-Site VPN을 네트워크 복구 옵션으로 사용할 수 있다.
- 복제
- RDS 리전 간 복제, Aurora, 글로벌 DB로 복제 가능
- 온프레미스 DB를 RDS로 복제할 때 DB 복제 소프트웨어 사용 가능.
- Storage Gateway 사용 가능
- 자동화
- CloudFormation과 Elastic Beanstalk가 클라우드에 새로운 환경을 빠르게 재생산하도록 돕는다.
- CloudWatch를 사용한다면 경보로 EC2를 복구하거나 다시 시작할 수 있다.
- AWS Lambda로 맞춤 자동화 동작을 설정 가능.
REST API에도 좋지만 AWS 인프라 전체를 자동화할 때 효과적이다.
- 카오스 테스트
- 모든 걸 AWS에서 실행하고 Simian Army를 만들어 EC2 인스턴스를 무작위로 종료해 인프라가 재해복구가 잘 실행되는지 확인(넷플릭스)
- 모든 걸 AWS에서 실행하고 Simian Army를 만들어 EC2 인스턴스를 무작위로 종료해 인프라가 재해복구가 잘 실행되는지 확인(넷플릭스)
DMS - Database Migration Service
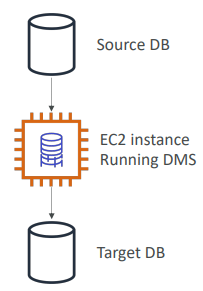
- DB를 온프레미스에서 AWS Cloud로 마이그레이션하는 서비스
- 복원력이 있고 자가 치유가 가능함
- 마이그레이션을 해도 소스 DB를 계속 사용할 수 있음.
- 다양한 엔진 지원
Oracle - Oracle, Postgre - Postgre 동종 마이그레이션
Microsoft SQL Server - Aurora 이종 마이그레이션 지원 - CDC(Change Data Caputre)를 이용한 지속적 데이터 복제 가능.
- DMS를 사용하기 위해 EC2를 만들고 그 EC2가 대신 복제 작업을 수행한다.
DMS Source & Target
- DMS를 이용해 다양한 DB에 넣고,내보내고,마이그레이션할 수 있다.
- Source
- 온프레미스 데이터베이스
- EC2 인스턴스 기반 데이터베이스
Oracle, Microsoft SQL Server, MySQL, MariaDB, PostgreSQL, MongoDB, SAP, DB2 - Azure
- Amazon Aurora, RDS
- Amazon S3
- DocumentDB
- Target
- 온프레미스
- EC2 인스턴스 DB
Oracle, Microsoft SQL Server, MySQL, MariaDB, PostgreSQL, MongoDB, SAP, DB2 - RDS
- Redshift, DynamoDB, S3
- OpenSearch Service
- Kinesis Data Streams
- Apache Kafka
- DocumentDB & Neptune
- Redis & Babelfish
AWS SCT(Schema Conversion Tool)
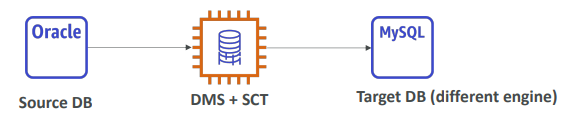
- 소스 DB와 타깃 DB의 엔진이 다른 경우 AWS SCT를 사용한다.
- SCT는 스키마 변환 도구를 의미한다.
DB 스키마를 엔진간 변환한다. - EX
- OLTP를 사용한다면 SQL Server나 Oracle에서 MySQL, PostgreSQL, Aurora로 마이그레이션을 할 수 있다.
- OLAP라면 Teradata나 Oracle에서 Amazon Redshift로 분석을 목적으로 변환할 수도있다. - 동일 엔진간 마이그레이션에는 SCT를 사용할 필요가 없다.
다른 DB 엔진의 경우 DMS+SCT를 사용한다.
DMS의 지속적 복제 설정
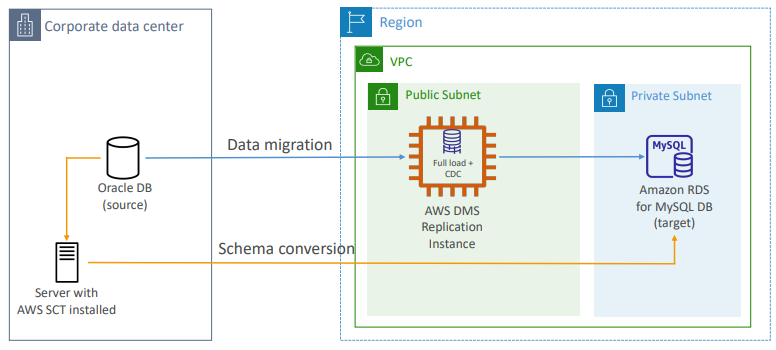
- Oracle DB같은 데이터 센터 소스가 있고
- MySQL DB를 위한 RDS DB를 타깃으로 갖는다.
- AWS SCT를 설치해 서버를 설정하고, 그걸 온프레미스에서 설정할 수 있다.
- 이어서 MySQL을 실행하는 RDS DB로 스키마를 변환한다.
- 이어서 DMS 복제 인스턴스를 설정하고, 지속적 복제를 위해 Full load와 CDC를 한다.
- 그럼 온프레미스에서 소스 Oracle DB를 읽어서 데이터 마이그레이션을 수행하고
- 데이터를 프라이빗 서브넷에 삽입한다.
DMS 멀티 AZ 배포
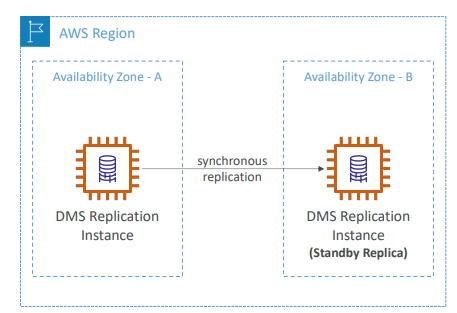
- 한 AZ에 DMS 복제 인스턴스가 있고, 그 인스턴스를 또 다른 AZ에 동기화 복제를 한다.
그게 대기 복제본이 된다. - 하나의 AZ에서 재해 발생시 회복력을 갖게 된다.
- 장점
- 데이터 중복성 제공
- I/O 멈춤 현상 제거
- 지연시간 급증(레이턴시 스파이크)을 최소화
Aurora & RDS 마이그레이션
[MySQL]
- RDS DB를 Aurora MySQL로 옮기려고 할때
- RDS MySQL DB의 스냅샷을 생성해 이 스냅샷을 MySQL Aurora DB에서 복원
이때 다운타임이 발생한다.
- RDS MySQL DB의 스냅샷을 생성해 이 스냅샷을 MySQL Aurora DB에서 복원
- Aurora 읽기 전용 복제본을 RDS MySQL에 생성

복제본의 지연이 0이 되면 Aurora 복제본이 MySQL과 완전 일치한다는 뜻
이때 복제본을 DB 클러스터로 승격시키면 된다.
이 방법은 DB 스냅샷보다는 시간이 많이 걸리고 복제본 생성과 관련한 네트워크 비용이 발생할 수 있다.
- Aurora 읽기 전용 복제본을 RDS MySQL에 생성
- MySQL DB가 RDS 외부에 있는 경우
- Percona XtraBackup 기능을 사용해 백업
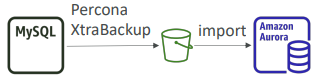
백업 파일을 생성해 S3에 두면 Aurora의 기능을 사용해 새로운 Aurora MySQL DB클러스터로 백업 파일을 가져올 수 있다.
- Percona XtraBackup 기능을 사용해 백업
- MySQLDump기능을 MySQL DB에서 실행해 기존 Aurora DB로 출력값을 내보내기
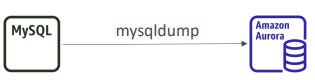
이 경우는 시간이 많이 들고 S3를 사용하지 않는다.
- MySQLDump기능을 MySQL DB에서 실행해 기존 Aurora DB로 출력값을 내보내기
- Amazon DMS를 이용하기
- DMS를 이용해 두 DB가 가동되는 채로 DB간 지속적인 복제를 진행하는 방법
[PostgreSQL]
- RDS DB를 Aurora PostgreSQL로 옮기려고 할때
- 스냅샷을 생성해 Aurora DB에서 복원
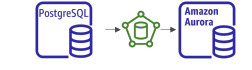
- 스냅샷을 생성해 Aurora DB에서 복원
- 읽기 전용 복제본을 Aurora에 생성해 복제 지연이 0이 될 때까지 기다렸다 DB 클러스터로 승격
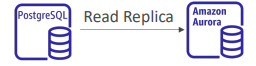
- 읽기 전용 복제본을 Aurora에 생성해 복제 지연이 0이 될 때까지 기다렸다 DB 클러스터로 승격
- 외부 PostgreSQL DB를 Aurora에 마이그레이션 하는 경우
- 백업을 생성 후 해당 백업을 S3에 두고 데이터를 자겨오기 위해 aws_s3 Aurora 확장자를 사용해 새로운 DB를 생성하는 방법
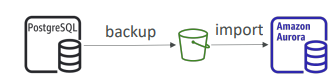
- 백업을 생성 후 해당 백업을 S3에 두고 데이터를 자겨오기 위해 aws_s3 Aurora 확장자를 사용해 새로운 DB를 생성하는 방법
- 또는 DMS를 통해 PostgreSQL에서 Aurora로 지속적 마이그레이션
AWS를 통한 온프레미스 전략(중요)
- Amazon Linux 2 AMI를 가상 머신으로 다운로드 가능하고 이건 ISO 형식이다.
이 ISO 이미지를 흔한 VM을 생성하는 소프트웨어로 로드 한다.
Oracle VM과 Microsoft Hyper-V에 해당하는 VMWare, KVM, Virtual Box를 포함한다.- 이를 통해 직접 VM을 통해 온프레미스 인프라에서 Linux 2를 실행할 수 있게한다.
- VM 가져오기/내보내기
- 기존의 VM과 애플리케이션을 EC2로 마이그레이션 가능
- 재해 복구 리포지토리 전략도 생성가능하다.
- 온프레미스 VM이 많은 경우 이를 클라우드에 백업하고 싶을 때 가져오기/내보내기 기능으로 VM을 EC2에서 온프레미스 환경으로 다시 빼올 수 있다.
- AWS 애플리케이션 Discovery Service
- 온프레미스의 정보를 모아주고 마이그레이션을 계획할 수 있게 해 주는 서비스
- 상위 수준의 서비스지만 서버 사용량 정보와 종속성 매핑에 대한 정보를 제공한다.
- 온프레미스에서 클라우드로 대량의 마이그레이션 할 때 유용하다.
- AWS Migration Hub를 사용해 모든 마이그레이션을 추적할 수도 있다.
- AWS Database Migration Service(DMS)
- 온프레미스에서 AWS로의 복제를 허용하고, AWS에서 AWS로, AWS에서 온프레미스로 복제를 허용한다.
- MySQL이나 PostgreSQL이 온프레미스에 있고, AWS로 워크로드를 옮기고 싶다면 DMS를 사용해서 그동안 DB를 복제하고 준비가 됐을 때 AWS만을 사용해 처리할 수 있다.
- Oracle, MySQL, DynamoDB 등 다양한 DB와 함께 작동해 사용하기 편리하다
- EX: MySQL에서 DynamoDB로 데이터를 마이그레이션하기.
- AWS Server Migration Service(SMS)
- 온프레미스의 라이브 서버들을 AWS로 증분 복제할 때 사용
- AWS로 볼륨을 직접 복제할 수 있다.
- 지속적인 복제 유형에 적용되는 증분 복제이다.
AWS Backup
- AWS 서비스 간의 백업을 중점적으로 관리하고 자동화
- 지원하는 서비스는 계속해서 늘어나는 중
- 실제 중앙 시스템이 없고, 사용자 지정 스크립트나 매뉴얼을 만들 필요 없이 백업 전략으로 사용할 수 있다.
- 지원 서비스
- EC2 / EBS
- S3
- RDS의 모든 DB엔진 / Aurora / DynamoDB
- DocumentDB / Neptune
- EFS / FSx(Lustre & Windows File Server)
- Storage Gateway(볼륨 게이트웨이)
- @
- 리전 간 백업을 지원
한 곳의 재해 복구 전략을 다른 리전에 푸시할 수 있다 - 계정 간 백업 지원
AWS에서 여러 계정을 사용할 경우 사용하면 된다. - PITR(지정 시간 복구) 지원
- 온디맨드와 함께 예약된 백업 지원
- 태그 기반 백업 정책으로 이를 사용해 프로덕션 태그가 지정된 리소스만 배업 하는 등의 활용 가능
- 백업 정책에서 백업 플랜 생성 가능
- 백업 빈도를 정의
cron 표현식을 정해 백업 기간 지정 가능 - 백업 window
- 콜드 스토리지 이전 여부 결정
보내지 않기/며칠/몇 주/ 몇 달/ 몇년 후 보내기 설정 가능 - 백업 보유 기간 정의 가능
계속 보유하기/일/주/월/년 기간 정할 수 있다.
- 백업 빈도를 정의
AWS Backup 과정
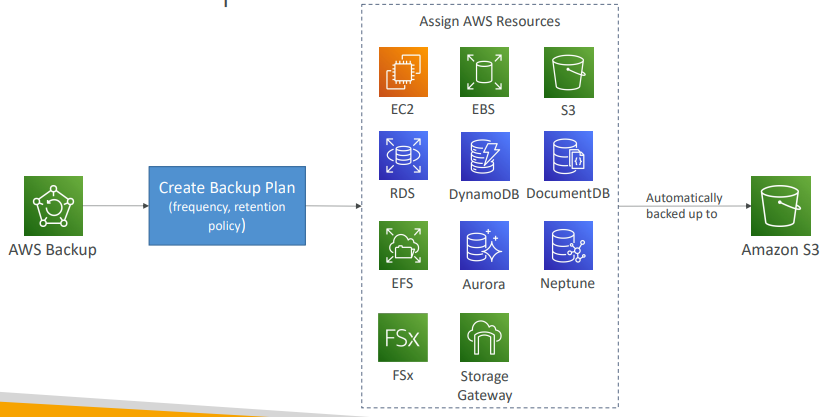
- 백업 플랜을 만들고 나서 중요한 특정 AWS 리소스를 할당한다.
- 할당이 완료되면 데이터가 자동으로 S3에 백업된다.
AWS Backup에 지정된 내부 버킷에 백업된다.
AWS Backup Vault 잠금
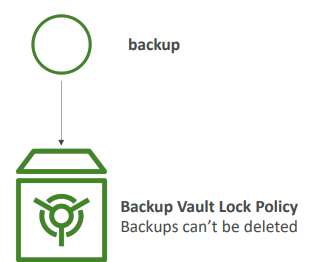
- WORM(Write Once Read Many) 정책을 시행하면 백업 볼트에 저장한 백업을 삭제할 수 없게 된다.
- 볼트 잠금 정책 때문에 백업을 삭제할 수 없고 백업에 대한 추가 방어막을 제공한다.
- 의도치 않거나 악의적인 삭제 작업을 막고
- 백업 유지 기간 축소 또는 변경 작업을 방지한다. - 이 기능은 루트 사용자도 백업을 삭제할 수 없다.
Application Migration Service(MGN)
AWS Application Discovery Service
온프레미스 서버나 데이터 센터를 클라우드로 마이그레이션하려면 마이그레이션을 계획해야한다.
- AWS Application Discovery 서비스로 마이그레이션을 계획
서버를 스캔하고 마이그레이션에 중요한 서버 설치 데이터 및 종속성 매핑에 대한 정보를 수집 - 마이그레이션 방법 두 가지
- Agentless Discovery(AWS Agentless Discovery Connector)
- VM, 구성, CPU와 메모리 및 디스크 사용량 같은 성능 기록에 대한 정보를 제공
- Agent-based Discovery(AWS Application Discovery Agent)
- VM 내에서 더 많은 업데이트와 정보를 얻을 수 있다.
- 시스템 구성, 성능, 실행 중인 프로세스, 시스템 사이의 네트워크 연결에 대한 세부정보
- 종속성 매핑을 얻는 데 좋다.
- Agentless Discovery(AWS Agentless Discovery Connector)
- 위 모든 결과 데이터를 AWS Migration Hub 서비스에서 볼 수 있다.
- Application Discovery 서비스는 이동해야 할 항목과 내부적으로 어떻게 상호 연결되어 있는지 파악하기에 유용하다.
- 이제 실제로 옮겨야 하는데 MGN을 사용한다.
AWS Application Migration Service(MGN)
- 온프레미스에서 AWS로 이동하는 가장 간단한 방법이다.
- MGN을 사용해 리호스팅을 할 수 있다.
Lift-and-shift 솔루션이라는 물리적,가상,또는 클라우드에 있는 다른 서버를 AWS 클라우드 네이티브로 실행
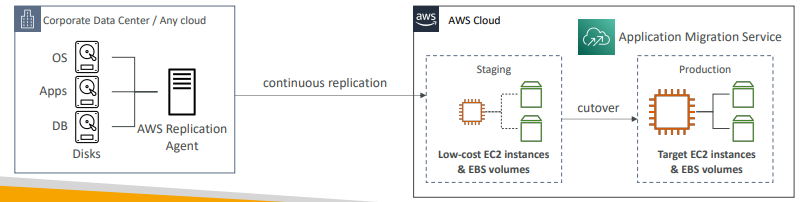
- OS, 앱, DB가 있는 데이터 센터가 있고, 디스크에서 실행된다.
- MGN을 실행하면 데이터 센터에 설치된 복제 에이전트가 디스크를 연속적으로 복제한다.
- 예를 들어 저비용 EC2, EBS볼륨이 이런 데이터 복제를 갖게 된다.
- 컷오버를 수행할 준비가 되면 스테이징에서 프로덕션으로 이동할 수 있다.
컷 오버: 구 시스템을 완전히 중단 시키고 새롭게 구축한 시스템으로 새로 서비스를 오픈 하는 것
- 원하는 크기의 더 큰 EC2와 EBS 볼륨을 갖게 되는것
- 즉, 데이터를 복제한 다음 어느 시점에서 컷오버를 수행하는 것. - 이 방법은 광범위한 플랫폼, OS, DB를 지원한다.
- 서비스가 자동으로 수행되어 엔지니어를 고용할 필요가 없기 때문에 비용도 줄고, 다운타임도 최소이다.
대규모 데이터를 AWS로 전송
[EX] 200TB의 데이터를 클라우드로 옮기고 싶다면
현재 인터넷 연결 속도는 100Mbps이다.
- 방법
- 공용 인터넷 사용/Site-to-Site VPN 사용
- 설치가 빠르고, 바로 연결이 가능하다
200TB -> 200,000,000MB * 8Mb/100Mbps = 16,000,000s = 185일
- 이렇게 적합할 수도 있고 아닐 수도 있다. - Direct Connect를 사용해 연결 라인을 통해 1Gbps로 프로비저닝한 경우
- 초기 설치에 시간이 오래 걸린다(한 달)
- 연결 된 후
200(TB)1000(GB)1000(MB)*8(Mb)/1Gbps= 1,600,000s = 18.5일 - Snowball을 사용(일회성 전송)
- Snowball 주문 2~3개가 필요할것으로 예상
- 시설에 동시에 도착하도록 병렬 주문
- Snowball이 도착해 로드하고 다시 싣고 AWS로 보내져 데이터가 송신되어 종단 간 전송에 일주일 소요
- 그리고 Snowball을 통해 전송되고 있던 DB가 있었다면 DMS와 결합해 나머지 데이터를 전송할 수 있다.
- AWS로 첫 번째 데이터를 보내는 데에 유용 - 지속적 복제/전송의 경우
- Site-to-Site VPN 또는 DMS가 포함된 DX(Direct Connect) 또는 데이터싱크
- 지속적 복제에서는 당장 전송할 데이터양이 적기 때문
- 공용 인터넷 사용/Site-to-Site VPN 사용
VMware Cloud on AWS
- 온프레미스에 데이터 센터가 있을 때 VMware Cloud로 데이터 센터를 관리하는 경우가 있다.
- vSphere 기반 환경과 VM을 VMWare Cloud를 통해 관리하는 경우
- VMware에 데이터 센터가 있는 고객은 데이터 센터의 용량을 확장하고 클라우드와 AWS를 모두 사용하고 싶다.
- 그러나 데이터 센터와 클라우드를 관리하는 데에는 계속 VMware Cloud를 이용하고 싶을 수 있다.
- 이럴때 VMware Cloud on AWS를 사용
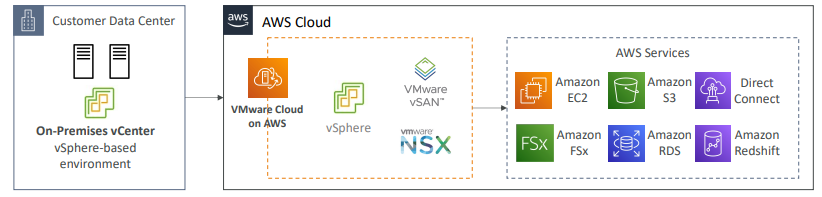
- 전체 VMware Cloud의 인프라를 AWS에서 확장함으로써 vShpere, vSAN, NSX 등에서 사용할 수 있다. - 사용 사례
- 컴퓨팅 성능을 확장해 데이터 센터에서 클라우드뿐 아니라 스토리지까지 컴퓨팅이 가능해져 VMware 기반 워크로드를 AWS로 마이그레이션할 수 있음.
- 프로덕션 워크로드를 여러 데이터 센터 간 실행할 수 있고, 프라이빗, 퍼블릭, 하이브리드 클라우드 환경 모두 가능하다.
- 재해 복구 전략으로도 활용 가능하다.
익숙한 제품을 사용해 신속하게 클라우드에 액세스할 수 있기 때문
- AWS 클라우드를 사용하므로 다양한 AWS 서비스를 이용할 수 있게 된다.
