
1. 강화학습의 개요
강화학습(Reinforcement Learning, RL)은 인공지능 분야의 한 갈래로, 에이전트(Agent)가 환경(Environment)과 상호작용하면서 최적의 행동(Policy)을 학습하는 방법이다.
1-1. 인공지능, 머신러닝, 강화학습
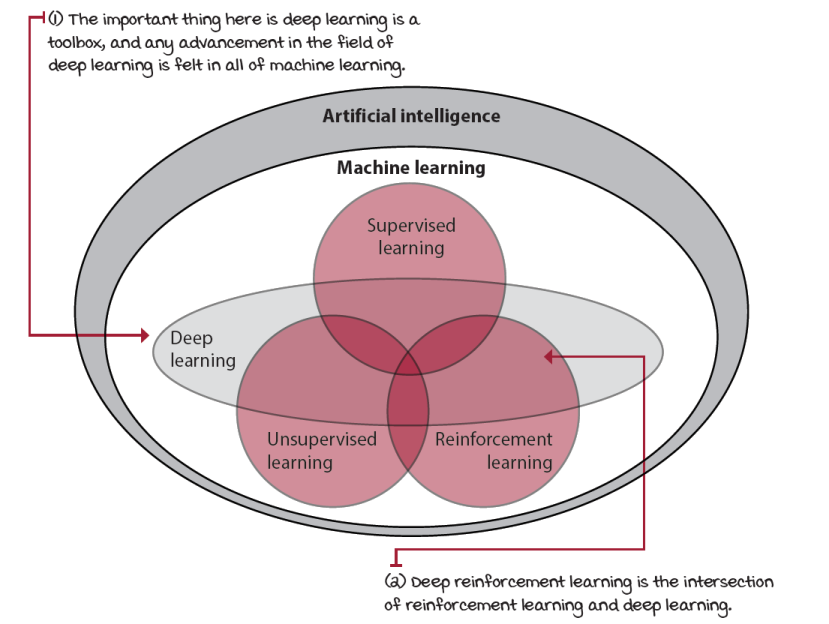
출처 : https://livebook.manning.com/book/grokking-deep-reinforcement-learning/chapter-1/
- 인공지능(AI): 전체적인 학문 분야, 인간 지능을 모방하는 시스템을 개발하는 것. 예: 챗봇, 자율주행차, 이미지 인식 시스템.
- 머신러닝(ML): AI의 하위 분야로, 데이터를 기반으로 패턴을 학습하는 알고리즘을 개발.
- 지도학습: 입력과 출력 데이터(레이블)를 사용하여 모델을 학습. 예: 이메일 스팸 필터링, 이미지 분류.
- 비지도학습: 레이블이 없는 데이터를 사용하여 데이터의 패턴이나 구조를 학습. 예: 고객 세분화, 주성분 분석(PCA).
- 강화학습: 에이전트가 환경과 상호작용하여 보상을 최대화하는 정책을 학습. 예: 자율주행차의 경로 최적화, 게임 플레이 에이전트.
1-2. 강화 학습이란?
강화학습(Reinforcement Learning, RL)은 에이전트가 환경과 상호작용하며 보상을 최대화하는 방법을 학습하는 알고리즘이다. 에이전트가 행동을 통해 보상을 받으면, 에이전트는 보상을 최대로 얻을 수 있도록 규칙을 개선해나간다.
강화학습으로 가장 잘 알려진 예시로는 AlphaGo가 있다. AlphaGo는 구글 딥마인드가 개발한 인공지능 프로그램으로, 바둑에서 최고 수준의 성과를 보이며 매우 유명한 사례이다.
AlphaGo는 강화학습을 기반으로 바둑을 두는 능력을 학습했다. 여기서 AlphaGo는 다음과 같은 요소들을 활용하여 학습하고 결정한다.
-
에이전트: AlphaGo 자체가 에이전트이다. 바둑을 두는 결정을 내리고 수를 선택하는 주체이다.
-
환경: AlphaGo가 상호작용하는 환경은 바둑판과 상대방(다른 바둑 프로그램 또는 전문가)이다.
-
상태: 현재 바둑판의 상태와 둘 수 있는 수가 상태가 된다. AlphaGo는 현재 바둑판의 상태를 입력으로 받아 결정을 내린다.
-
행동: AlphaGo는 현재 상태에서 가능한 수 중에서 하나를 선택하여 수를 둔다.
-
보상: AlphaGo는 승리하거나 패배하거나 또는 게임 진행 상의 보상을 받는다. 승리에 대한 보상은 높고, 패배에 대한 보상은 낮다.
-
정책: AlphaGo는 트리 탐색과 신경망 기반의 정책 신경망을 결합하여 최적의 수를 선택하는 정책을 개발하였다.
AlphaGo는 강화학습을 통해 수백만 번의 게임을 자기 학습하여 최적의 정책을 학습하였다. 이러한 방식으로 AlphaGo는 전세계 최고수 바둑기사 이세돌과 대국을 했을 때 승리를 거두며 인공지능의 가능성을 보여주었다.
1-3. 강화학습의 개념
강화학습의 주요 개념
강화학습은 다음과 같은 주요 개념을 포함한다.
❶ 에이전트(Agent): 의사 결정을 내리고 행동을 수행하는 주체. 예를 들어, 자율주행차가 에이전트가 될 수 있다.
❷ 환경(Environment): 에이전트가 상호작용하는 외부 시스템 또는 세계. 자율주행차가 주행하는 도로 환경이 환경이 될 수 있다.
❸ 상태(State): 에이전트가 현재 위치한 상황을 나타내는 정보. 예를 들어, 자율주행차가 현재 위치한 도로의 상태와 주변 차량의 위치와 속도가 상태가 될 수 있다.
❹ 행동(Action): 에이전트가 취할 수 있는 선택지. 예를 들어, 자율주행차가 전진, 좌회전, 우회전 등의 행동을 선택할 수 있다.
❺ 보상(Reward): 에이전트가 특정 상태에서 특정 행동을 취했을 때 받는 즉시적인 보상. 예를 들어, 자율주행차가 안전하게 목적지에 도착하면 양의 보상을 받고, 사고가 발생하면 음의 보상을 받을 수 있다.
❻ 정책(Policy): 에이전트가 주어진 상태에서 어떤 행동을 선택할지 결정하는 규칙이나 전략. 목표는 정책을 최적화하여 보상을 최대화하는 것.
강화학습이 보상을 최대화하는 방법
강화학습은 보상을 최대화하는 최적의 정책을 학습하기 위해 다음과 같은 방법들을 사용한다.
-
탐험(Exploration): 새로운 행동을 시도하며 미지의 지식을 탐구하는 과정. 초기에는 보상을 최대화하는 최적의 행동을 찾기 위해 다양한 행동을 시도해야 한다.
-
이용(Exploitation): 이미 배운 지식을 활용하여 현재에서 가장 좋은 행동을 선택하는 과정. 이용과 탐험은 상호보완적인 전략으로 사용된다.
-
가치 함수(Value Function): 각 상태나 상태-행동 쌍의 기대 보상을 추정하는 함수. 가치 함수는 에이전트가 보상을 최대화하는 데 도움을 준다.
-
모델(Model): 환경의 동작을 예측하는 모델을 학습하여 효율적인 학습을 돕는다. 모델은 실제 환경과의 상호작용 없이 시뮬레이션을 통해 학습할 수 있는 장점을 제공한다.
2. 강화 학습의 알고리즘
2-1. Q-learning
Q-learning은 마치 길을 찾는 게임을 하면서 경험을 통해 최적의 결정을 내리는 것과 비슷하다. 예를 들어, 미로를 탈출하는 게임에서 각 교차로마다 가장 빠른 길을 기억하고 있는 것처럼 생각할 수 있다. 처음에는 어떤 길이 가장 빠른지 모르지만, 경험을 통해 최적의 길을 찾아가는 과정이다.
-
탐험: 미로에서 시작할 때 어느 교차로에서든 무작위로 길을 선택한다.
-
보상과 벌점: 출구에 도착하면 보상을 받고, 막다른 길에 빠지면 벌점을 받는다. 이 경험을 바탕으로 각 교차로에서 어떤 선택이 좋은지를 학습한다.
-
학습: 시간이 지나면서 출구를 더 빨리 찾을 수 있는 최적의 결정을 Q-table이라는 표로 기록한다. Q-table은 각 상태(교차로)에서 가능한 행동(길의 선택)에 대한 최적의 가치(Q-value)를 담고 있다.
-
최적의 길 선택: Q-table을 참고하여 어느 교차로에서든 최선의 길을 선택하고 따라간다.
-
최적의 전략 습득: 충분한 탐험과 학습을 통해 미로를 빠르게 탈출할 수 있는 최적의 전략을 습득한다.
따라서 Q-learning은 간단하지만 매우 강력한 강화학습 알고리즘으로, 시행착오를 통해 최적의 전략을 배우는 과정을 의미한다.
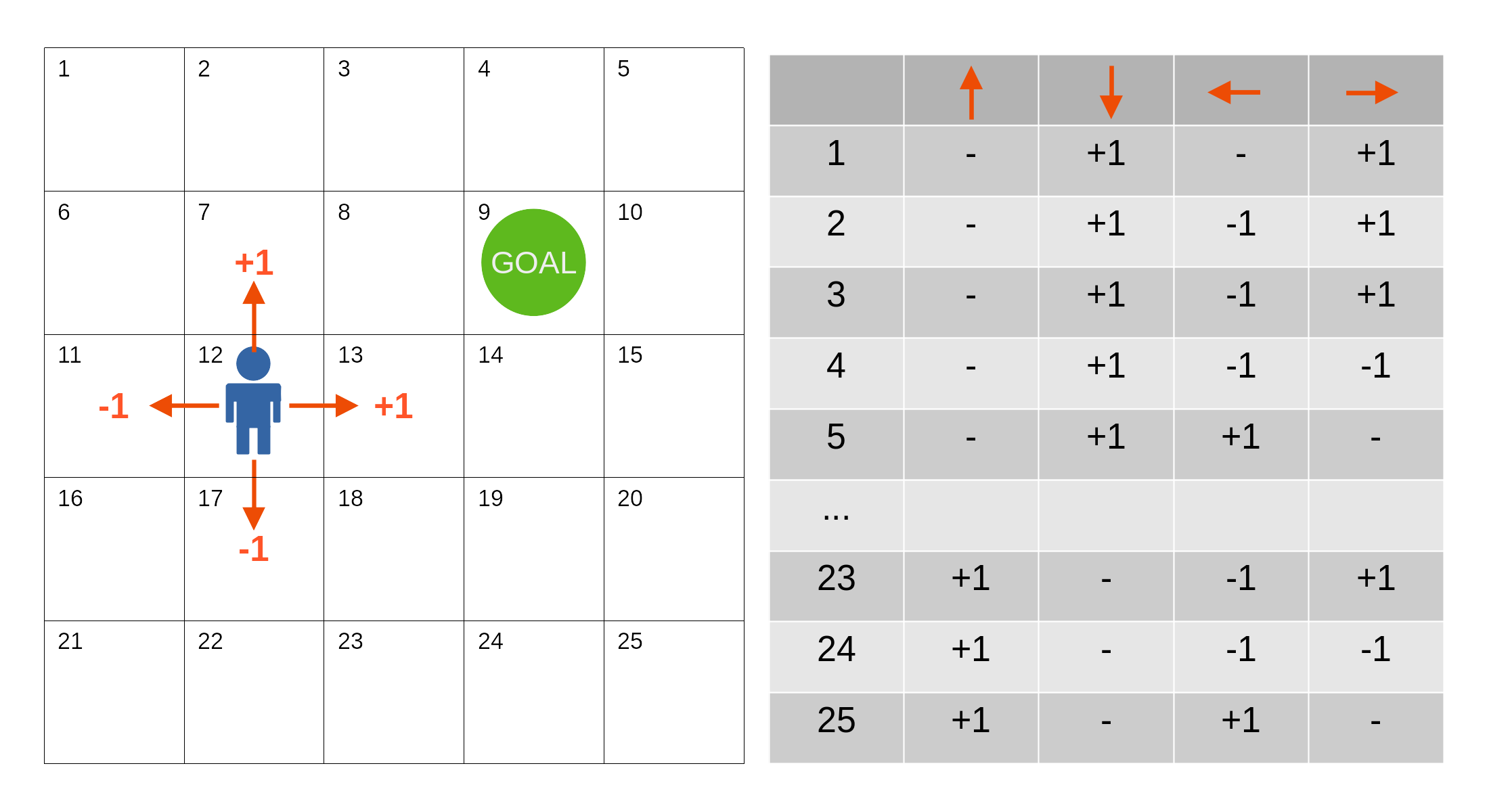
출처 : https://blog.spiceai.org/posts/2021/12/15/understanding-q-learning-how-a-reward-is-all-you-need/
2-2. Q값의 갱신
Q값의 갱신은 다음과 같은 과정을 거친다.
-
현재 상태에서 행동 선택: 에이전트는 현재 상태에서 Q값을 기반으로 행동을 선택한다. 일반적으로 ε-greedy 방법을 사용하여 탐험(exploration)과 활용(exploitation) 사이의 균형을 맞춘다.
-
보상 획득: 선택한 행동을 실행하면 환경으로부터 보상(reward)을 받는다.
-
다음 상태 이동: 환경에서는 선택한 행동에 따라 다음 상태로 이동한다.
-
Q값 갱신: Q-learning에서는 다음과 같은 공식을 사용하여 Q값을 갱신한다.
- 이 식에서 첨자 는 시각을 나타낸다. 은 다음 시각이다. 는 시각 에서의 행동, 는 시각 에서의 상태, 는 Q값, 는 학습 계수, 은 시각 에서 얻을 수 있는 보상, 는 할인율이라는 상수이다. 화살표는 Q값의 갱신을 의미한다.
-
환경과 상호작용: 에이전트는 갱신된 Q값을 바탕으로 환경과 상호작용한다. 이 과정에서 에이전트는 다음 상태로 이동하고, 보상을 받는다.
-
행동 선택: 다음 상태에서 다시 Q값을 기반으로 행동을 선택한다. 일반적으로는 ε-greedy 방법을 사용하여 탐험과 활용을 균형있게 한다.
- ε-greedy 방법에 대해서는 바로 다음 장에서 설명한다.
-
Q값 갱신: 새로운 상태에서 선택한 행동에 대한 Q값을 갱신한다. 위에서 설명한 Q값 갱신 공식을 사용하여 다시 Q값을 업데이트한다.
이런 과정을 반복하면서 에이전트는 시간이 지나면서 최적의 행동을 학습하고 최적의 Q값을 찾아간다.
ε-greedy method
ε-greedy 방법은 강화학습에서 탐험(exploration)과 활용(exploitation) 사이의 균형을 맞추기 위한 전략이다. 에이전트가 환경과 상호작용하면서 최적의 행동을 선택하는 전략 중 하나로 널리 사용되고 있다.
ε-greedy 방법은, 확률 ε으로 랜덤한 행동을 취하도록 하고, 확률 1-ε으로 Q값이 최대가 되는 행동을 취하도록 한다. 그리고 이 ε을 학습을 거듭함에 따라 감소시킨다. 이렇게 하면, 학습 초기에는 랜덤한 탐색이 많이 이루어지지만, 점차 Q값에 따라 행동이 결정된다.
확률 ε으로 랜덤한 행동을 취하도록 하는 것은, 탐색 범위가 좁은 영역에만 국한되지 않도록 하기 위함이다.
2-4. SARSA
SARSA(SARSA: State-Action-Reward-State-Action)는 강화학습에서 사용되는 알고리즘으로, 특히 에이전트가 특정 환경에서 어떤 상태에서 특정 행동을 했을 때의 가치를 학습하는 데 적합하다. SARSA는 주어진 상태에서 가능한 행동을 살펴보고, 각 행동의 가치를 업데이트하여 최적의 정책을 학습하는 방법이다. SARSA의 작동 과정은 다음과 같다.
-
상태 (State) 관찰 : 에이전트는 환경으로부터 현재 상태 를 관찰한다.
-
행동 선택 : 현재 상태 에서 가능한 행동 중에서 ε-greedy 방법 등을 사용하여 하나의 행동 를 선택한다.
-
보상 획득 : 선택한 행동 을 실행하여 환경으로부터 보상 을 받는다.
-
다음 상태 관찰 : 보상을 받은 후 에이전트는 다음 상태 을 관찰한다.
-
다음 행동 선택 및 Q값 업데이트
- 다음 상태 에서 가능한 행동 중에서 ε-greedy 방법을 사용하여 하나의 행동 을 선택한다.
- 선택한 행동 을 기반으로 Q값을 업데이트한다. 다음은 SARSA에서의 Q값의 갱신식이다.
- : 현재 상태 에서 행동 을 선택했을 때의 Q값
- : 학습률(learning rate), Q값을 업데이트할 때 얼마나 새로운 정보를 반영할지를 결정하는 요소
- $R_{t+1} : 다음 상태에서 얻은 보상
- : 할인 계수(discount factor), 미래 보상의 가치를 현재 가치로 얼마나 할인할지를 결정
2-5. Q-learning과 SARSA의 차이
SARSA와 Q-learning은 모두 Off-policy 강화학습 알고리즘으로서 Q값을 학습하지만, 다음과 같은 차이가 있다.
탐험 정책 적용
- SARSA : 학습 과정에서 사용하는 정책과 탐험 정책이 같다. 즉, 현재 상태에서 다음 행동을 선택할 때 사용되는 정책이 SARSA 알고리즘에서도 학습하는 정책이다.
- Q-learning : 학습 과정에서 사용하는 정책(탐욕적 정책)과 탐험 정책(ε-greedy)이 다르다. Q-learning은 학습 중에 최적의 정책을 학습하고, 탐험은 ε-greedy 방법을 사용하여 수행한다.
Q값 업데이트 시점
- SARSA: 다음 상태에서 실제로 선택한 행동 의 Q값을 사용하여 Q값을 업데이트한다.
- Q-learning: 다음 상태에서 가능한 모든 행동 중에서 가장 높은 Q값을 사용하여 Q값을 업데이트한다.
SARSA는 실제로 에이전트가 선택한 행동을 기반으로 Q값을 업데이트하는 반면, Q-learning은 다음 상태에서 가능한 모든 행동 중에서 가장 높은 Q값을 이용하여 업데이트를 수행하는 것이다.
3. 심층 강화 학습
3-1. Q-Table의 문제
Q-Table은 다음과 같은 문제가 있다.
-
메모리가 많이 필요하다 : Q-Table은 게임이나 문제의 모든 가능한 상태와 행동을 저장해야 한다. 상태나 행동의 수가 많아지면 테이블이 매우 커져서 컴퓨터 메모리를 많이 차지한다. 예를 들어, 체스 같은 게임에서는 가능한 상태가 너무 많아서 다 저장할 수 없다.
-
연속적인 상황을 처리하기 어렵다 : 예를 들어, 로봇이 방 안에서 움직일 때 로봇의 위치는 계속 변한다. Q-Table로 이 모든 위치를 각각 저장하려면 무한히 많은 상태를 저장해야 해서 불가능하다.
-
비슷한 상황을 배우기 어렵다 : Q-Table은 각각의 상태와 행동에 대해 따로따로 학습한다. 그래서 비슷한 상황에서의 정보를 잘 활용하지 못한다. 예를 들어, 길을 걷는 로봇이 비슷한 두 위치에 있을 때, 한 위치에서 배운 것을 다른 위치에 바로 적용할 수 없다.
-
탐색 시간이 오래 걸려요 : Q-Table을 사용하면 처음에는 모든 상태와 행동을 하나씩 시도해봐야 한다. 그래서 처음 학습할 때 시간이 오래 걸릴 수 있다. 예를 들어, 미로를 탐험하는 로봇이 처음에는 모든 길을 다 시도해봐야 해서 시간이 오래 걸린다.
이러한 문제를 해결하기 위해 딥러닝을 도입한 Deep Q-Networks 같은 모델이 제안되었다. DQN은 Q학습시 Q-Table 대신 신경망을 사용한다. 다음 장에서 자세히 설명하겠다.
3-2. DQN
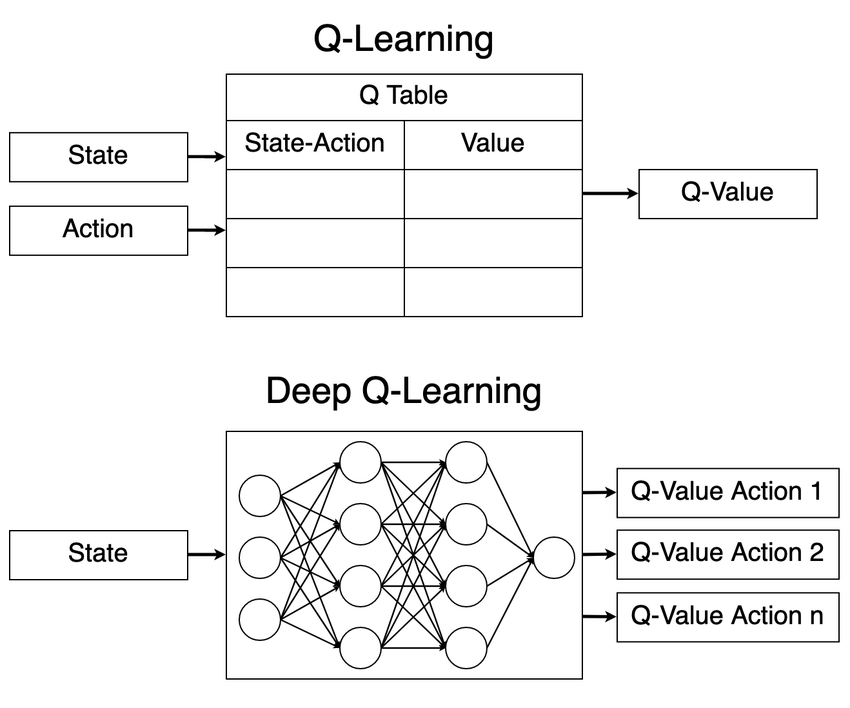
Deep Q-Networks (DQN)는 Q-learning의 확장으로, 딥러닝을 사용하여 Q값을 근사한다. 이로 인해 상태 공간이 매우 커도 효율적으로 학습할 수 있다. DQN에서는 Q값을 예측하기 위해 신경망(Neural Network)을 사용합니다. 이 신경망은 상태를 입력으로 받아, 각 행동에 대한 Q값을 출력한다.
DQN은 두 개의 신경망을 사용하는데, 하나는 현재 Q값을 예측하는 신경망, 다른 하나는 타깃 Q값을 예측하는 신경망이다. 타깃 네트워크는 일정 간격으로 현재 신경망의 가중치를 복사하여 업데이트된다. 이를 통해 학습 과정에서 발생할 수 있는 불안정성을 줄인다. 예를 들어, 일정 시간마다 현재 네트워크의 가중치를 타깃 네트워크로 복사하여 업데이트한다.
DQN의 작동 방식
-
초기화
- Q값을 근사하는 신경망과 타깃 신경망을 초기화한다.
- 경험을 저장할 메모리를 초기화한다.
-
반복 학습
- 현재 상태를 입력으로 받아 신경망을 통해 각 행동에 대한 Q값을 예측한다.
- ε-greedy 정책을 사용하여 행동을 선택한다. (무작위 탐색과 최적 행동 선택을 적절히 섞는다)
- 선택한 행동을 실행하고, 보상과 다음 상태를 관찰한다.
- (현재 상태, 행동, 보상, 다음 상태)를 메모리에 저장한다.
- 메모리에서 무작위로 샘플을 선택하여 신경망을 업데이트한다.
- 일정 간격으로 타깃 신경망을 업데이트한다.
DQN의 작동 예시(게임)
예를 들어, DQN을 사용하여 게임 에이전트를 학습시키는 경우를 생각해본다. 에이전트는 게임 화면(상태)을 입력으로 받아, 각 가능한 행동(예: 왼쪽 이동, 오른쪽 이동, 점프)에 대한 Q값을 출력한다. 에이전트는 ε-greedy 정책을 사용하여 행동을 선택하고, 게임을 진행하면서 보상(점수)을 얻는다. 이 경험을 메모리에 저장하고, 나중에 무작위로 샘플링하여 신경망을 학습한다. 이렇게 하면 에이전트는 점점 더 높은 점수를 얻는 방법을 학습하게 된다.
3-3. DQN의 학습
오차
Deep Q-Networks에서는 신경망이 학습을 담당한다. Q값으로부터 오차를 계산하고, 그 오차를 역전파시켜서 신경망에 학습한다. 이때의 오차에는 Q값 갱신량을 구할때 사용한 식의 일부를 사용한다. 다음은 DQN에서 사용되는 오차의 예시이다.
- : 시간 t+1에서 받은 보상
- 𝛾 : 할인 인자(discount factor), 미래 보상의 현재 가치에 대한 중요도를 결정
- : 다음 상태 에서의 가능한 행동 𝑎에 대한 Q값
- : 현재 상태 에서의 선택한 행동 에 대한 Q값
오차의 계산 과정
이 식을 사용한 오차의 계산 과정은 다음과 같다.
- 목표 Q값(Target Q-Value)
- 다음 상태 에서의 최대 Q값을 사용하여 목표 Q값을 계산한다.
- 목표 Q값 :
- 여기서, 는 다음 상태에서 가능한 모든 행동에 대한 Q값 중 최대값이다.
- 현재 Q값(Current Q-Value)
- 현재 상태 에서의 행동 에 대한 Q값이다.
- 현재 Q값:
- 오차 계산
- 목표 Q값과 현재 Q값 사이의 차이를 오차로 계산한다.
- 오차 :
- 제시된 식에서 오차는 제곱 오차(Mean Squared Error, MSE)로 계산된다.
- 여기서, 는 수학적으로 MSE를 계산할 때 사용하는 스케일링 상수이다.
신경망 학습
이 오차를 계산한 후, 역전파(backpropagation)를 통해 신경망의 가중치를 업데이트한다. 역전파 과정에서는 오차가 최소화되도록 신경망의 가중치가 조정된다. 이 과정을 반복하여 Q값을 점점 더 정확하게 예측하게 된다.
4. Cart Pole 문제
Cart Pole 문제는 강화학습에서 자주 사용되는 고전적인 제어 문제이다. 이 문제에서는 막대기(pole)가 수레(cart) 위에 세워져 있고, 에이전트는 수레를 좌우로 움직여 막대기가 넘어지지 않도록 균형을 유지해야 한다.
4-1. Cart Pole 문제란?
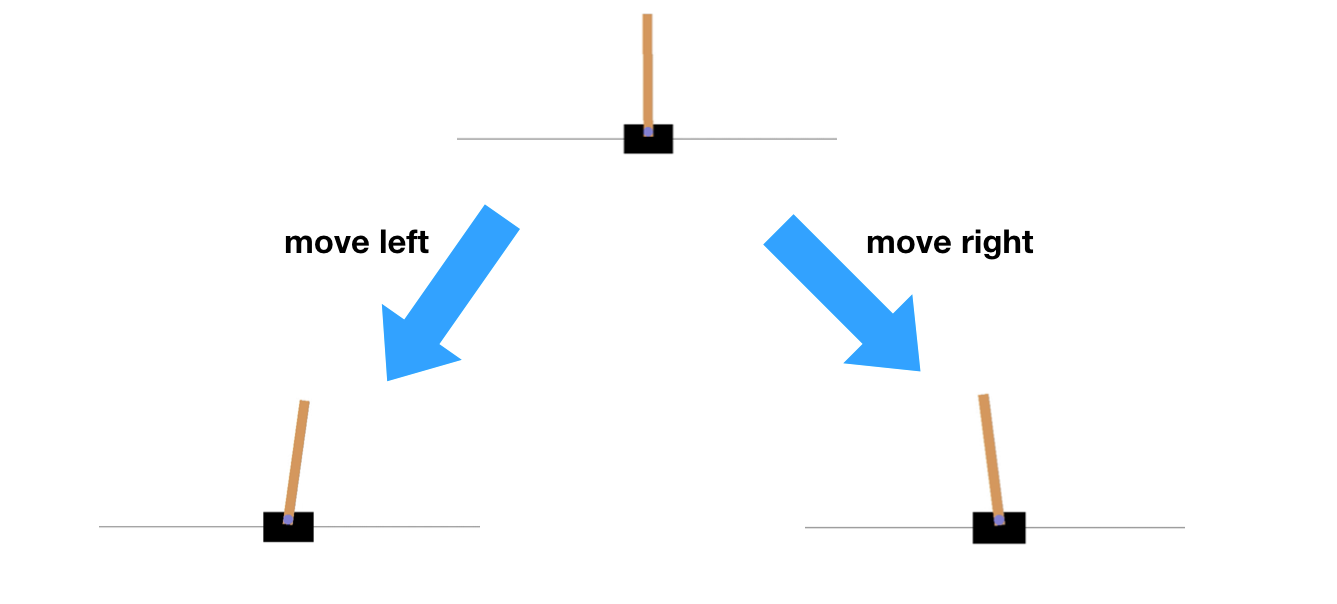
문제 설명
-
목표: 막대기가 수평으로 넘어지지 않도록 최대한 오래 유지하는 것.
-
상태(State): 4개의 요소로 구성된 벡터
- 수레의 위치 (cart position)
- 수레의 속도 (cart velocity)
- 막대기의 각도 (pole angle)
- 막대기의 각속도 (pole angular velocity)
-
행동(Action): 2가지
- 수레를 왼쪽으로 이동
- 수레를 오른쪽으로 이동
-
보상(Reward): 매 시간 단계마다 막대기가 넘어지지 않으면 +1의 보상을 받음. 막대기가 넘어지면 에피소드가 종료되고 보상을 받지 못함.
강화학습 알고리즘을 사용한 Cart Pole 해결
강화학습 알고리즘을 사용하여 Cart Pole 문제를 해결하는 과정은 다음과 같다.
- 환경 초기화: Cart Pole 환경을 초기화하고 초기 상태를 설정
- 행동 선택: 현재 상태를 기반으로 정책에 따라 행동을 선택 (예:
𝜖-greedy 방법) - 행동 수행 및 보상 획득: 선택한 행동을 수행하고 다음 상태와 보상을 관찰
- Q-값 업데이트: Q-러닝이나 다른 강화학습 알고리즘을 사용하여 Q-값을 업데이트
- 정책 업데이트: 얻은 경험을 바탕으로 정책을 업데이트
- 반복: 목표가 달성되거나 에피소드가 종료될 때까지 위 과정을 반복
4-3. Cart Pole 문제에서의 신경망
신경망 입력
- 입력: Cart Pole 문제의 상태 벡터
- 4개의 요소로 구성: 수레의 위치 (cart position), 수레의 속도 (cart velocity), 막대기의 각도 (pole angle), 막대기의 각속도 (pole angular velocity).
신경망 출력
- 출력: 각 행동에 대한 Q-값.
- 2개의 요소로 구성: 수레를 왼쪽으로 이동할 때의 Q-값, 수레를 오른쪽으로 이동할 때의 Q-값.
신경망 구조
일반적인 DQN의 신경망 구조는 다음과 같다.
- 입력층: 상태 벡터 를 입력으로 받음 (입력 크기: 4).
- 첫 번째 은닉층: Fully Connected Layer (Dense layer) - 유닛 수: 24, 활성화 함수: ReLU.
- 두 번째 은닉층: Fully Connected Layer (Dense layer) - 유닛 수: 24, 활성화 함수: ReLU.
- 출력층: Fully Connected Layer (Dense layer) - 유닛 수: 2 (각 행동에 대한 Q-값), 활성화 함수: 없음 (선형 활성화).
5. DQN 구현하기
DQN을 사용하여 중력이 있는 상황에서 비행하는 물체의 제어를 실습해 본다.
5-1. 에이전트의 비행
에이전트 비행에는 다음과 같은 규칙을 설정한다.
- 에이전트의 초기 위치는 설정된 2D 공간의 왼쪽 끝 중앙이다.
- 에이전트가 오른쪽 끝에 도달했을 때는 보상으로 +1을 주고 종료한다.
- 에이전트가 설정된 2D 공간의 맨 위 또는 아래에 닿으면 보상으로 -1을 주고 종료한다.
- 수평축 방향으로는 등속도 운동을 한다.
- 행동은 자유 낙하(행동 0)과 점프(행동 1)의 두 종류로 제한한다.
5-2. 각 설정
필요한 모듈을 임포트하고 최적화 알고리즘을 설정한다.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation, rc
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, ReLU
from tensorflow.keras.optimizers import RMSprop
optimizer = RMSprop()RMSprop은 Root Mean Square Propagation의 약자로, Adam옵티마이저와 비슷한 최적화 알고리즘 중 하나이다. 주로 신경망의 학습에서 사용되며, 기본적으로 경사 하강법의 한 종류이다. RMSprop은 기존의 경사 하강법에 비해 학습 속도를 개선하고 수렴을 빠르게 할 수 있는 장점이 있다.
5-3. 브레인 클래스
에이전트의 브레인이 되는 클래스이다. Q값을 출력하는 신경망을 구축하고, Q값이 정답에 근접하도록 훈련한다.
Q 학습에 이용하는 식은 다음과 같다.
딥러닝의 정답으로서 사용하는 것은 이 부분이 된다.
class Brain:
def __init__(self, n_state, n_mid, n_action, gamma=0.9, r=0.99):
self.eps = 1.0 # ε
self.gamma = gamma # 할인율
self.r = r # ε의 감쇠율
model = Sequential()
model.add(Dense(n_mid, input_shape=(n_state,)))
model.add(ReLU())
model.add(Dense(n_mid))
model.add(ReLU())
model.add(Dense(n_action))
model.compile(loss='mse', optimizer=optimizer)
self.model = model
def train(self, states, next_states, action, reward, terminal):
q = self.model.predict(states)
next_q = self.model.predict(next_states)
t = np.copy(q)
if terminal :
t[:, action] = reward
else :
t[:, action] = reward + self.gamma * np.max(next_q, axis=1)
self.model.train_on_batch(states, t)
def get_action(self, states):
q = self.model.predict(states)
if np.random.rand() < self.eps:
action = np.random.randint(q.shape[1], size=q.shape[0])
else :
action = np.argmax(q, axis=1) # Q값이 높은 행동
if self.eps > 0.1: # ε의 하한
self.eps *= self.r
return actiongamma는 할인율로 미래 보상의 가치를 감소시키는 역할이다. 할인율은 미래에 받을 보상이 현재에 비해 얼마나 중요한지를 결정한다. 미래에 받을 보상이 할인율에 따라 그 가치가 감소된다. 할인율이 1에 가까울수록 미래 보상의 가치가 높아지고, 0에 가까울수록 미래 보상의 가치가 낮아진다.
또, 할인율은 에이전트가 장기적인 보상을 최적화하는 데 도움을 준다. 에이전트는 할인율을 고려하여 현재 행동으로부터 기대되는 장기적인 보상을 계산하고 학습한다.
5-4. 에이전트 클래스
에이전트를 클래스로서 구현한다.
x좌표는 -1에서 1까지, y좌표는 -1에서 1까지 정사각형 영역이다. 에이전트의 초기 위치는 왼쪽 끝 중앙이다. 그리고 에이전트가 오른쪽 끝에 도달했을 때는 보상으로 +1을 주고 종료한다. 또한 에이전트가 위쪽 도는 아래쪽에 도달했을 때는 보상으로 -1을 주고 종료한다. x축 방향으로는 등속도 운동을 한다.
행동에는 자유낙하와 점프 두 종류가 있다. 자유낙하의 경우는 중력가속도를 y속도에 더한다. 점프의 경우는 y속도를 미리 설정한 값으로 변경한다.
class Agent:
def __init__(self, v_x, v_y_sigma, v_jump, brain):
self.v_x = v_x # x방향 속도
self.v_y_sigma = v_y_sigma # y속도, 초기값의 표준편차
self.v_jump = v_jump # 점프 속도
self.brain = brain
self.reset()
def reset(self):
self.x = -1 # 초기 x좌표
self.y = 0 # 초기 y좌표
self.v_y = self.v_y_sigma * np.random.randn() # 초기 y속도
states = np.array([[self.y, self.v_y]])
self.action = self.brain.get_action(states)
def step(self, g): # 시간을 1개 앞으로 움직인다. g : 중력 가속도
states = np.array([[self.y, self.v_y]])
self.x += self.v_x
self.y += self.v_y
reward = 0 # 보상
terminal = False # 종료 판정
if self.x > 1.0 :
reward = 1
terminal = True
elif self.y<-1.0 or self.y>1.0:
reward = -1
terminal = True
reward = np.array([reward])
if self.action[0] == 0:
self.v_y -= g # 자유낙하
else:
self.v_y = self.v_jump # 점프
next_states = np.array([[self.y, self.v_y]])
next_action = self.brain.get_action(next_states)
self.brain.train(states, next_states, self.action, reward, terminal)
self.action = next_action
if terminal :
self.reset() # 앞으로 움직인다
states = np.array([[self.y, self.v_y]])
self.x += self.v_x
self.y += self.v_y
reward = 0 # 보상
terminal = False # 종료 판정
if self.x > 1.0:
reward = 1
terminal = True
elif self.y<-1.0 or self.y>1.0:
reward = -1
terminal = True
reward = np.array([reward])
action = self.brain.get_action(states)
if action[0] == 0:
self.v_y -= g # 자유 낙하
else:
self.v_y = self.v_jump # 점프
next_states = np.array([[self.y, self.v_y]])
self.brain.train(states, next_states, action, reward, terminal)
if terminal:
self.reset()5-5. 환경의 클래스
환경을 클래스로서 구현한다. 이 클래스의 역할은 중력가속도를 설정하고 시가을 앞으로 움직이는 것이다.
class Environment:
def __init__(self, agent, g):
self.agent = agent
self.g = g
def step(self):
self.agent.step(self.g)
return (self.agent.x, self.agent.y)5-6. 애니메이션
여기에서는 matplotlib을 사용해서 물체의 비행을 애니메이션으로 나타낸다. 애니메이션에는 matplotlib.animation 의 FuncAnimation() 함수를 사용한다.
def animate(environment, interval, frames):
fig, ax = plt.subplots()
plt.close()
ax.set_xlim((-1, 1))
ax.set_ylim((-1, 1))
sc = ax.scatter([], [])
def plot(data):
x, y = environment.step()
sc.set_offsets(np.array([[x, y]]))
return (sc,)
return animation.FuncAnimation(fig, plot, interval=interval, frames=frames, blit=True)5-7. 랜덤한 확률
먼저 에이전트가 랜덤하게 행동하는 예를 살펴본다. r=1로 설정해서 ε이 감쇠하지 않게 해서, 에이전트는 완전히 랜덤한 행동만 선택한다.
# Random Behavior of Agent
n_state = 2 # 상태의 수
n_mid = 32 # 중간층의 뉴런 수
n_action = 2 # 행동의 수
brain = Brain(n_state, n_mid, n_action, r=1.0) # ε이 감쇠하지 않는다
v_x = 0.05 # x 방향 이동속도
v_y_sigma = 0.1
v_jump = 0.2 # 점프 시의 수직방향 속도
agent = Agent(v_x, v_y_sigma, v_jump, brain)
g = 0.2 # 중력 가속도
environment = Environment(agent, g)
interval = 50 # 애니메이션 순간(밀리초)
frames = 1024 # 프레임 수
anim = animate(environment, interval, frames)
rc('animation', html='jshtml')
anim실행 결과
에이전트의 랜덤한 행동을 관찰할 수 있다.
5-8. DQN 도입하기
r=0.99 로 설정하고 이 감쇠하도록 한다. 이로써 점차 Q값이 최대의 행동을 선택한다. 다음 코드를 실행하면 에이전트가 비행을 시작하는데, 여기에서는 DQN에 의한 학습을 수반한다.
# with DQN
n_state = 2 # 상태의 수
n_mid = 32 # 중간층의 뉴런 수
n_action = 2 # 행동의 수
brain = Brain(n_state, n_mid, n_action, r=0.99) # ε이 감쇠한다
v_x = 0.05 # x방향 이동속도
v_y_sigma = 0.1
v_jump = 0.2 # 점프 시의 수직방향 속도
agent = Agent(v_x, v_y_sigma, v_jump, brain)
g = 0.2 # 중력 가속도
environment = Environment(agent, g)
interval = 50 # 애니메이션 순간(밀리초)
frames = 1024 # 프레임 수
anim = animate(environment, interval, frames)
rc('animation', html='jshtml')
anim
에이전트는 화면 오른쪽 끝에 자주 도달하게 되었습니다.
