[머신러닝/딥러닝] 전이 학습 (Transfer Learning)

1. 전이 학습의 개요
1-1. 전이 학습이란?
Transfer Learning(전이 학습)은 머신러닝 및 딥러닝에서 사용되는 기술로, 이미 학습된 모델의 지식을 새로운 작업에 활용하는 방법을 의미한다. 이는 특히 대규모 데이터셋을 이용해 사전 학습된 모델이 있고, 새로운 작업에 대해 제한된 데이터만 있는 상황에서 유용하다. 전이 학습은 학습 시간과 데이터 요구량을 줄여주고, 새로운 작업에서 더 나은 성능을 달성하는 데 도움을 준다.
전이학습에는 다양한 장점이 있다. 먼저, 새로운 작업에 대해 적은 양의 데이터만으로도 높은 성능을 달성할 수 있다. 또, 사전 학습된 모델을 활용함으로써 학습 시간을 크게 줄일 수 있다. 그리고 사전 학습된 모델의 지식을 활용하여 새로운 작업에서 더 나은 성능을 기대할 수 있다.
1-2. 전이 학습과 파인 튜닝
전이 학습(Transfer Learning)과 파인튜닝(Fine-Tuning)은 머신러닝 및 딥러닝에서 사전 학습된 모델을 새로운 작업에 맞게 활용하는 두 가지 방법이다. 이 둘은 밀접하게 연관되어 있지만, 구체적인 접근 방식과 사용 목적에서 차이가 있다.
전이학습은 추가된 층만을 훈련하고, 학습한 모델은 동결한다(사전 학습된 모델의 파라미터를 고정한 상태에서 사용한다). 그에 반해 파인튜닝에서는 모델의 일부를 재학습하여 새로운 작업에 최적화한다. 파인튜닝은 사전 학습된 모델을 새로운 작업에 맞게 조정함으로써 해당 작업에 대한 성능을 크게 향상시킬 수 있다.
2. 전이학습의 구현
거대한 이미지 데이터셋 'ImageNet'에 의해 학습한 모델에 완전 결합 층(Fully Connected Layer)를 추가한다. 이미 학습한 모델은 훈련하지 않고, 새롭게 추가한 층만을 훈련하여 이미지 분류를 해본다.
2-1. 각 설정
필요한 모듈을 임포트하고, 최적화 알고리즘을 설정한다. CIFAR-10의 이미지 크기를 2배로 하여 사용하므로 이미지의 폭과 높이는 64, 채널 수는 3으로 설정한다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.optimizers import Adam
optimizer = Adam()
img_size = 64 # 이미지의 폭과 높이
n_channel = 3 # 채널 수
n_mid = 256 # 중간층의 뉴런 수
batch_size = 32
epochs = 202-2. VGG16의 도입
ImageNet을 사용해 훈련한 모델 VGG16을 불러들인다. 추가 훈련은 하지 않는다.
https://keras.io/api/applications/vgg/
from tensorflow.keras.applications import VGG16
model_vgg16 = VGG16(weights='imagenet', # Imagenet에서 학습한 파라미터 사용
include_top=False, # 완전결합층 포함 X
input_shape=(img_size, img_size, n_channel)) # 입력의 형태
model_vgg16.summary()실행 결과
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 64, 64, 3)] 0
block1_conv1 (Conv2D) (None, 64, 64, 64) 1792
block1_conv2 (Conv2D) (None, 64, 64, 64) 36928
block1_pool (MaxPooling2D) (None, 32, 32, 64) 0
block2_conv1 (Conv2D) (None, 32, 32, 128) 73856
block2_conv2 (Conv2D) (None, 32, 32, 128) 147584
block2_pool (MaxPooling2D) (None, 16, 16, 128) 0
block3_conv1 (Conv2D) (None, 16, 16, 256) 295168
block3_conv2 (Conv2D) (None, 16, 16, 256) 590080
block3_conv3 (Conv2D) (None, 16, 16, 256) 590080
block3_pool (MaxPooling2D) (None, 8, 8, 256) 0
block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160
block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808
block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808
block4_pool (MaxPooling2D) (None, 4, 4, 512) 0
block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808
block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block5_pool (MaxPooling2D) (None, 2, 2, 512) 0
=================================================================
Total params: 14714688 (56.13 MB)
Trainable params: 14714688 (56.13 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________합성곱층 및 풀링층을 여러번 중첩하고 있으며, 학습 가능한 파라미터의 수는 1500만 개 정도가 있다.
2-3. CIFAR-10
Keras를 사용해 CIFAR-10을 읽어들인다. 비행기와 자동차 이미지를 사용해 이미지가 비행기인지 자동차인지 분류할 수 있도록, 새롭게 추가한 층을 훈련한다. 아래 코드에서 CIFAR-10을 읽어들이고 비행기와 자동차의 랜덤 이미지 25장을 표시한다. 원래의 이미지 크기는 32x32인데, VGG16의 입력은 48x48 이상의 크기여야 하므로, Numpy의 repeat() 메소드로 크기를 2배인 64x64로 조정한다.
from tensorflow.keras.datasets import cifar10
(x_train, t_train), (x_test, t_test) = cifar10.load_data()
# 라벨이 0, 1인 데이터만 꺼낸다
t_train = t_train.reshape(-1)
t_test = t_test.reshape(-1)
x_train = x_train[t_train < 2]
t_train = t_train[t_train < 2]
x_test = x_test[t_test < 2]
t_test = t_test[t_test < 2]
print("Original size : ", x_train.shape)
# 이미지를 2배로 확대
x_train = x_train.repeat(2, axis=1).repeat(2, axis=2)
x_test = x_test.repeat(2, axis=1).repeat(2, axis=2)
print("Expanded size(Input Size) : ", x_train.shape)
n_image = 25
rand_idx = np.random.randint(0, len(x_train), n_image)
cifar10_labels = np.array(["airplane", "automobile"])
plt.figure(figsize=(10, 10))
for i in range(n_image):
cifar_img = plt.subplot(5, 5, i+1)
plt.imshow(x_train[rand_idx[i]])
label = cifar10_labels[t_train[rand_idx[i]]]
plt.title(label)
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False)
2-4. 모델의 구축
VGG16의 층은 훈련하지 않고, 추가한 FCL만 훈련한다.
model = Sequential()
model.add(model_vgg16)
model.add(Flatten()) # 1차원 배열로 변환
model.add(Dense(n_mid))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model_vgg16.trainable = False # 훈련 안함!
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 2, 2, 512) 14714688
flatten (Flatten) (None, 2048) 0
dense (Dense) (None, 256) 524544
activation (Activation) (None, 256) 0
dropout (Dropout) (None, 256) 0
dense_1 (Dense) (None, 1) 257
activation_1 (Activation) (None, 1) 0
=================================================================
Total params: 15239489 (58.13 MB)
Trainable params: 524801 (2.00 MB)
Non-trainable params: 14714688 (56.13 MB)
_________________________________________________________________2-5. 학습
overfitting 방지를 위해 데이터 확장을 도입한다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
x_train = x_train / 255
x_test = x_test / 255
# 데이터 확장
generator = ImageDataGenerator(rotation_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=10,
zoom_range=0.2,
horizontal_flip=True)
generator.fit(x_train)
# 훈련
history = model.fit(generator.flow(x_train, t_train, batch_size=batch_size), epochs=epochs, validation_data=(x_test, t_test))실행 결과
Epoch 1/20
313/313 [==============================] - 27s 62ms/step - loss: 0.2617 - accuracy: 0.8888 - val_loss: 0.1678 - val_accuracy: 0.9390
Epoch 2/20
313/313 [==============================] - 16s 51ms/step - loss: 0.2108 - accuracy: 0.9155 - val_loss: 0.1558 - val_accuracy: 0.9375
Epoch 3/20
313/313 [==============================] - 17s 53ms/step - loss: 0.1948 - accuracy: 0.9208 - val_loss: 0.1541 - val_accuracy: 0.9440
Epoch 4/20
313/313 [==============================] - 16s 52ms/step - loss: 0.1905 - accuracy: 0.9221 - val_loss: 0.1365 - val_accuracy: 0.9455
Epoch 5/20
313/313 [==============================] - 16s 51ms/step - loss: 0.1826 - accuracy: 0.9276 - val_loss: 0.1309 - val_accuracy: 0.9495
Epoch 6/20
313/313 [==============================] - 16s 50ms/step - loss: 0.1784 - accuracy: 0.9272 - val_loss: 0.1532 - val_accuracy: 0.9420
Epoch 7/20
313/313 [==============================] - 15s 49ms/step - loss: 0.1730 - accuracy: 0.9313 - val_loss: 0.1229 - val_accuracy: 0.9555
Epoch 8/20
313/313 [==============================] - 16s 51ms/step - loss: 0.1676 - accuracy: 0.9320 - val_loss: 0.1249 - val_accuracy: 0.9535
Epoch 9/20
313/313 [==============================] - 15s 49ms/step - loss: 0.1702 - accuracy: 0.9308 - val_loss: 0.1299 - val_accuracy: 0.9495
Epoch 10/20
313/313 [==============================] - 16s 52ms/step - loss: 0.1647 - accuracy: 0.9340 - val_loss: 0.1342 - val_accuracy: 0.9445
Epoch 11/20
313/313 [==============================] - 15s 49ms/step - loss: 0.1619 - accuracy: 0.9323 - val_loss: 0.1350 - val_accuracy: 0.9460
Epoch 12/20
313/313 [==============================] - 16s 51ms/step - loss: 0.1614 - accuracy: 0.9356 - val_loss: 0.1319 - val_accuracy: 0.9505
Epoch 13/20
313/313 [==============================] - 16s 51ms/step - loss: 0.1479 - accuracy: 0.9380 - val_loss: 0.1229 - val_accuracy: 0.9515
Epoch 14/20
313/313 [==============================] - 15s 49ms/step - loss: 0.1600 - accuracy: 0.9346 - val_loss: 0.1268 - val_accuracy: 0.9510
Epoch 15/20
313/313 [==============================] - 16s 52ms/step - loss: 0.1472 - accuracy: 0.9419 - val_loss: 0.1214 - val_accuracy: 0.9550
Epoch 16/20
313/313 [==============================] - 16s 50ms/step - loss: 0.1489 - accuracy: 0.9403 - val_loss: 0.1220 - val_accuracy: 0.9555
Epoch 17/20
313/313 [==============================] - 17s 54ms/step - loss: 0.1457 - accuracy: 0.9407 - val_loss: 0.1066 - val_accuracy: 0.9605
Epoch 18/20
313/313 [==============================] - 16s 51ms/step - loss: 0.1496 - accuracy: 0.9403 - val_loss: 0.1214 - val_accuracy: 0.9520
Epoch 19/20
313/313 [==============================] - 15s 49ms/step - loss: 0.1483 - accuracy: 0.9391 - val_loss: 0.1166 - val_accuracy: 0.9555
Epoch 20/20
313/313 [==============================] - 16s 50ms/step - loss: 0.1427 - accuracy: 0.9432 - val_loss: 0.1126 - val_accuracy: 0.95702-6. 학습의 추이
history를 사용해 학습의 추이를 확인한다.
import matplotlib.pyplot as plt
train_loss = history.history['loss'] # 훈련용 데이터의 오차
train_acc = history.history['accuracy'] # 훈련용 데이터의 정확도
val_loss = history.history['val_loss'] # 검증용 데이터의 오차
val_acc = history.history['val_accuracy'] # 검증용 데이터의 정확도
plt.plot(np.arange(len(train_loss)), train_loss, label='loss')
plt.plot(np.arange(len(val_loss)), val_loss, label='val_loss')
plt.legend()
plt.show()
plt.plot(np.arange(len(train_acc)), train_acc, label='acc')
plt.plot(np.arange(len(val_acc)), val_acc, label='val_acc')
plt.legend()
plt.show()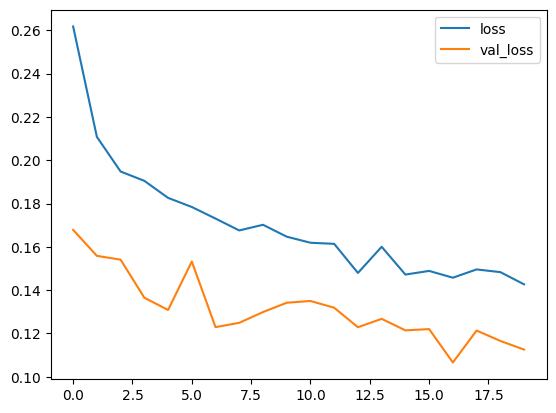
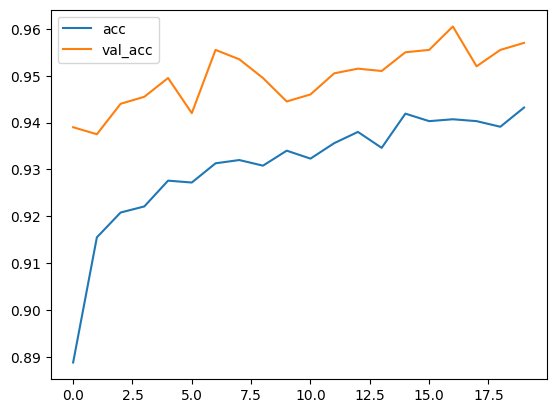
상당히 높은 정밀도로 비행기와 자동차를 분류할 수 있다.
3. 파인 튜닝의 구현
3-1. 설정
앞의 전이학습과 마찬가지로 필요한 모듈을 임포트하고 이미지 크기를 설정한다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.optimizers import Adam
optimizer = Adam()
img_size = 64 # 이미지의 폭과 높이
n_channel = 3 # 채널 수
n_mid = 256 # 중간층의 뉴런 수
batch_size = 32
epochs = 203-2. VGG16의 도입
from tensorflow.keras.applications import VGG16
model_vgg16 = VGG16(weights='imagenet', # imagenet에서 학습한 파라미터를 사용
include_top=False, # 전결합층을 포함하지 않는다
input_shape=(img_size, img_size, n_channel)) # 입력의 형태
model_vgg16.summary()Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 64, 64, 3)] 0
block1_conv1 (Conv2D) (None, 64, 64, 64) 1792
block1_conv2 (Conv2D) (None, 64, 64, 64) 36928
block1_pool (MaxPooling2D) (None, 32, 32, 64) 0
block2_conv1 (Conv2D) (None, 32, 32, 128) 73856
block2_conv2 (Conv2D) (None, 32, 32, 128) 147584
block2_pool (MaxPooling2D) (None, 16, 16, 128) 0
block3_conv1 (Conv2D) (None, 16, 16, 256) 295168
block3_conv2 (Conv2D) (None, 16, 16, 256) 590080
block3_conv3 (Conv2D) (None, 16, 16, 256) 590080
block3_pool (MaxPooling2D) (None, 8, 8, 256) 0
block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160
block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808
block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808
block4_pool (MaxPooling2D) (None, 4, 4, 512) 0
block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808
block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block5_pool (MaxPooling2D) (None, 2, 2, 512) 0
=================================================================
Total params: 14714688 (56.13 MB)
Trainable params: 14714688 (56.13 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________3-3. CIFAR-10
Keras를 사용해 CIFAR-10을 읽어들인다. 마찬가지로 비행기, 자동차의 이미지만을 사용하여 훈련한다.
from tensorflow.keras.datasets import cifar10
(x_train, t_train), (x_test, t_test) = cifar10.load_data()
# 라벨이 0, 1인 데이터만 꺼낸다
t_train = t_train.reshape(-1)
t_test = t_test.reshape(-1)
x_train = x_train[t_train < 2]
t_train = t_train[t_train < 2]
x_test = x_test[t_test < 2]
t_test = t_test[t_test < 2]
print("Original size : ", x_train.shape)
# 이미지를 확대한다
x_train = x_train.repeat(2, axis=1).repeat(2, axis=2)
x_test = x_test.repeat(2, axis=1).repeat(2, axis=2)
print("Expanded size : ", x_train.shape)실행 결과
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 10s 0us/step
Original size : (10000, 32, 32, 3)
Expanded size : (10000, 64, 64, 3)3-4. 모델의 구축
도입한 VGG16에 FCL층을 추가한다. VGG16에서는 block5에 있는 여러 개의 Convolutional Layer를 훈련 가능하도록 설정한다.
model = Sequential()
model.add(model_vgg16)
model.add(Flatten()) # 1차원 배열로 변환
model.add(Dense(n_mid))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
# block 5만 훈련한다
for layer in model_vgg16.layers:
if layer.name.startswith('block5_conv'):
layer.trainable = True
else:
layer.trainable = False
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
model.summary()3-5. 학습
from tensorflow.keras.preprocessing.image import ImageDataGenerator
x_train = x_train / 255
x_test = x_test / 255
# 데이터 확장
generator = ImageDataGenerator(rotation_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=10,
zoom_range=0.2,
horizontal_flip=True)
generator.fit(x_train)
# 훈련
history = model.fit(generator.flow(x_train, t_train, batch_size=batch_size), epochs=epochs, validation_data=(x_test, t_test))Epoch 1/20
313/313 [==============================] - 26s 62ms/step - loss: 0.3060 - accuracy: 0.8914 - val_loss: 0.1099 - val_accuracy: 0.9500
Epoch 2/20
313/313 [==============================] - 18s 57ms/step - loss: 0.1439 - accuracy: 0.9514 - val_loss: 0.0601 - val_accuracy: 0.9795
Epoch 3/20
313/313 [==============================] - 17s 56ms/step - loss: 0.1098 - accuracy: 0.9614 - val_loss: 0.0706 - val_accuracy: 0.9760
Epoch 4/20
313/313 [==============================] - 17s 53ms/step - loss: 0.1002 - accuracy: 0.9659 - val_loss: 0.0673 - val_accuracy: 0.9800
Epoch 5/20
313/313 [==============================] - 18s 57ms/step - loss: 0.0828 - accuracy: 0.9716 - val_loss: 0.0476 - val_accuracy: 0.9830
Epoch 6/20
313/313 [==============================] - 17s 54ms/step - loss: 0.0816 - accuracy: 0.9710 - val_loss: 0.0741 - val_accuracy: 0.9850
Epoch 7/20
313/313 [==============================] - 17s 55ms/step - loss: 0.0750 - accuracy: 0.9739 - val_loss: 0.0531 - val_accuracy: 0.9840
Epoch 8/20
313/313 [==============================] - 17s 53ms/step - loss: 0.0748 - accuracy: 0.9730 - val_loss: 0.0467 - val_accuracy: 0.9855
Epoch 9/20
313/313 [==============================] - 19s 59ms/step - loss: 0.0646 - accuracy: 0.9775 - val_loss: 0.0492 - val_accuracy: 0.9830
Epoch 10/20
313/313 [==============================] - 17s 53ms/step - loss: 0.0663 - accuracy: 0.9770 - val_loss: 0.0448 - val_accuracy: 0.9860
Epoch 11/20
313/313 [==============================] - 17s 54ms/step - loss: 0.0651 - accuracy: 0.9789 - val_loss: 0.0532 - val_accuracy: 0.9820
Epoch 12/20
313/313 [==============================] - 17s 56ms/step - loss: 0.0604 - accuracy: 0.9794 - val_loss: 0.0537 - val_accuracy: 0.9830
Epoch 13/20
313/313 [==============================] - 17s 54ms/step - loss: 0.0575 - accuracy: 0.9797 - val_loss: 0.0428 - val_accuracy: 0.9865
Epoch 14/20
313/313 [==============================] - 17s 55ms/step - loss: 0.0535 - accuracy: 0.9817 - val_loss: 0.0464 - val_accuracy: 0.9850
Epoch 15/20
313/313 [==============================] - 18s 56ms/step - loss: 0.0492 - accuracy: 0.9821 - val_loss: 0.0486 - val_accuracy: 0.9845
Epoch 16/20
313/313 [==============================] - 18s 57ms/step - loss: 0.0508 - accuracy: 0.9822 - val_loss: 0.0409 - val_accuracy: 0.9860
Epoch 17/20
313/313 [==============================] - 18s 56ms/step - loss: 0.0546 - accuracy: 0.9804 - val_loss: 0.0623 - val_accuracy: 0.9825
Epoch 18/20
313/313 [==============================] - 18s 57ms/step - loss: 0.0530 - accuracy: 0.9805 - val_loss: 0.0404 - val_accuracy: 0.9870
Epoch 19/20
313/313 [==============================] - 18s 58ms/step - loss: 0.0477 - accuracy: 0.9831 - val_loss: 0.0443 - val_accuracy: 0.9815
Epoch 20/20
313/313 [==============================] - 17s 55ms/step - loss: 0.0493 - accuracy: 0.9833 - val_loss: 0.0541 - val_accuracy: 0.98353-6. 학습의 추이
history 를 사용해 학습의 추이를 확인한다.
import matplotlib.pyplot as plt
train_loss = history.history['loss']
val_loss = history.history['val_loss']
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(np.arange(len(train_loss)), train_loss, label='loss')
plt.plot(np.arange(len(val_loss)), val_loss, label='val_loss')
plt.legend()
plt.show()
plt.plot(np.arange(len(train_acc)), train_acc, label='acc')
plt.plot(np.arange(len(val_acc)), val_acc, label='val_acc')
plt.legend()
plt.show()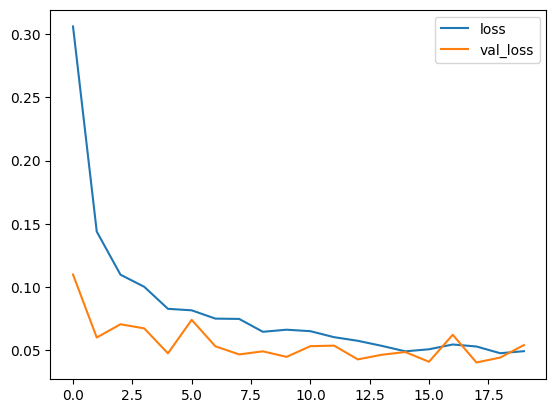
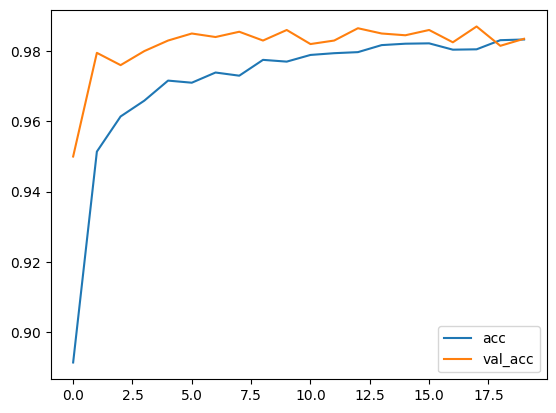
일반 전이학습을 적용했을 때보다 파인튜닝을 적용했을 때의 정확도가 높고 오차와 정확도가 안정적으로 수렴한다. 학습한 모델의 일부 및 추가한 층에 대해서 훈련함으로써, 특정 업무에 대해 특화한 학습을 할 수 있다.
